Archive for the ‘sql’ Category
Oracle Diagnostic Queries
It’s always a challenge when you want to build your own Oracle SQL Tools. I was asked how you could synchronize multiple cursors into a single source. The answer is quite simple, you write an Oracle object type to represent a record structure, an Oracle list of the record structure, and a stored function to return the list of the record structure.
For this example, you create the following table_struct object type and a table_list collection type:
/* Drop the types from most to least dependent. */ DROP TYPE table_list; DROP TYPE table_struct; /* Create the record type structure. */ CREATE OR REPLACE TYPE table_struct IS OBJECT ( table_name VARCHAR2(30) , column_cnt NUMBER , row_cnt NUMBER ); / /* Create the collection of a record type structure. */ CREATE OR REPLACE TYPE table_list IS TABLE OF table_struct; / |
The following listing function now reads all table names from the user_tables view. A subordinate cursor reads the user_tab_columns view for the number of columns in a table. A Native Dynamic SQL (NDS) cursor counts the number of rows in each tables found in the .
/* Create the listing function. */
CREATE OR REPLACE
FUNCTION listing RETURN table_list IS
/* Variable list. */
lv_column_cnt NUMBER;
lv_row_cnt NUMBER;
/* Declare a statement variable. */
stmt VARCHAR2(200);
/* Declare a system reference cursor variable. */
lv_refcursor SYS_REFCURSOR;
lv_table_cnt NUMBER;
/* Declare an output variable. */
lv_list TABLE_LIST := table_list();
/* Declare a table list cursor that excludes APEX tables. */
CURSOR c IS
SELECT table_name
FROM user_tables
WHERE table_name NOT IN
('DEPT','EMP','APEX$_ACL','APEX$_WS_WEBPG_SECTIONS','APEX$_WS_ROWS'
,'APEX$_WS_HISTORY','APEX$_WS_NOTES','APEX$_WS_LINKS'
,'APEX$_WS_TAGS','APEX$_WS_FILES','APEX$_WS_WEBPG_SECTION_HISTORY'
,'DEMO_USERS','DEMO_CUSTOMERS','DEMO_ORDERS','DEMO_PRODUCT_INFO'
,'DEMO_ORDER_ITEMS','DEMO_STATES');
/* Declare a column count. */
CURSOR cnt
( cv_table_name VARCHAR2 ) IS
SELECT table_name
, COUNT(column_id) AS cnt_columns
FROM user_tab_columns
WHERE table_name = cv_table_name
GROUP BY table_name;
BEGIN
/* Read through the data set of non-environment variables. */
FOR i IN c LOOP
/* Count the columns of a table. */
FOR j IN cnt(i.table_name) LOOP
lv_column_cnt := j.cnt_columns;
END LOOP;
/* Declare a statement. */
stmt := 'SELECT COUNT(*) AS column_cnt FROM '||i.table_name;
/* Open the cursor and write set to collection. */
OPEN lv_refcursor FOR stmt;
LOOP
FETCH lv_refcursor INTO lv_table_cnt;
EXIT WHEN lv_refcursor%NOTFOUND;
lv_list.EXTEND;
lv_list(lv_list.COUNT) := table_struct(
table_name => i.table_name
, column_cnt => lv_column_cnt
, row_cnt => lv_table_cnt );
END LOOP;
END LOOP;
RETURN lv_list;
END;
/ |
The following query pulls the processed data set as the function’s result:
COL table_name FORMAT A20 HEADING "Table Name" COL column_cnt FORMAT 9,999 HEADING "Column #" COL row_cnt FORMAT 9,999 HEADING "Row #" SELECT table_name , column_cnt , row_cnt FROM TABLE(listing); |
It returns the following result set:
Table Name Column # Row # -------------------- -------- ------ SYSTEM_USER 11 5 COMMON_LOOKUP 10 49 MEMBER 9 10 CONTACT 10 18 ADDRESS 10 18 STREET_ADDRESS 8 28 TELEPHONE 11 18 RENTAL 8 4,694 ITEM 14 93 RENTAL_ITEM 9 4,703 PRICE 11 558 TRANSACTION 12 4,694 CALENDAR 9 300 AIRPORT 9 6 ACCOUNT_LIST 8 200 15 rows selected. |
As always, I hope this helps those trying to work with the Oracle database.
DB_LINK w/o tnsnames.ora
A question popped up, which I thought was interesting. How can you create a DB_LINK in Oracle without the DBA changing the tnsnames.ora file? It’s actually quite easy, especially if the DBA sets the TNS address name the same as the instance’s service name or in older databases SID value.
- Do the following with the
tnspingutility:tnsping mohawk
It should return this when the server’s
hostnameismohawkand domain name istechtinker.com:TNS Ping Utility for Linux: Version 11.2.0.2.0 - Production on 26-JUL-2016 16:55:58 Copyright (c) 1997, 2011, Oracle. All rights reserved. Used parameter files: Used TNSNAMES adapter to resolve the alias Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = mohawk.techtinker.com)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ORCL))) OK (10 msec)
- You can now create a
DB_LINKin another Oracle instance without atnsnames.oraentry by referencing the type of server connection and service name with the following syntax (please note that you should remove extraneous white space):CREATE DATABASE LINK test CONNECT TO student IDENTIFIED BY student USING '(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=mohawk.techtinker.com)(PORT=1521))(CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=ORCL)))'
In an older database version, you may need to refer to the
SID, like this:CREATE DATABASE LINK test CONNECT TO student IDENTIFIED BY student USING '(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=mohawk.techtinker.com)(PORT=1521))(CONNECT_DATA=(SERVER=DEDICATED)(SID=ORCL)))'
Then, you can query a contact table in the remote instance like this:
SELECT COUNT(*) FROM contact@test;
As always, I hope this helps somebody trying to solve a problem.
Debug PL/SQL Web Pages
What happens when you can’t get a PL/SQL Web Toolkit to work because it only prints to a web page? That’s more tedious because any dbms_output.put_line command you embed only prints to a SQL*Plus session. The answer is quite simple, you create a test case and test it inside a SQL*Plus environment.
Here’s a sample web page that fails to run successfully …
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | CREATE OR REPLACE PROCEDURE html_table_values ( name_array OWA_UTIL.VC_ARR , value_array OWA_UTIL.VC_ARR ) IS BEGIN /* Print debug to SQL*Plus session. */ FOR i IN 1..name_array.COUNT LOOP DBMS_OUTPUT.put_line('Value ['||name_array(i)||'='||value_array(i)||']'); END LOOP; /* Open HTML page with the PL/SQL toolkit. */ htp.print('<!DOCTYPE html>'); htp.htmlopen; htp.headopen; htp.htitle('Test'); htp.headclose; htp.bodyopen; htp.line; htp.print('Test'); htp.line; htp.bodyclose; htp.htmlclose; END; / |
You can test the program with the following anonymous block as the SYSTEM user, which is equivalent to the following URL:
http://localhost:8080/db/html_table_values?begin=1004&end=1012 |
The following test program lets you work:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | DECLARE x OWA_UTIL.VC_ARR; y OWA_UTIL.VC_ARR; BEGIN /* Insert first row element. */ x(1) := 'begin'; y(1) := '1004'; /* Insert second row element. */ x(2) := 'end'; y(2) := '1012'; /* Call the anonymous schema's web page. */ anonymous.html_table_values(x,y); END; / |
It should print:
Value [begin=1004] Value [end=1012] |
I hope this helps those looking for a solution.
SQL Developer & PL/SQL
While SQL Developer installs with a dbms_output view, some organizations close it before they distribute images or virtual machine (VM) instances. This post shows you how to re-enable the Dbms Output view for SQL Developer.
SQL Developer DBMS_OUTPUT Configuration
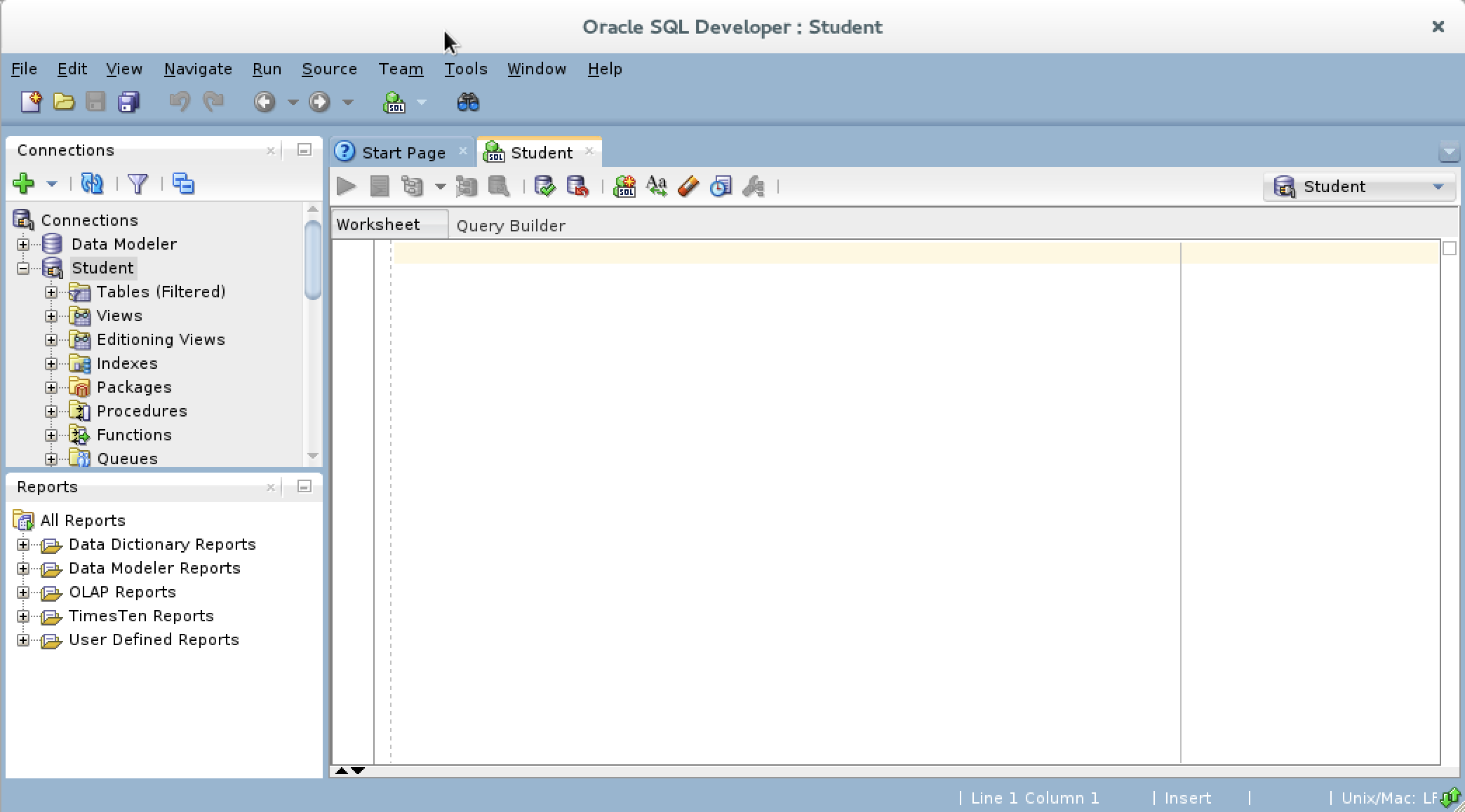
- You need to open SQL Developer, which may look like this when the
DBMS_OUTPUTview isn’t visible.
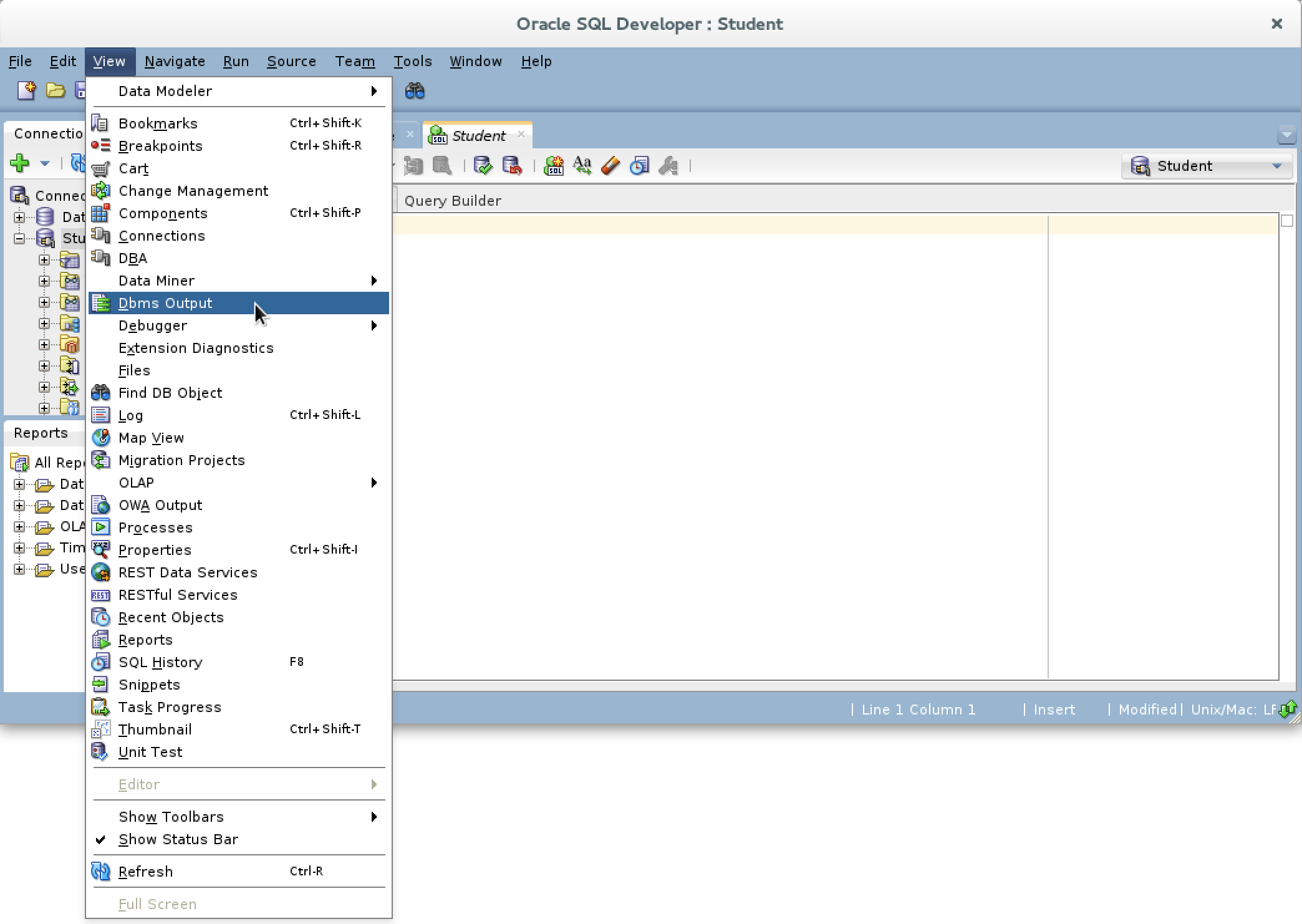
- You need to click on the View menu option in SQL Developer and choose the Dbms Output dropdown menu element.
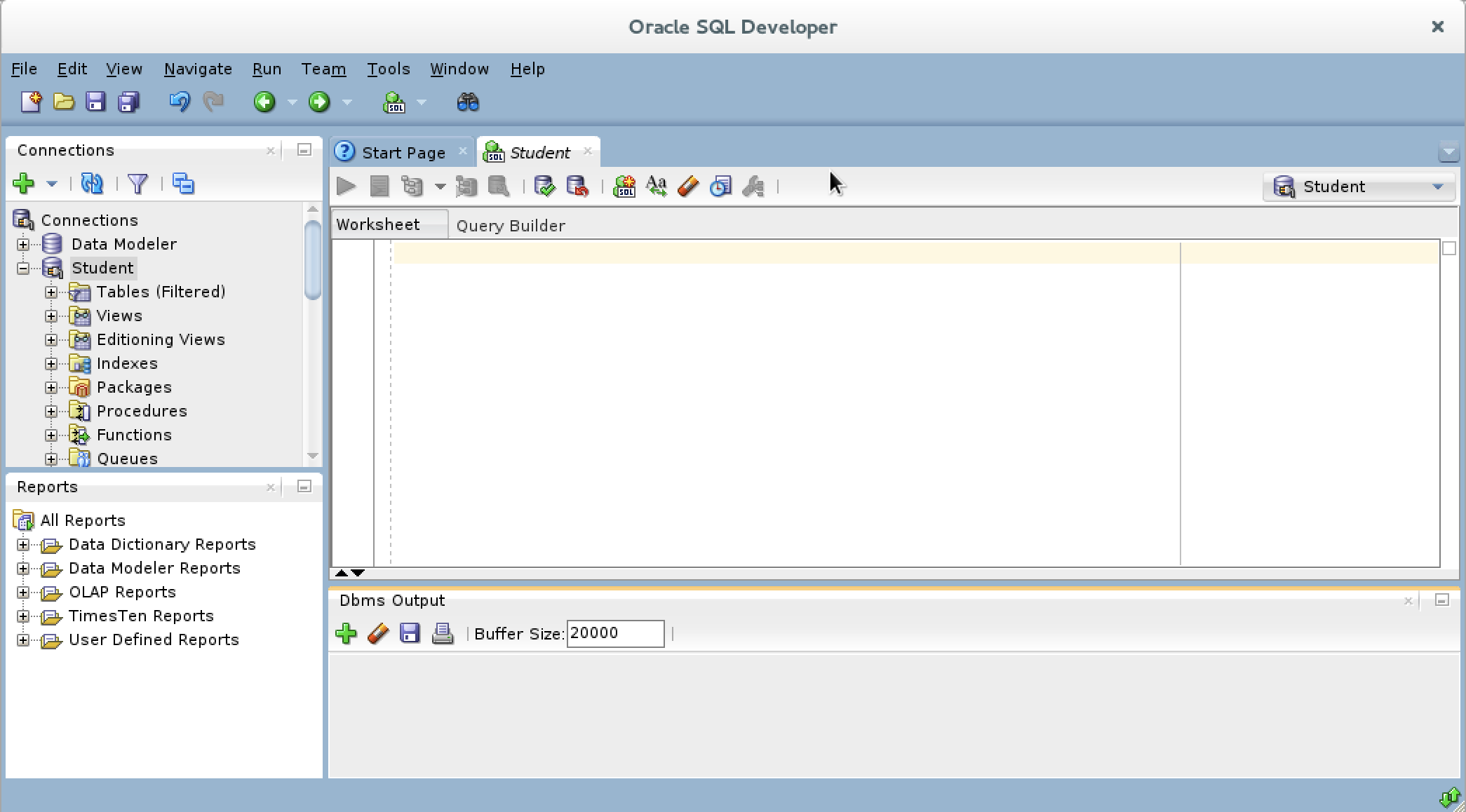
- You should see a grayed-out Dbms Output view.
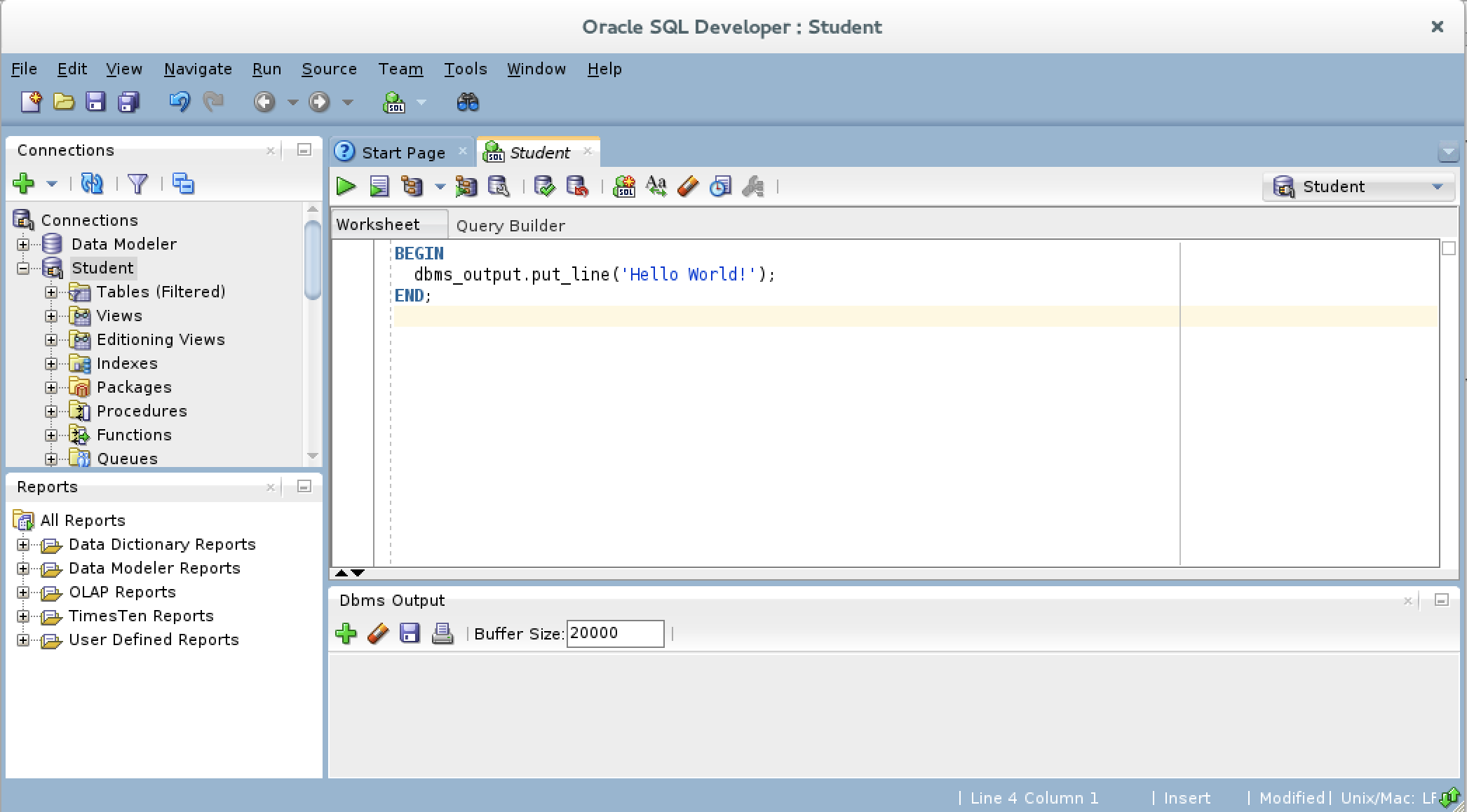
- You should type a simply “Hello World!” anonymous block program in PL/SQL, like the one shown in the drawing.
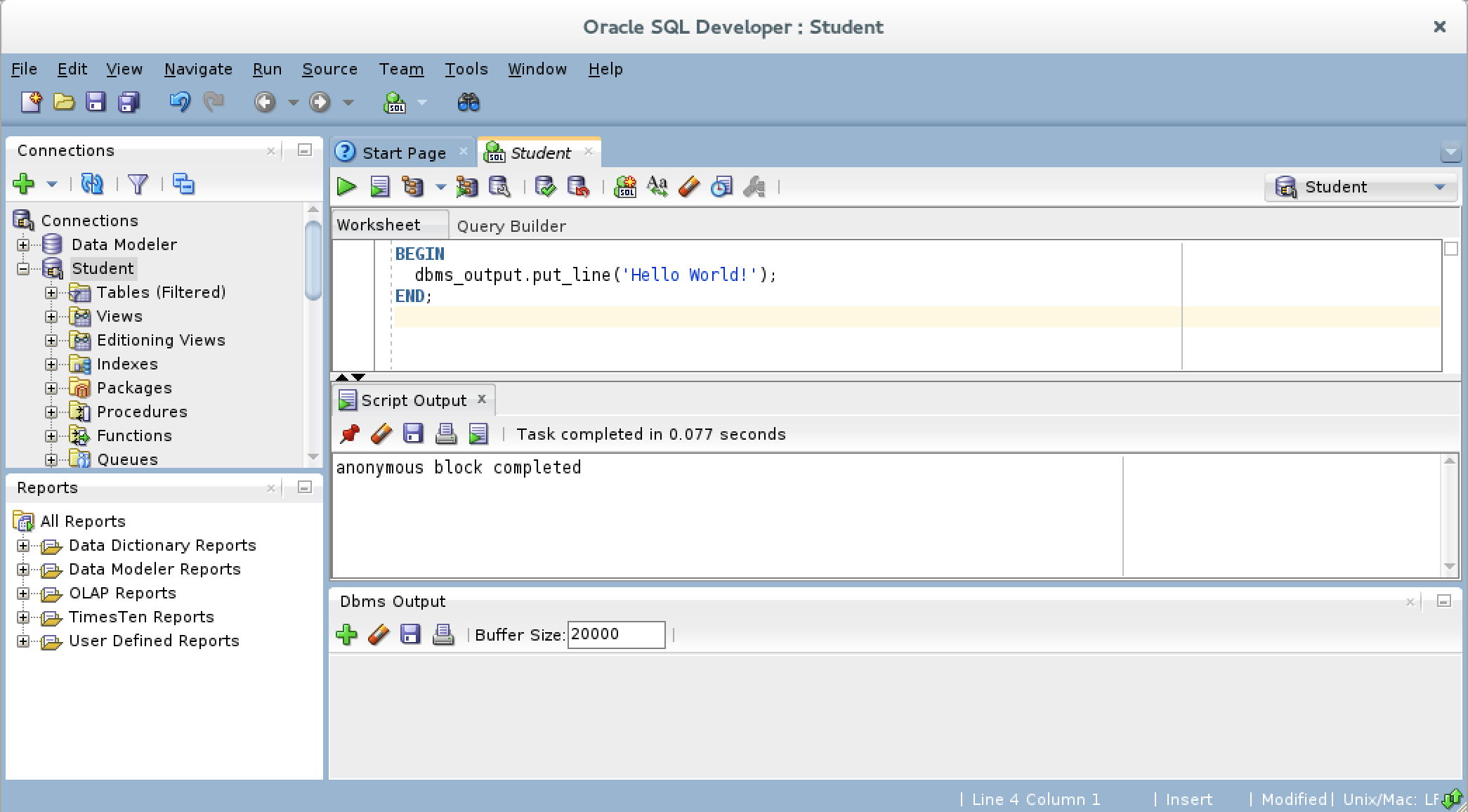
- After writing the “Hello World!” anonymous block program in PL/SQL, click the green arrow to start the statement and you will see two things. There is now a Script Output view between your console and Dbms Output views, and it should say “anonymous block completed.” Unfortunately, none of your output is displayed in the Dbms Output view because you need to enable it.
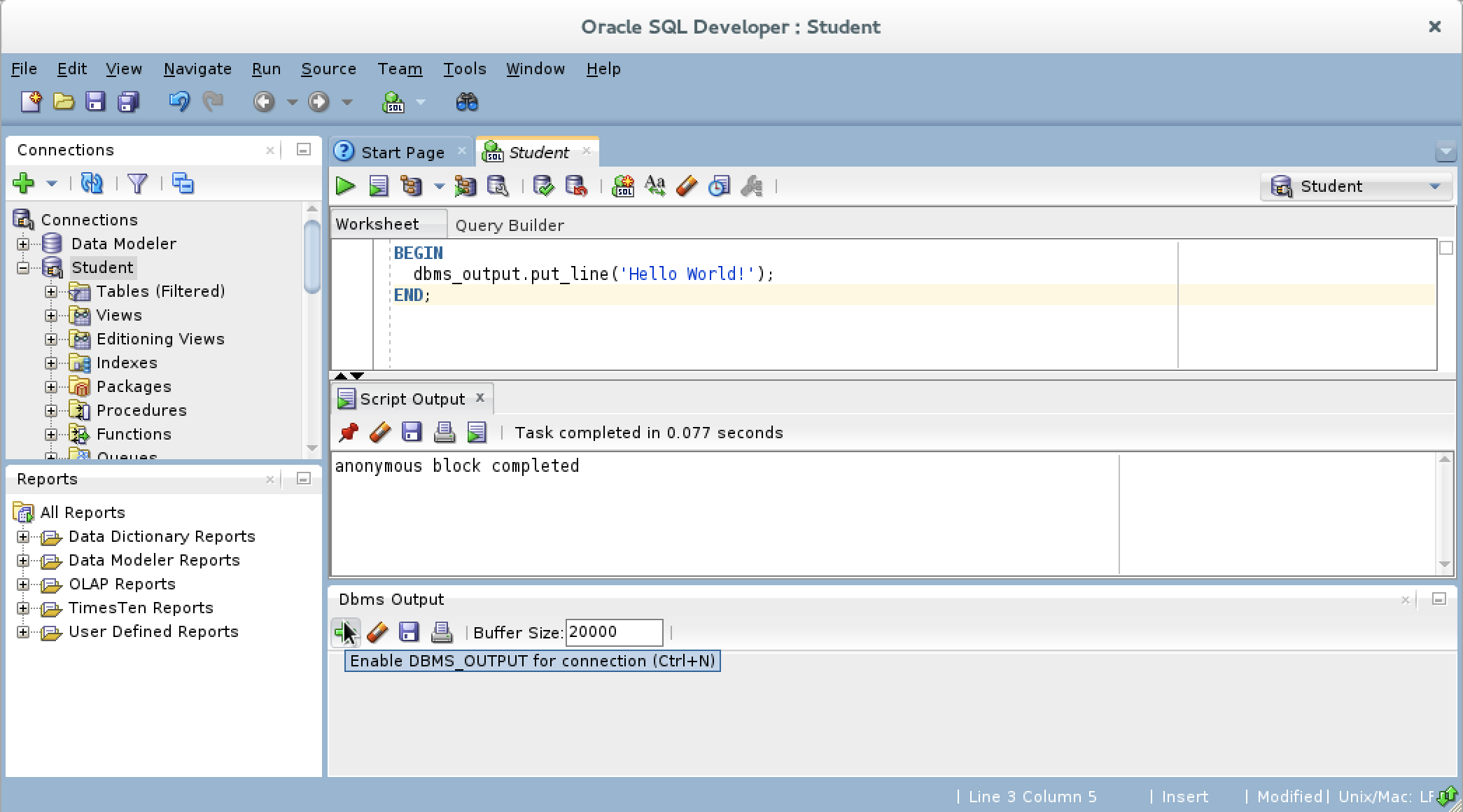
- If you hover over the Dbms Output view’s green arrow, you see the help message that describes the behavior of the green arrow. The Dbms Output green arrow lets you enable the Dbms Output view for output.
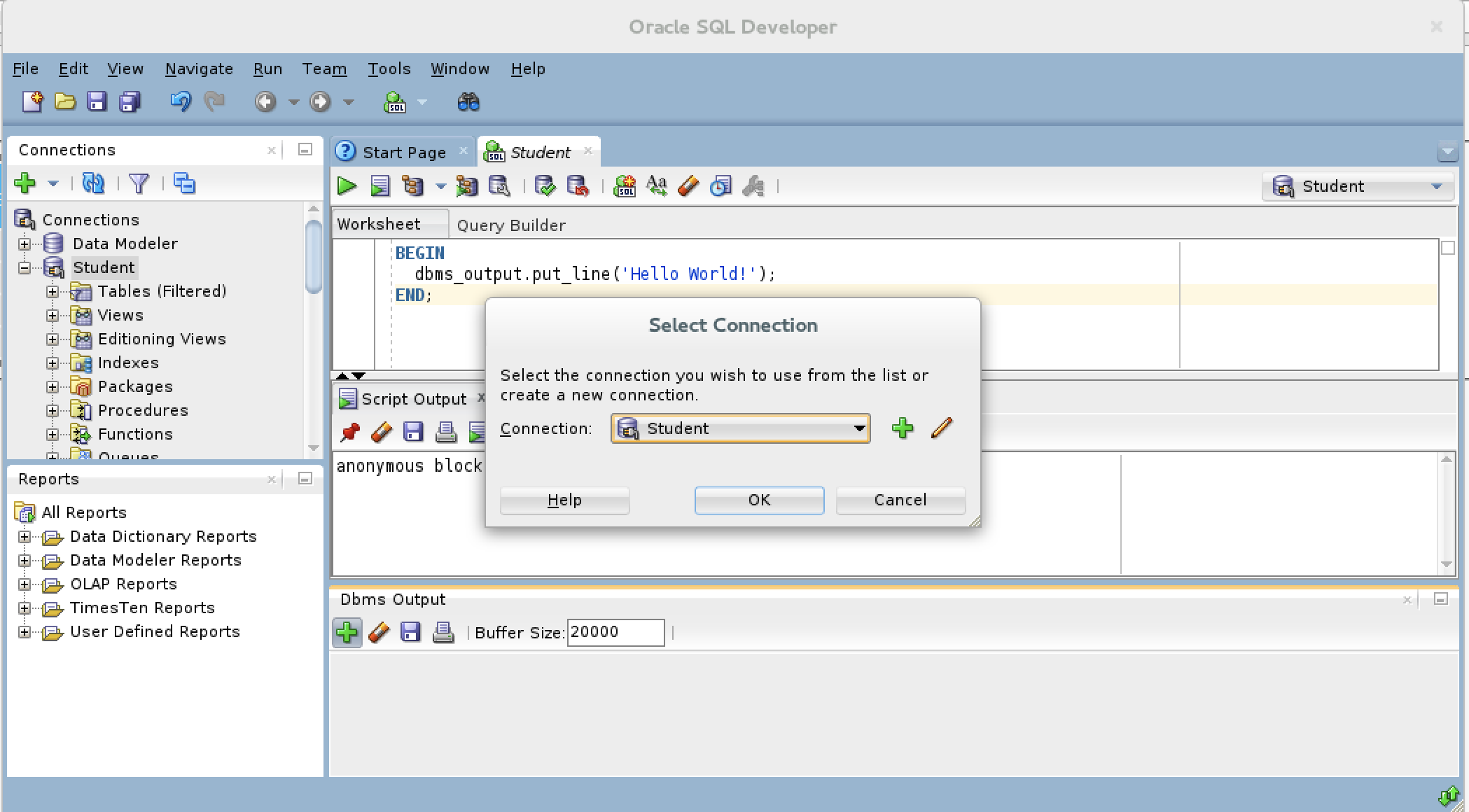
- After you click the Dbms Output view’s green arrow, you receive a Select Connection prompt for the view. Make sure you have the right user, and click the OK button to continue.
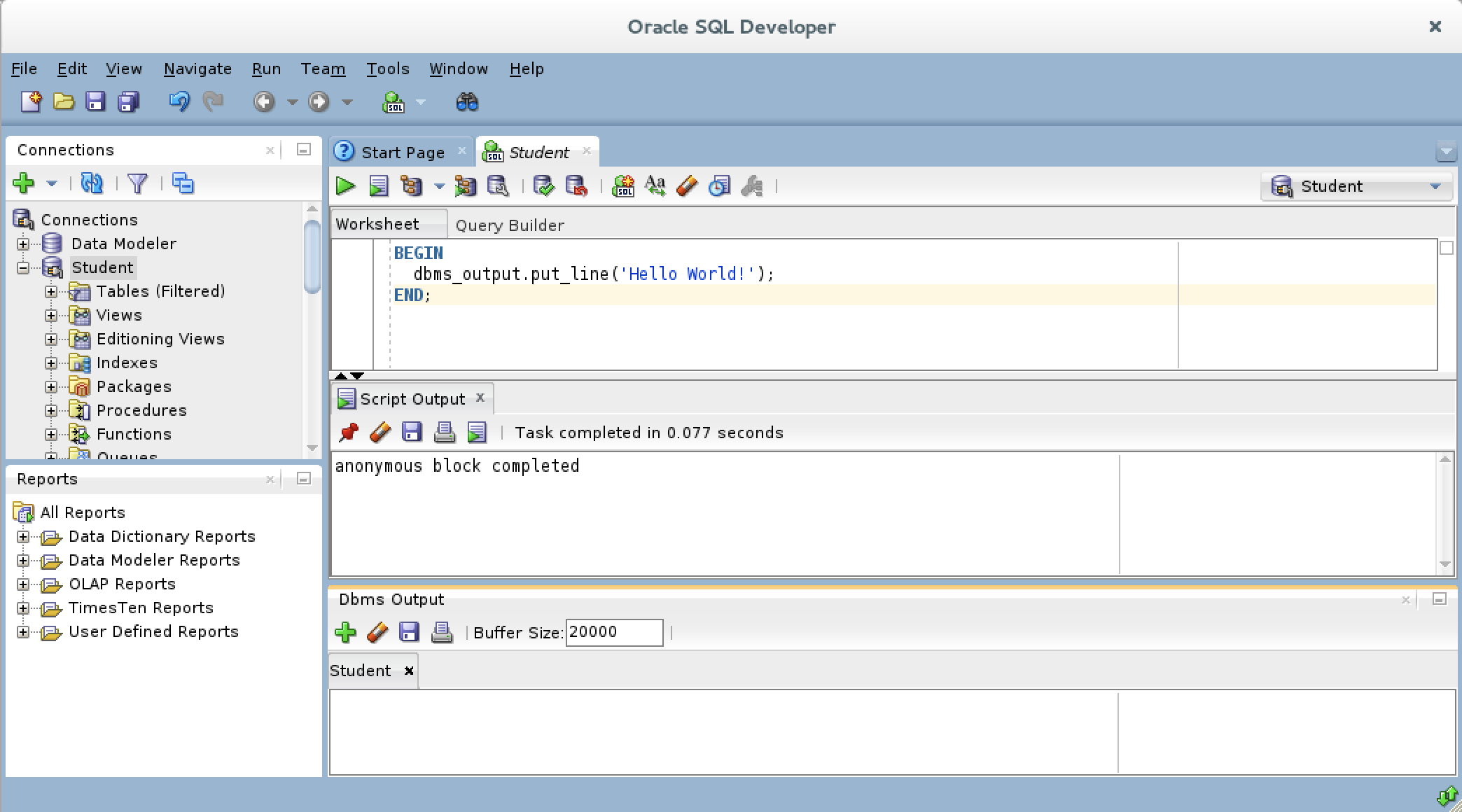
- After you create the connection for the Dbms Output stream, the view area becomes white rather than gray.
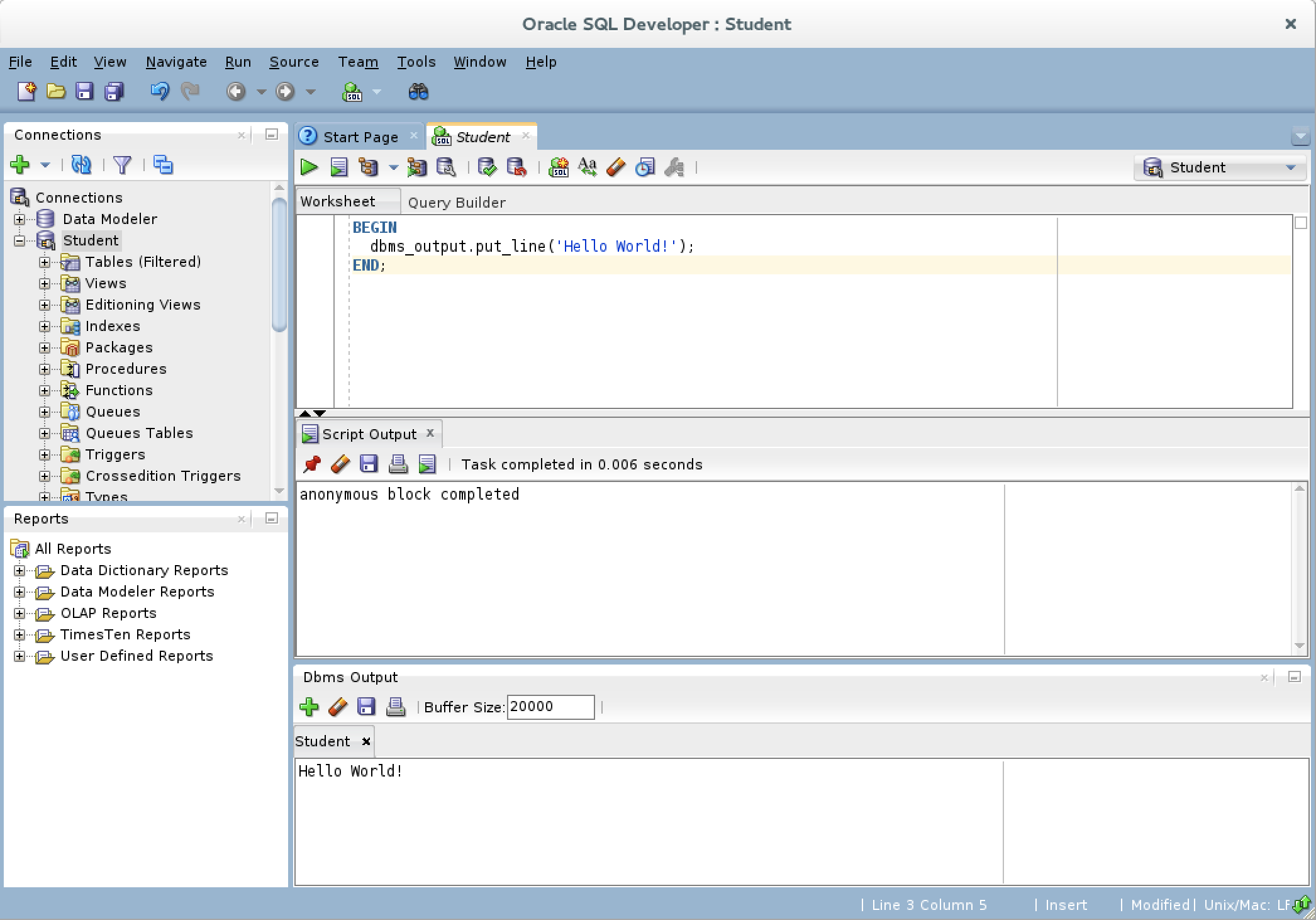
- Click the green arrow to start the statement and you will see the “Hello World!” string in the Dbms Output view.”
As always, I hope this helps those looking for a solution.
Using a Sparse Index
My vacation from my blog is officially over. The question that I’m answering today is: How can you pass a set of non-sequential ID values to a function and return a result set? You can solve the problem by passing an ADT (Attribute Data Type) or UDT (User Defined Type) variable into a subquery of a cursor. The subquery leverages the TABLE function to translate the ADT or UDT into SQL result set, which is equivalent to a comma-delimited list of values.
You can also solve this problem with Native Dynamic SQL (NDS). However, the person who posed the question didn’t want to use NDS to build out a variable length list of comma-delimited numbers.
You need to create three object types for this example. They are:
- a list of numbers
- a record structure, declared as an object type without methods
- a list of the record structure
These are the SQL commands to create the required data types:
CREATE OR REPLACE TYPE list_ids IS TABLE OF NUMBER; / |
CREATE OR REPLACE TYPE item_struct IS OBJECT ( item_id NUMBER , item_title VARCHAR2(80) , release_date DATE ); / |
CREATE OR REPLACE TYPE item_struct_list IS TABLE OF item_struct; / |
Next, you create a nonsynchronous function. It takes a sparsely populated list of values that map to the surrogate key of the column, which is typically the table’s primary key column. It returns a collection of the item_struct object type. This type of function is an object-table function.
The code follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | CREATE OR REPLACE FUNCTION nonsynchronous ( pv_list_ids LIST_IDS ) RETURN item_struct_list IS /* Declare a record data structure list. */ lv_struct_list ITEM_STRUCT_LIST := item_struct_list(); /* Declare a sparsely indexed list of film items. */ CURSOR get_items ( cv_list_ids LIST_IDS ) IS SELECT item_id AS item_id , item_title || CASE WHEN item_subtitle IS NOT NULL THEN ': '|| item_subtitle END AS item_title , release_date AS release_date FROM item WHERE item_id IN (SELECT * FROM TABLE(cv_list_ids)) ORDER BY item_id; BEGIN /* Lood through the sparsely populated list of numbers. */ FOR i IN get_items(pv_list_ids) LOOP lv_struct_list.EXTEND; lv_struct_list(lv_struct_list.COUNT) := item_struct( item_id => i.item_id , item_title => i.item_title , release_date => i.release_date ); END LOOP; /* Return the record structure list. */ RETURN lv_struct_list; END; / |
The foregoing nonsynchronous function uses a nested query that transforms to a result set on lines 18 and 19. In the execution block of the program, it uses a call to the item_struct structure to capture and assign row values to an element of the lv_struct_list variable.
You can now test the nonsynchronous function with the following query:
COL item_id FORMAT 9999 HEADING "Item|ID #" COL item_title FORMAT A40 HEADING "Item Title" COL release_date FORMAT A11 HEADING "Release|Date" SELECT * FROM TABLE(nonsynchronous(list_ids(1002, 1013, 1007))); |
The query returns the record set as an ordered list in the result set, like:
Item Release ID # Item Title Date ----- ---------------------------------------- ----------- 1002 Star Wars I: Phantom Menace 04-MAY-99 1007 RoboCop 24-JUL-03 1013 The DaVinci Code 19-MAY-06 |
I hope this answers the question about how to get results sets with sparsely populated ID values.
REGEXP_LIKE Behavior
Often, the biggest problem with regular expressions is that those who use them sometimes don’t use them correctly. A great example occurs in the Oracle Database with the REGEXP_LIKE function. For example, some developer use the following to validate whether a string is a number but it only validates whether the first character is a number.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | DECLARE lv_input VARCHAR2(100); BEGIN /* Assign input value. */ lv_input := '&input'; /* Check for numeric string. */ IF REGEXP_LIKE(lv_input,'[[:digit:]]') THEN dbms_output.put_line('It''s a number.'); ELSE dbms_output.put_line('It''s a string.'); END IF; END; / |
When they test numbers it appears to works, it even appears to work when the test string start with number, but it fails with any string that starts with a character. That’s because the REGEXP_LIKE function on line 8 only checks the first character, but the following checks all the characters in the string.
8 | IF REGEXP_LIKE(lv_inputs(i),'[[:digit:]]{'||LENGTH(lv_inputs(i))||'}') THEN |
You can also fix it with the following non-Posix solution:
8 | IF REGEXP_LIKE(lv_input,'[[0-9]]') THEN |
You can add a collection to the program and use it to test single-digit, double-digit, and string with a leading integer. Save the program as test.sql and you can test three conditions with one call.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | DECLARE /* Declare the local collection type. */ TYPE inputs IS TABLE OF VARCHAR2(100); /* Declare a local variable of the collection type. */ lv_inputs INPUTS; BEGIN /* Assign the inputs to the collection variable. */ lv_inputs := inputs('&1','&2','&3'); /* Read through the collection and print whether it's an number or string. */ FOR i IN 1..lv_inputs.COUNT LOOP IF REGEXP_LIKE(lv_inputs(i),'[[:digit:]]{'||LENGTH(lv_inputs(i))||',}') THEN dbms_output.put_line('It''s a number.'); ELSE dbms_output.put_line('It''s a string.'); END IF; END LOOP; END; / |
You can run the test.sql program like this:
SQL> @test.sql 1 12 1a |
It prints:
It's a number. It's a number. It's a string. |
As always, I hope this helps those looking for a solution.
Create MySQL Index
Indexes are separate data structures that provide alternate pathways to finding data. They can and do generally speed up the processing of queries and other DML commands, like the INSERT, UPDATE, REPLACE INTO, and DELETE statements. Indexes are also called fast access paths.
In the scope of the InnoDB Database Engine, the MySQL database maintains the integrity of indexes after you create them. The upside of indexes is that they can improve SQL statement performance. The downside is that they impose overhead on every INSERT, UPDATE, REPLACE INTO, and DELETE statement, because the database maintains them by inserting, updating, or deleting items for each related change in the tables that the indexes support.
Indexes have two key properties—usability and visibility. Indexes are both usable and visible by default. That means they are visible to the MySQL cost-based optimizer and usable when statements run against the tables they support.
You have the ability to make any index invisible, in which case queries and DML statements won’t use the index because they won’t see it. However, the cost-based optimizer still sees the index and maintains it with any DML statement change. That means making an index invisible isn’t quite like making the index unusable or like dropping it temporarily. An invisible index becomes overhead and thus is typically a short-term solution to run a resource-intensive statement that behaves better without the index while avoiding the cost of rebuilding it after the statement runs.
It is also possible to make an index unusable, in which case it stops collecting information and becomes obsolete and the database drops its index segment. You rebuild the index when you change it back to a usable index.
Indexes work on the principal of a key. A key is typically a set of columns or expressions on which you can build an index, but it’s possible that a key can be a single column. An index based on a set of columns is a composite, or concatenated, index.
Indexes can be unique or non-unique. You create a unique index anytime you constrain a column by assigning a primary key or unique constraint, but they’re indirect indexes. You create a direct unique index on a single column with the following syntax against two non-unique columns:
1 2 | CREATE INDEX common_lookup_u1 ON common_lookup (common_lookup_table) USING BTREE; |
You could convert this to a non-unique index on two columns by using this syntax:
1 2 | CREATE INDEX common_lookup_u1 ON common_lookup (common_lookup_table, common_lookup_column) USING BTREE; |
Making the index unique is straightforward;, you only need to add a UNIQUE key wordk to the CREATE INDEX statement, like
1 2 3 4 | CREATE UNIQUE INDEX common_lookup_u1 ON common_lookup ( common_lookup_table , common_lookup_column , common_lookup_type) USING BTREE; |
Most indexes use a B-tree (balanced tree). A B-tree is composed of three types of blocks—a root branch block for searching next-level blocks, branch blocks for searching other branch blocks, or and leaf blocks that store pointers to row values. B-trees are balanced because all leaf-blocks are at the same level, which means the length of search is the same to any element in the tree. All branch blocks store the minimum key prefix required to make branching decisions through the B-tree.
SQL*Plus Tricks
Have you ever wondered how to leverage substitution variables in anonymous block programs? There are several tricks that you can use beyond passing numeric and string values to local variable. The generic default appears to take a number unless you cast it as a string but that’s not really the whole story. The first two are standard examples of how to use numeric and string substitution values.
The following accept a numeric substitution value:
1 2 3 4 5 6 7 8 9 10 | DECLARE lv_input NUMBER; BEGIN /* Assign substitution value to local variable. */ lv_input := &input; /* Print the local variable. */ dbms_output.put_line('['||lv_input||']'); END; / |
The following accept a string substitution value, casts the input as a string, assigns the string value to a 4,000 character length local variable, checks whether the 4,000 character length is greater than 10, and assigns the first 10 characters to the lv_parse_input variable:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | DECLARE lv_unparsed_input VARCHAR2(4000); lv_parsed_input VARCHAR2(10); BEGIN /* Assign substitution value to local variable. */ lv_unparsed_input := '&input'; /* Check size of input value. */ IF LENGTH(lv_unparsed_input) > 10 THEN lv_parsed_input := SUBSTR(lv_unparsed_input,1,10); END IF; /* Print the local variable. */ dbms_output.put_line('Print {lv_parsed_input}: ['||lv_parsed_input||']'); END; / |
Next, let’s examine two tricks. The first passes a case insensitive variable name and the second passes a case sensitive variable name as a parameter to an anonymous block program.
This declares an anonymous block program that uses a substitution value as a variable name:
1 2 3 4 5 6 7 | DECLARE mine VARCHAR2(10) := 'Default'; BEGIN /* Print the local variable's value. */ dbms_output.put_line('Print {mine} variable value: ['||&input||']'); END; / |
When you run the anonymous block, you’re prompted for an input variable. You provide a case insensitive variable name as the input value:
Enter value for input: MINE
old 5: dbms_output.put_line('['||&input||']');
new 5: dbms_output.put_line('['||MINE||']');
Print {mine} variable value: [Default] |
The downside of this approach, yields an ORA-06550 and PLS-00201 exception. Neither of these can be caught because Oracle raises the errors during parsing when the variable name isn’t a 100% case insensitive match. The same type of problem occurs in the next example when the input variable isn’t a 100% case sensitive match.
You can rewrite the program to handle case insensitive variables like this:
1 2 3 4 5 6 7 | DECLARE "Mine" VARCHAR2(10) := 'Default'; BEGIN /* Print the local variable's value. */ dbms_output.put_line('Print {mine} variable value: ['||"&input"||']'); END; / |
When you run the anonymous block, you’re prompted for an input variable. You provide a case sensitive variable name as the input value:
Enter value for input: Mine
old 5: dbms_output.put_line('['||&input||']');
new 5: dbms_output.put_line('['||"Mine"||']');
Print {Mine} variable value: [Default] |
Hope this helps those looking for a solution.
Using CALIBRATE_IO
Using Oracle’s Resource Manager requires you to understand the IO dynamics. The first step requires you to run the CALIBRATE_IO procedure from the DBMS_RESOURCE_MANAGER package.
Oracle provides some great examples about how to use the CALIBRATE_IO procedure of the DBMS_RESOURCE_MANAGER package in the Oracle Database Database PL/SQL Packages and Types Reference. The CALIBRATE_IO procedure returns the best answer when you provide a valid number of files, which you can capture by querying the V$ASM_DISK view.
The following code queries the view and assigns the value to a session level variable:
CLEAR BREAKS CLEAR COLUMNS CLEAR COMPUTES VARIABLE files NUMBER BEGIN SELECT COUNT(DISTINCT name) disks INTO :files FROM v$asm_disk; END; / |
When you have the number of files, you can calibrate the IO with the following anonymous block. The query should always work but just in case the NVL function on line 9 assigns the default number of files.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | DECLARE lv_num_physical_disks BINARY_INTEGER; — v$asm_disk lv_max_latency BINARY_INTEGER := 10; lv_max_iops BINARY_INTEGER; lv_max_mbps BINARY_INTEGER; lv_actual_latency BINARY_INTEGER; BEGIN /* Assign actual files to anonymous block variable. */ lv_num_physical_disks := NVL(:files,2); /* Run the calibrate_io procedure. */ DBMS_RESOURCE_MANAGER.CALIBRATE_IO( num_physical_disks => lv_num_physical_disks , max_latency => lv_max_latency , max_iops => lv_max_iops , max_mbps => lv_max_mbps , actual_latency => lv_actual_latency); END; / |
You can query the results like this:
SELECT max_iops , max_mbps , max_pmbps , latency , num_physical_disks FROM dba_rsrc_io_calibrate; |
It should show results like these:
MAX_IOPS MAX_MBPS MAX_PMBPS LATENCY NUM_PHYSICAL_DISKS
-------- -------- --------- ------- ------------------
8894 443 294 9 18 |
Hope this helps those using the CALIBRATE_IO procedure of the DBMS_RESOURCE_MANAGER package.
Free Oracle Tuning Book
 Who can resist a free Rich Nimeiec book on SQL Tuning? O.K., those who know everything can resist. If you’re like me, this is an opportunity to learn from Rich. Click on the book image or this link to get a free copy, or if you want to pay $10 for a copy click here to buy Quick Start Guide to Oracle Query Tuning: Tips for DBAs and Developers
Who can resist a free Rich Nimeiec book on SQL Tuning? O.K., those who know everything can resist. If you’re like me, this is an opportunity to learn from Rich. Click on the book image or this link to get a free copy, or if you want to pay $10 for a copy click here to buy Quick Start Guide to Oracle Query Tuning: Tips for DBAs and Developers from Amazon.com.
The book is four chapters long, is a 129 pages in length, and is in a PDF format. The outline is:
- Query Tuning: Developer and Beginning DBA
- Query Tuning: Basics for DBAs and Developers
- Advanced Performance Tuning
- Tips for Tuning When You Have Everything Tuned
Enjoy reading it. His more comprehensive book is Oracle Database 11g Release 2 Performance Tuning Tips & Techniques (Oracle Press) and it’s $30, but it’s written for an advanced audience (more or less OCA or higher).
