Relational vs. XML modeling
The MarkLogic 2008 user Conference presentation, by Michael Bowers, makes the case that normalization can lose data context. It qualifies three steps to normalize data. They are: (1) Normalizing the data; (2) Orthogonalizing the data; and (3) Generalizing the data. You remove redundancies in tables when you normalize tables. You make sure there isn’t data duplicated between tables, which mean you orthogonalize the model. You generalize the data by creating tables that are super types. These tables contain subtypes that are qualified by super keys, like models of cars.
While there’s an argument that XML is for narrative or unstructured data, is it really? XML actually models highly structured and unstructured data. Combining reality with that dose of theory got me thinking about how you could build and query a traditional normalized XML model. For example, what should happen to the primary and foreign keys that let you orthogonalize relationships?
Surrogate and foreign keys always seemed a bit out of place but I couldn’t put my finger on it. The concept of the natural key being part of the data made sense because it uniquely describes a table at a moment in time. A surrogate primary key made sense because it qualifies the domain of identification, which allows a model to evolve. Models evolve as developers discover new perspective on a table’s domain. The presence of a surrogate key lets you redefine a natural key without rewriting SQL join statements. You can do this because joins that use surrogate keys should rely on a composite primary key index. The primary key index is led by the surrogate key and followed by the natural key columns, at least in Oracle. Therefore, surrogate keys lets you discover and redefine table domains dropping and recreating the primary key index.
When I modeled them in XML to mimic a relational model, surrogate keys made sense because they’re not part of the data. This means they’re not represented by tags in an XML hierarchy. At least, it appears that they should be attributes describing an element (or row in a relational model). My relational XML model treats them that way. It makes them attributes, as shown below in the example.
The queries use tables modeled as table, row, and column tags. The row tags contain attributes for primary and foreign keys. The following queries join the two XML files just like SQL or PL/SQL would join two tables or two cursor result sets.
XQuery like SQL:
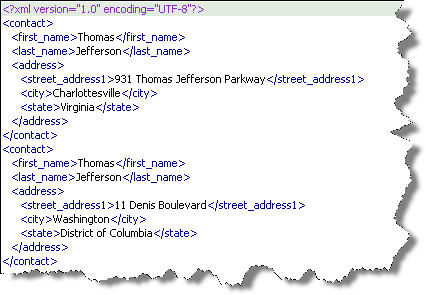
This returns a result set like that from an inner join between two tables. The interesting element is that the column values for the CONTACT table are repeated for each matching row in the ADDRESS table. You need SQL*Plus or a PL/SQL loop to organize the results in a tree structure in a relational database but only a nested FLOWR statement in XQuery (shown below in the next section).

This would be equal to a query between two tables, like CONTACT and ADDRESS with a WHERE clause:
SELECT * FROM contact c JOIN address a ON c.contact_id = a.contact_id WHERE c.contact_id = 3; |
The results for the XQuery follows.
Results:
XQuery like PL/SQL:
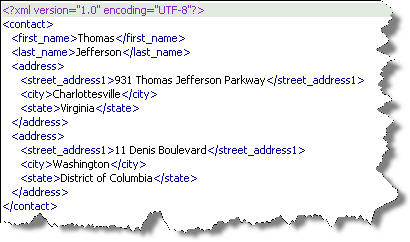
This returns a hierarchical result set by embedding a for loop in the original return value. It is like a nested loop in PL/SQL.

The equivalent PL/SQL statement would be something like this nested loop structure:
BEGIN FOR i IN (SELECT c.contact_id , c.first_name , c.last_name FROM contact c WHERE c.contact_id = 3) LOOP DBMS_OUTPUT.put_line(i.first_name); DBMS_OUTPUT.put_line(i.last_name); FOR j IN (SELECT a.street_address , a.city , a.state FROM address a WHERE a.contact_id = i.contact_id) LOOP DBMS_OUTPUT.put_line(j.street_address); DBMS_OUTPUT.put_line(j.city); DBMS_OUTPUT.put_line(j.state); END LOOP; END LOOP; END; / |
Results:
These results are hierarchical and more natural for structured XML data. They’re a direct temporary result set that you can then transform for presentation in XHTML.
XQuery preserving the primary key attribute:
The interesting twist in the foregoing XQuery is that the primary key value is lost from the source. You can preserve it by making the following change to the XQuery statement:

Results:
The new results show that you can join the hierarchical node to another XML document or fragment:
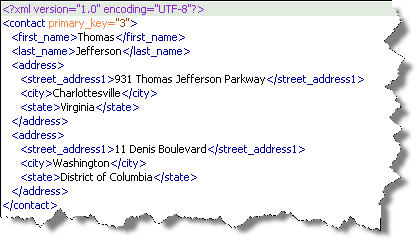
The resulting XML document could now join to another XML document. It also demonstrates the nested table concept present in modern databases. Like nested tables, these nested container attributes don’t have separate keys explicitly identifying their ordering. You can derive their ordering.
While these have put the primary and foreign keys in attributes, there is no limitation that imposes a constraint. You could choose to implement them as tags in their own right.
Observation:
A real XML data model would include a file that contains all the relative information about contacts, similar to the output of the query. It would appear like an inverted tree, or hierarchy. The difference is the contact information wouldn’t repeat, as it does in a normalized table or XML file. This makes an XML document like a data object model. More or less a Singleton pattern data object because if normalization rules apply, there’s only one in any collection of XML files or stored collections.
XML data objects can be joined to other data objects to build comprehensive business solutions. You might make the argument that the data may translate to object-oriented developers more effectively in a context sensitive XML format.
XML is flexible enough to fit the definitions of hierarchical, networked, and relational database models. You define the database model by how you implement the XML files. There are a couple twists from a traditional relational modeling perspective. The twists are (a) XQuery replaces SQL and PL/SQL, and (b) full or context indexes are always built on insert of XML documents like indexes (like OracleText context and catalog indexes) in a relational model.
Naysayers can point to a lack of transactional standards, like SQL Data Manipulation Language (DML) commands. The complaint doesn’t appear to hold too much water because XML databases extend XQuery with library functions that provide transactional capabilities. These capabilities mimic SQL DML statements.
Some XML databases typically act as in memory databases and have extremely fast data retrieval when documents are relatively small. Update throughput currently seems to degrade after files reach a megabyte but the XML database tools let you fragment documents across a collection of servers to gain enhanced throughput.
While highly transactional data probably scales best in relational databases, XML databases don’t look like only a niche product in the not too distant future. What the future holds is anyone’s guess. As the standards and products mature, adding XQuery to one’s SQL skill looks like a good bet on future employment opportunities.
Source Files:
1. Contact.xml
<?xml version="1.0" encoding="UTF-8"?>
<table>
<contact primary_key=”1″>
<first_name primary_key=”1″>Samuel</first_name>
<last_name>Adams</last_name>
</contact>
<contact primary_key=”2″>
<first_name>John</first_name>
<last_name>Adams</last_name>
</contact>
<contact primary_key=”3″>
<first_name>Thomas</first_name>
<last_name>Jefferson</last_name>
</contact>
<contact primary_key=”4″>
<first_name>James</first_name>
<last_name>Madison</last_name>
</contact>
<contact primary_key=”5″>
<first_name>James</first_name>
<last_name>Monroe</last_name>
</contact>
<contact primary_key=”6″>
<first_name>John</first_name>
<middle_name>Quincy</middle_name>
<last_name>Adams</last_name>
</contact>
</table> |
2. Address.xml
<table>
<address primary_key=”1″ contact_foreign_key=”1″>
<street_address1>1 Purchase Street</street_address1>
<city>Boston</city>
<state>Massachusetts</state>
</address>
<address primary_key=”2″ contact_foreign_key=”2″>
<street_address1>1 Main Street</street_address1>
<city>Quincy</city>
<state>Massachusetts</state>
</address>
<address primary_key=”3″ contact_foreign_key=”3″>
<street_address1>931 Thomas Jefferson Parkway</street_address1>
<city>Charlottesville</city>
<state>Virginia</state>
</address>
<address primary_key=”3″ contact_foreign_key=”3″>
<street_address1>11 Denis Boulevard</street_address1>
<city>Washington</city>
<state>District of Columbia</state>
</address>
<address primary_key=”4″ contact_foreign_key=”4″>
<street_address1>1000 James Monroe Parkway</street_address1>
<city>Charlottesville</city>
<state>Virginia</state>
</address>
<address primary_key=”5″ contact_foreign_key=”5″>
<street_address1>2129-33 Eye St NW</street_address1>
<city>Washington</city>
<state>District of Columbia</state>
</address>
</table> |

That’s good, that will be very useful for my project~!
John
31 Jan 09 at 5:12 pm