Archive for the ‘MySQL’ Category
MySQL RegExp Default
We had an interesting set of questions regarding the REGEXP comparison operator in MySQL today in both sections of Database Design and Development. They wanted to know the default behavior.
For example, we built a little movie table so that we didn’t change their default sakila example database. The movie table was like this:
CREATE TABLE movie ( movie_id int unsigned primary key auto_increment , movie_title varchar(60)) auto_increment=1001; |
Then, I inserted the following rows:
INSERT INTO movie ( movie_title ) VALUES ('The King and I') ,('I') ,('The I Inside') ,('I am Legend'); |
Querying all results with this query:
SELECT * FROM movie; |
It returns the following results:
+----------+----------------+ | movie_id | movie_title | +----------+----------------+ | 1001 | The King and I | | 1002 | I | | 1003 | The I Inside | | 1004 | I am Legend | +----------+----------------+ 4 rows in set (0.00 sec) |
The following REGEXP returns all the rows because it looks for a case insensitive “I” anywhere in the string.
SELECT movie_title FROM movie WHERE movie_title REGEXP 'I'; |
The implicit regular expression is actually:
WHERE movie_title REGEXP '^.*I.*$'; |
It looks for zero-to-many of any character before and after the “I“. You can get any string beginning with an “I” with the “^I“; and any string ending with an “I” with the “I$“. Interestingly, the “I.+$” should only match strings with one or more characters after the “I“, but it returns:
+----------------+ | movie_title | +----------------+ | The King and I | | The I Inside | | I am Legend | +----------------+ 3 rows in set (0.00 sec) |
This caught me by surprise because I was lazy. As pointed out in the comment, it only appears to substitute a “.*“, or zero-to-many evaluation for the “.+” because it’s a case-insensitive search. There’s another lowercase “i” in the “The King and I” and that means the regular expression returns true because that “i” has one-or-more following characters. If we convert it to a case-sensitive comparison with the keyword binary, it works as expected because it ignores the lowercase “i“.
WHERE binary movie_title REGEXP '^.*I.*$'; |
This builds on my 10-year old post on Regular Expressions. As always, I hope these notes helps others discovering features and behaviors of the MySQL database, and Bill thanks for catching my error.
MySQL CSV Output
Saturday, I posted how to use Microsoft ODBC DSN to connect to MySQL. Somebody didn’t like the fact that the PowerShell program failed to write a *.csv file to disk because the program used the Write-Host command to write to the content of the query to the console.
I thought that approach was a better as an example. However, it appears that it wasn’t because not everybody knows simple redirection. The original program can transfer the console output to a file, like:
powershell .\MySQLODBC.ps1 > output.csv |
So, the first thing you need to do is add a parameter list, like:
2 3 4 | param ( [Parameter(Mandatory)][string]$fileName ) |
Anyway, it’s trivial to demonstrate how to modify the PowerShell program to write to a disk. You should also create a virtual PowerShell drive before writing the file. That’s because you can change the physical directory anytime you want with minimal changes to rest of your code’s file references.
You can create a PowerShell virtual drive with the following command:
7 8 | New-PSDrive -Name test -PSProvider FileSystem -Description 'Test area' ` -Root C:\Data\cit225\mysql\test |
but, it will write the following to console:
Name Used (GB) Free (GB) Provider Root CurrentLocation ---- --------- --------- -------- ---- --------------- test 0.00 28.74 FileSystem C:\Data\cit225\mysql\test |
You can suppress the console output with Microsoft’s version of redirection to the void (> /dev/null), which pipes (|) the standard out (stdout) to Out-Null, like:
7 8 | New-PSDrive -Name test -PSProvider FileSystem -Description 'Test area' ` -Root C:\Data\cit225\mysql\test | Out-Null |
Since the program may run before an output file has been created, or after its been created and removed, you need to check whether the file exists before attempting to remove it. PowerShell provides the Test-Path command to check for the existence of a file and the Remove-Item command to remove a file, like:
11 12 | if (Test-Path test:$fileName) { Remove-Item -Path test:$fileName } |
Then, you simply replace the Write-Host call in the other program with the Add-Content command:
Add-Content -Value $output -Path test:$fileName |
Now, the PowerShell script file writes the MySQL query’s output to an output.csv file. You can call the MySQLContact.ps1 script file with the following syntax:
powershell MySQLContact.ps1 output.csv |
In case these changes don’t make sense outside the scope of the full script, here is the rewritten script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | # Define parameter list for mandatory file name. param ( [Parameter(Mandatory)][string]$fileName ) # Define a PowerShell Virtual Drive. New-PSDrive -Name test -PSProvider FileSystem -Description 'Test area' ` -Root C:\Data\cit225\mysql\test | Out-Null # Remove the file only when it exists. if (Test-Path test:$fileName) { Remove-Item -Path test:$fileName } # Define a ODBC DSN connection string. $ConnectionString = 'DSN=MySQLODBC2' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT last_name " + ", first_name " + "FROM contact " + "ORDER BY 1, 2"; # Attempt to read SQL command. try { $row = $Command.ExecuteReader(); # Read while records are found. while ($row.Read()) { # Initialize output for each row. $output = "" # Navigate across all columns (only two in this example). for ($column = 0; $column -lt $row.FieldCount; $column += 1) { # Mechanic for comma-delimit between last and first name. if ($output.length -eq 0) { $output += $row[$column] } else { $output += ", " + $row[$column] } } # Write the output from the database to a file. Add-Content -Value $output -Path test:$fileName } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $row.Close() } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
While I understand you might want to go to this level of effort if you where building a formal cmdlet, I’m not convinced its worth the effort in an ordinary PowerShell script. However, I don’t like to leave a question unanswered.
MySQL ODBC DSN
This post explains and demonstrates how to install, configure, and use the MySQL’s ODBC libraries and a DSN (Data Source Name) to connect your Microsoft PowerShell programs to a locally or remotely installed MySQL database. After you’ve installed the MySQL ODBC library, use Windows search field to find the ODBC Data Sources dialog and run it as administrator.
There are four steps to setup, test, and save your ODBC Data Source Name (DSN) for MySQL. You can click on the images on the right to launch them in a more readable format or simply read the instructions.
MySQL ODBC Setup Steps
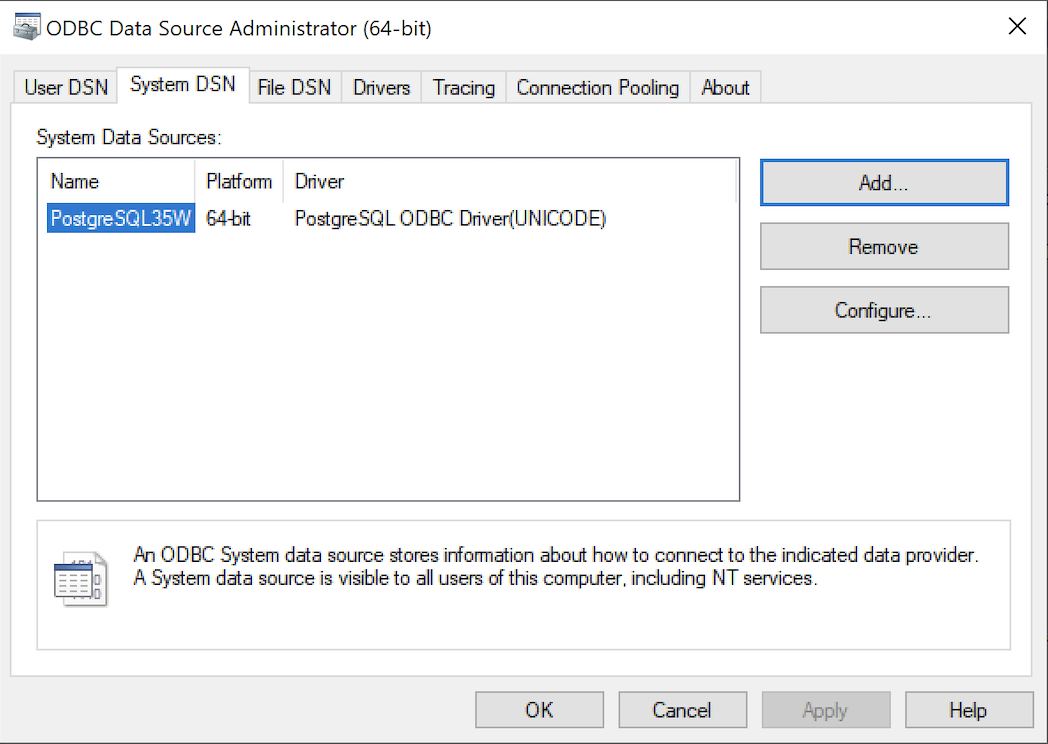
- Click the SystemDSN tab to see he view which is exactly like the User DSN tab. Click the Add button to start the workflow.
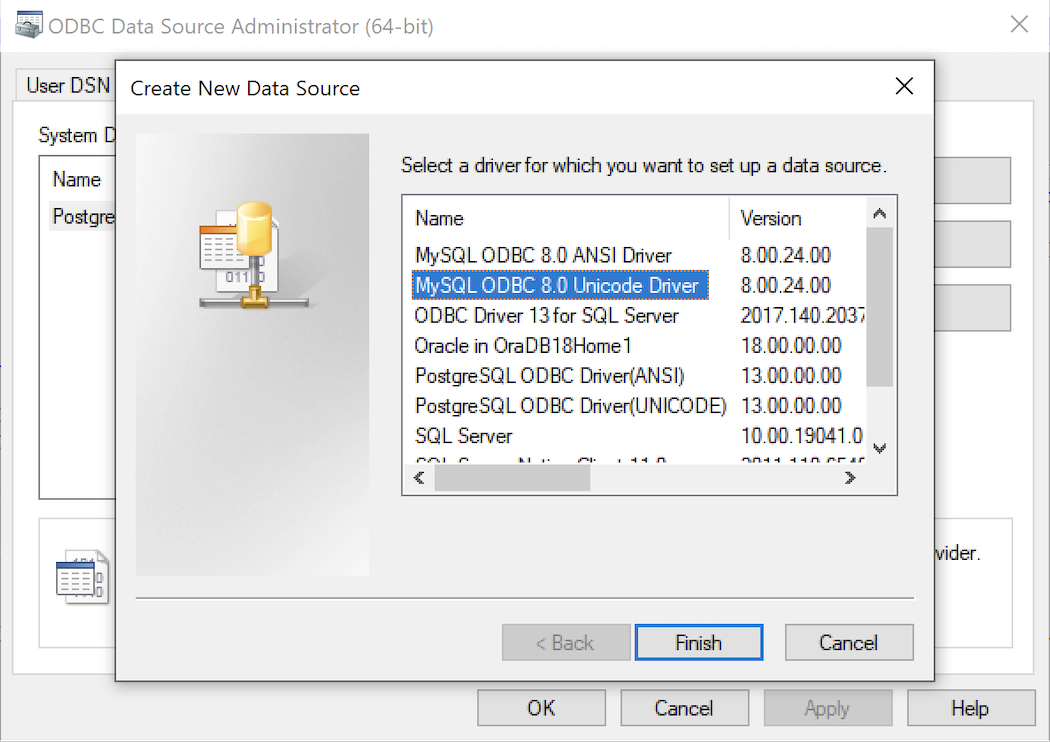
- The Create New Data Source dialog requires you select the MySQL ODBC Driver(UNICODE) option from the list and click the Finish button to proceed.
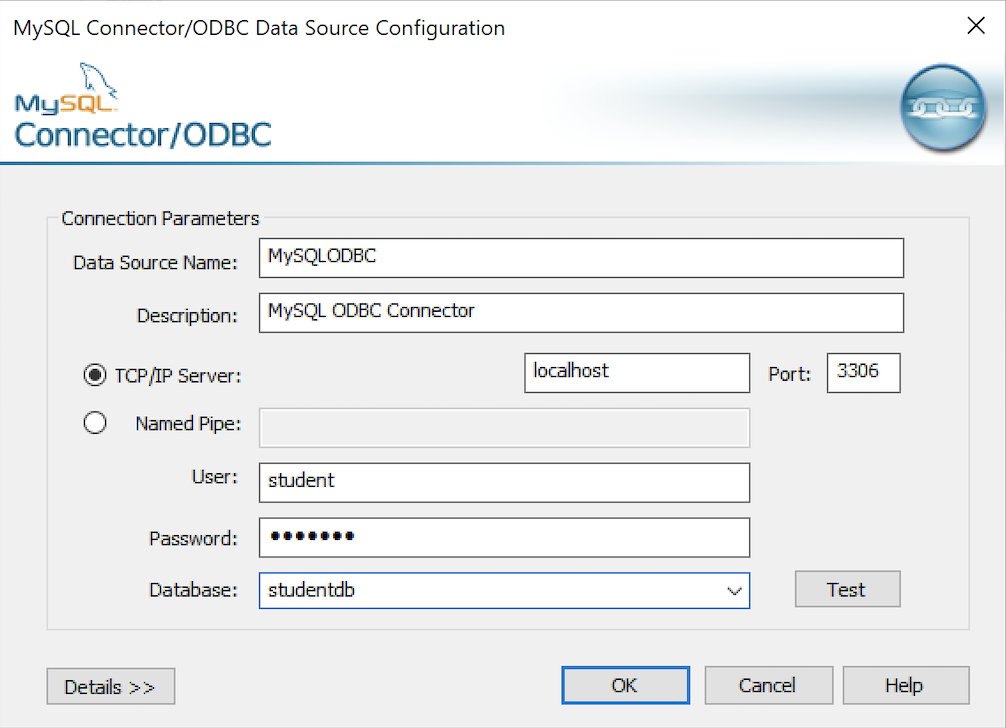
- The MySQL Unicode ODBC Driver Setup dialog should complete the prompts as follows below. If you opt for localhost as the server value and you have a DCHP IP address, make sure you’ve configured your hosts file in the C:\Windows\System32\drivers\etc directory. You should enter the following two lines in the hosts file:
127.0.0.1 localhost ::1 localhost
These are the string values you should enter in the MySQL Unicode ODBC Driver Setup dialog:
Data Source: MySQLODBC Database: studentdb Server: localhost User Name: student Description: MySQL ODBC Connector Port: 3306 Password: student
After you complete the entry, click the Test button.
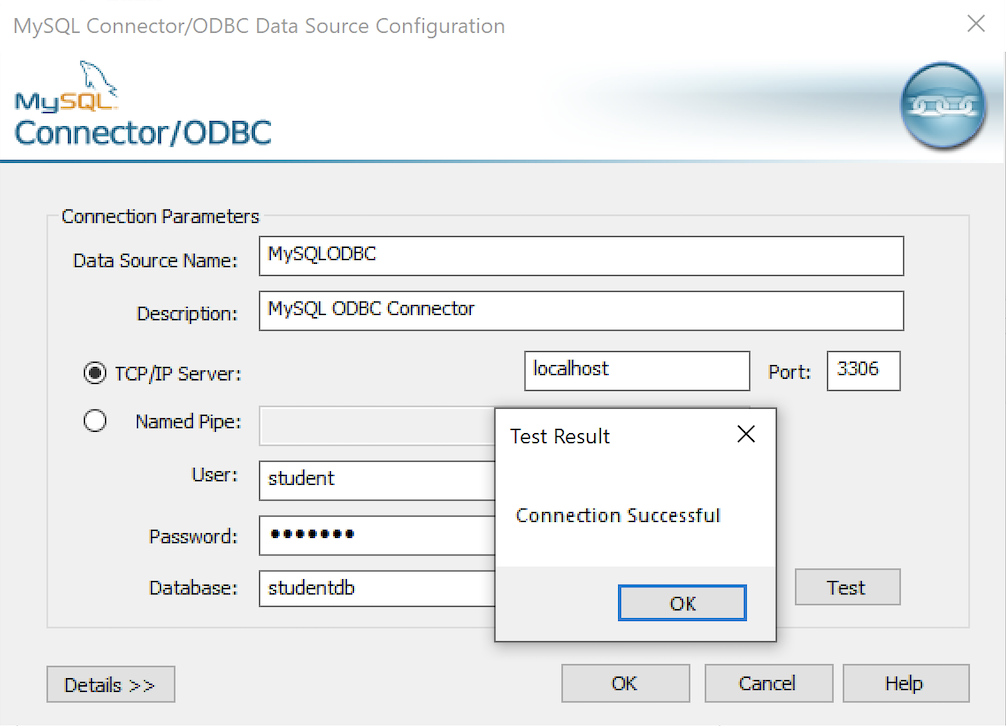
- The Connection Test dialog should return a “Connection successful” message. Click the OK button to continue, and then click the OK button in the next two screens.
After you have created the System MySQL ODBC Setup, it’s time to build a PowerShell Cmdlet (or, Commandlet). Some documentation and blog notes incorrectly suggest you need to write a connection string with a UID and password, like:
$ConnectionString = 'DSN=MySQLODBC;Uid=student;Pwd=student' |
You can do that if you leave the UID and password fields empty in the MySQL ODBC Setup but it’s recommended to enter them there to avoid putting them in your PowerShell script file.
The UID and password are unnecessary in the connection string when they’re in MySQL ODBC DSN. You can use a connection string like the following when the UID and password are in the DSN:
$ConnectionString = 'DSN=MySQLODBC' |
You can create a MySQLCursor.ps1 Cmdlet like the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | # Define a ODBC DSN connection string. $ConnectionString = 'DSN=MySQLODBC' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT database();"; # Attempt to read SQL command. try { $Reader = $Command.ExecuteReader(); # Read while records are found. while ($Reader.Read()) { Write-Host "Current Database [" $Reader[0] "]"} } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $Reader.Close() } } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
Line 14 assigns a SQL query that returns a single row with one column as the CommandText of a Command object. Line 22 reads the zero position of a row or record set with only one column.
You call the MySQLCursor.ps1 Cmdlet with the following syntax:
powershell .\MySQLCursor.ps1 |
It returns:
Current Database [ studentdb ] |
A more realistic way to write a query would return multiple rows with a set of two or more columns. The following program queries a table with multiple rows of two columns, but the program logic can manage any number of columns.
# Define a ODBC DSN connection string. $ConnectionString = 'DSN=MySQLODBC' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT last_name, first_name FROM contact ORDER BY 1, 2"; # Attempt to read SQL command. try { $row = $Command.ExecuteReader(); # Read while records are found. while ($row.Read()) { # Initialize output for each row. $output = "" # Navigate across all columns (only two in this example). for ($column = 0; $column -lt $row.FieldCount; $column += 1) { # Mechanic for comma-delimit between last and first name. if ($output.length -eq 0) { $output += $row[$column] } else { $output += ", " + $row[$column] } } # Write the output from the database. Write-Host $output } } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $row.Close() } } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
You call the MySQLContact.ps1 Cmdlet with the following syntax:
powershell .\MySQLContact.ps1 |
It returns an ordered set of comma-separated values, like
Clinton, Goeffrey Gretelz, Simon Moss, Wendy Potter, Ginny Potter, Harry Potter, Lily Royal, Elizabeth Smith, Brian Sweeney, Ian Sweeney, Matthew Sweeney, Meaghan Vizquel, Doreen Vizquel, Oscar Winn, Brian Winn, Randi |
As always, I hope this helps those looking for a complete concrete example of how to make Microsoft Powershell connect and query results from a MySQL database.
MySQL 5-Table Procedure
A student wanted a better example of writing a MySQL Persistent Stored Module (PSM) that maintains transactional scope across a couple tables. Here’s the one I wrote about ten years ago to build the MySQL Video Store model. It looks I neglected to put it out there before, so here it is for reference.
-- Conditionally drop procedure if it exists. DROP PROCEDURE IF EXISTS contact_insert; -- Reset the delimiter so that a semicolon can be used as a statement and block terminator. DELIMITER $$ SELECT 'CREATE PROCEDURE contact_insert' AS "Statement"; CREATE PROCEDURE contact_insert ( pv_member_type CHAR(12) , pv_account_number CHAR(19) , pv_credit_card_number CHAR(19) , pv_credit_card_type CHAR(12) , pv_first_name CHAR(20) , pv_middle_name CHAR(20) , pv_last_name CHAR(20) , pv_contact_type CHAR(12) , pv_address_type CHAR(12) , pv_city CHAR(30) , pv_state_province CHAR(30) , pv_postal_code CHAR(20) , pv_street_address CHAR(30) , pv_telephone_type CHAR(12) , pv_country_code CHAR(3) , pv_area_code CHAR(6) , pv_telephone_number CHAR(10)) MODIFIES SQL DATA BEGIN /* Declare variables to manipulate auto generated sequence values. */ DECLARE member_id int unsigned; DECLARE contact_id int unsigned; DECLARE address_id int unsigned; DECLARE street_address_id int unsigned; DECLARE telephone_id int unsigned; /* Declare local constants for who-audit columns. */ DECLARE lv_created_by int unsigned DEFAULT 1001; DECLARE lv_creation_date DATE DEFAULT UTC_DATE(); DECLARE lv_last_updated_by int unsigned DEFAULT 1001; DECLARE lv_last_update_date DATE DEFAULT UTC_DATE(); /* Declare a locally scoped variable. */ DECLARE duplicate_key INT DEFAULT 0; /* Declare a duplicate key handler */ DECLARE CONTINUE HANDLER FOR 1062 SET duplicate_key = 1; /* Start the transaction context. */ START TRANSACTION; /* Create a SAVEPOINT as a recovery point. */ SAVEPOINT all_or_none; /* Insert into the first table in sequence based on inheritance of primary keys by foreign keys. */ INSERT INTO member ( member_type , account_number , credit_card_number , credit_card_type , created_by , creation_date , last_updated_by , last_update_date ) VALUES ((SELECT common_lookup_id FROM common_lookup WHERE common_lookup_context = 'MEMBER' AND common_lookup_type = pv_member_type) , pv_account_number , pv_credit_card_number ,(SELECT common_lookup_id FROM common_lookup WHERE common_lookup_context = 'MEMBER' AND common_lookup_type = pv_credit_card_type) , lv_created_by , lv_creation_date , lv_last_updated_by , lv_last_update_date ); /* Preserve the sequence by a table related variable name. */ SET member_id = last_insert_id(); /* Insert into the first table in sequence based on inheritance of primary keys by foreign keys. */ INSERT INTO contact VALUES ( null , member_id ,(SELECT common_lookup_id FROM common_lookup WHERE common_lookup_context = 'CONTACT' AND common_lookup_type = pv_contact_type) , pv_first_name , pv_middle_name , pv_last_name , lv_created_by , lv_creation_date , lv_last_updated_by , lv_last_update_date ); /* Preserve the sequence by a table related variable name. */ SET contact_id = last_insert_id(); /* Insert into the first table in sequence based on inheritance of primary keys by foreign keys. */ INSERT INTO address VALUES ( null , last_insert_id() ,(SELECT common_lookup_id FROM common_lookup WHERE common_lookup_context = 'MULTIPLE' AND common_lookup_type = pv_address_type) , pv_city , pv_state_province , pv_postal_code , lv_created_by , lv_creation_date , lv_last_updated_by , lv_last_update_date ); /* Preserve the sequence by a table related variable name. */ SET address_id = last_insert_id(); /* Insert into the first table in sequence based on inheritance of primary keys by foreign keys. */ INSERT INTO street_address VALUES ( null , last_insert_id() , pv_street_address , lv_created_by , lv_creation_date , lv_last_updated_by , lv_last_update_date ); /* Insert into the first table in sequence based on inheritance of primary keys by foreign keys. */ INSERT INTO telephone VALUES ( null , contact_id , address_id ,(SELECT common_lookup_id FROM common_lookup WHERE common_lookup_context = 'MULTIPLE' AND common_lookup_type = pv_telephone_type) , pv_country_code , pv_area_code , pv_telephone_number , lv_created_by , lv_creation_date , lv_last_updated_by , lv_last_update_date); /* This acts as an exception handling block. */ IF duplicate_key = 1 THEN /* This undoes all DML statements to this point in the procedure. */ ROLLBACK TO SAVEPOINT all_or_none; END IF; /* This commits the write when successful and is harmless otherwise. */ COMMIT; END; $$ -- Reset the standard delimiter to let the semicolon work as an execution command. DELIMITER ; |
You can then call the procedure, like:
SELECT 'CALL contact_insert() PROCEDURE 5 times' AS "Statement"; CALL contact_insert('INDIVIDUAL','R11-514-34','1111-1111-1111-1111','VISA_CARD','Goeffrey','Ward','Clinton','CUSTOMER','HOME','Provo','Utah','84606','118 South 9th East','HOME','011','801','423\-1234'); CALL contact_insert('INDIVIDUAL','R11-514-35','1111-2222-1111-1111','VISA_CARD','Wendy',null,'Moss','CUSTOMER','HOME','Provo','Utah','84606','1218 South 10th East','HOME','011','801','423-1234'); CALL contact_insert('INDIVIDUAL','R11-514-36','1111-1111-2222-1111','VISA_CARD','Simon','Jonah','Gretelz','CUSTOMER','HOME','Provo','Utah','84606','2118 South 7th East','HOME','011','801','423-1234'); CALL contact_insert('INDIVIDUAL','R11-514-37','1111-1111-1111-2222','MASTER_CARD','Elizabeth','Jane','Royal','CUSTOMER','HOME','Provo','Utah','84606','2228 South 14th East','HOME','011','801','423-1234'); CALL contact_insert('INDIVIDUAL','R11-514-38','1111-1111-3333-1111','VISA_CARD','Brian','Nathan','Smith','CUSTOMER','HOME','Spanish Fork','Utah','84606','333 North 2nd East','HOME','011','801','423-1234'); |
I hope this code complete approach helps those looking to learn how to write MySQL PSMs.
Setting SQL_MODE
In MySQL, the @@sql_mode parameter should generally use ONLY_FULL_GROUP_BY. If it doesn’t include it and you don’t have the ability to change the database parameters, you can use a MySQL PSM (Persistent Stored Module), like:
Create the set_full_group_by procedure:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | -- Drop procedure conditionally on whether it exists already. DROP PROCEDURE IF EXISTS set_full_group_by; -- Reset delimter to allow semicolons to terminate statements. DELIMITER $$ -- Create a procedure to verify and set connection parameter. CREATE PROCEDURE set_full_group_by() LANGUAGE SQL NOT DETERMINISTIC SQL SECURITY DEFINER COMMENT 'Set connection parameter when not set.' BEGIN /* Check whether full group by is set in the connection and if unset, set it in the scope of the connection. */ IF NOT EXISTS (SELECT NULL WHERE REGEXP_LIKE(@@SQL_MODE,'ONLY_FULL_GROUP_BY')) THEN SET SQL_MODE=(SELECT CONCAT(@@sql_mode,',ONLY_FULL_GROUP_BY')); END IF; END; $$ -- Reset the default delimiter. DELIMITER ; |
Run the following SQL command before you attempt the exercises in the same session scope:
CALL set_full_group_by(); |
As always, I hope this helps those looking for a solution. Naturally, you can simply use the SET command on line #21 above.
Dynamic Drop Table
I always get interesting feedback on some posts. On my test case for discovering the STR_TO_DATE function’s behavior, the comment was tragically valid. I failed to cleanup after my test case. That was correct, and I should have dropped param table and the two procedures.
While appending the drop statements is the easiest, I thought it was an opportunity to have a bit of fun and write another procedure that will cleanup test case tables within the test_month_name procedure. Here’s sample dynamic drop_table procedure that you can use in other MySQL stored procedures:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | CREATE PROCEDURE drop_table ( table_name VARCHAR(64)) BEGIN /* Declare a local variable for the SQL statement. */ DECLARE stmt VARCHAR(1024); /* Set a session variable with two parameter markers. */ SET @SQL := CONCAT('DROP TABLE ',table_name); /* Check if the constraint exists. */ IF EXISTS (SELECT NULL FROM information_schema.tables t WHERE t.table_schema = database() AND t.table_name = table_name) THEN /* Dynamically allocated and run statement. */ PREPARE stmt FROM @SQL; EXECUTE stmt; DEALLOCATE PREPARE stmt; END IF; END; $$ |
You can now put a call to the drop_table procedure in the test_month_name procedure from the earlier post. For convenience, here’s the modified test_month_name procedure with the call on line #33 right before you leave the loop and procedure:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | CREATE PROCEDURE test_month_name() BEGIN /* Declare a handler variable. */ DECLARE month_name VARCHAR(9); /* Declare a handler variable. */ DECLARE fetched INT DEFAULT 0; /* Cursors must come after variables and before event handlers. */ DECLARE month_cursor CURSOR FOR SELECT m.month_name FROM month m; /* Declare a not found record handler to close a cursor loop. */ DECLARE CONTINUE HANDLER FOR NOT FOUND SET fetched = 1; /* Open cursor and start simple loop. */ OPEN month_cursor; cursor_loop:LOOP /* Fetch a record from the cursor. */ FETCH month_cursor INTO month_name; /* Place the catch handler for no more rows found immediately after the fetch operations. */ IF fetched = 1 THEN /* Fetch the partial strings that fail to find a month. */ SELECT * FROM param; /* Conditionally drop the param table. */ CALL drop_table('param'); /* Leave the loop. */ LEAVE cursor_loop; END IF; /* Call the subfunction because stored procedures do not support nested loops. */ CALL read_string(month_name); END LOOP; END; $$ |
As always, I hope sample code examples help others solve problems.
str_to_date Function
As many know, I’ve adopted Learning SQL by Alan Beaulieu as a core reference for my database class. Chapter 7 in the book focuses on data generation, manipulation, and conversion.
The last exercise question in my check of whether they read the chapter and played with some of the discussed functions is:
- Use one or more temporal function to write a query that convert the ’29-FEB-2024′ string value into a default MySQL date format. The result should display:
+--------------------+ | mysql_default_date | +--------------------+ | 2024-02-29 | +--------------------+ 1 row in set, 1 warning (0.00 sec)
If you’re not familiar with the behavior of MySQL functions, this could look like a difficult problem to solve. If you’re risk inclined you would probably try the STR_TO_DATE function but if you’re not risk inclined the description of the %m specifier might suggest you don’t have SQL builtin to solve the problem.
I use the problem to teach the students how to solve problems in SQL queries. The first step requires putting the base ’29-FEB-2024′ string value into a mystringstrings table, like:
DROP TABLE IF EXISTS strings; CREATE TABLE strings (mystring VARCHAR(11)); SELECT 'Insert' AS statement; INSERT INTO strings (mystring) VALUES ('29-FEB-2024'); |
The next step requires creating a query with:
- A list of parameters in a Common Table Expression (CTE)
- A CASE statement to filter results in the SELECT-list
- A CROSS JOIN between the strings table and params CTE
The query would look like this resolves the comparison in the CASE statement through a case insensitive comparison:
SELECT 'Query' AS statement; WITH params AS (SELECT 'January' AS full_month UNION ALL SELECT 'February' AS full_month) SELECT s.mystring , p.full_month , CASE WHEN SUBSTR(s.mystring,4,3) = SUBSTR(p.full_month,1,3) THEN STR_TO_DATE(REPLACE(s.mystring,SUBSTR(s.mystring,4,3),p.full_month),'%d-%M-%Y') END AS converted_date FROM strings s CROSS JOIN params p; |
and return:
+-------------+------------+----------------+ | mystring | full_month | converted_date | +-------------+------------+----------------+ | 29-FEB-2024 | January | NULL | | 29-FEB-2024 | February | 2024-02-29 | +-------------+------------+----------------+ 2 rows in set (0.00 sec) |
The problem with the result set, or derived table, is the CROSS JOIN. A CROSS JOIN matches every row in one table with every row in another table or derived table from prior joins. That means you need to add a filter in the WHERE clause to ensure you only get matches between the strings and parameters, like the modified query:
WITH params AS (SELECT 'January' AS full_month UNION ALL SELECT 'February' AS full_month) SELECT s.mystring , p.full_month , CASE WHEN SUBSTR(s.mystring,4,3) = SUBSTR(p.full_month,1,3) THEN STR_TO_DATE(REPLACE(s.mystring,SUBSTR(s.mystring,4,3),p.full_month),'%d-%M-%Y') END AS converted_date FROM strings s CROSS JOIN params p WHERE SUBSTR(s.mystring,4,3) = SUBSTR(p.full_month,1,3); |
It returns a single row, like:
+-------------+------------+----------------+ | mystring | full_month | converted_date | +-------------+------------+----------------+ | 29-FEB-2024 | February | 2024-02-29 | +-------------+------------+----------------+ 1 row in set (0.00 sec) |
However, none of this is necessary because the query can be written like this:
SELECT STR_TO_DATE('29-FEB-2024','%d-%M-%Y') AS mysql_date; |
It returns:
+------------+ | mysql_date | +------------+ | 2024-02-29 | +------------+ 1 row in set (0.00 sec) |
That’s because the STR_TO_DATE() function with the %M specifier resolves all months with three or more characters. Three characters are required because both Mar and May, and June and July can only be qualified by three characters. If you provide less than three characters of the month, the function returns a null value.
Here’s a complete test case that lets you discover all the null values that may occur with two few characters:
/* Conditionally drop the table. */ DROP TABLE IF EXISTS month, param; /* Create a table. */ CREATE TABLE month ( month_name VARCHAR(9)); /* Insert into the month table. */ INSERT INTO month ( month_name ) VALUES ('January') ,('February') ,('March') ,('April') ,('May') ,('June') ,('July') ,('August') ,('September') ,('October') ,('November') ,('December'); /* Create a table. */ CREATE TABLE param ( month VARCHAR(9) , needle VARCHAR(9)); /* Conditionally drop the procedure. */ DROP PROCEDURE IF EXISTS read_string; DROP PROCEDURE IF EXISTS test_month_name; /* Reset the execution delimiter to create a stored program. */ DELIMITER $$ /* Create a procedure. */ CREATE PROCEDURE read_string(month_name VARCHAR(9)) BEGIN /* Declare a handler variable. */ DECLARE display VARCHAR(17); DECLARE evaluate VARCHAR(17); DECLARE iterator INT DEFAULT 1; DECLARE partial VARCHAR(9); /* Read the list of characters. */ character_loop:LOOP /* Print the character list. */ IF iterator > LENGTH(month_name) THEN LEAVE character_loop; END IF; /* Assign substring of month name. */ SELECT SUBSTR(month_name,1,iterator) INTO partial; SELECT CONCAT('01-',partial,'-2024') INTO evaluate; /* Print only the strings too short to identify as the month. */ IF STR_TO_DATE(evaluate,'%d-%M-%Y') IS NULL THEN INSERT INTO param ( month, needle ) VALUES ( month_name, partial ); END IF; /* Increment the counter. */ SET iterator = iterator + 1; END LOOP; END; $$ /* Create a procedure. */ CREATE PROCEDURE test_month_name() BEGIN /* Declare a handler variable. */ DECLARE month_name VARCHAR(9); /* Declare a handler variable. */ DECLARE fetched INT DEFAULT 0; /* Cursors must come after variables and before event handlers. */ DECLARE month_cursor CURSOR FOR SELECT m.month_name FROM month m; /* Declare a not found record handler to close a cursor loop. */ DECLARE CONTINUE HANDLER FOR NOT FOUND SET fetched = 1; /* Open cursor and start simple loop. */ OPEN month_cursor; cursor_loop:LOOP /* Fetch a record from the cursor. */ FETCH month_cursor INTO month_name; /* Place the catch handler for no more rows found immediately after the fetch operations. */ IF fetched = 1 THEN /* Fetch the partial strings that fail to find a month. */ SELECT * FROM param; /* Leave the loop. */ LEAVE cursor_loop; END IF; /* Call the subfunction because stored procedures do not support nested loops. */ CALL read_string(month_name); END LOOP; END; $$ /* Reset the delimter. */ DELIMITER ; CALL test_month_name(); |
It returns the list of character fragments that fail to resolve English months:
+---------+--------+ | month | needle | +---------+--------+ | January | J | | March | M | | March | Ma | | April | A | | May | M | | May | Ma | | June | J | | June | Ju | | July | J | | July | Ju | | August | A | +---------+--------+ 11 rows in set (0.02 sec) |
There are two procedures because MySQL doesn’t support nested loops and uses a single-pass parser. So, the first read_string procedure is the inner loop and the second test_month_name procedure is the outer loop.
I wrote a follow-up to this post because of a reader’s question about not cleaning up the test case. In the other post, you will find a drop_table procedure that lets you dynamically drop the param table created to store the inner loop procedure’s results.
As always, I hope this helps those looking to open the hood and check the engine.
Case Sensitive Comparison
Sometimes you hear from some new developers that MySQL only makes case insensitive string comparisons. One of my students showed me their test case that they felt proved it:
SELECT STRCMP('a','A') WHERE 'a' = 'A'; |
Naturally, it returns 0, which means:
- The values compared by the STRCMP() function makes a case insensitive comparison, and
- The WHERE clause also compares strings case insensitively.
As a teacher, you’re gratified that the student took the time to build their own use cases. However, in this case I had to explain that while he was right about the STRCMP() function and the case insensitive comparison the student used in the WHERE clause was a choice, it wasn’t the only option. The student was wrong to conclude that MySQL couldn’t make case sensitive string comparisons.
I modified his sample by adding the required BINARY keyword for a case sensitive comparison in the WHERE clause:
SELECT STRCMP('a','A') WHERE BINARY 'a' = 'A'; |
It returns an empty set, which means the binary comparison in the WHERE clause is a case sensitive comparison. Then, I explained while the STRCMP() function performs a case insensitive match, the REPLACE() function performs a case sensitive one. Then, I gave him the following expanded use case for the two functions:
SELECT STRCMP('a','A') AS test1 , REPLACE('a','A','b') AS test2 , REPLACE('a','a','b') AS test3; |
It returns:
+-------+-------+-------+ | test1 | test2 | test3 | +-------+-------+-------+ | 0 | a | b | +-------+-------+-------+ 1 row in set (0.00 sec) |
The behavior of one function may be different than another as to how it compares strings, and its the developers responsibility to make sure they understand its behavior thoroughly before they use it. The binary comparison was a win for the student since they were building a website that needed that behavior from MySQL.
As always, I hope tidbits like this save folks time using MySQL.
Read CSV with Python
In 2009, I showed an example of how to use the MySQL LOAD DATA INFILE command. Last year, I updated the details to reset the secure_file-priv privilege to use the LOAD DATA INFILE command, but you can avoid that approach with a simple Python 3 program like the one in this example. You also can use MySQL Shell’s new parallel table import feature, introduced in 8.0.17, as noted in a comment on this blog post.
The example requires creating an avenger table, avenger.csv file, a readWriteData.py Python script, run the readWriteData.py Python script, and a query that validates the insertion of the avenger.csv file’s data into the avenger table. The complete code in five steps using the sakila demonstration database:
- Creating the avenger table with the create_avenger.sql script:
-- Conditionally drop the avenger table. DROP TABLE IF EXISTS avenger; -- Create the avenger table. CREATE TABLE avenger ( avenger_id int unsigned PRIMARY KEY AUTO_INCREMENT , first_name varchar(20) , last_name varchar(20) , avenger_name varchar(20)) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
- Create the avenger.csv file with the following data:
Anthony,Stark,Iron Man Thor,Odinson,God of Thunder Steven,Rogers,Captain America Bruce,Banner,Hulk Clinton,Barton,Hawkeye Natasha,Romanoff,Black Widow Peter,Parker,Spiderman Steven,Strange,Dr. Strange Scott,Lange,Ant-man Hope,van Dyne,Wasp
- Create the readWriteFile.py Python 3 script:
# Import libraries. import csv import mysql.connector from mysql.connector import errorcode from csv import reader # Attempt the statement. # ============================================================ # Use a try-catch block to manage the connection. # ============================================================ try: # Open connection. cnx = mysql.connector.connect( user='student' , password='student' , host='127.0.0.1' , database='sakila') # Create cursor. cursor = cnx.cursor() # Open file in read mode and pass the file object to reader. with open('avenger.csv', 'r') as read_obj: csv_reader = reader(read_obj) # Declare the dynamic statement. stmt = ("INSERT INTO avenger " "(first_name, last_name, avenger_name) " "VALUES " "(%s, %s, %s)") # Iterate over each row in the csv using reader object for row in csv_reader: cursor.execute(stmt, row) # Commit the writes. cnx.commit() #close the connection to the database. cursor.close() # Handle exception and close connection. except mysql.connector.Error as e: if e.errno == errorcode.ER_ACCESS_DENIED_ERROR: print("Something is wrong with your user name or password") elif e.errno == errorcode.ER_BAD_DB_ERROR: print("Database does not exist") else: print("Error code:", e.errno) # error number print("SQLSTATE value:", e.sqlstate) # SQLSTATE value print("Error message:", e.msg) # error message # Close the connection when the try block completes. else: cnx.close()
- Run the readWriteFile.py file:
python3 readWriteFile.py
- Query the avenger table:
SELECT * FROM avenger;It returns:
+------------+------------+-----------+-----------------+ | avenger_id | first_name | last_name | avenger_name | +------------+------------+-----------+-----------------+ | 1001 | Anthony | Stark | Iron Man | | 1002 | Thor | Odinson | God of Thunder | | 1003 | Steven | Rogers | Captain America | | 1004 | Bruce | Banner | Hulk | | 1005 | Clinton | Barton | Hawkeye | | 1006 | Natasha | Romanoff | Black Widow | | 1007 | Peter | Parker | Spiderman | | 1008 | Steven | Strange | Dr. Strange | | 1009 | Scott | Lange | Ant-man | | 1010 | Hope | van Dyne | Wasp | +------------+------------+-----------+-----------------+ 10 rows in set (0.00 sec)
MySQL Query Performance
Working through our chapter on MySQL views, I wrote the query two ways to introduce the idea of SQL tuning. That’s one of the final topics before introducing JSON types.
I gave the students this query based on the Sakila sample database after explaining how to use the EXPLAIN syntax. The query only uses only inner joins, which are generally faster and more efficient than subqueries as a rule of thumb than correlated subqueries.
SELECT ctry.country AS country_name , SUM(p.amount) AS tot_payments FROM city c INNER JOIN address a ON c.city_id = a.city_id INNER JOIN customer cus ON a.address_id = cus.address_id INNER JOIN payment p ON cus.customer_id = p.customer_id INNER JOIN country ctry ON c.country_id = ctry.country_id GROUP BY ctry.country; |
It generated the following tabular explain plan output:
+----+-------------+-------+------------+--------+---------------------------+--------------------+---------+------------------------+------+----------+------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+--------+---------------------------+--------------------+---------+------------------------+------+----------+------------------------------+ | 1 | SIMPLE | cus | NULL | index | PRIMARY,idx_fk_address_id | idx_fk_address_id | 2 | NULL | 599 | 100.00 | Using index; Using temporary | | 1 | SIMPLE | a | NULL | eq_ref | PRIMARY,idx_fk_city_id | PRIMARY | 2 | sakila.cus.address_id | 1 | 100.00 | NULL | | 1 | SIMPLE | c | NULL | eq_ref | PRIMARY,idx_fk_country_id | PRIMARY | 2 | sakila.a.city_id | 1 | 100.00 | NULL | | 1 | SIMPLE | ctry | NULL | eq_ref | PRIMARY | PRIMARY | 2 | sakila.c.country_id | 1 | 100.00 | NULL | | 1 | SIMPLE | p | NULL | ref | idx_fk_customer_id | idx_fk_customer_id | 2 | sakila.cus.customer_id | 26 | 100.00 | NULL | +----+-------------+-------+------------+--------+---------------------------+--------------------+---------+------------------------+------+----------+------------------------------+ 5 rows in set, 1 warning (0.02 sec) |
Then, I used MySQL Workbench to generate the following visual explain plan:

Then, I compared it against a refactored version of the query that uses a correlated subquery in the SELECT-list. The example comes form Appendix B in Learning SQL, 3rd Edition by Alan Beaulieu.
SELECT ctry.country , (SELECT SUM(p.amount) FROM city c INNER JOIN address a ON c.city_id = a.city_id INNER JOIN customer cus ON a.address_id = cus.address_id INNER JOIN payment p ON cus.customer_id = p.customer_id WHERE c.country_id = ctry.country_id) AS tot_payments FROM country ctry; |
It generated the following tabular explain plan output:
+----+--------------------+-------+------------+------+---------------------------+--------------------+---------+------------------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+--------------------+-------+------------+------+---------------------------+--------------------+---------+------------------------+------+----------+-------------+ | 1 | PRIMARY | ctry | NULL | ALL | NULL | NULL | NULL | NULL | 109 | 100.00 | NULL | | 2 | DEPENDENT SUBQUERY | c | NULL | ref | PRIMARY,idx_fk_country_id | idx_fk_country_id | 2 | sakila.ctry.country_id | 5 | 100.00 | Using index | | 2 | DEPENDENT SUBQUERY | a | NULL | ref | PRIMARY,idx_fk_city_id | idx_fk_city_id | 2 | sakila.c.city_id | 1 | 100.00 | Using index | | 2 | DEPENDENT SUBQUERY | cus | NULL | ref | PRIMARY,idx_fk_address_id | idx_fk_address_id | 2 | sakila.a.address_id | 1 | 100.00 | Using index | | 2 | DEPENDENT SUBQUERY | p | NULL | ref | idx_fk_customer_id | idx_fk_customer_id | 2 | sakila.cus.customer_id | 26 | 100.00 | NULL | +----+--------------------+-------+------------+------+---------------------------+--------------------+---------+------------------------+------+----------+-------------+ 5 rows in set, 2 warnings (0.00 sec) |
and, MySQL Workbench generated the following visual explain plan:

The tabular explain plan identifies the better performing query to an experienced eye but the visual explain plan works better for those new to SQL tuning.
The second query performs best because it reads the least data by leveraging the indexes best. As always, I hope these examples help those looking at learning more about MySQL.
