VSCode & $PYTHONPATH
About 4 years ago, I demonstrated how to develop Python functions with a relative src directory in this old blog post. I thought it might be possible to do with VSCode. Doing a bit of research, it appeared all that was required was adding the PythonPath to VSCode’s Python settings in:
/home/student/.vscode/extensions/ms-python.python-2023.22.0/pythonFiles/.vscode/settings.json |
It contained:
{"files.exclude":{"**/__pycache__/**":true,"**/**/*.pyc":true},"python.formatting.provider":"black"} |
I added a configuration for the PYTHONPATH, as shown:
{"files.exclude":{"**/__pycache__/**":true,"**/**/*.pyc":true},"python.formatting.provider":"black","python.pythonPath": "/home/student/Lib"} |
As you can tell from the embedded VSCode Terminal output below, the PYTHONPATH is not found. You can manually enter it and retest your code successfully. There is no way to use a relative PYTHONPATH like the one you can use from an shell environment file.
This is the hello_whom5.py code:
#!/usr/bin/python # Import the basic sys library. import sys from input import parse_input # Assign command-line argument list to variable. whom = parse_input(sys.argv) # Check if string isn't empty and use dynamic input. if len(whom) > 0: # Print dynamic hello salutation. print("Hello " + whom + "!\n") else: # Print default saluation. print("Hello World!") |
This is the input.py library module:
# Parse a list and return a whitespace delimited string. def parse_input(input_list): # Assign command-line argument list to variable. cmd_list = input_list[1:] # Declare return variable. result = "" # Check whether or not their are parameters beyond the file name. if isinstance(input_list,list) and len(input_list) != 0: # Loop through the command-line argument list and print it. for element in cmd_list: if len(result) == 0: result = element else: result = result + " " + element # Return result variable as string. return result |
This is the Terminal output from VSCode:
student@student-virtual-machine:~$ /bin/python /home/student/Code/python/hello_whom5.py Traceback (most recent call last): File "/home/student/Code/python/hello_whom5.py", line 5, in <module> from input import parse_input ModuleNotFoundError: No module named 'input' student@student-virtual-machine:~$ export set PYTHONPATH=/home/student/Lib student@student-virtual-machine:~$ /bin/python /home/student/Code/python/hello_whom5.py Hello World! student@student-virtual-machine:~$ /bin/python /home/student/Code/python/hello_whom5.py Katniss Everdeen Hello Katniss Everdeen! student@student-virtual-machine:~$ |
The VSCode image for the test follows below:
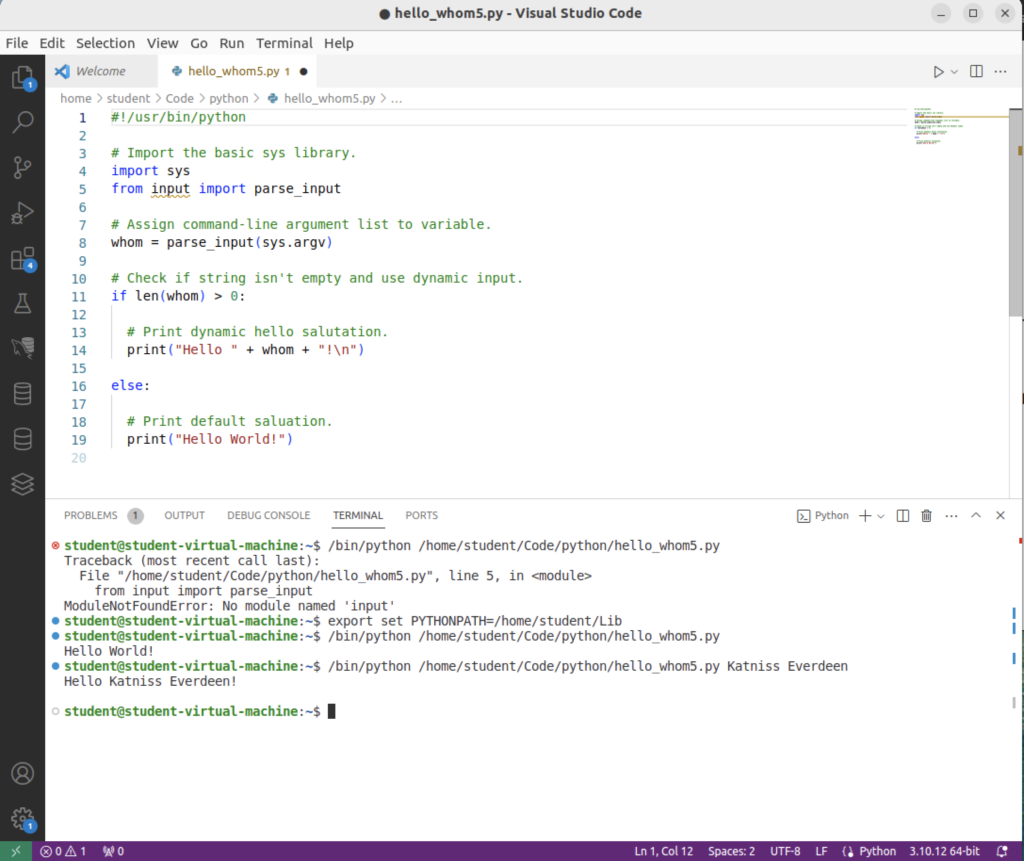
As always, I hope this helps somebody working the same issue. However, if somebody has a better solution, please let me know.
Ubuntu Next.js Install
You begin by setting up Node with its version manager. You can do this in a Terminal shell with the following command:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash |
After running that command, you should reboot your system. Then, open a new Terminal session and start NVM with this command in your home directory:
nvm install --lts |
Display detailed console log →
Installing latest LTS version. Downloading and installing node v20.11.0... Downloading https://nodejs.org/dist/v20.11.0/node-v20.11.0-linux-x64.tar.xz... ######################################################################### 100.0% Computing checksum with sha256sum Checksums matched! Now using node v20.11.0 (npm v10.2.4) Creating default alias: default -> lts/* (-> v20.11.0) |
After installing Node, create a new Next.js application to test if everything is working. Create a blog-app application with the following command in the Ubuntu bash shell session:
npx create-next-app@latest blog-app |
It produces a small console log and asks you complete interactive responses as shown:
Need to install the following packages:
create-next-app@14.0.4
Ok to proceed? (y) y
✔ Would you like to use TypeScript? … No / Yes
✔ Would you like to use ESLint? … No / Yes
✔ Would you like to use Tailwind CSS? … No / Yes
✔ Would you like to use `src/` directory? … No / Yes
✔ Would you like to use App Router? (recommended) … No / Yes
✔ Would you like to customize the default import alias (@/*)? … No / Yes
Creating a new Next.js app in /home/student/blog-app.
Display detailed console log →
Using npm. Initializing project with template: app-tw Installing dependencies: - react - react-dom - next Installing devDependencies: - typescript - @types/node - @types/react - @types/react-dom - autoprefixer - postcss - tailwindcss - eslint - eslint-config-next added 362 packages, and audited 363 packages in 25s 128 packages are looking for funding run `npm fund` for details found 0 vulnerabilities Success! Created blog-app at /home/student/blog-app npm notice npm notice New minor version of npm available! 10.2.4 -> 10.3.0 npm notice Changelog: https://github.com/npm/cli/releases/tag/v10.3.0 npm notice Run npm install -g npm@10.3.0 to update! npm notice |
Now, you can launch the application from the command-line interface (CLI):
npm run dev & |
Display detailed console log →
> blog-app@0.1.0 dev > next dev ▲ Next.js 14.0.4 - Local: http://localhost:3000 Attention: Next.js now collects completely anonymous telemetry regarding usage. This information is used to shape Next.js' roadmap and prioritize features. You can learn more, including how to opt-out if you'd not like to participate in this anonymous program, by visiting the following URL: https://nextjs.org/telemetry ✓ Ready in 1937ms ○ Compiling / ... ✓ Compiled / in 14.9s (500 modules) ✓ Compiled in 597ms (235 modules) ○ Compiling /favicon.ico ... ✓ Compiled /favicon.ico in 2.1s (505 modules) |
You can view the running application by using the following URL in a local browser:
http://localhost:3000 |
It should render the following web application:
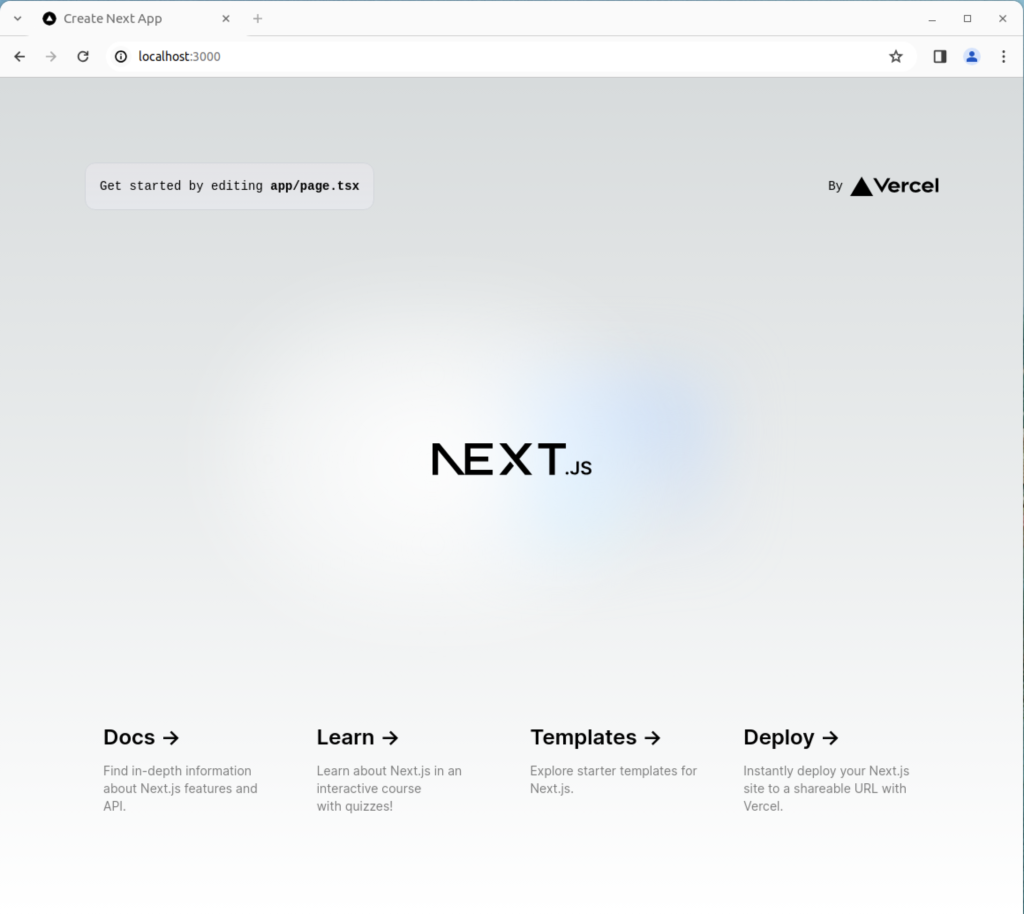
As always, I hope this helps those curious about new things and who need a set of instructions.
Ubuntu, R, RScript & RStudio
Installed R, Rscript, and RStudio on my student Ubuntu instance. You use the following command to install R a
sudo apt install -y r-base-core |
Then, you can check the version with the following command:
R --version |
It should return:
R version 4.1.2 (2021-11-01) -- "Bird Hippie" Copyright (C) 2021 The R Foundation for Statistical Computing Platform: x86_64-pc-linux-gnu (64-bit) R is free software and comes with ABSOLUTELY NO WARRANTY. You are welcome to redistribute it under the terms of the GNU General Public License versions 2 or 3. For more information about these matters see https://www.gnu.org/licenses/. |
You also can run the interactive R environment by simply typing “R” at the command-line interface (CLI). It will display the following after entering the environment, quitting the environment, and discarding the workspace:
R version 4.1.2 (2021-11-01) -- "Bird Hippie" Copyright (C) 2021 The R Foundation for Statistical Computing Platform: x86_64-pc-linux-gnu (64-bit) R is free software and comes with ABSOLUTELY NO WARRANTY. You are welcome to redistribute it under certain conditions. Type 'license()' or 'licence()' for distribution details. Natural language support but running in an English locale R is a collaborative project with many contributors. Type 'contributors()' for more information and 'citation()' on how to cite R or R packages in publications. Type 'demo()' for some demos, 'help()' for on-line help, or 'help.start()' for an HTML browser interface to help. Type 'q()' to quit R. > q() Save workspace image? [y/n/c]: n |
You can write and run a hello.r script file as follows in a Linux environment:
#!/usr/bin/Rscript
# Print a string.
print("Hello World!") |
It prints what you would expect:
[1] "Hello World!" |
The RStudio comes in two versions. One is Free and the other costs money. These are not hosted in the Ubuntu repository, and you must download them manually to apply them. You can go to RStudio web site or run the following command to download RStudio Free edition:
wget https://download1.rstudio.org/electron/jammy/amd64/rstudio-2023.12.0-369-amd64.deb |
After downloading the package, you can’t quite install RStudio until you install two likely uninstalled dependencies, which are:
libclang-dev libclang-14-dev libclang1-14 libclang-common-14-dev lib32gcc-s1 lib32stdc++6 libc6-i386 libobjc4 libobjc-11-dev libssl-dev |
Therefore, the prestep is:
sudo apt install -y libssl-dev libclang-dev libclang-14-dev libobjc-11-dev libclang1-14 libclang-common-14-dev lib32gcc-s1 lib32stdc++6 libc6-i386 libobjc4 |
Display detailed console log →
Reading package lists... Done Building dependency tree... Done Reading state information... Done Suggested packages: libssl-doc The following NEW packages will be installed: lib32gcc-s1 lib32stdc++6 libc6-i386 libclang-14-dev libclang-common-14-dev libclang-dev libclang1-14 libobjc-11-dev libobjc4 libssl-dev 0 upgraded, 10 newly installed, 0 to remove and 14 not upgraded. 1 not fully installed or removed. Need to get 44.2 MB of archives. After this operation, 382 MB of additional disk space will be used. Get:1 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libssl-dev amd64 3.0.2-0ubuntu1.12 [2,373 kB] Get:2 http://us.archive.ubuntu.com/ubuntu jammy-updates/universe amd64 libobjc4 amd64 12.3.0-1ubuntu1~22.04 [48.6 kB] Get:3 http://us.archive.ubuntu.com/ubuntu jammy-updates/universe amd64 libobjc-11-dev amd64 11.4.0-1ubuntu1~22.04 [196 kB] Get:4 http://us.archive.ubuntu.com/ubuntu jammy-updates/universe amd64 libclang1-14 amd64 1:14.0.0-1ubuntu1.1 [6,792 kB] Get:5 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libc6-i386 amd64 2.35-0ubuntu3.5 [2,837 kB] Get:6 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 lib32gcc-s1 amd64 12.3.0-1ubuntu1~22.04 [63.9 kB] Get:7 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 lib32stdc++6 amd64 12.3.0-1ubuntu1~22.04 [740 kB] Get:8 http://us.archive.ubuntu.com/ubuntu jammy-updates/universe amd64 libclang-common-14-dev amd64 1:14.0.0-1ubuntu1.1 [5,975 kB] Get:9 http://us.archive.ubuntu.com/ubuntu jammy-updates/universe amd64 libclang-14-dev amd64 1:14.0.0-1ubuntu1.1 [25.2 MB] Get:10 http://us.archive.ubuntu.com/ubuntu jammy/universe amd64 libclang-dev amd64 1:14.0-55~exp2 [3,138 B] Fetched 44.2 MB in 3s (17.1 MB/s) Selecting previously unselected package libssl-dev:amd64. (Reading database ... 242640 files and directories currently installed.) Preparing to unpack .../0-libssl-dev_3.0.2-0ubuntu1.12_amd64.deb ... Unpacking libssl-dev:amd64 (3.0.2-0ubuntu1.12) ... Selecting previously unselected package libobjc4:amd64. Preparing to unpack .../1-libobjc4_12.3.0-1ubuntu1~22.04_amd64.deb ... Unpacking libobjc4:amd64 (12.3.0-1ubuntu1~22.04) ... Selecting previously unselected package libobjc-11-dev:amd64. Preparing to unpack .../2-libobjc-11-dev_11.4.0-1ubuntu1~22.04_amd64.deb ... Unpacking libobjc-11-dev:amd64 (11.4.0-1ubuntu1~22.04) ... Selecting previously unselected package libclang1-14. Preparing to unpack .../3-libclang1-14_1%3a14.0.0-1ubuntu1.1_amd64.deb ... Unpacking libclang1-14 (1:14.0.0-1ubuntu1.1) ... Selecting previously unselected package libc6-i386. Preparing to unpack .../4-libc6-i386_2.35-0ubuntu3.5_amd64.deb ... Unpacking libc6-i386 (2.35-0ubuntu3.5) ... Selecting previously unselected package lib32gcc-s1. Preparing to unpack .../5-lib32gcc-s1_12.3.0-1ubuntu1~22.04_amd64.deb ... Unpacking lib32gcc-s1 (12.3.0-1ubuntu1~22.04) ... Selecting previously unselected package lib32stdc++6. Preparing to unpack .../6-lib32stdc++6_12.3.0-1ubuntu1~22.04_amd64.deb ... Unpacking lib32stdc++6 (12.3.0-1ubuntu1~22.04) ... Selecting previously unselected package libclang-common-14-dev. Preparing to unpack .../7-libclang-common-14-dev_1%3a14.0.0-1ubuntu1.1_amd64.deb ... Unpacking libclang-common-14-dev (1:14.0.0-1ubuntu1.1) ... Selecting previously unselected package libclang-14-dev. Preparing to unpack .../8-libclang-14-dev_1%3a14.0.0-1ubuntu1.1_amd64.deb ... Unpacking libclang-14-dev (1:14.0.0-1ubuntu1.1) ... Selecting previously unselected package libclang-dev. Preparing to unpack .../9-libclang-dev_1%3a14.0-55~exp2_amd64.deb ... Unpacking libclang-dev (1:14.0-55~exp2) ... Setting up libclang1-14 (1:14.0.0-1ubuntu1.1) ... Setting up libobjc4:amd64 (12.3.0-1ubuntu1~22.04) ... Setting up libssl-dev:amd64 (3.0.2-0ubuntu1.12) ... Setting up libc6-i386 (2.35-0ubuntu3.5) ... Setting up libobjc-11-dev:amd64 (11.4.0-1ubuntu1~22.04) ... Setting up lib32gcc-s1 (12.3.0-1ubuntu1~22.04) ... Setting up lib32stdc++6 (12.3.0-1ubuntu1~22.04) ... Setting up libclang-common-14-dev (1:14.0.0-1ubuntu1.1) ... Setting up libclang-14-dev (1:14.0.0-1ubuntu1.1) ... Setting up libclang-dev (1:14.0-55~exp2) ... Setting up rstudio (2023.12.0+369) ... Processing triggers for libc-bin (2.35-0ubuntu3.5) ... |
Then, you can install RStudio with this command from the directory where you downloaded it:
sudo dpkg -i rstudio-2023.12.0-369-amd64.deb |
Display detailed console log →
Selecting previously unselected package rstudio. (Reading database ... 239285 files and directories currently installed.) Preparing to unpack rstudio-2023.12.0-369-amd64.deb ... Unpacking rstudio (2023.12.0+369) ... Setting up rstudio (2023.12.0+369) ... Processing triggers for mailcap (3.70+nmu1ubuntu1) ... Processing triggers for gnome-menus (3.36.0-1ubuntu3) ... Processing triggers for desktop-file-utils (0.26-1ubuntu3) ... Processing triggers for hicolor-icon-theme (0.17-2) ... Processing triggers for shared-mime-info (2.1-2) ... |
After a successful installation, you can launch RStudio with the following command:
rstudio |
You will get the following console:
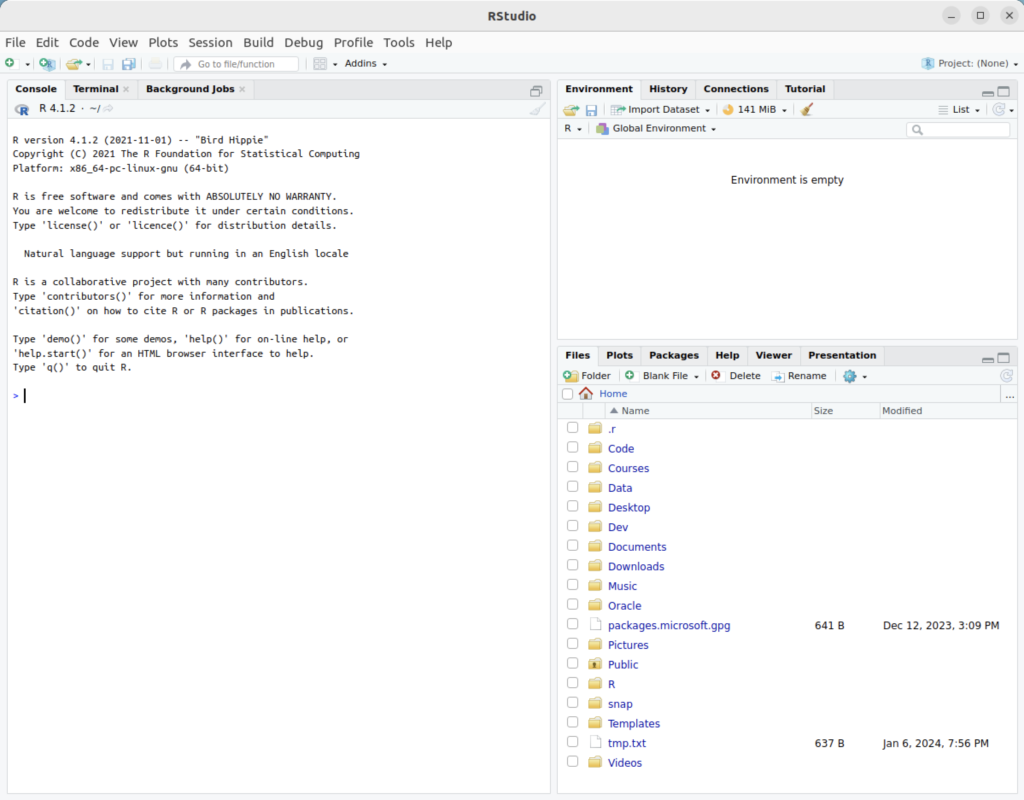
As always, I hope this helps those trying to do something that should be simple but isn’t quite simple.
Ubuntu, Perl & MySQL
Configuring Perl to work with MySQL is straight forward. While Perl is installed generally, you may need to install the libdbd-mysql-perl library.
You install it as a sudoer user with this syntax:
sudo apt install -y libdbd-mysql-perl |
Display detailed console log →
Reading package lists... Done Building dependency tree... Done Reading state information... Done The following additional packages will be installed: libmysqlclient21 The following NEW packages will be installed: libdbd-mysql-perl libmysqlclient21 0 upgraded, 2 newly installed, 0 to remove and 12 not upgraded. Need to get 1,389 kB of archives. After this operation, 7,143 kB of additional disk space will be used. Get:1 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libmysqlclient21 amd64 8.0.35-0ubuntu0.22.04.1 [1,301 kB] Get:2 http://us.archive.ubuntu.com/ubuntu jammy-updates/universe amd64 libdbd-mysql-perl amd64 4.050-5ubuntu0.22.04.1 [87.6 kB] Fetched 1,389 kB in 1s (1,213 kB/s) Selecting previously unselected package libmysqlclient21:amd64. (Reading database ... 235085 files and directories currently installed.) Preparing to unpack .../libmysqlclient21_8.0.35-0ubuntu0.22.04.1_amd64.deb ... Unpacking libmysqlclient21:amd64 (8.0.35-0ubuntu0.22.04.1) ... Selecting previously unselected package libdbd-mysql-perl:amd64. Preparing to unpack .../libdbd-mysql-perl_4.050-5ubuntu0.22.04.1_amd64.deb ... Unpacking libdbd-mysql-perl:amd64 (4.050-5ubuntu0.22.04.1) ... Setting up libmysqlclient21:amd64 (8.0.35-0ubuntu0.22.04.1) ... Setting up libdbd-mysql-perl:amd64 (4.050-5ubuntu0.22.04.1) ... Processing triggers for man-db (2.10.2-1) ... Processing triggers for libc-bin (2.35-0ubuntu3.5) ... |
You can find the Perl version with the following version.pl program:
1 2 3 4 | #!/usr/bin/perl -w # Print the version. print "Perl ".$]."\n"; |
The first line lets you call the program without prefacing the program name with perl. The first line invokes a subshell of perl by default. You just need to ensure the file has read and execute privileges to run by using the
chmod 755 version.pl |
You call it with this:
./version.pl |
It prints:
Perl 5.034000 |
The following static_query.pl Perl program uses the Perl DBI library to query and return a data set based on a static query.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | #!/usr/bin/perl -w # Use the DBI library. use DBI; use strict; use warnings; # Create a connection. my $dbh = DBI->connect("DBI:mysql:database=studentdb;host=localhost:3306" ,"student","student",{'RaiseError' => 1}); # Create SQL statement. my $sql = "SELECT i.item_title , ra.rating , cl.common_lookup_meaning FROM item i INNER JOIN common_lookup cl ON i.item_type = cl.common_lookup_id INNER JOIN rating_agency ra ON i.item_rating_id = ra.rating_agency_id WHERE i.item_title LIKE 'Harry%' AND cl.common_lookup_type = 'BLU-RAY'"; # Prepare SQL statement. my $sth = $dbh->prepare($sql); # Execute statement and read result set. $sth->execute() or die $DBI::errstr; # Read through returned rows, assign elements explicitly to match SELECT-list. while (my @row = $sth->fetchrow_array()) { my $item_title = $row[0]; my $rating = $row[1]; my $lookup_meaning = $row[2]; print "$item_title, $rating, $lookup_meaning\n"; } # Close resources. $sth->finish(); |
It returns the following rows from the sample database:
Harry Potter and the Sorcerer's Stone, PG, Blu-ray Harry Potter and the Chamber of Secrets, PG, Blu-ray Harry Potter and the Prisoner of Azkaban, PG, Blu-ray Harry Potter and the Goblet of Fire, PG-13, Blu-ray |
The following dynamic_query.pl Perl program uses the Perl DBI library to prepare a query, bind a local variable into the query, and return a data set based on a dynamic query.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | #!/usr/bin/perl -w # Use the DBI library. use DBI; use strict; use warnings; # Mimic a function parameter by using a local variable. my $item_title_in = 'Star'; # Create a connection. my $dbh = DBI->connect("DBI:mysql:database=studentdb;host=localhost:3306" ,"student","student",{'RaiseError' => 1}); # Create SQL statement. my $sql = "SELECT i.item_title , ra.rating , cl.common_lookup_meaning FROM item i INNER JOIN common_lookup cl ON i.item_type = cl.common_lookup_id INNER JOIN rating_agency ra ON i.item_rating_id = ra.rating_agency_id WHERE i.item_title LIKE CONCAT(?,'%') AND cl.common_lookup_type = 'BLU-RAY'"; # Prepare SQL statement. my $sth = $dbh->prepare($sql); # Bind a variable to first parameter in the query string. $sth->bind_param(1, $item_title_in); # Execute statement and read result set. $sth->execute() or die $DBI::errstr; # Read through returned rows, assign elements explicitly to match SELECT-list. while (my @row = $sth->fetchrow_array()) { my $item_title = $row[0]; my $rating = $row[1]; my $lookup_meaning = $row[2]; print "$item_title, $rating, $lookup_meaning\n"; } # Close resources. $sth->finish(); |
It returns the following rows from the sample database:
Star Wars II, PG, Blu-ray |
You can replace lines 34 through 40 with the following to read any number of columns into a comma-delimited row return:
34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | # Read through returned rows, assign elements explicitly to match SELECT-list. while (my @row = $sth->fetchrow_array()) { # Read through a dynamic column list for column separated display. my $result = ''; foreach(@row) { if (length($result) == 0) { $result = $_; } else { $result .= ", " . $_; } } # Print comma-separted values by row. print $result . "\n" } |
It returns the following rows from the sample database:
Star Wars II, PG, Blu-ray |
As always, I hope this helps the reader solve a problem.
Oracle 23c Free Ext Files
This is an example of how you would upload data from a flat file, or Comma Separated Value (CSV) file inside Docker Oracle Database 23c Free. It’s important to note that in the file upload you are transferring information that doesn’t have surrogate key values by leveraing joins inside a MERGE statement.
Step #1 : Create a virtual directory
You can create a virtual directory without a physical directory but it won’t work when you try to access it. Therefore, you should create the physical directory first. Assuming you’ve created the Docker Oracle Database 23c Free instance, you should put the code in subdirectories of the /opt/oracle file directory.
- Connect as the root user with the following Docker command:
docker exec -it --user root oracle23c bash
Issue the following commands as the oracle user inside the Docker container to create the necessary physical directories. You may need to refer to my earlier blog post if you haven’t setup the oracle user inside the Docker instance. While this blog post will only use the /opt/oracle/upload/text and /opt/oracle/upload/log directories, a subsequent post will demonstrate the preprocessing module for the external tables.
mkdir /opt/oracle/upload mkdir /opt/oracle/upload/text mkdir /opt/oracle/upload/log mkdir /opt/oracle/upload/preproc
- Connect to the Oracle Database 23c Free inside the container as the system user to create a c##studentrole, and do the following three things:
- Grant privileges to the c##studentrole, and grant the c##studentrole to the c##student user.
-- Create the role. CREATE ROLE c##studentrole; -- Grant privileges to the role. GRANT CREATE CLUSTER, CREATE INDEXTYPE, CREATE PROCEDURE, CREATE SEQUENCE, CREATE SESSION, CREATE TABLE, CREATE TRIGGER, CREATE TYPE, CREATE VIEW TO c##studentrole; -- Grant privileges to the user. GRANT c##studentrole TO c##student;
- As the system user, create the necessary virtual directories that map to the physical directories inside the Docker container:
CREATE DIRECTORY upload AS '/opt/oracle/upload/text'; CREATE DIRECTORY preproc AS '/opt/oracle/upload/preproc'; CREATE DIRECTORY LOG AS '/opt/oracle/upload/log';
- As the system user, grant the necessary privileges on the virtual directories to the c##studentrole role:
GRANT read ON DIRECTORY upload TO c##studentrole; GRANT read, WRITE ON DIRECTORY LOG TO c##studentrole; GRANT read, EXECUTE ON DIRECTORY preproc TO c##studentrole;
- Grant privileges to the c##studentrole, and grant the c##studentrole to the c##student user.
Step #2 : Position your CSV file in the physical directory
After creating the virtual directory, copy the following contents into a file named kingdom_import.csv in the /opt/oracle/upload/texgt directory or folder. If you attempt to do this in Windows, you need to disable Windows UAC before performing this step.
Place the following in the kingdom_import.csv file. The trailing commas aren’t too meaningful in Oracle but they’re very helpful if you use the file in MySQL. A key element in creating this files requires that you avoid trailing line returns at the bottom of the file because they’re inserted as null values. There should be no lines after the last row of data.
'Narnia',77600,'Peter the Magnificent','20-MAR-1272','19-JUN-1292','The Lion, The Witch and The Wardrobe', 'Narnia',77600,'Edmund the Just','20-MAR-1272','19-JUN-1292','The Lion, The Witch and The Wardrobe', 'Narnia',77600,'Susan the Gentle','20-MAR-1272','19-JUN-1292','The Lion, The Witch and The Wardrobe', 'Narnia',77600,'Lucy the Valiant','20-MAR-1272','19-JUN-1292','The Lion, The Witch and The Wardrobe', 'Narnia',42100,'Peter the Magnificent','12-APR-1531','31-MAY-1328','Prince Caspian', 'Narnia',42100,'Edmund the Just','12-APR-1531','31-MAY-1328','Prince Caspian', 'Narnia',42100,'Susan the Gentle','12-APR-1531','31-MAY-1328','Prince Caspian', 'Narnia',42100,'Lucy the Valiant','12-APR-1531','31-MAY-1328','Prince Caspian', 'Camelot',15200,'King Arthur','10-MAR-0631','12-DEC-0686','The Once and Future King', 'Camelot',15200,'Sir Lionel','10-MAR-0631','12-DEC-0686','The Once and Future King', 'Camelot',15200,'Sir Bors','10-MAR-0631','12-DEC-0635','The Once and Future King', 'Camelot',15200,'Sir Bors','10-MAR-0640','12-DEC-0686','The Once and Future King', 'Camelot',15200,'Sir Galahad','10-MAR-0631','12-DEC-0686','The Once and Future King', 'Camelot',15200,'Sir Gawain','10-MAR-0631','12-DEC-0686','The Once and Future King', 'Camelot',15200,'Sir Tristram','10-MAR-0631','12-DEC-0686','The Once and Future King', 'Camelot',15200,'Sir Percival','10-MAR-0631','12-DEC-0686','The Once and Future King', 'Camelot',15200,'Sir Lancelot','30-SEP-0670','12-DEC-0686','The Once and Future King', |
Step #3 : Reconnect as the student user
Disconnect and connect as the c##student user, or reconnect as the c##student user. The reconnect syntax that protects your password is:
CONNECT c##student@free |
Step #4 : Run the script that creates tables and sequences
Copy the following into a create_kingdom_upload.sql file within a directory of your choice. I use varchar as the data type because it’s an alias for varchar2 and highlights appropriately with the GeSHi formatting. Then, run it as the student account.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | -- Conditionally drop tables. DROP TABLE IF EXISTS kingdom; DROP TABLE IF EXISTS knight; DROP TABLE IF EXISTS kingdom_knight_import; -- Conditionally drop sequences. DROP SEQUENCE IF EXISTS kingdom_s1; DROP SEQUENCE IF EXISTS knight_s1; -- Create normalized kingdom table. CREATE TABLE kingdom ( kingdom_id NUMBER , kingdom_name VARCHAR(20) , population NUMBER , book VARCHAR(40)); -- Create a sequence for the kingdom table. CREATE SEQUENCE kingdom_s1; -- Create normalized knight table. CREATE TABLE knight ( knight_id NUMBER , knight_name VARCHAR(22) , kingdom_allegiance_id NUMBER , allegiance_start_date DATE , allegiance_end_date DATE , book VARCHAR(40)); -- Create a sequence for the knight table. CREATE SEQUENCE knight_s1; -- Create external import table. CREATE TABLE kingdom_knight_import ( kingdom_name VARCHAR(20) , population NUMBER , knight_name VARCHAR(22) , allegiance_start_date DATE , allegiance_end_date DATE , book VARCHAR(40)) ORGANIZATION EXTERNAL ( TYPE oracle_loader DEFAULT DIRECTORY upload ACCESS PARAMETERS ( RECORDS DELIMITED BY NEWLINE CHARACTERSET US7ASCII BADFILE 'LOG':'kingdom_import.bad' DISCARDFILE 'LOG':'kingdom_import.dis' LOGFILE 'LOG':'kingdom_import.log' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY "'" MISSING FIELD VALUES ARE NULL ) LOCATION ('kingdom_import.csv')) REJECT LIMIT UNLIMITED; |
Step #5 : Test your access to the external table
There a number of things that could go wrong with setting up an external table, such as file permissions. Before moving on to the balance of the steps, you should test what you’ve done. Run the following query from the student account to check whether or not you can access the kingdom_import.csv file.
1 2 3 4 5 6 7 8 9 10 11 12 | SET PAGESIZE 999 COL kingdom_name FORMAT A7 HEADING "Kingdom|Name" COL folks FORMAT 99999 HEADING "Folks" COL knight_name FORMAT A21 HEADING "Knight Name" COL dates FORMAT A11 HEADING "Start Date" COL source_book FORMAT A38 HEADING "Book" SELECT kingdom_name , knight_name , TO_CHAR(allegiance_start_date,'DD-MON-YYYY') || TO_CHAR(allegiance_end_date,'DD-MON-YYYY') AS dates , book FROM kingdom_knight_import; |
Step #6 : Create the upload procedure
Copy the following into a create_upload_procedure.sql file within a virtual directory of your choice. As noted above in the external table definition writes only occur in the log virtual directory. This is important because there are articles out there on the Internet that could misdirect you when you get the following error message on the upload virtual directory.
ORA-06564: Object UPLOAD does not exist or is not accessible to the user. |
By the way, you’ll only see that error if you fail to:
- Designate the procedure as AUTH_ID CURRENT, and
- Enabled SERVEROUTPUT inside the SQL*Plus command-line interface (CLI) session or inside the glogin.sql file for the Oracle Database 23c Free Docker instance.
Then, run it as the student account.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | -- Create a procedure to wrap the transaction. CREATE OR REPLACE PROCEDURE upload_kingdom AUTHID CURRENT_USER IS BEGIN -- Set save point for an all or nothing transaction. SAVEPOINT starting_point; -- Insert or update the table, which makes this rerunnable when the file hasn't been updated. MERGE INTO kingdom target USING (SELECT DISTINCT k.kingdom_id , kki.kingdom_name , kki.population , kki.book FROM kingdom_knight_import kki LEFT JOIN kingdom k ON kki.kingdom_name = k.kingdom_name AND kki.population = k.population AND kki.book = k.book) SOURCE ON (target.kingdom_id = SOURCE.kingdom_id) WHEN MATCHED THEN UPDATE SET kingdom_name = SOURCE.kingdom_name WHEN NOT MATCHED THEN INSERT VALUES ( kingdom_s1.nextval , SOURCE.kingdom_name , SOURCE.population , SOURCE.book); -- Insert or update the table, which makes this rerunnable when the file hasn't been updated. MERGE INTO knight target USING (SELECT kn.knight_id , kki.knight_name , k.kingdom_id , kki.allegiance_start_date AS start_date , kki.allegiance_end_date AS end_date , kki.book FROM kingdom_knight_import kki INNER JOIN kingdom k ON kki.kingdom_name = k.kingdom_name AND kki.population = k.population LEFT JOIN knight kn ON k.kingdom_id = kn.kingdom_allegiance_id AND kki.knight_name = kn.knight_name AND kki.allegiance_start_date = kn.allegiance_start_date AND kki.allegiance_end_date = kn.allegiance_end_date AND kki.book = kn.book) SOURCE ON (target.kingdom_allegiance_id = SOURCE.kingdom_id) WHEN MATCHED THEN UPDATE SET allegiance_start_date = SOURCE.start_date , allegiance_end_date = SOURCE.end_date , book = SOURCE.book WHEN NOT MATCHED THEN INSERT VALUES ( knight_s1.nextval , SOURCE.knight_name , SOURCE.kingdom_id , SOURCE.start_date , SOURCE.end_date , SOURCE.book); -- Save the changes. COMMIT; EXCEPTION WHEN OTHERS THEN dbms_output.put_line(SQLERRM); ROLLBACK TO starting_point; RETURN; END; / |
Step #7 : Run the upload procedure
You can run the file by calling the script above. The procedure ensures that records are inserted or updated into their respective tables.
EXECUTE upload_kingdom; |
Step #8 : Test the results of the upload procedure
You can test whether or not it worked by running the following queries.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | -- Format Oracle output. COLUMN kingdom_id FORMAT 999 HEADING "Kingdom|ID #" COLUMN kingdom_name FORMAT A14 HEADING "Kingdom|Name" COLUMN population FORMAT 999,999 HEADING "Population" COLUMN book FORMAT A40 HEADING "Source Book" -- Check the kingdom table. SELECT * FROM kingdom; -- Format Oracle output. SET PAGESIZE 999 COLUMN knight_id FORMAT 999 HEADING "Knight|ID #" COLUMN knight_name FORMAT A23 HEADING "Knight|Name" COLUMN kingdom_allegiance_id FORMAT 999 HEADING "Kingdom|ID #" COLUMN allegiance_start_date FORMAT A11 HEADING "Allegiance|Start Date" COLUMN allegiance_end_date FORMAT A11 HEADING "Allegiance|End Date" -- Check the knight table. SELECT knight_id , knight_name , kingdom_allegiance_id , TO_CHAR(allegiance_start_date,'DD-MON-YYYY') AS allegiance_start_date , TO_CHAR(allegiance_end_date,'DD-MON-YYYY') AS allegiance_end_date FROM knight; |
It should display the following information:
Kingdom Kingdom
ID # Name Population Source Book
------- -------------- ---------- ----------------------------------------
1 Narnia 42,100 Prince Caspian
2 Narnia 77,600 The Lion, The Witch and The Wardrobe
3 Camelot 15,200 The Once and Future King
Knight Knight Kingdom Allegiance Allegiance
ID # Name ID # Start Date End Date
------ ----------------------- ------- ----------- -----------
1 Peter the Magnificent 2 20-MAR-1272 19-JUN-1292
2 Edmund the Just 2 20-MAR-1272 19-JUN-1292
3 Susan the Gentle 2 20-MAR-1272 19-JUN-1292
4 Lucy the Valiant 2 20-MAR-1272 19-JUN-1292
5 Peter the Magnificent 1 12-APR-1531 31-MAY-1328
6 Edmund the Just 1 12-APR-1531 31-MAY-1328
7 Susan the Gentle 1 12-APR-1531 31-MAY-1328
8 Lucy the Valiant 1 12-APR-1531 31-MAY-1328
9 King Arthur 3 10-MAR-0631 12-DEC-0686
10 Sir Lionel 3 10-MAR-0631 12-DEC-0686
11 Sir Bors 3 10-MAR-0631 12-DEC-0635
12 Sir Bors 3 10-MAR-0640 12-DEC-0686
13 Sir Galahad 3 10-MAR-0631 12-DEC-0686
14 Sir Gawain 3 10-MAR-0631 12-DEC-0686
15 Sir Tristram 3 10-MAR-0631 12-DEC-0686
16 Sir Percival 3 10-MAR-0631 12-DEC-0686
17 Sir Lancelot 3 30-SEP-0670 12-DEC-0686 |
You can rerun the procedure to check that it doesn’t alter any information, then you could add a new knight to test the insertion portion.
Native sqlplus editing
I have to remind myself from time to time that Ubuntu is a Desktop or Workstation and by default can go missing key server software, like ssh. This became evident when I wanted to check whether I could run sqlplus from my Mac OS terminal through my Ubuntu VM and internally embedded Oracle Database 23c Free docker instance.
If like me you forgot to add it, you can add the ssh service with the following commands to your Ubuntu VM:
sudo apt update sudo apt install -y openssh-server sudo systemctl start ssh.service |
Then, you can test the installation with an ssh call to localhost, like:
ssh localhost |
You should see the following, where you need to enter the sudoer’s password to continue. Your localhost target causes an authenticity check, like:
The authenticity of host 'localhost (127.0.0.1)' can't be established. ED25519 key fingerprint is SHA256:js8knEf/lOE1rSss3u8lP4Ii634Y0CkUz+oJM5dt3w4. This key is not known by any other names Are you sure you want to continue connecting (yes/no/[fingerprint])? |
Enter yes to continue:
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes |
It will now add localhost to the list of known hosts provide standard messages, as shown below.
Warning: Permanently added 'localhost' (ED25519) to the list of known hosts. student@localhost's password: Welcome to Ubuntu 22.04.3 LTS (GNU/Linux 6.2.0-39-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Expanded Security Maintenance for Applications is not enabled. 9 updates can be applied immediately. 5 of these updates are standard security updates. To see these additional updates run: apt list --upgradable Enable ESM Apps to receive additional future security updates. See https://ubuntu.com/esm or run: sudo pro status The programs included with the Ubuntu system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. |
Having verified the installation and functionality of ssh in the Ubuntu VM. Then, I launched a Terminal session on my MacBookPro base operating system. Using the Ubuntu instance ssh and a customized Bash function, I discovered its IP address.
The following is the get_ip() user-defined function in the Ubuntu instance’s student user’s customized .bashrc file:
# Return the local instance's IP address. get_ip () { echo `hostname -I | cut -f1 -d' '` } |
In this instance, it returned:
192.168.195.155 |
With the IP address, I secured shelled into my Ubuntu sudoer student user like this:
ssh student@192.168.195.155 |
It’ll prompt you for the remote server’s student password, like:
student@192.168.195.155's password: |
After entering the correct password, I got the standard reply of a valid connection:
Welcome to Ubuntu 22.04.3 LTS (GNU/Linux 6.2.0-39-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Expanded Security Maintenance for Applications is not enabled. 9 updates can be applied immediately. 5 of these updates are standard security updates. To see these additional updates run: apt list --upgradable Enable ESM Apps to receive additional future security updates. See https://ubuntu.com/esm or run: sudo pro status Last login: Fri Jan 5 18:13:21 2024 from 127.0.0.1 |
Next, I connected to the Ubuntu Docker Oracle Database 23c Free instance with this syntax:
docker exec -it --user student oracle23c bash |
At the prompt for the Docker instance of Oracle Database 23c Free, you can type sqlplus to work directly against the Oracle Database 23c Free instance with a pluggable c##student database user.
sqlplus c##student/student SQL*Plus: Release 23.0.0.0.0 - Production on Sat Jan 6 01:38:06 2024 Version 23.3.0.23.09 Copyright (c) 1982, 2023, Oracle. All rights reserved. Last Successful login time: Sat Dec 23 2023 04:30:00 +00:00 Connected to: Oracle Database 23c Free Release 23.0.0.0.0 - Develop, Learn, and Run for Free Version 23.3.0.23.09 |
Now, I can interactively edit my files with vi in the Docker Oracle Database 23c Free directory. The following demonstrates using the sandboxed student() function from my earlier Oracle 23c Free SQL*Plus blog post and connects as a sandboxed student user in the Docker Oracle 23c Free container. The image uses a different Mac OS and different Ubuntu VM from the earlier entries in this blog post from the earlier examples.
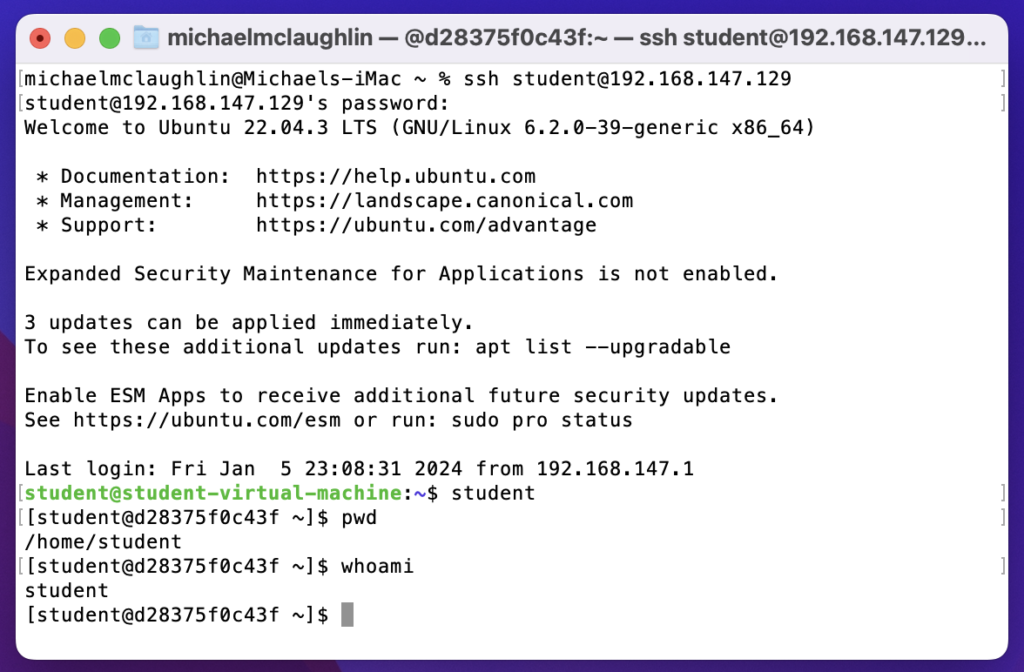
You can edit and test the files in the Docker Oracle 23c Free instance through the command-line interface (CLI). You can further automate the ssh connection by making the Ubuntu instance’s IP address a static address instead of a DCHP-assigned address; and then you can put it in the Mac OS’s /etc/hosts file which lets you resolve it by name (through file versus DNS resolution).
As always, I hope this helps those looking for a solution.
Oracle 23c Free SQL*Plus
It’s always frustrated me when using the sqlplus command-line interface (CLI) that you can’t just “up arrow” to through the history. At least, that’s the default case unless you wrap the sqlplus executable.
I like to do my development work as close to the database as possible. The delay from SQL Developer to the database or VSCode to the database is just too long. Therefore, I like the native sqlplus to be as efficient as possible. This post shows you how to install the rlwarp utility to wrap sqlplus and create a sandboxed student user for a local development account inside the Oracle 23c Free container. You should note that the Docker or Podman Container is using Oracle Unbreakable Linux 8 as it’s native OS.
You can connect to your Docker version of Oracle Database 23c Free with the following command:
docker exec -it -u root oracle23c bash |
You can’t just use dnf to install rlwrap and get it to magically install all the dependencies. That would be too easy, eh?
Attempting to do so will lock your base OS and eventually force you to kill with prejudice the hung dnf process (at least it forced me to do so). You need to determine the rlwrap dependencies and then install them first. In that process, I noticed that the which utility program wasn’t installed in the container.
Naturally, I installed the which utility first with this command:
dnf install -y which |
Display detailed console log →
Last metadata expiration check: 0:26:00 ago on Thu Dec 21 05:18:09 2023. Dependencies resolved. ================================================================================ Package Architecture Version Repository Size ================================================================================ Installing: which x86_64 2.21-20.el8 ol8_baseos_latest 50 k Transaction Summary ================================================================================ Install 1 Package Total download size: 50 k Installed size: 81 k Downloading Packages: which-2.21-20.el8.x86_64.rpm 80 kB/s | 50 kB 00:00 -------------------------------------------------------------------------------- Total 80 kB/s | 50 kB 00:00 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Installing : which-2.21-20.el8.x86_64 1/1 Running scriptlet: which-2.21-20.el8.x86_64 1/1 Verifying : which-2.21-20.el8.x86_64 1/1 Installed: which-2.21-20.el8.x86_64 Complete! |
The rlwrap dependencies are: glibc, ncurses, perl, readline, python, and git. Only the perl, python, and git are missing from the list of formal dependencies but there’s another dependency the epel-release package.
If you want to verify whether a package is installed, you can use the rpm command like this:
rpm -qa | grep package_name |
I installed the perl programming environment (a big install) with this command:
dnf install -y perl |
Display detailed console log →
Last metadata expiration check: 0:28:29 ago on Thu Dec 21 05:18:09 2023.
Dependencies resolved.
================================================================================
Package Arch Version Repository Size
================================================================================
Installing:
perl x86_64 4:5.26.3-422.el8 ol8_appstream 73 k
Installing dependencies:
dwz x86_64 0.12-10.el8 ol8_appstream 109 k
efi-srpm-macros noarch 3-3.0.1.el8 ol8_appstream 22 k
file x86_64 5.33-24.el8 ol8_baseos_latest 77 k
ghc-srpm-macros noarch 1.4.2-7.el8 ol8_appstream 9.3 k
glibc-gconv-extra x86_64 2.28-225.0.3.el8 ol8_baseos_latest 1.5 M
go-srpm-macros noarch 2-17.el8 ol8_appstream 13 k
groff-base x86_64 1.22.3-18.el8 ol8_baseos_latest 1.0 M
ocaml-srpm-macros noarch 5-4.el8 ol8_appstream 9.3 k
openblas-srpm-macros noarch 2-2.el8 ol8_appstream 7.9 k
perl-Algorithm-Diff noarch 1.1903-9.el8 ol8_baseos_latest 52 k
perl-Archive-Tar noarch 2.30-1.el8 ol8_baseos_latest 79 k
perl-Archive-Zip noarch 1.60-3.el8 ol8_appstream 108 k
perl-Attribute-Handlers noarch 0.99-422.el8 ol8_appstream 89 k
perl-B-Debug noarch 1.26-2.el8 ol8_appstream 26 k
perl-CPAN noarch 2.18-397.el8 ol8_appstream 554 k
perl-CPAN-Meta noarch 2.150010-396.el8 ol8_appstream 191 k
perl-CPAN-Meta-Requirements noarch 2.140-396.el8 ol8_appstream 37 k
perl-CPAN-Meta-YAML noarch 0.018-397.el8 ol8_appstream 34 k
perl-Carp noarch 1.42-396.el8 ol8_baseos_latest 30 k
perl-Compress-Bzip2 x86_64 2.26-6.el8 ol8_appstream 72 k
perl-Compress-Raw-Bzip2 x86_64 2.081-1.el8 ol8_baseos_latest 40 k
perl-Compress-Raw-Zlib x86_64 2.081-1.el8 ol8_baseos_latest 68 k
perl-Config-Perl-V noarch 0.30-1.el8 ol8_appstream 22 k
perl-DB_File x86_64 1.842-1.el8 ol8_appstream 83 k
perl-Data-Dumper x86_64 2.167-399.el8 ol8_baseos_latest 58 k
perl-Data-OptList noarch 0.110-6.el8 ol8_appstream 31 k
perl-Data-Section noarch 0.200007-3.el8 ol8_appstream 30 k
perl-Devel-PPPort x86_64 3.36-5.el8 ol8_appstream 118 k
perl-Devel-Peek x86_64 1.26-422.el8 ol8_appstream 94 k
perl-Devel-SelfStubber noarch 1.06-422.el8 ol8_appstream 76 k
perl-Devel-Size x86_64 0.81-2.el8 ol8_appstream 34 k
perl-Digest noarch 1.17-395.el8 ol8_baseos_latest 27 k
perl-Digest-MD5 x86_64 2.55-396.el8 ol8_baseos_latest 37 k
perl-Digest-SHA x86_64 1:6.02-1.el8 ol8_appstream 66 k
perl-Encode x86_64 4:2.97-3.el8 ol8_baseos_latest 1.5 M
perl-Encode-devel x86_64 4:2.97-3.el8 ol8_appstream 39 k
perl-Env noarch 1.04-395.el8 ol8_appstream 21 k
perl-Errno x86_64 1.28-422.el8 ol8_baseos_latest 76 k
perl-Exporter noarch 5.72-396.el8 ol8_baseos_latest 34 k
perl-ExtUtils-CBuilder noarch 1:0.280230-2.el8 ol8_appstream 48 k
perl-ExtUtils-Command noarch 1:7.34-1.el8 ol8_appstream 19 k
perl-ExtUtils-Embed noarch 1.34-422.el8 ol8_appstream 79 k
perl-ExtUtils-Install noarch 2.14-4.el8 ol8_appstream 46 k
perl-ExtUtils-MM-Utils noarch 1:7.34-1.el8 ol8_appstream 16 k
perl-ExtUtils-MakeMaker noarch 1:7.34-1.el8 ol8_appstream 300 k
perl-ExtUtils-Manifest noarch 1.70-395.el8 ol8_appstream 36 k
perl-ExtUtils-Miniperl noarch 1.06-422.el8 ol8_appstream 77 k
perl-ExtUtils-ParseXS noarch 1:3.35-2.el8 ol8_appstream 83 k
perl-File-Fetch noarch 0.56-2.el8 ol8_appstream 33 k
perl-File-HomeDir noarch 1.002-4.el8 ol8_appstream 61 k
perl-File-Path noarch 2.15-2.el8 ol8_baseos_latest 38 k
perl-File-Temp noarch 0.230.600-1.el8 ol8_baseos_latest 63 k
perl-File-Which noarch 1.22-2.el8 ol8_appstream 23 k
perl-Filter x86_64 2:1.58-2.el8 ol8_appstream 82 k
perl-Filter-Simple noarch 0.94-2.el8 ol8_appstream 29 k
perl-Getopt-Long noarch 1:2.50-4.el8 ol8_baseos_latest 63 k
perl-HTTP-Tiny noarch 0.074-2.el8 ol8_baseos_latest 57 k
perl-IO x86_64 1.38-422.el8 ol8_baseos_latest 142 k
perl-IO-Compress noarch 2.081-1.el8 ol8_baseos_latest 258 k
perl-IO-Socket-IP noarch 0.39-5.el8 ol8_baseos_latest 47 k
perl-IO-Socket-SSL noarch 2.066-4.module+el8.6.0+20623+f0897f98
ol8_appstream 298 k
perl-IO-Zlib noarch 1:1.10-422.el8 ol8_baseos_latest 81 k
perl-IPC-Cmd noarch 2:1.02-1.el8 ol8_appstream 43 k
perl-IPC-SysV x86_64 2.07-397.el8 ol8_appstream 43 k
perl-IPC-System-Simple noarch 1.25-17.el8 ol8_appstream 43 k
perl-JSON-PP noarch 1:2.97.001-3.el8 ol8_appstream 68 k
perl-Locale-Codes noarch 3.57-1.el8 ol8_appstream 310 k
perl-Locale-Maketext noarch 1.28-396.el8 ol8_appstream 99 k
perl-Locale-Maketext-Simple noarch 1:0.21-422.el8 ol8_appstream 79 k
perl-MIME-Base64 x86_64 3.15-396.el8 ol8_baseos_latest 31 k
perl-MRO-Compat noarch 0.13-4.el8 ol8_appstream 24 k
perl-Math-BigInt noarch 1:1.9998.11-7.el8 ol8_baseos_latest 196 k
perl-Math-BigInt-FastCalc x86_64 0.500.600-6.el8 ol8_appstream 27 k
perl-Math-BigRat noarch 0.2614-1.el8 ol8_appstream 40 k
perl-Math-Complex noarch 1.59-422.el8 ol8_baseos_latest 109 k
perl-Memoize noarch 1.03-422.el8 ol8_appstream 119 k
perl-Module-Build noarch 2:0.42.24-5.el8 ol8_appstream 273 k
perl-Module-CoreList noarch 1:5.20181130-1.el8 ol8_appstream 87 k
perl-Module-CoreList-tools noarch 1:5.20181130-1.el8 ol8_appstream 22 k
perl-Module-Load noarch 1:0.32-395.el8 ol8_appstream 19 k
perl-Module-Load-Conditional noarch 0.68-395.el8 ol8_appstream 24 k
perl-Module-Loaded noarch 1:0.08-422.el8 ol8_appstream 75 k
perl-Module-Metadata noarch 1.000033-395.el8 ol8_appstream 44 k
perl-Mozilla-CA noarch 20160104-7.0.1.module+el8.3.0+21136+b437fca9
ol8_appstream 15 k
perl-Net-Ping noarch 2.55-422.el8 ol8_appstream 102 k
perl-Net-SSLeay x86_64 1.88-2.module+el8.6.0+20623+f0897f98
ol8_appstream 379 k
perl-Package-Generator noarch 1.106-11.el8 ol8_appstream 27 k
perl-Params-Check noarch 1:0.38-395.el8 ol8_appstream 24 k
perl-Params-Util x86_64 1.07-22.el8 ol8_appstream 44 k
perl-PathTools x86_64 3.74-1.el8 ol8_baseos_latest 90 k
perl-Perl-OSType noarch 1.010-396.el8 ol8_appstream 29 k
perl-PerlIO-via-QuotedPrint noarch 0.08-395.el8 ol8_appstream 13 k
perl-Pod-Checker noarch 4:1.73-395.el8 ol8_appstream 33 k
perl-Pod-Escapes noarch 1:1.07-395.el8 ol8_baseos_latest 20 k
perl-Pod-Html noarch 1.22.02-422.el8 ol8_appstream 88 k
perl-Pod-Parser noarch 1.63-396.el8 ol8_appstream 108 k
perl-Pod-Perldoc noarch 3.28-396.el8 ol8_baseos_latest 88 k
perl-Pod-Simple noarch 1:3.35-395.el8 ol8_baseos_latest 213 k
perl-Pod-Usage noarch 4:1.69-395.el8 ol8_baseos_latest 34 k
perl-Scalar-List-Utils x86_64 3:1.49-2.el8 ol8_baseos_latest 68 k
perl-SelfLoader noarch 1.23-422.el8 ol8_appstream 83 k
perl-Socket x86_64 4:2.027-3.el8 ol8_baseos_latest 59 k
perl-Software-License noarch 0.103013-2.el8 ol8_appstream 137 k
perl-Storable x86_64 1:3.11-3.el8 ol8_baseos_latest 98 k
perl-Sub-Exporter noarch 0.987-15.el8 ol8_appstream 73 k
perl-Sub-Install noarch 0.928-14.el8 ol8_appstream 27 k
perl-Sys-Syslog x86_64 0.35-397.el8 ol8_appstream 50 k
perl-Term-ANSIColor noarch 4.06-396.el8 ol8_baseos_latest 46 k
perl-Term-Cap noarch 1.17-395.el8 ol8_baseos_latest 23 k
perl-Test noarch 1.30-422.el8 ol8_appstream 90 k
perl-Test-Harness noarch 1:3.42-1.el8 ol8_appstream 279 k
perl-Test-Simple noarch 1:1.302135-1.el8 ol8_appstream 516 k
perl-Text-Balanced noarch 2.03-395.el8 ol8_appstream 58 k
perl-Text-Diff noarch 1.45-2.el8 ol8_baseos_latest 45 k
perl-Text-Glob noarch 0.11-4.el8 ol8_appstream 17 k
perl-Text-ParseWords noarch 3.30-395.el8 ol8_baseos_latest 18 k
perl-Text-Tabs+Wrap noarch 2013.0523-395.el8 ol8_baseos_latest 24 k
perl-Text-Template noarch 1.51-1.el8 ol8_appstream 64 k
perl-Thread-Queue noarch 3.13-1.el8 ol8_appstream 24 k
perl-Time-HiRes x86_64 4:1.9758-2.el8 ol8_appstream 61 k
perl-Time-Local noarch 1:1.280-1.el8 ol8_baseos_latest 33 k
perl-Time-Piece x86_64 1.31-422.el8 ol8_appstream 98 k
perl-URI noarch 1.73-3.el8 ol8_baseos_latest 116 k
perl-Unicode-Collate x86_64 1.25-2.el8 ol8_appstream 686 k
perl-Unicode-Normalize x86_64 1.25-396.el8 ol8_baseos_latest 82 k
perl-autodie noarch 2.29-396.el8 ol8_appstream 98 k
perl-bignum noarch 0.49-2.el8 ol8_appstream 43 k
perl-constant noarch 1.33-396.el8 ol8_baseos_latest 25 k
perl-devel x86_64 4:5.26.3-422.el8 ol8_appstream 600 k
perl-encoding x86_64 4:2.22-3.el8 ol8_appstream 68 k
perl-experimental noarch 0.019-2.el8 ol8_appstream 24 k
perl-inc-latest noarch 2:0.500-9.el8 ol8_appstream 25 k
perl-interpreter x86_64 4:5.26.3-422.el8 ol8_baseos_latest 6.3 M
perl-libnet noarch 3.11-3.el8 ol8_baseos_latest 121 k
perl-libnetcfg noarch 4:5.26.3-422.el8 ol8_appstream 78 k
perl-libs x86_64 4:5.26.3-422.el8 ol8_baseos_latest 1.6 M
perl-local-lib noarch 2.000024-2.el8 ol8_appstream 74 k
perl-macros x86_64 4:5.26.3-422.el8 ol8_baseos_latest 72 k
perl-open noarch 1.11-422.el8 ol8_appstream 78 k
perl-parent noarch 1:0.237-1.el8 ol8_baseos_latest 20 k
perl-perlfaq noarch 5.20180605-1.el8 ol8_appstream 386 k
perl-podlators noarch 4.11-1.el8 ol8_baseos_latest 118 k
perl-srpm-macros noarch 1-25.el8 ol8_appstream 11 k
perl-threads x86_64 1:2.21-2.el8 ol8_baseos_latest 61 k
perl-threads-shared x86_64 1.58-2.el8 ol8_baseos_latest 48 k
perl-utils noarch 5.26.3-422.el8 ol8_appstream 129 k
perl-version x86_64 6:0.99.24-1.el8 ol8_appstream 67 k
python-rpm-macros noarch 3-45.el8 ol8_appstream 16 k
python-srpm-macros noarch 3-45.el8 ol8_appstream 16 k
python3-pyparsing noarch 2.1.10-7.el8 ol8_baseos_latest 142 k
python3-rpm-macros noarch 3-45.el8 ol8_appstream 15 k
qt5-srpm-macros noarch 5.15.3-1.el8 ol8_appstream 11 k
redhat-rpm-config noarch 131-1.0.1.el8 ol8_appstream 91 k
rust-srpm-macros noarch 5-2.el8 ol8_appstream 9.2 k
systemtap-sdt-devel x86_64 4.9-3.0.1.el8 ol8_appstream 88 k
zip x86_64 3.0-23.el8 ol8_baseos_latest 270 k
Installing weak dependencies:
perl-Encode-Locale noarch 1.05-10.module+el8.3.0+7692+542c56f9
ol8_appstream 22 k
perl-TermReadKey x86_64 2.37-7.el8 ol8_appstream 40 k
Enabling module streams:
perl 5.26
perl-IO-Socket-SSL 2.066
perl-libwww-perl 6.34
Transaction Summary
================================================================================
Install 159 Packages
Total download size: 25 M
Installed size: 73 M
Downloading Packages:
(1/159): file-5.33-24.el8.x86_64.rpm 163 kB/s | 77 kB 00:00
(2/159): perl-Algorithm-Diff-1.1903-9.el8.noarc 531 kB/s | 52 kB 00:00
(3/159): groff-base-1.22.3-18.el8.x86_64.rpm 1.5 MB/s | 1.0 MB 00:00
(4/159): perl-Archive-Tar-2.30-1.el8.noarch.rpm 642 kB/s | 79 kB 00:00
(5/159): perl-Carp-1.42-396.el8.noarch.rpm 449 kB/s | 30 kB 00:00
(6/159): perl-Compress-Raw-Bzip2-2.081-1.el8.x8 452 kB/s | 40 kB 00:00
(7/159): perl-Compress-Raw-Zlib-2.081-1.el8.x86 968 kB/s | 68 kB 00:00
(8/159): perl-Data-Dumper-2.167-399.el8.x86_64. 734 kB/s | 58 kB 00:00
(9/159): perl-Digest-1.17-395.el8.noarch.rpm 391 kB/s | 27 kB 00:00
(10/159): perl-Digest-MD5-2.55-396.el8.x86_64.r 481 kB/s | 37 kB 00:00
(11/159): perl-Errno-1.28-422.el8.x86_64.rpm 811 kB/s | 76 kB 00:00
(12/159): perl-Encode-2.97-3.el8.x86_64.rpm 9.4 MB/s | 1.5 MB 00:00
(13/159): perl-File-Path-2.15-2.el8.noarch.rpm 627 kB/s | 38 kB 00:00
(14/159): perl-Exporter-5.72-396.el8.noarch.rpm 466 kB/s | 34 kB 00:00
(15/159): perl-Getopt-Long-2.50-4.el8.noarch.rp 867 kB/s | 63 kB 00:00
(16/159): perl-File-Temp-0.230.600-1.el8.noarch 648 kB/s | 63 kB 00:00
(17/159): perl-HTTP-Tiny-0.074-2.el8.noarch.rpm 847 kB/s | 57 kB 00:00
(18/159): perl-IO-Compress-2.081-1.el8.noarch.r 3.5 MB/s | 258 kB 00:00
(19/159): perl-IO-1.38-422.el8.x86_64.rpm 1.2 MB/s | 142 kB 00:00
(20/159): perl-IO-Socket-IP-0.39-5.el8.noarch.r 614 kB/s | 47 kB 00:00
(21/159): perl-IO-Zlib-1.10-422.el8.noarch.rpm 881 kB/s | 81 kB 00:00
(22/159): perl-MIME-Base64-3.15-396.el8.x86_64. 425 kB/s | 31 kB 00:00
(23/159): perl-Math-BigInt-1.9998.11-7.el8.noar 1.5 MB/s | 196 kB 00:00
(24/159): perl-Math-Complex-1.59-422.el8.noarch 1.5 MB/s | 109 kB 00:00
(25/159): perl-Pod-Escapes-1.07-395.el8.noarch. 300 kB/s | 20 kB 00:00
(26/159): perl-PathTools-3.74-1.el8.x86_64.rpm 1.2 MB/s | 90 kB 00:00
(27/159): perl-Pod-Perldoc-3.28-396.el8.noarch. 1.2 MB/s | 88 kB 00:00
(28/159): perl-Pod-Simple-3.35-395.el8.noarch.r 2.2 MB/s | 213 kB 00:00
(29/159): perl-Pod-Usage-1.69-395.el8.noarch.rp 499 kB/s | 34 kB 00:00
(30/159): perl-Scalar-List-Utils-1.49-2.el8.x86 947 kB/s | 68 kB 00:00
(31/159): perl-Socket-2.027-3.el8.x86_64.rpm 864 kB/s | 59 kB 00:00
(32/159): perl-Storable-3.11-3.el8.x86_64.rpm 1.2 MB/s | 98 kB 00:00
(33/159): perl-Term-ANSIColor-4.06-396.el8.noar 677 kB/s | 46 kB 00:00
(34/159): perl-Term-Cap-1.17-395.el8.noarch.rpm 321 kB/s | 23 kB 00:00
(35/159): perl-Text-Diff-1.45-2.el8.noarch.rpm 596 kB/s | 45 kB 00:00
(36/159): perl-Text-ParseWords-3.30-395.el8.noa 257 kB/s | 18 kB 00:00
(37/159): perl-Text-Tabs+Wrap-2013.0523-395.el8 351 kB/s | 24 kB 00:00
(38/159): perl-Time-Local-1.280-1.el8.noarch.rp 440 kB/s | 33 kB 00:00
(39/159): perl-URI-1.73-3.el8.noarch.rpm 1.6 MB/s | 116 kB 00:00
(40/159): perl-Unicode-Normalize-1.25-396.el8.x 1.1 MB/s | 82 kB 00:00
(41/159): perl-constant-1.33-396.el8.noarch.rpm 395 kB/s | 25 kB 00:00
(42/159): perl-libnet-3.11-3.el8.noarch.rpm 1.8 MB/s | 121 kB 00:00
(43/159): perl-libs-5.26.3-422.el8.x86_64.rpm 13 MB/s | 1.6 MB 00:00
(44/159): perl-macros-5.26.3-422.el8.x86_64.rpm 1.1 MB/s | 72 kB 00:00
(45/159): perl-parent-0.237-1.el8.noarch.rpm 279 kB/s | 20 kB 00:00
(46/159): perl-podlators-4.11-1.el8.noarch.rpm 1.3 MB/s | 118 kB 00:00
(47/159): perl-interpreter-5.26.3-422.el8.x86_6 14 MB/s | 6.3 MB 00:00
(48/159): glibc-gconv-extra-2.28-225.0.3.el8.x8 601 kB/s | 1.5 MB 00:02
(49/159): perl-threads-2.21-2.el8.x86_64.rpm 876 kB/s | 61 kB 00:00
(50/159): perl-threads-shared-1.58-2.el8.x86_64 657 kB/s | 48 kB 00:00
(51/159): python3-pyparsing-2.1.10-7.el8.noarch 2.0 MB/s | 142 kB 00:00
(52/159): zip-3.0-23.el8.x86_64.rpm 3.7 MB/s | 270 kB 00:00
(53/159): dwz-0.12-10.el8.x86_64.rpm 1.6 MB/s | 109 kB 00:00
(54/159): efi-srpm-macros-3-3.0.1.el8.noarch.rp 350 kB/s | 22 kB 00:00
(55/159): ghc-srpm-macros-1.4.2-7.el8.noarch.rp 125 kB/s | 9.3 kB 00:00
(56/159): go-srpm-macros-2-17.el8.noarch.rpm 198 kB/s | 13 kB 00:00
(57/159): ocaml-srpm-macros-5-4.el8.noarch.rpm 154 kB/s | 9.3 kB 00:00
(58/159): openblas-srpm-macros-2-2.el8.noarch.r 116 kB/s | 7.9 kB 00:00
(59/159): perl-5.26.3-422.el8.x86_64.rpm 921 kB/s | 73 kB 00:00
(60/159): perl-Archive-Zip-1.60-3.el8.noarch.rp 1.4 MB/s | 108 kB 00:00
(61/159): perl-Attribute-Handlers-0.99-422.el8. 1.2 MB/s | 89 kB 00:00
(62/159): perl-B-Debug-1.26-2.el8.noarch.rpm 356 kB/s | 26 kB 00:00
(63/159): perl-CPAN-2.18-397.el8.noarch.rpm 5.3 MB/s | 554 kB 00:00
(64/159): perl-CPAN-Meta-2.150010-396.el8.noarc 2.3 MB/s | 191 kB 00:00
(65/159): perl-CPAN-Meta-Requirements-2.140-396 512 kB/s | 37 kB 00:00
(66/159): perl-CPAN-Meta-YAML-0.018-397.el8.noa 508 kB/s | 34 kB 00:00
(67/159): perl-Compress-Bzip2-2.26-6.el8.x86_64 990 kB/s | 72 kB 00:00
(68/159): perl-Config-Perl-V-0.30-1.el8.noarch. 337 kB/s | 22 kB 00:00
(69/159): perl-DB_File-1.842-1.el8.x86_64.rpm 1.2 MB/s | 83 kB 00:00
(70/159): perl-Data-OptList-0.110-6.el8.noarch. 457 kB/s | 31 kB 00:00
(71/159): perl-Data-Section-0.200007-3.el8.noar 423 kB/s | 30 kB 00:00
(72/159): perl-Devel-PPPort-3.36-5.el8.x86_64.r 1.6 MB/s | 118 kB 00:00
(73/159): perl-Devel-Peek-1.26-422.el8.x86_64.r 960 kB/s | 94 kB 00:00
(74/159): perl-Devel-SelfStubber-1.06-422.el8.n 831 kB/s | 76 kB 00:00
(75/159): perl-Devel-Size-0.81-2.el8.x86_64.rpm 510 kB/s | 34 kB 00:00
(76/159): perl-Digest-SHA-6.02-1.el8.x86_64.rpm 859 kB/s | 66 kB 00:00
(77/159): perl-Encode-Locale-1.05-10.module+el8 285 kB/s | 22 kB 00:00
(78/159): perl-Encode-devel-2.97-3.el8.x86_64.r 510 kB/s | 39 kB 00:00
(79/159): perl-Env-1.04-395.el8.noarch.rpm 321 kB/s | 21 kB 00:00
(80/159): perl-ExtUtils-CBuilder-0.280230-2.el8 730 kB/s | 48 kB 00:00
(81/159): perl-ExtUtils-Command-7.34-1.el8.noar 248 kB/s | 19 kB 00:00
(82/159): perl-ExtUtils-Embed-1.34-422.el8.noar 1.1 MB/s | 79 kB 00:00
(83/159): perl-ExtUtils-Install-2.14-4.el8.noar 661 kB/s | 46 kB 00:00
(84/159): perl-ExtUtils-MM-Utils-7.34-1.el8.noa 243 kB/s | 16 kB 00:00
(85/159): perl-ExtUtils-MakeMaker-7.34-1.el8.no 4.0 MB/s | 300 kB 00:00
(86/159): perl-ExtUtils-Manifest-1.70-395.el8.n 500 kB/s | 36 kB 00:00
(87/159): perl-ExtUtils-Miniperl-1.06-422.el8.n 1.1 MB/s | 77 kB 00:00
(88/159): perl-File-HomeDir-1.002-4.el8.noarch. 980 kB/s | 61 kB 00:00
(89/159): perl-File-Fetch-0.56-2.el8.noarch.rpm 483 kB/s | 33 kB 00:00
(90/159): perl-ExtUtils-ParseXS-3.35-2.el8.noar 1.1 MB/s | 83 kB 00:00
(91/159): perl-Filter-Simple-0.94-2.el8.noarch. 417 kB/s | 29 kB 00:00
(92/159): perl-File-Which-1.22-2.el8.noarch.rpm 312 kB/s | 23 kB 00:00
(93/159): perl-Filter-1.58-2.el8.x86_64.rpm 1.1 MB/s | 82 kB 00:00
(94/159): perl-IO-Socket-SSL-2.066-4.module+el8 3.6 MB/s | 298 kB 00:00
(95/159): perl-IPC-Cmd-1.02-1.el8.noarch.rpm 545 kB/s | 43 kB 00:00
(96/159): perl-IPC-SysV-2.07-397.el8.x86_64.rpm 544 kB/s | 43 kB 00:00
(97/159): perl-IPC-System-Simple-1.25-17.el8.no 535 kB/s | 43 kB 00:00
(98/159): perl-JSON-PP-2.97.001-3.el8.noarch.rp 853 kB/s | 68 kB 00:00
(99/159): perl-Locale-Codes-3.57-1.el8.noarch.r 3.7 MB/s | 310 kB 00:00
(100/159): perl-MRO-Compat-0.13-4.el8.noarch.rp 399 kB/s | 24 kB 00:00
(101/159): perl-Locale-Maketext-1.28-396.el8.no 1.4 MB/s | 99 kB 00:00
(102/159): perl-Locale-Maketext-Simple-0.21-422 1.1 MB/s | 79 kB 00:00
(103/159): perl-Math-BigInt-FastCalc-0.500.600- 371 kB/s | 27 kB 00:00
(104/159): perl-Math-BigRat-0.2614-1.el8.noarch 560 kB/s | 40 kB 00:00
(105/159): perl-Memoize-1.03-422.el8.noarch.rpm 1.6 MB/s | 119 kB 00:00
(106/159): perl-Module-Build-0.42.24-5.el8.noar 3.4 MB/s | 273 kB 00:00
(107/159): perl-Module-CoreList-tools-5.2018113 297 kB/s | 22 kB 00:00
(108/159): perl-Module-CoreList-5.20181130-1.el 1.1 MB/s | 87 kB 00:00
(109/159): perl-Module-Load-0.32-395.el8.noarch 242 kB/s | 19 kB 00:00
(110/159): perl-Module-Load-Conditional-0.68-39 316 kB/s | 24 kB 00:00
(111/159): perl-Module-Loaded-0.08-422.el8.noar 972 kB/s | 75 kB 00:00
(112/159): perl-Module-Metadata-1.000033-395.el 664 kB/s | 44 kB 00:00
(113/159): perl-Mozilla-CA-20160104-7.0.1.modul 229 kB/s | 15 kB 00:00
(114/159): perl-Net-Ping-2.55-422.el8.noarch.rp 1.5 MB/s | 102 kB 00:00
(115/159): perl-Package-Generator-1.106-11.el8. 386 kB/s | 27 kB 00:00
(116/159): perl-Params-Check-0.38-395.el8.noarc 333 kB/s | 24 kB 00:00
(117/159): perl-Net-SSLeay-1.88-2.module+el8.6. 4.4 MB/s | 379 kB 00:00
(118/159): perl-Perl-OSType-1.010-396.el8.noarc 459 kB/s | 29 kB 00:00
(119/159): perl-Params-Util-1.07-22.el8.x86_64. 656 kB/s | 44 kB 00:00
(120/159): perl-PerlIO-via-QuotedPrint-0.08-395 206 kB/s | 13 kB 00:00
(121/159): perl-Pod-Checker-1.73-395.el8.noarch 449 kB/s | 33 kB 00:00
(122/159): perl-Pod-Parser-1.63-396.el8.noarch. 1.6 MB/s | 108 kB 00:00
(123/159): perl-Pod-Html-1.22.02-422.el8.noarch 1.1 MB/s | 88 kB 00:00
(124/159): perl-SelfLoader-1.23-422.el8.noarch. 1.1 MB/s | 83 kB 00:00
(125/159): perl-Software-License-0.103013-2.el8 1.8 MB/s | 137 kB 00:00
(126/159): perl-Sub-Exporter-0.987-15.el8.noarc 1.0 MB/s | 73 kB 00:00
(127/159): perl-Sub-Install-0.928-14.el8.noarch 383 kB/s | 27 kB 00:00
(128/159): perl-Sys-Syslog-0.35-397.el8.x86_64. 734 kB/s | 50 kB 00:00
(129/159): perl-TermReadKey-2.37-7.el8.x86_64.r 536 kB/s | 40 kB 00:00
(130/159): perl-Test-1.30-422.el8.noarch.rpm 1.2 MB/s | 90 kB 00:00
(131/159): perl-Test-Harness-3.42-1.el8.noarch. 3.4 MB/s | 279 kB 00:00
(132/159): perl-Test-Simple-1.302135-1.el8.noar 5.2 MB/s | 516 kB 00:00
(133/159): perl-Text-Glob-0.11-4.el8.noarch.rpm 272 kB/s | 17 kB 00:00
(134/159): perl-Text-Balanced-2.03-395.el8.noar 807 kB/s | 58 kB 00:00
(135/159): perl-Text-Template-1.51-1.el8.noarch 841 kB/s | 64 kB 00:00
(136/159): perl-Time-HiRes-1.9758-2.el8.x86_64. 855 kB/s | 61 kB 00:00
(137/159): perl-Thread-Queue-3.13-1.el8.noarch. 319 kB/s | 24 kB 00:00
(138/159): perl-Time-Piece-1.31-422.el8.x86_64. 1.3 MB/s | 98 kB 00:00
(139/159): perl-autodie-2.29-396.el8.noarch.rpm 1.3 MB/s | 98 kB 00:00
(140/159): perl-Unicode-Collate-1.25-2.el8.x86_ 7.2 MB/s | 686 kB 00:00
(141/159): perl-bignum-0.49-2.el8.noarch.rpm 620 kB/s | 43 kB 00:00
(142/159): perl-encoding-2.22-3.el8.x86_64.rpm 934 kB/s | 68 kB 00:00
(143/159): perl-devel-5.26.3-422.el8.x86_64.rpm 6.5 MB/s | 600 kB 00:00
(144/159): perl-experimental-0.019-2.el8.noarch 327 kB/s | 24 kB 00:00
(145/159): perl-inc-latest-0.500-9.el8.noarch.r 331 kB/s | 25 kB 00:00
(146/159): perl-libnetcfg-5.26.3-422.el8.noarch 1.0 MB/s | 78 kB 00:00
(147/159): perl-local-lib-2.000024-2.el8.noarch 1.1 MB/s | 74 kB 00:00
(148/159): perl-srpm-macros-1-25.el8.noarch.rpm 157 kB/s | 11 kB 00:00
(149/159): perl-open-1.11-422.el8.noarch.rpm 1.0 MB/s | 78 kB 00:00
(150/159): perl-perlfaq-5.20180605-1.el8.noarch 4.7 MB/s | 386 kB 00:00
(151/159): perl-version-0.99.24-1.el8.x86_64.rp 1.0 MB/s | 67 kB 00:00
(152/159): perl-utils-5.26.3-422.el8.noarch.rpm 1.7 MB/s | 129 kB 00:00
(153/159): python-rpm-macros-3-45.el8.noarch.rp 219 kB/s | 16 kB 00:00
(154/159): python3-rpm-macros-3-45.el8.noarch.r 243 kB/s | 15 kB 00:00
(155/159): python-srpm-macros-3-45.el8.noarch.r 239 kB/s | 16 kB 00:00
(156/159): qt5-srpm-macros-5.15.3-1.el8.noarch. 132 kB/s | 11 kB 00:00
(157/159): rust-srpm-macros-5-2.el8.noarch.rpm 128 kB/s | 9.2 kB 00:00
(158/159): redhat-rpm-config-131-1.0.1.el8.noar 1.2 MB/s | 91 kB 00:00
(159/159): systemtap-sdt-devel-4.9-3.0.1.el8.x8 1.2 MB/s | 88 kB 00:00
--------------------------------------------------------------------------------
Total 4.6 MB/s | 25 MB 00:05
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing : 1/1
Installing : python-srpm-macros-3-45.el8.noarch 1/159
Installing : python-rpm-macros-3-45.el8.noarch 2/159
Installing : python3-rpm-macros-3-45.el8.noarch 3/159
Installing : rust-srpm-macros-5-2.el8.noarch 4/159
Installing : qt5-srpm-macros-5.15.3-1.el8.noarch 5/159
Installing : perl-srpm-macros-1-25.el8.noarch 6/159
Installing : openblas-srpm-macros-2-2.el8.noarch 7/159
Installing : ocaml-srpm-macros-5-4.el8.noarch 8/159
Installing : go-srpm-macros-2-17.el8.noarch 9/159
Installing : ghc-srpm-macros-1.4.2-7.el8.noarch 10/159
Installing : efi-srpm-macros-3-3.0.1.el8.noarch 11/159
Installing : dwz-0.12-10.el8.x86_64 12/159
Installing : zip-3.0-23.el8.x86_64 13/159
Installing : python3-pyparsing-2.1.10-7.el8.noarch 14/159
Installing : systemtap-sdt-devel-4.9-3.0.1.el8.x86_64 15/159
Installing : groff-base-1.22.3-18.el8.x86_64 16/159
Installing : perl-Digest-1.17-395.el8.noarch 17/159
Installing : perl-Digest-MD5-2.55-396.el8.x86_64 18/159
Installing : perl-Data-Dumper-2.167-399.el8.x86_64 19/159
Installing : perl-libnet-3.11-3.el8.noarch 20/159
Installing : perl-URI-1.73-3.el8.noarch 21/159
Installing : perl-Pod-Escapes-1:1.07-395.el8.noarch 22/159
Installing : perl-IO-Socket-IP-0.39-5.el8.noarch 23/159
Installing : perl-Time-Local-1:1.280-1.el8.noarch 24/159
Installing : perl-Mozilla-CA-20160104-7.0.1.module+el8.3.0+21 25/159
Installing : perl-IO-Socket-SSL-2.066-4.module+el8.6.0+20623+ 26/159
Installing : perl-Net-SSLeay-1.88-2.module+el8.6.0+20623+f089 27/159
Installing : perl-Term-ANSIColor-4.06-396.el8.noarch 28/159
Installing : perl-Term-Cap-1.17-395.el8.noarch 29/159
Installing : perl-File-Temp-0.230.600-1.el8.noarch 30/159
Installing : perl-HTTP-Tiny-0.074-2.el8.noarch 31/159
Installing : perl-Pod-Simple-1:3.35-395.el8.noarch 32/159
Installing : perl-podlators-4.11-1.el8.noarch 33/159
Installing : perl-Pod-Perldoc-3.28-396.el8.noarch 34/159
Installing : perl-Text-ParseWords-3.30-395.el8.noarch 35/159
Installing : perl-Pod-Usage-4:1.69-395.el8.noarch 36/159
Installing : perl-MIME-Base64-3.15-396.el8.x86_64 37/159
Installing : perl-Storable-1:3.11-3.el8.x86_64 38/159
Installing : perl-Getopt-Long-1:2.50-4.el8.noarch 39/159
Installing : perl-Errno-1.28-422.el8.x86_64 40/159
Installing : perl-Socket-4:2.027-3.el8.x86_64 41/159
Installing : perl-Encode-4:2.97-3.el8.x86_64 42/159
Installing : perl-Carp-1.42-396.el8.noarch 43/159
Installing : perl-Exporter-5.72-396.el8.noarch 44/159
Installing : perl-libs-4:5.26.3-422.el8.x86_64 45/159
Installing : perl-Scalar-List-Utils-3:1.49-2.el8.x86_64 46/159
Installing : perl-parent-1:0.237-1.el8.noarch 47/159
Installing : perl-macros-4:5.26.3-422.el8.x86_64 48/159
Installing : perl-Text-Tabs+Wrap-2013.0523-395.el8.noarch 49/159
Installing : perl-Unicode-Normalize-1.25-396.el8.x86_64 50/159
Installing : perl-File-Path-2.15-2.el8.noarch 51/159
Installing : perl-IO-1.38-422.el8.x86_64 52/159
Installing : perl-PathTools-3.74-1.el8.x86_64 53/159
Installing : perl-constant-1.33-396.el8.noarch 54/159
Installing : perl-threads-1:2.21-2.el8.x86_64 55/159
Installing : perl-threads-shared-1.58-2.el8.x86_64 56/159
Installing : perl-interpreter-4:5.26.3-422.el8.x86_64 57/159
Installing : perl-version-6:0.99.24-1.el8.x86_64 58/159
Installing : perl-Time-HiRes-4:1.9758-2.el8.x86_64 59/159
Installing : perl-CPAN-Meta-Requirements-2.140-396.el8.noarch 60/159
Installing : perl-ExtUtils-Manifest-1.70-395.el8.noarch 61/159
Installing : perl-ExtUtils-ParseXS-1:3.35-2.el8.noarch 62/159
Installing : perl-Test-Harness-1:3.42-1.el8.noarch 63/159
Installing : perl-Module-CoreList-1:5.20181130-1.el8.noarch 64/159
Installing : perl-Module-Metadata-1.000033-395.el8.noarch 65/159
Installing : perl-Compress-Raw-Zlib-2.081-1.el8.x86_64 66/159
Installing : perl-Filter-2:1.58-2.el8.x86_64 67/159
Installing : perl-SelfLoader-1.23-422.el8.noarch 68/159
Installing : perl-Module-Load-1:0.32-395.el8.noarch 69/159
Installing : perl-Perl-OSType-1.010-396.el8.noarch 70/159
Installing : perl-Text-Balanced-2.03-395.el8.noarch 71/159
Installing : perl-encoding-4:2.22-3.el8.x86_64 72/159
Installing : perl-Net-Ping-2.55-422.el8.noarch 73/159
Installing : perl-Compress-Raw-Bzip2-2.081-1.el8.x86_64 74/159
Installing : perl-IO-Compress-2.081-1.el8.noarch 75/159
Installing : perl-IO-Zlib-1:1.10-422.el8.noarch 76/159
Installing : perl-Math-Complex-1.59-422.el8.noarch 77/159
Installing : perl-Math-BigInt-1:1.9998.11-7.el8.noarch 78/159
Installing : perl-JSON-PP-1:2.97.001-3.el8.noarch 79/159
Installing : perl-Math-BigRat-0.2614-1.el8.noarch 80/159
Installing : perl-CPAN-Meta-YAML-0.018-397.el8.noarch 81/159
Installing : perl-CPAN-Meta-2.150010-396.el8.noarch 82/159
Installing : perl-Digest-SHA-1:6.02-1.el8.x86_64 83/159
Installing : perl-ExtUtils-Command-1:7.34-1.el8.noarch 84/159
Installing : perl-Locale-Maketext-1.28-396.el8.noarch 85/159
Installing : perl-Locale-Maketext-Simple-1:0.21-422.el8.noarc 86/159
Installing : perl-Params-Check-1:0.38-395.el8.noarch 87/159
Installing : perl-Module-Load-Conditional-0.68-395.el8.noarch 88/159
Installing : perl-Params-Util-1.07-22.el8.x86_64 89/159
Installing : perl-Pod-Html-1.22.02-422.el8.noarch 90/159
Installing : perl-Sub-Install-0.928-14.el8.noarch 91/159
Installing : perl-Data-OptList-0.110-6.el8.noarch 92/159
Installing : perl-bignum-0.49-2.el8.noarch 93/159
Installing : perl-Math-BigInt-FastCalc-0.500.600-6.el8.x86_64 94/159
Installing : perl-open-1.11-422.el8.noarch 95/159
Installing : perl-Filter-Simple-0.94-2.el8.noarch 96/159
Installing : perl-Devel-SelfStubber-1.06-422.el8.noarch 97/159
Installing : perl-Archive-Zip-1.60-3.el8.noarch 98/159
Installing : perl-Module-CoreList-tools-1:5.20181130-1.el8.no 99/159
Installing : perl-experimental-0.019-2.el8.noarch 100/159
Installing : perl-Algorithm-Diff-1.1903-9.el8.noarch 101/159
Installing : perl-Text-Diff-1.45-2.el8.noarch 102/159
Installing : perl-Archive-Tar-2.30-1.el8.noarch 103/159
Installing : perl-Attribute-Handlers-0.99-422.el8.noarch 104/159
Installing : perl-B-Debug-1.26-2.el8.noarch 105/159
Installing : perl-Compress-Bzip2-2.26-6.el8.x86_64 106/159
Installing : perl-Config-Perl-V-0.30-1.el8.noarch 107/159
Installing : perl-DB_File-1.842-1.el8.x86_64 108/159
Installing : perl-Devel-PPPort-3.36-5.el8.x86_64 109/159
Installing : perl-Devel-Size-0.81-2.el8.x86_64 110/159
Installing : perl-Encode-Locale-1.05-10.module+el8.3.0+7692+5 111/159
Installing : perl-Env-1.04-395.el8.noarch 112/159
Installing : perl-ExtUtils-MM-Utils-1:7.34-1.el8.noarch 113/159
Installing : perl-IPC-Cmd-2:1.02-1.el8.noarch 114/159
Installing : perl-File-Fetch-0.56-2.el8.noarch 115/159
Installing : perl-IPC-SysV-2.07-397.el8.x86_64 116/159
Installing : perl-IPC-System-Simple-1.25-17.el8.noarch 117/159
Installing : perl-autodie-2.29-396.el8.noarch 118/159
Installing : perl-Locale-Codes-3.57-1.el8.noarch 119/159
Installing : perl-Memoize-1.03-422.el8.noarch 120/159
Installing : perl-Module-Loaded-1:0.08-422.el8.noarch 121/159
Installing : perl-Package-Generator-1.106-11.el8.noarch 122/159
Installing : perl-Sub-Exporter-0.987-15.el8.noarch 123/159
Installing : perl-Pod-Checker-4:1.73-395.el8.noarch 124/159
Installing : perl-Pod-Parser-1.63-396.el8.noarch 125/159
Installing : perl-Sys-Syslog-0.35-397.el8.x86_64 126/159
Installing : perl-TermReadKey-2.37-7.el8.x86_64 127/159
Installing : perl-Test-1.30-422.el8.noarch 128/159
Installing : perl-Test-Simple-1:1.302135-1.el8.noarch 129/159
Installing : perl-Text-Glob-0.11-4.el8.noarch 130/159
Installing : perl-Text-Template-1.51-1.el8.noarch 131/159
Installing : perl-Time-Piece-1.31-422.el8.x86_64 132/159
Installing : perl-Unicode-Collate-1.25-2.el8.x86_64 133/159
Installing : perl-local-lib-2.000024-2.el8.noarch 134/159
Installing : perl-utils-5.26.3-422.el8.noarch 135/159
Installing : perl-Thread-Queue-3.13-1.el8.noarch 136/159
Installing : perl-File-Which-1.22-2.el8.noarch 137/159
Installing : perl-File-HomeDir-1.002-4.el8.noarch 138/159
Installing : perl-Devel-Peek-1.26-422.el8.x86_64 139/159
Installing : perl-MRO-Compat-0.13-4.el8.noarch 140/159
Installing : perl-Data-Section-0.200007-3.el8.noarch 141/159
Installing : perl-Software-License-0.103013-2.el8.noarch 142/159
Installing : perl-PerlIO-via-QuotedPrint-0.08-395.el8.noarch 143/159
Installing : perl-perlfaq-5.20180605-1.el8.noarch 144/159
Installing : glibc-gconv-extra-2.28-225.0.3.el8.x86_64 145/159
Running scriptlet: glibc-gconv-extra-2.28-225.0.3.el8.x86_64 145/159
Installing : file-5.33-24.el8.x86_64 146/159
Installing : redhat-rpm-config-131-1.0.1.el8.noarch 147/159
Installing : perl-ExtUtils-Install-2.14-4.el8.noarch 148/159
Installing : perl-devel-4:5.26.3-422.el8.x86_64 149/159
Installing : perl-ExtUtils-MakeMaker-1:7.34-1.el8.noarch 150/159
Installing : perl-ExtUtils-CBuilder-1:0.280230-2.el8.noarch 151/159
Installing : perl-ExtUtils-Embed-1.34-422.el8.noarch 152/159
Installing : perl-ExtUtils-Miniperl-1.06-422.el8.noarch 153/159
Installing : perl-libnetcfg-4:5.26.3-422.el8.noarch 154/159
Installing : perl-Encode-devel-4:2.97-3.el8.x86_64 155/159
Installing : perl-inc-latest-2:0.500-9.el8.noarch 156/159
Installing : perl-Module-Build-2:0.42.24-5.el8.noarch 157/159
Installing : perl-CPAN-2.18-397.el8.noarch 158/159
Installing : perl-4:5.26.3-422.el8.x86_64 159/159
Running scriptlet: perl-4:5.26.3-422.el8.x86_64 159/159
Verifying : file-5.33-24.el8.x86_64 1/159
Verifying : glibc-gconv-extra-2.28-225.0.3.el8.x86_64 2/159
Verifying : groff-base-1.22.3-18.el8.x86_64 3/159
Verifying : perl-Algorithm-Diff-1.1903-9.el8.noarch 4/159
Verifying : perl-Archive-Tar-2.30-1.el8.noarch 5/159
Verifying : perl-Carp-1.42-396.el8.noarch 6/159
Verifying : perl-Compress-Raw-Bzip2-2.081-1.el8.x86_64 7/159
Verifying : perl-Compress-Raw-Zlib-2.081-1.el8.x86_64 8/159
Verifying : perl-Data-Dumper-2.167-399.el8.x86_64 9/159
Verifying : perl-Digest-1.17-395.el8.noarch 10/159
Verifying : perl-Digest-MD5-2.55-396.el8.x86_64 11/159
Verifying : perl-Encode-4:2.97-3.el8.x86_64 12/159
Verifying : perl-Errno-1.28-422.el8.x86_64 13/159
Verifying : perl-Exporter-5.72-396.el8.noarch 14/159
Verifying : perl-File-Path-2.15-2.el8.noarch 15/159
Verifying : perl-File-Temp-0.230.600-1.el8.noarch 16/159
Verifying : perl-Getopt-Long-1:2.50-4.el8.noarch 17/159
Verifying : perl-HTTP-Tiny-0.074-2.el8.noarch 18/159
Verifying : perl-IO-1.38-422.el8.x86_64 19/159
Verifying : perl-IO-Compress-2.081-1.el8.noarch 20/159
Verifying : perl-IO-Socket-IP-0.39-5.el8.noarch 21/159
Verifying : perl-IO-Zlib-1:1.10-422.el8.noarch 22/159
Verifying : perl-MIME-Base64-3.15-396.el8.x86_64 23/159
Verifying : perl-Math-BigInt-1:1.9998.11-7.el8.noarch 24/159
Verifying : perl-Math-Complex-1.59-422.el8.noarch 25/159
Verifying : perl-PathTools-3.74-1.el8.x86_64 26/159
Verifying : perl-Pod-Escapes-1:1.07-395.el8.noarch 27/159
Verifying : perl-Pod-Perldoc-3.28-396.el8.noarch 28/159
Verifying : perl-Pod-Simple-1:3.35-395.el8.noarch 29/159
Verifying : perl-Pod-Usage-4:1.69-395.el8.noarch 30/159
Verifying : perl-Scalar-List-Utils-3:1.49-2.el8.x86_64 31/159
Verifying : perl-Socket-4:2.027-3.el8.x86_64 32/159
Verifying : perl-Storable-1:3.11-3.el8.x86_64 33/159
Verifying : perl-Term-ANSIColor-4.06-396.el8.noarch 34/159
Verifying : perl-Term-Cap-1.17-395.el8.noarch 35/159
Verifying : perl-Text-Diff-1.45-2.el8.noarch 36/159
Verifying : perl-Text-ParseWords-3.30-395.el8.noarch 37/159
Verifying : perl-Text-Tabs+Wrap-2013.0523-395.el8.noarch 38/159
Verifying : perl-Time-Local-1:1.280-1.el8.noarch 39/159
Verifying : perl-URI-1.73-3.el8.noarch 40/159
Verifying : perl-Unicode-Normalize-1.25-396.el8.x86_64 41/159
Verifying : perl-constant-1.33-396.el8.noarch 42/159
Verifying : perl-interpreter-4:5.26.3-422.el8.x86_64 43/159
Verifying : perl-libnet-3.11-3.el8.noarch 44/159
Verifying : perl-libs-4:5.26.3-422.el8.x86_64 45/159
Verifying : perl-macros-4:5.26.3-422.el8.x86_64 46/159
Verifying : perl-parent-1:0.237-1.el8.noarch 47/159
Verifying : perl-podlators-4.11-1.el8.noarch 48/159
Verifying : perl-threads-1:2.21-2.el8.x86_64 49/159
Verifying : perl-threads-shared-1.58-2.el8.x86_64 50/159
Verifying : python3-pyparsing-2.1.10-7.el8.noarch 51/159
Verifying : zip-3.0-23.el8.x86_64 52/159
Verifying : dwz-0.12-10.el8.x86_64 53/159
Verifying : efi-srpm-macros-3-3.0.1.el8.noarch 54/159
Verifying : ghc-srpm-macros-1.4.2-7.el8.noarch 55/159
Verifying : go-srpm-macros-2-17.el8.noarch 56/159
Verifying : ocaml-srpm-macros-5-4.el8.noarch 57/159
Verifying : openblas-srpm-macros-2-2.el8.noarch 58/159
Verifying : perl-4:5.26.3-422.el8.x86_64 59/159
Verifying : perl-Archive-Zip-1.60-3.el8.noarch 60/159
Verifying : perl-Attribute-Handlers-0.99-422.el8.noarch 61/159
Verifying : perl-B-Debug-1.26-2.el8.noarch 62/159
Verifying : perl-CPAN-2.18-397.el8.noarch 63/159
Verifying : perl-CPAN-Meta-2.150010-396.el8.noarch 64/159
Verifying : perl-CPAN-Meta-Requirements-2.140-396.el8.noarch 65/159
Verifying : perl-CPAN-Meta-YAML-0.018-397.el8.noarch 66/159
Verifying : perl-Compress-Bzip2-2.26-6.el8.x86_64 67/159
Verifying : perl-Config-Perl-V-0.30-1.el8.noarch 68/159
Verifying : perl-DB_File-1.842-1.el8.x86_64 69/159
Verifying : perl-Data-OptList-0.110-6.el8.noarch 70/159
Verifying : perl-Data-Section-0.200007-3.el8.noarch 71/159
Verifying : perl-Devel-PPPort-3.36-5.el8.x86_64 72/159
Verifying : perl-Devel-Peek-1.26-422.el8.x86_64 73/159
Verifying : perl-Devel-SelfStubber-1.06-422.el8.noarch 74/159
Verifying : perl-Devel-Size-0.81-2.el8.x86_64 75/159
Verifying : perl-Digest-SHA-1:6.02-1.el8.x86_64 76/159
Verifying : perl-Encode-Locale-1.05-10.module+el8.3.0+7692+5 77/159
Verifying : perl-Encode-devel-4:2.97-3.el8.x86_64 78/159
Verifying : perl-Env-1.04-395.el8.noarch 79/159
Verifying : perl-ExtUtils-CBuilder-1:0.280230-2.el8.noarch 80/159
Verifying : perl-ExtUtils-Command-1:7.34-1.el8.noarch 81/159
Verifying : perl-ExtUtils-Embed-1.34-422.el8.noarch 82/159
Verifying : perl-ExtUtils-Install-2.14-4.el8.noarch 83/159
Verifying : perl-ExtUtils-MM-Utils-1:7.34-1.el8.noarch 84/159
Verifying : perl-ExtUtils-MakeMaker-1:7.34-1.el8.noarch 85/159
Verifying : perl-ExtUtils-Manifest-1.70-395.el8.noarch 86/159
Verifying : perl-ExtUtils-Miniperl-1.06-422.el8.noarch 87/159
Verifying : perl-ExtUtils-ParseXS-1:3.35-2.el8.noarch 88/159
Verifying : perl-File-Fetch-0.56-2.el8.noarch 89/159
Verifying : perl-File-HomeDir-1.002-4.el8.noarch 90/159
Verifying : perl-File-Which-1.22-2.el8.noarch 91/159
Verifying : perl-Filter-2:1.58-2.el8.x86_64 92/159
Verifying : perl-Filter-Simple-0.94-2.el8.noarch 93/159
Verifying : perl-IO-Socket-SSL-2.066-4.module+el8.6.0+20623+ 94/159
Verifying : perl-IPC-Cmd-2:1.02-1.el8.noarch 95/159
Verifying : perl-IPC-SysV-2.07-397.el8.x86_64 96/159
Verifying : perl-IPC-System-Simple-1.25-17.el8.noarch 97/159
Verifying : perl-JSON-PP-1:2.97.001-3.el8.noarch 98/159
Verifying : perl-Locale-Codes-3.57-1.el8.noarch 99/159
Verifying : perl-Locale-Maketext-1.28-396.el8.noarch 100/159
Verifying : perl-Locale-Maketext-Simple-1:0.21-422.el8.noarc 101/159
Verifying : perl-MRO-Compat-0.13-4.el8.noarch 102/159
Verifying : perl-Math-BigInt-FastCalc-0.500.600-6.el8.x86_64 103/159
Verifying : perl-Math-BigRat-0.2614-1.el8.noarch 104/159
Verifying : perl-Memoize-1.03-422.el8.noarch 105/159
Verifying : perl-Module-Build-2:0.42.24-5.el8.noarch 106/159
Verifying : perl-Module-CoreList-1:5.20181130-1.el8.noarch 107/159
Verifying : perl-Module-CoreList-tools-1:5.20181130-1.el8.no 108/159
Verifying : perl-Module-Load-1:0.32-395.el8.noarch 109/159
Verifying : perl-Module-Load-Conditional-0.68-395.el8.noarch 110/159
Verifying : perl-Module-Loaded-1:0.08-422.el8.noarch 111/159
Verifying : perl-Module-Metadata-1.000033-395.el8.noarch 112/159
Verifying : perl-Mozilla-CA-20160104-7.0.1.module+el8.3.0+21 113/159
Verifying : perl-Net-Ping-2.55-422.el8.noarch 114/159
Verifying : perl-Net-SSLeay-1.88-2.module+el8.6.0+20623+f089 115/159
Verifying : perl-Package-Generator-1.106-11.el8.noarch 116/159
Verifying : perl-Params-Check-1:0.38-395.el8.noarch 117/159
Verifying : perl-Params-Util-1.07-22.el8.x86_64 118/159
Verifying : perl-Perl-OSType-1.010-396.el8.noarch 119/159
Verifying : perl-PerlIO-via-QuotedPrint-0.08-395.el8.noarch 120/159
Verifying : perl-Pod-Checker-4:1.73-395.el8.noarch 121/159
Verifying : perl-Pod-Html-1.22.02-422.el8.noarch 122/159
Verifying : perl-Pod-Parser-1.63-396.el8.noarch 123/159
Verifying : perl-SelfLoader-1.23-422.el8.noarch 124/159
Verifying : perl-Software-License-0.103013-2.el8.noarch 125/159
Verifying : perl-Sub-Exporter-0.987-15.el8.noarch 126/159
Verifying : perl-Sub-Install-0.928-14.el8.noarch 127/159
Verifying : perl-Sys-Syslog-0.35-397.el8.x86_64 128/159
Verifying : perl-TermReadKey-2.37-7.el8.x86_64 129/159
Verifying : perl-Test-1.30-422.el8.noarch 130/159
Verifying : perl-Test-Harness-1:3.42-1.el8.noarch 131/159
Verifying : perl-Test-Simple-1:1.302135-1.el8.noarch 132/159
Verifying : perl-Text-Balanced-2.03-395.el8.noarch 133/159
Verifying : perl-Text-Glob-0.11-4.el8.noarch 134/159
Verifying : perl-Text-Template-1.51-1.el8.noarch 135/159
Verifying : perl-Thread-Queue-3.13-1.el8.noarch 136/159
Verifying : perl-Time-HiRes-4:1.9758-2.el8.x86_64 137/159
Verifying : perl-Time-Piece-1.31-422.el8.x86_64 138/159
Verifying : perl-Unicode-Collate-1.25-2.el8.x86_64 139/159
Verifying : perl-autodie-2.29-396.el8.noarch 140/159
Verifying : perl-bignum-0.49-2.el8.noarch 141/159
Verifying : perl-devel-4:5.26.3-422.el8.x86_64 142/159
Verifying : perl-encoding-4:2.22-3.el8.x86_64 143/159
Verifying : perl-experimental-0.019-2.el8.noarch 144/159
Verifying : perl-inc-latest-2:0.500-9.el8.noarch 145/159
Verifying : perl-libnetcfg-4:5.26.3-422.el8.noarch 146/159
Verifying : perl-local-lib-2.000024-2.el8.noarch 147/159
Verifying : perl-open-1.11-422.el8.noarch 148/159
Verifying : perl-perlfaq-5.20180605-1.el8.noarch 149/159
Verifying : perl-srpm-macros-1-25.el8.noarch 150/159
Verifying : perl-utils-5.26.3-422.el8.noarch 151/159
Verifying : perl-version-6:0.99.24-1.el8.x86_64 152/159
Verifying : python-rpm-macros-3-45.el8.noarch 153/159
Verifying : python-srpm-macros-3-45.el8.noarch 154/159
Verifying : python3-rpm-macros-3-45.el8.noarch 155/159
Verifying : qt5-srpm-macros-5.15.3-1.el8.noarch 156/159
Verifying : redhat-rpm-config-131-1.0.1.el8.noarch 157/159
Verifying : rust-srpm-macros-5-2.el8.noarch 158/159
Verifying : systemtap-sdt-devel-4.9-3.0.1.el8.x86_64 159/159
Installed:
dwz-0.12-10.el8.x86_64
efi-srpm-macros-3-3.0.1.el8.noarch
file-5.33-24.el8.x86_64
ghc-srpm-macros-1.4.2-7.el8.noarch
glibc-gconv-extra-2.28-225.0.3.el8.x86_64
go-srpm-macros-2-17.el8.noarch
groff-base-1.22.3-18.el8.x86_64
ocaml-srpm-macros-5-4.el8.noarch
openblas-srpm-macros-2-2.el8.noarch
perl-4:5.26.3-422.el8.x86_64
perl-Algorithm-Diff-1.1903-9.el8.noarch
perl-Archive-Tar-2.30-1.el8.noarch
perl-Archive-Zip-1.60-3.el8.noarch
perl-Attribute-Handlers-0.99-422.el8.noarch
perl-B-Debug-1.26-2.el8.noarch
perl-CPAN-2.18-397.el8.noarch
perl-CPAN-Meta-2.150010-396.el8.noarch
perl-CPAN-Meta-Requirements-2.140-396.el8.noarch
perl-CPAN-Meta-YAML-0.018-397.el8.noarch
perl-Carp-1.42-396.el8.noarch
perl-Compress-Bzip2-2.26-6.el8.x86_64
perl-Compress-Raw-Bzip2-2.081-1.el8.x86_64
perl-Compress-Raw-Zlib-2.081-1.el8.x86_64
perl-Config-Perl-V-0.30-1.el8.noarch
perl-DB_File-1.842-1.el8.x86_64
perl-Data-Dumper-2.167-399.el8.x86_64
perl-Data-OptList-0.110-6.el8.noarch
perl-Data-Section-0.200007-3.el8.noarch
perl-Devel-PPPort-3.36-5.el8.x86_64
perl-Devel-Peek-1.26-422.el8.x86_64
perl-Devel-SelfStubber-1.06-422.el8.noarch
perl-Devel-Size-0.81-2.el8.x86_64
perl-Digest-1.17-395.el8.noarch
perl-Digest-MD5-2.55-396.el8.x86_64
perl-Digest-SHA-1:6.02-1.el8.x86_64
perl-Encode-4:2.97-3.el8.x86_64
perl-Encode-Locale-1.05-10.module+el8.3.0+7692+542c56f9.noarch
perl-Encode-devel-4:2.97-3.el8.x86_64
perl-Env-1.04-395.el8.noarch
perl-Errno-1.28-422.el8.x86_64
perl-Exporter-5.72-396.el8.noarch
perl-ExtUtils-CBuilder-1:0.280230-2.el8.noarch
perl-ExtUtils-Command-1:7.34-1.el8.noarch
perl-ExtUtils-Embed-1.34-422.el8.noarch
perl-ExtUtils-Install-2.14-4.el8.noarch
perl-ExtUtils-MM-Utils-1:7.34-1.el8.noarch
perl-ExtUtils-MakeMaker-1:7.34-1.el8.noarch
perl-ExtUtils-Manifest-1.70-395.el8.noarch
perl-ExtUtils-Miniperl-1.06-422.el8.noarch
perl-ExtUtils-ParseXS-1:3.35-2.el8.noarch
perl-File-Fetch-0.56-2.el8.noarch
perl-File-HomeDir-1.002-4.el8.noarch
perl-File-Path-2.15-2.el8.noarch
perl-File-Temp-0.230.600-1.el8.noarch
perl-File-Which-1.22-2.el8.noarch
perl-Filter-2:1.58-2.el8.x86_64
perl-Filter-Simple-0.94-2.el8.noarch
perl-Getopt-Long-1:2.50-4.el8.noarch
perl-HTTP-Tiny-0.074-2.el8.noarch
perl-IO-1.38-422.el8.x86_64
perl-IO-Compress-2.081-1.el8.noarch
perl-IO-Socket-IP-0.39-5.el8.noarch
perl-IO-Socket-SSL-2.066-4.module+el8.6.0+20623+f0897f98.noarch
perl-IO-Zlib-1:1.10-422.el8.noarch
perl-IPC-Cmd-2:1.02-1.el8.noarch
perl-IPC-SysV-2.07-397.el8.x86_64
perl-IPC-System-Simple-1.25-17.el8.noarch
perl-JSON-PP-1:2.97.001-3.el8.noarch
perl-Locale-Codes-3.57-1.el8.noarch
perl-Locale-Maketext-1.28-396.el8.noarch
perl-Locale-Maketext-Simple-1:0.21-422.el8.noarch
perl-MIME-Base64-3.15-396.el8.x86_64
perl-MRO-Compat-0.13-4.el8.noarch
perl-Math-BigInt-1:1.9998.11-7.el8.noarch
perl-Math-BigInt-FastCalc-0.500.600-6.el8.x86_64
perl-Math-BigRat-0.2614-1.el8.noarch
perl-Math-Complex-1.59-422.el8.noarch
perl-Memoize-1.03-422.el8.noarch
perl-Module-Build-2:0.42.24-5.el8.noarch
perl-Module-CoreList-1:5.20181130-1.el8.noarch
perl-Module-CoreList-tools-1:5.20181130-1.el8.noarch
perl-Module-Load-1:0.32-395.el8.noarch
perl-Module-Load-Conditional-0.68-395.el8.noarch
perl-Module-Loaded-1:0.08-422.el8.noarch
perl-Module-Metadata-1.000033-395.el8.noarch
perl-Mozilla-CA-20160104-7.0.1.module+el8.3.0+21136+b437fca9.noarch
perl-Net-Ping-2.55-422.el8.noarch
perl-Net-SSLeay-1.88-2.module+el8.6.0+20623+f0897f98.x86_64
perl-Package-Generator-1.106-11.el8.noarch
perl-Params-Check-1:0.38-395.el8.noarch
perl-Params-Util-1.07-22.el8.x86_64
perl-PathTools-3.74-1.el8.x86_64
perl-Perl-OSType-1.010-396.el8.noarch
perl-PerlIO-via-QuotedPrint-0.08-395.el8.noarch
perl-Pod-Checker-4:1.73-395.el8.noarch
perl-Pod-Escapes-1:1.07-395.el8.noarch
perl-Pod-Html-1.22.02-422.el8.noarch
perl-Pod-Parser-1.63-396.el8.noarch
perl-Pod-Perldoc-3.28-396.el8.noarch
perl-Pod-Simple-1:3.35-395.el8.noarch
perl-Pod-Usage-4:1.69-395.el8.noarch
perl-Scalar-List-Utils-3:1.49-2.el8.x86_64
perl-SelfLoader-1.23-422.el8.noarch
perl-Socket-4:2.027-3.el8.x86_64
perl-Software-License-0.103013-2.el8.noarch
perl-Storable-1:3.11-3.el8.x86_64
perl-Sub-Exporter-0.987-15.el8.noarch
perl-Sub-Install-0.928-14.el8.noarch
perl-Sys-Syslog-0.35-397.el8.x86_64
perl-Term-ANSIColor-4.06-396.el8.noarch
perl-Term-Cap-1.17-395.el8.noarch
perl-TermReadKey-2.37-7.el8.x86_64
perl-Test-1.30-422.el8.noarch
perl-Test-Harness-1:3.42-1.el8.noarch
perl-Test-Simple-1:1.302135-1.el8.noarch
perl-Text-Balanced-2.03-395.el8.noarch
perl-Text-Diff-1.45-2.el8.noarch
perl-Text-Glob-0.11-4.el8.noarch
perl-Text-ParseWords-3.30-395.el8.noarch
perl-Text-Tabs+Wrap-2013.0523-395.el8.noarch
perl-Text-Template-1.51-1.el8.noarch
perl-Thread-Queue-3.13-1.el8.noarch
perl-Time-HiRes-4:1.9758-2.el8.x86_64
perl-Time-Local-1:1.280-1.el8.noarch
perl-Time-Piece-1.31-422.el8.x86_64
perl-URI-1.73-3.el8.noarch
perl-Unicode-Collate-1.25-2.el8.x86_64
perl-Unicode-Normalize-1.25-396.el8.x86_64
perl-autodie-2.29-396.el8.noarch
perl-bignum-0.49-2.el8.noarch
perl-constant-1.33-396.el8.noarch
perl-devel-4:5.26.3-422.el8.x86_64
perl-encoding-4:2.22-3.el8.x86_64
perl-experimental-0.019-2.el8.noarch
perl-inc-latest-2:0.500-9.el8.noarch
perl-interpreter-4:5.26.3-422.el8.x86_64
perl-libnet-3.11-3.el8.noarch
perl-libnetcfg-4:5.26.3-422.el8.noarch
perl-libs-4:5.26.3-422.el8.x86_64
perl-local-lib-2.000024-2.el8.noarch
perl-macros-4:5.26.3-422.el8.x86_64
perl-open-1.11-422.el8.noarch
perl-parent-1:0.237-1.el8.noarch
perl-perlfaq-5.20180605-1.el8.noarch
perl-podlators-4.11-1.el8.noarch
perl-srpm-macros-1-25.el8.noarch
perl-threads-1:2.21-2.el8.x86_64
perl-threads-shared-1.58-2.el8.x86_64
perl-utils-5.26.3-422.el8.noarch
perl-version-6:0.99.24-1.el8.x86_64
python-rpm-macros-3-45.el8.noarch
python-srpm-macros-3-45.el8.noarch
python3-pyparsing-2.1.10-7.el8.noarch
python3-rpm-macros-3-45.el8.noarch
qt5-srpm-macros-5.15.3-1.el8.noarch
redhat-rpm-config-131-1.0.1.el8.noarch
rust-srpm-macros-5-2.el8.noarch
systemtap-sdt-devel-4.9-3.0.1.el8.x86_64
zip-3.0-23.el8.x86_64
Complete! |
I installed the python3 with this command:
dnf install -y python3 |
Display detailed console log →
Last metadata expiration check: 0:31:49 ago on Thu Dec 21 05:18:09 2023.
Dependencies resolved.
================================================================================
Package Arch Version Repository Size
================================================================================
Installing:
python36 x86_64 3.6.8-38.module+el8.9.0+90104+968a3e84
ol8_appstream 18 k
Installing dependencies:
platform-python-pip noarch 9.0.3-23.el8 ol8_baseos_latest 1.6 M
python3-pip noarch 9.0.3-23.el8 ol8_appstream 20 k
python3-setuptools noarch 39.2.0-7.el8 ol8_baseos_latest 163 k
Enabling module streams:
python36 3.6
Transaction Summary
================================================================================
Install 4 Packages
Total download size: 1.8 M
Installed size: 7.0 M
Downloading Packages:
(1/4): python3-pip-9.0.3-23.el8.noarch.rpm 61 kB/s | 20 kB 00:00
(2/4): python36-3.6.8-38.module+el8.9.0+90104+9 229 kB/s | 18 kB 00:00
(3/4): python3-setuptools-39.2.0-7.el8.noarch.r 335 kB/s | 163 kB 00:00
(4/4): platform-python-pip-9.0.3-23.el8.noarch. 1.9 MB/s | 1.6 MB 00:00
--------------------------------------------------------------------------------
Total 2.2 MB/s | 1.8 MB 00:00
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing : 1/1
Installing : python3-setuptools-39.2.0-7.el8.noarch 1/4
Installing : platform-python-pip-9.0.3-23.el8.noarch 2/4
Installing : python36-3.6.8-38.module+el8.9.0+90104+968a3e84.x86_ 3/4
Running scriptlet: python36-3.6.8-38.module+el8.9.0+90104+968a3e84.x86_ 3/4
Installing : python3-pip-9.0.3-23.el8.noarch 4/4
Running scriptlet: python3-pip-9.0.3-23.el8.noarch 4/4
Verifying : platform-python-pip-9.0.3-23.el8.noarch 1/4
Verifying : python3-setuptools-39.2.0-7.el8.noarch 2/4
Verifying : python3-pip-9.0.3-23.el8.noarch 3/4
Verifying : python36-3.6.8-38.module+el8.9.0+90104+968a3e84.x86_ 4/4
Installed:
platform-python-pip-9.0.3-23.el8.noarch
python3-pip-9.0.3-23.el8.noarch
python3-setuptools-39.2.0-7.el8.noarch
python36-3.6.8-38.module+el8.9.0+90104+968a3e84.x86_64
Complete! |
I installed the git module with this command:
dnf install -y git |
Display detailed console log →
Last metadata expiration check: 0:33:00 ago on Thu Dec 21 05:18:09 2023. Dependencies resolved. ================================================================================ Package Arch Version Repository Size ================================================================================ Installing: git x86_64 2.39.3-1.el8_8 ol8_appstream 104 k Installing dependencies: emacs-filesystem noarch 1:26.1-11.el8 ol8_baseos_latest 70 k git-core x86_64 2.39.3-1.el8_8 ol8_appstream 11 M git-core-doc noarch 2.39.3-1.el8_8 ol8_appstream 3.0 M less x86_64 530-1.el8 ol8_baseos_latest 164 k perl-Error noarch 1:0.17025-2.el8 ol8_appstream 46 k perl-Git noarch 2.39.3-1.el8_8 ol8_appstream 79 k Transaction Summary ================================================================================ Install 7 Packages Total download size: 14 M Installed size: 45 M Downloading Packages: (1/7): git-2.39.3-1.el8_8.x86_64.rpm 233 kB/s | 104 kB 00:00 (2/7): emacs-filesystem-26.1-11.el8.noarch.rpm 155 kB/s | 70 kB 00:00 (3/7): less-530-1.el8.x86_64.rpm 309 kB/s | 164 kB 00:00 (4/7): perl-Error-0.17025-2.el8.noarch.rpm 519 kB/s | 46 kB 00:00 (5/7): perl-Git-2.39.3-1.el8_8.noarch.rpm 722 kB/s | 79 kB 00:00 (6/7): git-core-doc-2.39.3-1.el8_8.noarch.rpm 5.1 MB/s | 3.0 MB 00:00 (7/7): git-core-2.39.3-1.el8_8.x86_64.rpm 12 MB/s | 11 MB 00:00 -------------------------------------------------------------------------------- Total 11 MB/s | 14 MB 00:01 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Installing : perl-Error-1:0.17025-2.el8.noarch 1/7 Installing : less-530-1.el8.x86_64 2/7 Installing : git-core-2.39.3-1.el8_8.x86_64 3/7 Installing : git-core-doc-2.39.3-1.el8_8.noarch 4/7 Installing : emacs-filesystem-1:26.1-11.el8.noarch 5/7 Installing : perl-Git-2.39.3-1.el8_8.noarch 6/7 Installing : git-2.39.3-1.el8_8.x86_64 7/7 Running scriptlet: git-2.39.3-1.el8_8.x86_64 7/7 Verifying : emacs-filesystem-1:26.1-11.el8.noarch 1/7 Verifying : less-530-1.el8.x86_64 2/7 Verifying : git-2.39.3-1.el8_8.x86_64 3/7 Verifying : git-core-2.39.3-1.el8_8.x86_64 4/7 Verifying : git-core-doc-2.39.3-1.el8_8.noarch 5/7 Verifying : perl-Error-1:0.17025-2.el8.noarch 6/7 Verifying : perl-Git-2.39.3-1.el8_8.noarch 7/7 Installed: emacs-filesystem-1:26.1-11.el8.noarch git-2.39.3-1.el8_8.x86_64 git-core-2.39.3-1.el8_8.x86_64 git-core-doc-2.39.3-1.el8_8.noarch less-530-1.el8.x86_64 perl-Error-1:0.17025-2.el8.noarch perl-Git-2.39.3-1.el8_8.noarch Complete! |
I installed the epel-release container with this command:
dnf install -y epel-release |
Display detailed console log →
Last metadata expiration check: 0:40:34 ago on Thu Dec 21 05:18:09 2023. Dependencies resolved. ================================================================================ Package Arch Version Repository Size ================================================================================ Installing: oracle-epel-release-el8 x86_64 1.0-5.el8 ol8_baseos_latest 15 k Transaction Summary ================================================================================ Install 1 Package Total download size: 15 k Installed size: 18 k Downloading Packages: oracle-epel-release-el8-1.0-5.el8.x86_64.rpm 49 kB/s | 15 kB 00:00 -------------------------------------------------------------------------------- Total 49 kB/s | 15 kB 00:00 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Installing : oracle-epel-release-el8-1.0-5.el8.x86_64 1/1 Verifying : oracle-epel-release-el8-1.0-5.el8.x86_64 1/1 Installed: oracle-epel-release-el8-1.0-5.el8.x86_64 Complete! |
After installing all of these, you’re now ready to install the core rlwrap utility program. Like the other installations, you use:
dnf install -y rlwrap |
Display detailed console log →
Oracle Linux 8 EPEL Packages for Development (x 15 MB/s | 58 MB 00:03 Oracle Linux 8 EPEL Modular Packages for Develo 404 kB/s | 322 kB 00:00 Dependencies resolved. ================================================================================ Package Arch Version Repository Size ================================================================================ Installing: rlwrap x86_64 0.46.1-1.el8 ol8_developer_EPEL 140 k Installing dependencies: perl-File-Slurp noarch 9999.19-19.el8 ol8_appstream 47 k Transaction Summary ================================================================================ Install 2 Packages Total download size: 186 k Installed size: 426 k Downloading Packages: (1/2): perl-File-Slurp-9999.19-19.el8.noarch.rp 94 kB/s | 47 kB 00:00 (2/2): rlwrap-0.46.1-1.el8.x86_64.rpm 242 kB/s | 140 kB 00:00 -------------------------------------------------------------------------------- Total 321 kB/s | 186 kB 00:00 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Installing : perl-File-Slurp-9999.19-19.el8.noarch 1/2 Installing : rlwrap-0.46.1-1.el8.x86_64 2/2 Running scriptlet: rlwrap-0.46.1-1.el8.x86_64 2/2 Verifying : rlwrap-0.46.1-1.el8.x86_64 1/2 Verifying : perl-File-Slurp-9999.19-19.el8.noarch 2/2 Installed: perl-File-Slurp-9999.19-19.el8.noarch rlwrap-0.46.1-1.el8.x86_64 Complete! |
At this point, you need to create a sandboxed user account for the Docker instance because as a developer using the root user for simple tasks is a bad idea. While you could do this with a Docker command, the Oracle 23c Free edition raised a lock on the /etc/group file when I tried it. Naturally, that’s not a problem because you can connect as the root user with this syntax:
docker exec -it -u root oracle23c bash |
As the root user, create a student account as a developer account in the Oracle 23c Free container:
useradd -u 501 -g dba -G users -d /home/student -s /bin/bash/ -c "Student" -n student |
You’ll be unable to leverage the tnsnames.ora file unless you alter the prior command to replace dba with oinstall or add the following command:
usermod -a -G oinstall student |
Exit the Oracle 23c Free container as the root user and reconnect as the student user with this syntax:
docker exec -it --user student oracle23c bash |
While you’re connected as the root user, you should create an upload directory as a subdirectory of the $ORACLE_BASE directory. The $ORACLE_BASE directory in the Oracle Database 23c Free Docker image is the /opt/oracle directory.
You should use the following syntax to create the upload directory and change its permission to that of the Oracle Database 23c Free installation (for a future blog post on developing external table deployment on the Docker image):
mkdir /opt/oracle chown -R oracle:install /opt/oracle/upload |
You also can add the following student function to the Ubuntu student user’s .bashrc file. It means all you need to type to connect to the Oracle Database 23c Free Docker instance is “student“. I like shortcuts like this one, which let you leverage one-line Python commands.
student () { # Discover the fully qualified program name. path=`which docker 2>/dev/null` file='' # Parse the program name from the path. if [ -n ${path} ]; then file=${path##/*/} fi # Wrap when there is a file and it is rewrap. if [ -n ${file} ] && [[ ${file} = "docker" ]]; then python -c "import subprocess; subprocess.run(['docker exec -it --user student oracle23c bash'], shell=True)" else echo "Docker is unavailable: Install the docker package." fi } |
Open a Ubuntu Terminal shell and type a student function name to connect to the Docker Oracle Database 23c Free instance where you can now test things like external tables with the SQL*Plus command line without installing it on the Ubuntu local operating system.
student@student-virtual-machine:~$ student [student@d28375f0c43f ~]$ sqlplus c##student/student@free SQL*Plus: Release 23.0.0.0.0 - Production on Wed Jan 3 02:14:22 2024 Version 23.3.0.23.09 Copyright (c) 1982, 2023, Oracle. All rights reserved. Last Successful login time: Wed Jan 03 2024 01:56:44 +00:00 Connected to: Oracle Database 23c Free Release 23.0.0.0.0 - Develop, Learn, and Run for Free Version 23.3.0.23.09 SQL> |
Then, I added this sqlplus function to the /home/student/.bashrc file, which is owned by the student user. However, I also added the instruction to change to the student user’s home directory because the Oracle 23c Free container will connect you to the /home/oracle directory by default. I also added the default long list (ll) alias to the .bashrc file.
sqlplus () { # Discover the fully qualified program name. path=`which rlwrap 2>/dev/null` file='' # Parse the program name from the path. if [ -n ${path} ]; then file=${path##/*/} fi; # Wrap when there is a file and it is rewrap. if [ -n ${file} ] && [[ ${file} = "rlwrap" ]]; then rlwrap sqlplus "${@}" else echo "Command-line history unavailable: Install the rlwrap package." $ORACLE_HOME/bin/sqlplus "${@}" fi } # Change to the user's home directory. cd ${HOME} # Create a long list alias: alias ll='ls -l --color=auto' |
After you’ve configured your student user, you can configure the oracle user account to work like a regular server. Exit the Docker Oracle Database 23c Free as the student user, then connect as the root user with this command:
docker exec -it -u root oracle23c bash |
As the root user you can become the oracle user with the following command:
su - oracle |
Now, add the following .bashrc shell in the /home/oracle directory:
# The oracle user's .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # User specific environment if ! [[ "$PATH" =~ "$HOME/.local/bin:$HOME/bin:" ]] then PATH="$HOME/.local/bin:$HOME/bin:$PATH" fi export PATH # Uncomment the following line if you don't like systemctl's auto-paging feature: # export SYSTEMD_PAGER= # User specific aliases and functions export ORACLE_SID=FREE export ORACLE_BASE=/opt/oracle export ORACLE_HOME=/opt/oracle/product/23c/dbhomeFree export PATH=$PATH:/$ORACLE_HOME/bin # Change to the user's home directory. cd ${HOME} # Create a long list alias: alias ll='ls -l --color=auto' sqlplus () { # Discover the fully qualified program name. path=`which rlwrap 2>/dev/null` file='' # Parse the program name from the path. if [ -n ${path} ]; then file=${path##/*/} fi; # Wrap when there is a file and it is rewrap. if [ -n ${file} ] && [[ ${file} = "rlwrap" ]]; then rlwrap sqlplus "${@}" else echo "Command-line history unavailable: Install the rlwrap package." $ORACLE_HOME/bin/sqlplus "${@}" fi } |
You need to manually source the .bashrc for the oracle user because it’s not an externally available user. Use this syntax to connect as the internal user:
sqlplus / as sysdba |
It’ll display:
SQL*Plus: RELEASE 23.0.0.0.0 - Production ON Wed Jan 3 07:08:11 2024 Version 23.3.0.23.09 Copyright (c) 1982, 2023, Oracle. ALL rights reserved. Connected TO: Oracle DATABASE 23c Free RELEASE 23.0.0.0.0 - Develop, Learn, AND Run FOR Free Version 23.3.0.23.09 SQL> |
After all this, I can now click the “up arrow” to edit any of the sqlplus command history. If you like to work inside sqlplus natively, this should help you.
Ubuntu DaaS VM
Completed the build of my new Ubuntu Virtual Machine (VM) with Oracle 23c installed in a Docker instance, and MySQL and PostgreSQL installed locally. The VM image also provides a LAMP stack with Apache2, PHP 8.1 with MySQLi and PDO modules. Since the original post, I’ve added a number of items to support our program courses and the Data Science degrees.
There are lots of tricks and techniques in the blog associated with creating the build. I took the background photograph of Chapel Bridge early on Sunday morning August 30, 1987 in Lucerne Switzerland (with a Canon A1 and ASA 64 slide film that subsequently digitized well).
Next step: roll it out into an AWS image for the students to use for their courses.
Related blog posts:
- Installing and configuring Apache2 and PHP 8.1 on Ubuntu 22.04
- Installing and configuring Docker on Ubuntu 22.04
- Installing and configuring MySQL 8 on Ubuntu 22.04
- Installing Oracle Database 23c Free in a Docker container with space allocation techniques
- Installing and configuring PostgreSQL on Ubuntu 22.04
- Installing and configuring pgAdmin4
- Installing and configuring Python for MySQL 8
- Installing and configuring Python for PostgreSQL driver on Ubuntu 22.04
- Installing and configuring SQL Developer on Ubuntu 22.04
- Installing the rlwrap utility to access command history in SQL*Plus (sqlplus) inside Docker container.
- How to add PostGIS to an existing PostgreSQL 14 Install on Ubuntu 22.0.4
- How to create a sandboxed user and wrap sqlplus inside the Docker version of Oracle 23c Free
- How to install, configure, and create a persistent SQLite 3 database and access it with Python.
As always, I hope the post and information helps others.
Apache2 on Ubuntu
It’s always interesting when I build new instances. Ubuntu 22.0.4 was no different but I ran into an issue with installing Apache2 and eventually loading the mysqli module.
The Apache2 error was an issue with an unsupported module or hidden prerequisite. The MySQLi required an Apache reload after installation. Contrary to some erroneous posts the mysqli driver is supported on PHP 8.1.
Apache2 installation starts first and the mysqli module reload and verification script follows. On Ubuntu, you install Apache2 if you’re unaware of the hidden pre-requisite, otherwise install the pre-requisite first and avoid the error.
This is the command to install the apache2 module:
sudo apt-get install -y apache2 |
It generated the following error message:
apache2: Syntax error on line 146 of /etc/apache2/apache2.conf: Syntax error on line 1 of /etc/apache2/mods-enabled/wsgi.load: Cannot load /usr/lib/apache2/modules/mod_wsgi.so into server: /usr/lib/apache2/modules/mod_wsgi.so: cannot open shared object file: No such file or directory Action 'start' failed. The Apache error log may have more information. |
Line 146 in the /etc/apache2/apache2.conf file contains the instruction to load modules. The error says it can’t find the mod_wsgi.so library, which was originally part of the deprecated Python 2.7 release.
IncludeOptional mods-enabled/*.load |
The first step I pursued was finding the missing library, which appeared to be in the libapache2-mod-wsgi package. However, it became clear there is no installation candidate for that module, which supported Python 3.x. A little more research led me to find the appropriate library version for Python 3, which is found in the libapache2-mod-wsgi-py3 package.
I installed the libapache2-mod-wsgi-py3 package with the following syntax:
sudo apt-get install -y libapache2-mod-wsgi-py3 |
Display detailed console log →
Reading package lists... Done Building dependency tree... Done Reading state information... Done The following NEW packages will be installed: libapache2-mod-wsgi-py3 0 upgraded, 1 newly installed, 0 to remove and 10 not upgraded. Need to get 106 kB of archives. After this operation, 304 kB of additional disk space will be used. Get:1 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libapache2-mod-wsgi-py3 amd64 4.9.0-1ubuntu0.1 [106 kB] Fetched 106 kB in 1s (135 kB/s) Selecting previously unselected package libapache2-mod-wsgi-py3. (Reading database ... 228859 files and directories currently installed.) Preparing to unpack .../libapache2-mod-wsgi-py3_4.9.0-1ubuntu0.1_amd64.deb ... Unpacking libapache2-mod-wsgi-py3 (4.9.0-1ubuntu0.1) ... Setting up libapache2-mod-wsgi-py3 (4.9.0-1ubuntu0.1) ... apache2_invoke wsgi: already enabled |
After applying it, I was able to start Apache2. Then, typing in localhost returns the Apache2 index.htm page, like:
After creating the following file in the default directory:
<?php phpinfo(); ?> |
Typing in localhost/infophp returns the Apache2 info.php page, like:
After the basics for PHP, the next step is the mysqli module for the MySQL database. This can be done in two steps on Ubuntu.
- Install the MySQLi software with the following syntax on Ubuntu:
sudo apt-get install -y php8.1-mysql
If you forget and use the old php-mysqli, it will redirect to the new PHP 8.1 MySQL module.
- You need to reload the Apache configuration with the following syntax:
sudo systemctl reload apache2
Now, you can use the following PHP program to verify that the mysqli and pdo drivers are installed:
<html>
<header>
<title>Module Verification</title>
</header>
<body>
<?php
if (!function_exists('mysqli_init') && !extension_loaded('mysqli')) {
print 'mysqli not installed.'; }
else {
print 'mysqli installed.'; }
if (!function_exists('pdo_init') && !extension_loaded('pdo')) {
print '<p>pdo not installed.</p>'; }
else {
print '<p>pdo installed.</p>'; }
?>
</script>
</body>
</html> |
If everything is correct, it should return the following in a browser when you query it from localhost/the-file-name and the file is in the /var/www/html directory:
mysqli installed. pdo installed. |
This means you can now write PHP applications, like the following example for my students:
I also have some demonstration programs that upload PNG files. As usual, I forgot about that while building the Ubuntu installation with MySQL 8, PHP 8.1 and Apache2. Fortunately, I solved it back in the day when moving from PHP 5.7 to 7.1 and here are the equivalent steps for Ubuntu:
I installed the libapache2-mod-wsgi-py3 package with the following syntax:
sudo apt-get install -y php-gd |
Display detailed console log →
Reading package lists... Done Building dependency tree... Done Reading state information... Done The following additional packages will be installed: php8.1-gd The following NEW packages will be installed: php-gd php8.1-gd 0 upgraded, 2 newly installed, 0 to remove and 13 not upgraded. Need to get 34.7 kB of archives. After this operation, 158 kB of additional disk space will be used. Get:1 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 php8.1-gd amd64 8.1.2-1ubuntu2.14 [32.9 kB] Get:2 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 php-gd all 2:8.1+92ubuntu1 [1,828 B] Fetched 34.7 kB in 1s (39.3 kB/s) sh: 0: getcwd() failed: No such file or directory sh: 0: getcwd() failed: No such file or directory sh: 0: getcwd() failed: No such file or directory sh: 0: getcwd() failed: No such file or directory Selecting previously unselected package php8.1-gd. (Reading database ... 228928 files and directories currently installed.) Preparing to unpack .../php8.1-gd_8.1.2-1ubuntu2.14_amd64.deb ... Unpacking php8.1-gd (8.1.2-1ubuntu2.14) ... Selecting previously unselected package php-gd. Preparing to unpack .../php-gd_2%3a8.1+92ubuntu1_all.deb ... Unpacking php-gd (2:8.1+92ubuntu1) ... Setting up php8.1-gd (8.1.2-1ubuntu2.14) ... Creating config file /etc/php/8.1/mods-available/gd.ini with new version Setting up php-gd (2:8.1+92ubuntu1) ... Processing triggers for libapache2-mod-php8.1 (8.1.2-1ubuntu2.14) ... Processing triggers for php8.1-cli (8.1.2-1ubuntu2.14) ... |
Then, I restarted the Apache2 server to incorporate the php-gd library in my PHP module with this syntax:
sudo systemctl restart apache2.service |
Retesting the PHP form to upload and render a PNG image file with this code (note that the only thing you can display is the html header and converted image, as shown on lines 64 and 65):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | <?php /* ConvertBlobToImage.php * by Michael McLaughlin * * This script queries an image from a BLOB column and * converts it to a PNG image. * * ALERT: * * The header must be inside the PHP script tag because nothing * can be rendered before the header() function call that signals * this is a PNG file. */ // Database credentials must be set manually because an include_once() function // call puts something ahead of the header, which causes a failure when rendering // an image. // Include the credential library. include_once("MySQLCredentials.inc"); // Return successful attempt to connect to the database. if (!$c = @mysqli_connect(HOSTNAME,USERNAME,PASSWORD,DATABASE)) { // Print user message. print "Sorry! The connection to the database failed. Please try again later."; // Assign the OCI error and format double and single quotes. print mysqli_error(); // Kill the resource. die(); } else { // Declare input variables. $id = (isset($_GET['id'])) ? (int) $_GET['id'] : 1023; // Initialize a statement in the scope of the connection. $stmt = mysqli_stmt_init($c); // Declare a SQL SELECT statement returning a MediumBLOB. $sql = "SELECT item_blob FROM item WHERE item_id = ?"; // Prepare statement and link it to a connection. if (mysqli_stmt_prepare($stmt,$sql)) { mysqli_stmt_bind_param($stmt,"i",$id); // Execute the PL/SQL statement. if (mysqli_stmt_execute($stmt)) { // Bind result to local variable. mysqli_stmt_bind_result($stmt, $image); // Read result. mysqli_stmt_fetch($stmt); } } // Disconnect from database. mysqli_close($c); // Print the header first. header('Content-type: image/png'); imagepng(imagecreatefromstring($image)); } ?> |
The call to the ConvertMySQLBlobToImage.php is handled in an image tag, as shown:
<img src="ConvertMySQLBlobToImage.php?id='.$id.'"> |
Rendering a web page, like:
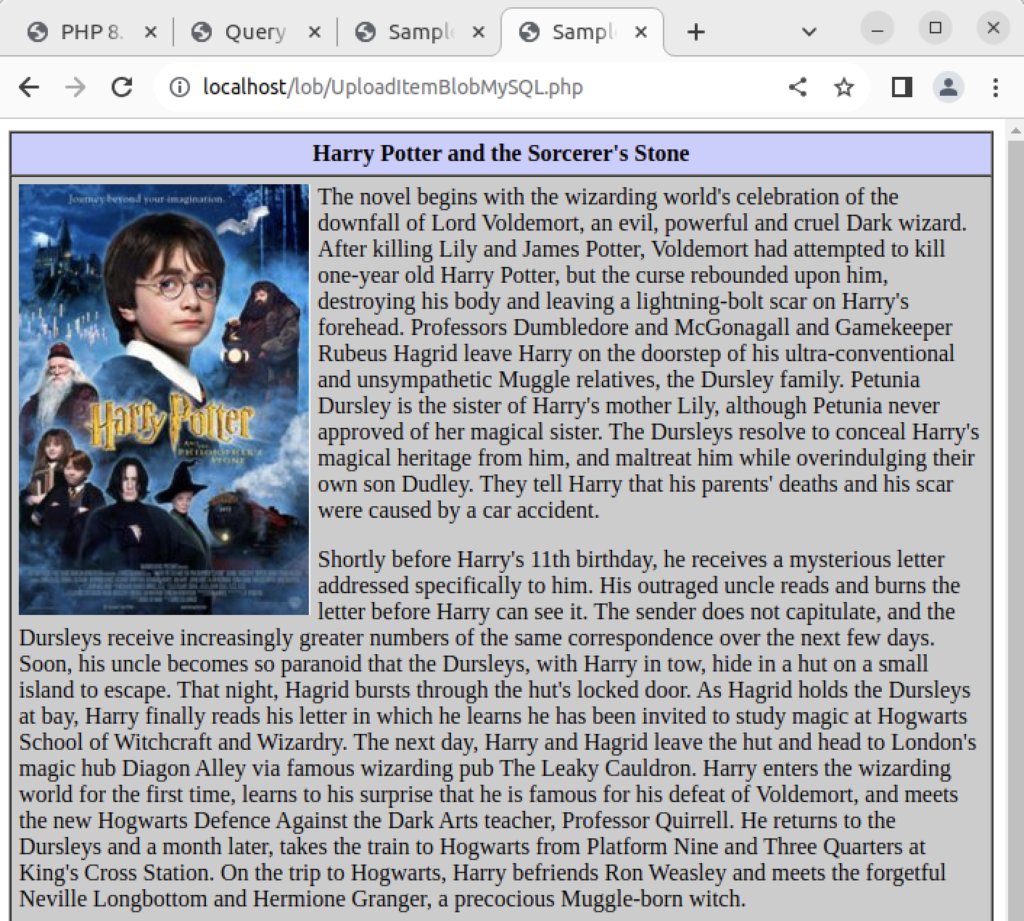
As always, I hope this explains something worthwhile.
OracleDB Python Tutorial 1
This shows you how to get Python working with the Oracle Database 23c in Docker or Podman on Ubuntu. You can find useful connection strings for this in Oracle Database Free Get Started.
- First step requires you to install the pip3/span> utility on Ubuntu.
sudo apt install -y python3-pip
Display detailed console log →
Reading package lists... Done Building dependency tree... Done Reading state information... Done The following additional packages will be installed: binutils binutils-common binutils-x86-64-linux-gnu build-essential dpkg-dev fakeroot g++ g++-11 gcc gcc-11 javascript-common libalgorithm-diff-perl libalgorithm-diff-xs-perl libalgorithm-merge-perl libasan6 libbinutils libc-dev-bin libc-devtools libc6-dev libcc1-0 libcrypt-dev libctf-nobfd0 libctf0 libdpkg-perl libexpat1-dev libfakeroot libfile-fcntllock-perl libgcc-11-dev libitm1 libjs-jquery libjs-sphinxdoc libjs-underscore liblsan0 libnsl-dev libpython3-dev libpython3.10-dev libquadmath0 libstdc++-11-dev libtirpc-dev libtsan0 libubsan1 linux-libc-dev lto-disabled-list make manpages-dev python3-dev python3-distutils python3-setuptools python3-wheel python3.10-dev rpcsvc-proto zlib1g-dev Suggested packages: binutils-doc debian-keyring g++-multilib g++-11-multilib gcc-11-doc gcc-multilib autoconf automake libtool flex bison gcc-doc gcc-11-multilib gcc-11-locales apache2 | lighttpd | httpd glibc-doc bzr libstdc++-11-doc make-doc python-setuptools-doc The following NEW packages will be installed: binutils binutils-common binutils-x86-64-linux-gnu build-essential dpkg-dev fakeroot g++ g++-11 gcc gcc-11 javascript-common libalgorithm-diff-perl libalgorithm-diff-xs-perl libalgorithm-merge-perl libasan6 libbinutils libc-dev-bin libc-devtools libc6-dev libcc1-0 libcrypt-dev libctf-nobfd0 libctf0 libdpkg-perl libexpat1-dev libfakeroot libfile-fcntllock-perl libgcc-11-dev libitm1 libjs-jquery libjs-sphinxdoc libjs-underscore liblsan0 libnsl-dev libpython3-dev libpython3.10-dev libquadmath0 libstdc++-11-dev libtirpc-dev libtsan0 libubsan1 linux-libc-dev lto-disabled-list make manpages-dev python3-dev python3-distutils python3-pip python3-setuptools python3-wheel python3.10-dev rpcsvc-proto zlib1g-dev 0 upgraded, 53 newly installed, 0 to remove and 9 not upgraded. Need to get 62.2 MB of archives. After this operation, 220 MB of additional disk space will be used. Get:1 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 binutils-common amd64 2.38-4ubuntu2.3 [222 kB] Get:2 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libbinutils amd64 2.38-4ubuntu2.3 [662 kB] Get:3 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libctf-nobfd0 amd64 2.38-4ubuntu2.3 [107 kB] Get:4 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libctf0 amd64 2.38-4ubuntu2.3 [103 kB] Get:5 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 binutils-x86-64-linux-gnu amd64 2.38-4ubuntu2.3 [2,327 kB] Get:6 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 binutils amd64 2.38-4ubuntu2.3 [3,190 B] Get:7 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libc-dev-bin amd64 2.35-0ubuntu3.5 [20.3 kB] Get:8 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 linux-libc-dev amd64 5.15.0-91.101 [1,332 kB] Get:9 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libcrypt-dev amd64 1:4.4.27-1 [112 kB] Get:10 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 rpcsvc-proto amd64 1.4.2-0ubuntu6 [68.5 kB] Get:11 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libtirpc-dev amd64 1.3.2-2ubuntu0.1 [192 kB] Get:12 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libnsl-dev amd64 1.3.0-2build2 [71.3 kB] Get:13 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libc6-dev amd64 2.35-0ubuntu3.5 [2,098 kB] Get:14 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libcc1-0 amd64 12.3.0-1ubuntu1~22.04 [48.3 kB] Get:15 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libitm1 amd64 12.3.0-1ubuntu1~22.04 [30.2 kB] Get:16 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libasan6 amd64 11.4.0-1ubuntu1~22.04 [2,282 kB] Get:17 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 liblsan0 amd64 12.3.0-1ubuntu1~22.04 [1,069 kB] Get:18 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libtsan0 amd64 11.4.0-1ubuntu1~22.04 [2,260 kB] Get:19 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libubsan1 amd64 12.3.0-1ubuntu1~22.04 [976 kB] Get:20 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libquadmath0 amd64 12.3.0-1ubuntu1~22.04 [154 kB] Get:21 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libgcc-11-dev amd64 11.4.0-1ubuntu1~22.04 [2,517 kB] Get:22 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 gcc-11 amd64 11.4.0-1ubuntu1~22.04 [20.1 MB] Get:23 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 gcc amd64 4:11.2.0-1ubuntu1 [5,112 B] Get:24 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libstdc++-11-dev amd64 11.4.0-1ubuntu1~22.04 [2,101 kB] Get:25 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 g++-11 amd64 11.4.0-1ubuntu1~22.04 [11.4 MB] Get:26 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 g++ amd64 4:11.2.0-1ubuntu1 [1,412 B] Get:27 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 make amd64 4.3-4.1build1 [180 kB] Get:28 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libdpkg-perl all 1.21.1ubuntu2.2 [237 kB] Get:29 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 lto-disabled-list all 24 [12.5 kB] Get:30 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 dpkg-dev all 1.21.1ubuntu2.2 [922 kB] Get:31 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 build-essential amd64 12.9ubuntu3 [4,744 B] Get:32 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libfakeroot amd64 1.28-1ubuntu1 [31.5 kB] Get:33 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 fakeroot amd64 1.28-1ubuntu1 [60.4 kB] Get:34 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 javascript-common all 11+nmu1 [5,936 B] Get:35 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libalgorithm-diff-perl all 1.201-1 [41.8 kB] Get:36 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libalgorithm-diff-xs-perl amd64 0.04-6build3 [11.9 kB] Get:37 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libalgorithm-merge-perl all 0.08-3 [12.0 kB] Get:38 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libc-devtools amd64 2.35-0ubuntu3.5 [28.9 kB] Get:39 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libexpat1-dev amd64 2.4.7-1ubuntu0.2 [147 kB] Get:40 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libfile-fcntllock-perl amd64 0.22-3build7 [33.9 kB] Get:41 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libjs-jquery all 3.6.0+dfsg+~3.5.13-1 [321 kB] Get:42 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libjs-underscore all 1.13.2~dfsg-2 [118 kB] Get:43 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libjs-sphinxdoc all 4.3.2-1 [139 kB] Get:44 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 zlib1g-dev amd64 1:1.2.11.dfsg-2ubuntu9.2 [164 kB] Get:45 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libpython3.10-dev amd64 3.10.12-1~22.04.3 [4,762 kB] Get:46 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libpython3-dev amd64 3.10.6-1~22.04 [7,166 B] Get:47 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 manpages-dev all 5.10-1ubuntu1 [2,309 kB] Get:48 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 python3.10-dev amd64 3.10.12-1~22.04.3 [507 kB] Get:49 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 python3-distutils all 3.10.8-1~22.04 [139 kB] Get:50 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 python3-dev amd64 3.10.6-1~22.04 [26.0 kB] Get:51 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 python3-setuptools all 59.6.0-1.2ubuntu0.22.04.1 [339 kB] Get:52 http://us.archive.ubuntu.com/ubuntu jammy-updates/universe amd64 python3-wheel all 0.37.1-2ubuntu0.22.04.1 [32.0 kB] Get:53 http://us.archive.ubuntu.com/ubuntu jammy-updates/universe amd64 python3-pip all 22.0.2+dfsg-1ubuntu0.4 [1,305 kB] Fetched 62.2 MB in 35s (1,781 kB/s) Extracting templates from packages: 100% Selecting previously unselected package binutils-common:amd64. (Reading database ... 221117 files and directories currently installed.) Preparing to unpack .../00-binutils-common_2.38-4ubuntu2.3_amd64.deb ... Unpacking binutils-common:amd64 (2.38-4ubuntu2.3) ... Selecting previously unselected package libbinutils:amd64. Preparing to unpack .../01-libbinutils_2.38-4ubuntu2.3_amd64.deb ... Unpacking libbinutils:amd64 (2.38-4ubuntu2.3) ... Selecting previously unselected package libctf-nobfd0:amd64. Preparing to unpack .../02-libctf-nobfd0_2.38-4ubuntu2.3_amd64.deb ... Unpacking libctf-nobfd0:amd64 (2.38-4ubuntu2.3) ... Selecting previously unselected package libctf0:amd64. Preparing to unpack .../03-libctf0_2.38-4ubuntu2.3_amd64.deb ... Unpacking libctf0:amd64 (2.38-4ubuntu2.3) ... Selecting previously unselected package binutils-x86-64-linux-gnu. Preparing to unpack .../04-binutils-x86-64-linux-gnu_2.38-4ubuntu2.3_amd64.deb ... Unpacking binutils-x86-64-linux-gnu (2.38-4ubuntu2.3) ... Selecting previously unselected package binutils. Preparing to unpack .../05-binutils_2.38-4ubuntu2.3_amd64.deb ... Unpacking binutils (2.38-4ubuntu2.3) ... Selecting previously unselected package libc-dev-bin. Preparing to unpack .../06-libc-dev-bin_2.35-0ubuntu3.5_amd64.deb ... Unpacking libc-dev-bin (2.35-0ubuntu3.5) ... Selecting previously unselected package linux-libc-dev:amd64. Preparing to unpack .../07-linux-libc-dev_5.15.0-91.101_amd64.deb ... Unpacking linux-libc-dev:amd64 (5.15.0-91.101) ... Selecting previously unselected package libcrypt-dev:amd64. Preparing to unpack .../08-libcrypt-dev_1%3a4.4.27-1_amd64.deb ... Unpacking libcrypt-dev:amd64 (1:4.4.27-1) ... Selecting previously unselected package rpcsvc-proto. Preparing to unpack .../09-rpcsvc-proto_1.4.2-0ubuntu6_amd64.deb ... Unpacking rpcsvc-proto (1.4.2-0ubuntu6) ... Selecting previously unselected package libtirpc-dev:amd64. Preparing to unpack .../10-libtirpc-dev_1.3.2-2ubuntu0.1_amd64.deb ... Unpacking libtirpc-dev:amd64 (1.3.2-2ubuntu0.1) ... Selecting previously unselected package libnsl-dev:amd64. Preparing to unpack .../11-libnsl-dev_1.3.0-2build2_amd64.deb ... Unpacking libnsl-dev:amd64 (1.3.0-2build2) ... Selecting previously unselected package libc6-dev:amd64. Preparing to unpack .../12-libc6-dev_2.35-0ubuntu3.5_amd64.deb ... Unpacking libc6-dev:amd64 (2.35-0ubuntu3.5) ... Selecting previously unselected package libcc1-0:amd64. Preparing to unpack .../13-libcc1-0_12.3.0-1ubuntu1~22.04_amd64.deb ... Unpacking libcc1-0:amd64 (12.3.0-1ubuntu1~22.04) ... Selecting previously unselected package libitm1:amd64. Preparing to unpack .../14-libitm1_12.3.0-1ubuntu1~22.04_amd64.deb ... Unpacking libitm1:amd64 (12.3.0-1ubuntu1~22.04) ... Selecting previously unselected package libasan6:amd64. Preparing to unpack .../15-libasan6_11.4.0-1ubuntu1~22.04_amd64.deb ... Unpacking libasan6:amd64 (11.4.0-1ubuntu1~22.04) ... Selecting previously unselected package liblsan0:amd64. Preparing to unpack .../16-liblsan0_12.3.0-1ubuntu1~22.04_amd64.deb ... Unpacking liblsan0:amd64 (12.3.0-1ubuntu1~22.04) ... Selecting previously unselected package libtsan0:amd64. Preparing to unpack .../17-libtsan0_11.4.0-1ubuntu1~22.04_amd64.deb ... Unpacking libtsan0:amd64 (11.4.0-1ubuntu1~22.04) ... Selecting previously unselected package libubsan1:amd64. Preparing to unpack .../18-libubsan1_12.3.0-1ubuntu1~22.04_amd64.deb ... Unpacking libubsan1:amd64 (12.3.0-1ubuntu1~22.04) ... Selecting previously unselected package libquadmath0:amd64. Preparing to unpack .../19-libquadmath0_12.3.0-1ubuntu1~22.04_amd64.deb ... Unpacking libquadmath0:amd64 (12.3.0-1ubuntu1~22.04) ... Selecting previously unselected package libgcc-11-dev:amd64. Preparing to unpack .../20-libgcc-11-dev_11.4.0-1ubuntu1~22.04_amd64.deb ... Unpacking libgcc-11-dev:amd64 (11.4.0-1ubuntu1~22.04) ... Selecting previously unselected package gcc-11. Preparing to unpack .../21-gcc-11_11.4.0-1ubuntu1~22.04_amd64.deb ... Unpacking gcc-11 (11.4.0-1ubuntu1~22.04) ... Selecting previously unselected package gcc. Preparing to unpack .../22-gcc_4%3a11.2.0-1ubuntu1_amd64.deb ... Unpacking gcc (4:11.2.0-1ubuntu1) ... Selecting previously unselected package libstdc++-11-dev:amd64. Preparing to unpack .../23-libstdc++-11-dev_11.4.0-1ubuntu1~22.04_amd64.deb ... Unpacking libstdc++-11-dev:amd64 (11.4.0-1ubuntu1~22.04) ... Selecting previously unselected package g++-11. Preparing to unpack .../24-g++-11_11.4.0-1ubuntu1~22.04_amd64.deb ... Unpacking g++-11 (11.4.0-1ubuntu1~22.04) ... Selecting previously unselected package g++. Preparing to unpack .../25-g++_4%3a11.2.0-1ubuntu1_amd64.deb ... Unpacking g++ (4:11.2.0-1ubuntu1) ... Selecting previously unselected package make. Preparing to unpack .../26-make_4.3-4.1build1_amd64.deb ... Unpacking make (4.3-4.1build1) ... Selecting previously unselected package libdpkg-perl. Preparing to unpack .../27-libdpkg-perl_1.21.1ubuntu2.2_all.deb ... Unpacking libdpkg-perl (1.21.1ubuntu2.2) ... Selecting previously unselected package lto-disabled-list. Preparing to unpack .../28-lto-disabled-list_24_all.deb ... Unpacking lto-disabled-list (24) ... Selecting previously unselected package dpkg-dev. Preparing to unpack .../29-dpkg-dev_1.21.1ubuntu2.2_all.deb ... Unpacking dpkg-dev (1.21.1ubuntu2.2) ... Selecting previously unselected package build-essential. Preparing to unpack .../30-build-essential_12.9ubuntu3_amd64.deb ... Unpacking build-essential (12.9ubuntu3) ... Selecting previously unselected package libfakeroot:amd64. Preparing to unpack .../31-libfakeroot_1.28-1ubuntu1_amd64.deb ... Unpacking libfakeroot:amd64 (1.28-1ubuntu1) ... Selecting previously unselected package fakeroot. Preparing to unpack .../32-fakeroot_1.28-1ubuntu1_amd64.deb ... Unpacking fakeroot (1.28-1ubuntu1) ... Selecting previously unselected package javascript-common. Preparing to unpack .../33-javascript-common_11+nmu1_all.deb ... Unpacking javascript-common (11+nmu1) ... Selecting previously unselected package libalgorithm-diff-perl. Preparing to unpack .../34-libalgorithm-diff-perl_1.201-1_all.deb ... Unpacking libalgorithm-diff-perl (1.201-1) ... Selecting previously unselected package libalgorithm-diff-xs-perl. Preparing to unpack .../35-libalgorithm-diff-xs-perl_0.04-6build3_amd64.deb ... Unpacking libalgorithm-diff-xs-perl (0.04-6build3) ... Selecting previously unselected package libalgorithm-merge-perl. Preparing to unpack .../36-libalgorithm-merge-perl_0.08-3_all.deb ... Unpacking libalgorithm-merge-perl (0.08-3) ... Selecting previously unselected package libc-devtools. Preparing to unpack .../37-libc-devtools_2.35-0ubuntu3.5_amd64.deb ... Unpacking libc-devtools (2.35-0ubuntu3.5) ... Selecting previously unselected package libexpat1-dev:amd64. Preparing to unpack .../38-libexpat1-dev_2.4.7-1ubuntu0.2_amd64.deb ... Unpacking libexpat1-dev:amd64 (2.4.7-1ubuntu0.2) ... Selecting previously unselected package libfile-fcntllock-perl. Preparing to unpack .../39-libfile-fcntllock-perl_0.22-3build7_amd64.deb ... Unpacking libfile-fcntllock-perl (0.22-3build7) ... Selecting previously unselected package libjs-jquery. Preparing to unpack .../40-libjs-jquery_3.6.0+dfsg+~3.5.13-1_all.deb ... Unpacking libjs-jquery (3.6.0+dfsg+~3.5.13-1) ... Selecting previously unselected package libjs-underscore. Preparing to unpack .../41-libjs-underscore_1.13.2~dfsg-2_all.deb ... Unpacking libjs-underscore (1.13.2~dfsg-2) ... Selecting previously unselected package libjs-sphinxdoc. Preparing to unpack .../42-libjs-sphinxdoc_4.3.2-1_all.deb ... Unpacking libjs-sphinxdoc (4.3.2-1) ... Selecting previously unselected package zlib1g-dev:amd64. Preparing to unpack .../43-zlib1g-dev_1%3a1.2.11.dfsg-2ubuntu9.2_amd64.deb ... Unpacking zlib1g-dev:amd64 (1:1.2.11.dfsg-2ubuntu9.2) ... Selecting previously unselected package libpython3.10-dev:amd64. Preparing to unpack .../44-libpython3.10-dev_3.10.12-1~22.04.3_amd64.deb ... Unpacking libpython3.10-dev:amd64 (3.10.12-1~22.04.3) ... Selecting previously unselected package libpython3-dev:amd64. Preparing to unpack .../45-libpython3-dev_3.10.6-1~22.04_amd64.deb ... Unpacking libpython3-dev:amd64 (3.10.6-1~22.04) ... Selecting previously unselected package manpages-dev. Preparing to unpack .../46-manpages-dev_5.10-1ubuntu1_all.deb ... Unpacking manpages-dev (5.10-1ubuntu1) ... Selecting previously unselected package python3.10-dev. Preparing to unpack .../47-python3.10-dev_3.10.12-1~22.04.3_amd64.deb ... Unpacking python3.10-dev (3.10.12-1~22.04.3) ... Selecting previously unselected package python3-distutils. Preparing to unpack .../48-python3-distutils_3.10.8-1~22.04_all.deb ... Unpacking python3-distutils (3.10.8-1~22.04) ... Selecting previously unselected package python3-dev. Preparing to unpack .../49-python3-dev_3.10.6-1~22.04_amd64.deb ... Unpacking python3-dev (3.10.6-1~22.04) ... Selecting previously unselected package python3-setuptools. Preparing to unpack .../50-python3-setuptools_59.6.0-1.2ubuntu0.22.04.1_all.deb ... Unpacking python3-setuptools (59.6.0-1.2ubuntu0.22.04.1) ... Selecting previously unselected package python3-wheel. Preparing to unpack .../51-python3-wheel_0.37.1-2ubuntu0.22.04.1_all.deb ... Unpacking python3-wheel (0.37.1-2ubuntu0.22.04.1) ... Selecting previously unselected package python3-pip. Preparing to unpack .../52-python3-pip_22.0.2+dfsg-1ubuntu0.4_all.deb ... Unpacking python3-pip (22.0.2+dfsg-1ubuntu0.4) ... Setting up python3-distutils (3.10.8-1~22.04) ... Setting up javascript-common (11+nmu1) ... Setting up manpages-dev (5.10-1ubuntu1) ... Setting up lto-disabled-list (24) ... Setting up python3-setuptools (59.6.0-1.2ubuntu0.22.04.1) ... Setting up libfile-fcntllock-perl (0.22-3build7) ... Setting up libalgorithm-diff-perl (1.201-1) ... Setting up binutils-common:amd64 (2.38-4ubuntu2.3) ... Setting up linux-libc-dev:amd64 (5.15.0-91.101) ... Setting up libctf-nobfd0:amd64 (2.38-4ubuntu2.3) ... Setting up python3-wheel (0.37.1-2ubuntu0.22.04.1) ... Setting up libfakeroot:amd64 (1.28-1ubuntu1) ... Setting up libasan6:amd64 (11.4.0-1ubuntu1~22.04) ... Setting up fakeroot (1.28-1ubuntu1) ... update-alternatives: using /usr/bin/fakeroot-sysv to provide /usr/bin/fakeroot (fakeroot) in auto mode Setting up libtirpc-dev:amd64 (1.3.2-2ubuntu0.1) ... Setting up rpcsvc-proto (1.4.2-0ubuntu6) ... Setting up make (4.3-4.1build1) ... Setting up libquadmath0:amd64 (12.3.0-1ubuntu1~22.04) ... Setting up python3-pip (22.0.2+dfsg-1ubuntu0.4) ... Setting up libdpkg-perl (1.21.1ubuntu2.2) ... Setting up libubsan1:amd64 (12.3.0-1ubuntu1~22.04) ... Setting up libnsl-dev:amd64 (1.3.0-2build2) ... Setting up libcrypt-dev:amd64 (1:4.4.27-1) ... Setting up libjs-jquery (3.6.0+dfsg+~3.5.13-1) ... Setting up libbinutils:amd64 (2.38-4ubuntu2.3) ... Setting up libc-dev-bin (2.35-0ubuntu3.5) ... Setting up libalgorithm-diff-xs-perl (0.04-6build3) ... Setting up libcc1-0:amd64 (12.3.0-1ubuntu1~22.04) ... Setting up liblsan0:amd64 (12.3.0-1ubuntu1~22.04) ... Setting up libitm1:amd64 (12.3.0-1ubuntu1~22.04) ... Setting up libc-devtools (2.35-0ubuntu3.5) ... Setting up libjs-underscore (1.13.2~dfsg-2) ... Setting up libalgorithm-merge-perl (0.08-3) ... Setting up libtsan0:amd64 (11.4.0-1ubuntu1~22.04) ... Setting up libctf0:amd64 (2.38-4ubuntu2.3) ... Setting up libjs-sphinxdoc (4.3.2-1) ... Setting up libgcc-11-dev:amd64 (11.4.0-1ubuntu1~22.04) ... Setting up libc6-dev:amd64 (2.35-0ubuntu3.5) ... Setting up binutils-x86-64-linux-gnu (2.38-4ubuntu2.3) ... Setting up binutils (2.38-4ubuntu2.3) ... Setting up dpkg-dev (1.21.1ubuntu2.2) ... Setting up libexpat1-dev:amd64 (2.4.7-1ubuntu0.2) ... Setting up libstdc++-11-dev:amd64 (11.4.0-1ubuntu1~22.04) ... Setting up zlib1g-dev:amd64 (1:1.2.11.dfsg-2ubuntu9.2) ... Setting up gcc-11 (11.4.0-1ubuntu1~22.04) ... Setting up g++-11 (11.4.0-1ubuntu1~22.04) ... Setting up gcc (4:11.2.0-1ubuntu1) ... Setting up libpython3.10-dev:amd64 (3.10.12-1~22.04.3) ... Setting up python3.10-dev (3.10.12-1~22.04.3) ... Setting up g++ (4:11.2.0-1ubuntu1) ... update-alternatives: using /usr/bin/g++ to provide /usr/bin/c++ (c++) in auto mode Setting up build-essential (12.9ubuntu3) ... Setting up libpython3-dev:amd64 (3.10.6-1~22.04) ... Setting up python3-dev (3.10.6-1~22.04) ... Processing triggers for man-db (2.10.2-1) ... Processing triggers for libc-bin (2.35-0ubuntu3.5) ...
- Second step requires that you pip3 install the oracledb library:
sudo pip3 install oracledb --upgrade
Display detailed console log →
Defaulting to user installation because normal site-packages is not writeable Collecting oracledb Downloading oracledb-1.4.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (8.6 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.6/8.6 MB 2.7 MB/s eta 0:00:00 Requirement already satisfied: cryptography>=3.2.1 in /usr/lib/python3/dist-packages (from oracledb) (3.4.8) Installing collected packages: oracledb Successfully installed oracledb-1.4.2 - Third step requires you write a Python program to test your connection to Oracle Database 23c Free, like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
#!/usr/bin/python # Import the Oracle library. import oracledb try: # Create a connection to local Docker or Podman installation. db = oracledb.connect(user='c##student', password='student', dsn='localhost:51521/FREE') # Print a connection message. print("Connected to the Oracle", db.version, "database.") except oracledb.DatabaseError as e: error, = e.args print(sys.stderr, "Oracle-Error-Code:", error.code) print(sys.stderr, "Oracle-Error-Message:", error.message) finally: # Close connection. db.close()
The 51521 port is the recommended port when setting up Docker or Podman services, however, it can be set to any port above 1024.
It should print:
Connected to the Oracle 23.3.0.23.9 database.
- Fourth step requires you write a Python program to test querying data from an Oracle Database 23c Free instance. I created the following avenger table and seeded it with six Avengers.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/* Conditionally drop the table. */ DROP TABLE IF EXISTS avenger; /* Create the table. */ CREATE TABLE avenger ( avenger_id NUMBER , first_name VARCHAR2(20) , last_name VARCHAR2(20) , character_name VARCHAR2(20)); /* Seed the table with data. */ INSERT INTO avenger VALUES (1,'Anthony','Stark','Iron Man'); INSERT INTO avenger VALUES (2,'Thor','Odinson','God of Thunder'); INSERT INTO avenger VALUES (3,'Steven','Rogers','Captain America'); INSERT INTO avenger VALUES (4,'Bruce','Banner','Hulk'); INSERT INTO avenger VALUES (5,'Clinton','Barton','Hawkeye'); INSERT INTO avenger VALUES (6,'Natasha','Romanoff','Black Widow');
Then, I extended the program logic to include a cursor and for loop to read the values from the avenger table:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
#!/usr/bin/python # Import the Oracle library. import oracledb try: # Create a connection to local Docker or Podman installation. db = oracledb.connect(user='c##student', password='student', dsn='localhost:51521/FREE') # Create a cursor. cursor = db.cursor() # Execute a query. cursor.execute("SELECT character_name " + ", first_name " + ", last_name " + "FROM avenger " + "ORDER BY character_name") # Read the contents of the cursor. for row in cursor: print(row[0] + ':',row[2] + ',',row[1]) except oracledb.DatabaseError as e: error, = e.args print(sys.stderr, "Oracle-Error-Code:", error.code) print(sys.stderr, "Oracle-Error-Message:", error.message) finally: # Close cursor and connection. cursor.close() db.close()
The 51521 port is the recommended port when setting up Docker or Podman services, however, it can be set to any port above 1024.
It should print:
Black Widow: Romanoff, Natasha Captain America: Rogers, Steven God of Thunder: Odinson, Thor Hawkeye: Barton, Clinton Hulk: Banner, Bruce Iron Man: Stark, Anthony
- Fifth step requires you write a Python program to test querying data filtered by a local variable from an Oracle Database 23c Free instance. This example looks only for the Hulk among the six Avengers.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
#!/usr/bin/python # Import the Oracle library. import oracledb try: # Create a connection to local Docker or Podman installation. db = oracledb.connect(user='c##student', password='student', dsn='localhost:51521/FREE') # Create a cursor. cursor = db.cursor() # Execute a query. stmt = "SELECT character_name " \ ", first_name " \ ", last_name " \ "FROM avenger " \ "WHERE character_name = :avenger " \ "ORDER BY character_name" # Execute with bind variable. cursor.execute(stmt, avenger = "Hulk") # Read the contents of the cursor. for row in cursor: print(row[0] + ':',row[2] + ',',row[1]) except oracledb.DatabaseError as e: error, = e.args print(sys.stderr, "Oracle-Error-Code:", error.code) print(sys.stderr, "Oracle-Error-Message:", error.message) finally: # Close cursor and connection. cursor.close() db.close()
It should print:
Hulk: Banner, Bruce
As always, I hope this puts everything together for setting up Python with Oracle Database 23c Free.
