Archive for the ‘C’ Category
Quick C How-to add .h
Somebody wanted a quick example of using a user-defined header file for a constant value. While I think there a lot of examples on the Internet already, here’s quick example.
You can define a header (or global.h) file in the local directory with the value of pi, like this:
1 2 | // A global header file for constants. double pi = 3.1415926535; |
Then, you can write a little circle.c program like so:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | #include <stdio.h> #include "global.h" int main() { int r; double area; // Get the radius. printf("Enter a radius in inches: "); scanf("%i",&r); // Calculate the area of a circle. area = pi * (r * r); // Print the radius and circle area. printf("Area of a %d inch circle is %lf square inches!\n",r,area); return(0); } |
The local global.h file is enclosed in double quotes rather than less than and great than symbols. You can compile circle.c like this on Linux, provided both files are in the same directory:
gcc -o circle circle.c |
According to the gcc-documentation, the priority for include <> is, on a “standard Unix system”, as follows:
/usr/local/include libdir/gcc/target/version/include /usr/target/include /usr/include |
You should chmod the circle file as executable and then you can run it like so:
./circle |
You’ll see more or less the following:
Enter a radius in inches: 3 Area of a 3 inch circle is 28.274334 square inches! |
As always, I hope the example helps those looking for a starting point.
IT Salary Thought
During the holidays, I check salaries for my students and the IT industry overall. I’m never surprised by the reality, after all salaries pay for return on skills and effort. Here’s my annual look, which some may find unkind but reality is seldom kind.
Before looking at IT salaries, it seems like a good opportunity to first look at the overall job market for Millennials in the United States. AOL provides a great graphic of the median income for Millennials (those born between 1981 and 1997), which is $18,000 to $43,000 a year:

That’s a stark contrast to Forbes’ statistics on the top college baccalaureate degrees. In fact, the top five with the highest salary are between $58 to $67 thousand a year. They are:
- Computer Science ………… $66,800
- Engineering ………………… $65,000
- Mathematics & Statistics … $60,300
- Economics ………………….. $58,600
- Finance ……………………… $58,000
Computer science, applied computer science, and information technology are probably lumped into the first category. Information systems, exposure without real skills, is a management degree and probably opens positions equivalent to the business degree at $50 thousand a year. More or less, that’s a nine thousand dollar difference between having real skills and being able to talk the game and supervise technical resources. (The 10 hottest IT skills for 2015 are listed in Computerworld.)
There’s no surprise that Ruby, Objective C (iPhone, iPad, Mac OS X), Python, Java, C++ are at the top of the pyramid. Starting salaries in the Salt Lake area are higher for programmers college than they are for other computer science skill sets. In fact, my informal contacts peg them as starting at $70+ thousand. That’s higher than Forbes average for computer science. Here’s a visual on experienced programmers by language:

It seems fair to say that a computer science, applied computer science, and information technology degree with an emphasis in real programming skills is the best bet to pay off student loans. However, some will wait for politicians to do that for them, but really that’s quite unlikely, isn’t it?
Reality is always blunt. Reality also seems to frequently differs from what politicians say. After all, politicians pander to audiences, which generally means they say a great deal of nonsense. Nonsense like economics doesn’t matter, everyone should earn the same regardless of their education, skills, or work ethic. Aldous Huxley said it more elegantly when he said, “That all men are equal is a proposition to which, at ordinary times, no sane human being has ever given his assent.”
C Shared Libraries
I wrote a shared C library example to demonstrate external procedures in the Oracle Database 11g PL/SQL Programming book. I also reused the same example to demonstrate Oracle’s external procedures in the Oracle Database 12c PL/SQL Advanced Programming Techniques book last year. The example uses a C Shared Library but a PL/SQL wrapper and PL/SQL test case.
One of my students asked me to simplify the unit test case example by writing the complete unit test in the C Progamming Language. The student request seemed like a good idea, and while poking around on the web it appears there’s a strong case for a set of simple shared C library examples. This blog post isn’t meant to replace the C Programming web site and C Programming Tutorial web site, which I recommend as a great reference point.
Like most things, the best place to start is with basics of C programming because some readers may be very new to C programming. I’ll start with basic standalone programs and how to use the gcc compiler before showing you how to use shared C libraries.
The most basic program is a hello.c program that serves as a “Hello World!” program:
1 2 3 4 5 | #include <stdio.h> int main() { printf("Hello World!\n"); return(0); } |
Assuming you put the C source files in a src subdirectory and the executable files in a bin subdirectory. You compile the program with the gcc program from the parent directory of the src and bin subdirectories, as follows:
gcc -o bin/hello src/hello.c |
Then, you execute the hello executable program from the parent directory as follows:
bin/hello |
It prints:
Hello World! |
You can modify the basic Hello World! program to accept a single input word, like this hello_whom.c program:
1 2 3 4 5 6 7 8 9 10 11 12 | #include <stdio.h> /* The executable main method. */ int main() { // Declare a character array to hold an input value. char whom[30]; /* Print a question and read a string input. */ printf("Who are you? "); scanf("%s", whom); printf("Hello %s!\n", whom); return(0); } |
You can compile the hello_whom.c program as follows:
gcc -o bin/hello_whom src/hello_whom.c |
Then, you execute the hello_whom executable program from the parent directory as follows:
bin/hello_whom
Who are you? Stuart |
It prints:
Hello Stuart! |
Alternatively, you can modify the hello_whom.c program to accept a stream of text, like the following hello_string.c program:
1 2 3 4 5 6 7 8 9 10 11 12 | #include <stdio.h> /* The executable main method. */ int main() { // Declare a character array to hold an input name. char phrase[4000]; /* Print a question and read a string input. */ printf("Hello? "); scanf("%[^\n]%*c", phrase); printf("Hello %s!\n", phrase); return(0); } |
The [] is the scan set character. The [^\n] on line 10 defines the input as not a newline with a white space, and the %*c reads the newline character from the input buffer. After you compile the program you can call it like this:
bin/hello_string
Hello? there, it reads like a C++ stream |
It would print:
Hello there, it reads like a C++ stream! |
These example, like the previous examples, assume the source files are in a src subdirectory and the executable files are in the bin subdirectory. All compilation commands are run from the parent directory of the src and bin subdirectories.
The first example puts everything into a single writingstr.c file. It defines a writestr() function prototype before the main() function and the writestr() function after the main() function.
The code follows below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #include <stdio.h> /* Declare two integer variables. */ char path[255], message[4000]; /* Define a prototype for the writestr() function. */ void writestr(char *path, char *message); /* The executable main method. */ int main() { printf("Enter file name and message: "); scanf("%s %[^\n]%*c", &path, &message); printf("File name: %s\n", path); printf("File content: %s\n", message); writestr(path, message); return(0); } void writestr(char *path, char *message) { FILE *file_name; file_name = fopen(path,"w"); fprintf(file_name,"%s\n",message); fclose(file_name); } |
You can compile the writingstr.c function with the following syntax:
gcc -o bin/writingstr src/writingstr.c |
You can run the writingstr executable file with the following syntax:
bin/writingstr Enter file name and message: /home/student/Code/c/test.txt A string for a file. File name: /home/student/Code/c/test.txt File content: A string for a file. |
You’ll find a test.txt file written to the /home/student/Code/C directory. The file contains only the single sentence fragment entered above.
Now, let’s create a writestr.h header file, a writestr.c shared object file, and a main.c testing file. You should note a pattern between the self-contained code and the approach for using shared libraries. The prototype of the writestr() function becomes the definition of the writestr.h file, and the implementation of the writestr() function becomes the writestr.so shared library.
The main.c file contains the only the main() function from the writingstr.c file. The main() function uses the standard scanf() function to read a fully qualified file name (also known as a path) as a string and then a text stream for the content of the file.
You define the writestr.h header file as:
1 2 3 4 5 6 | #ifndef writestr_h__ #define writestr_h__ extern void writestr(char *path, char *message); #endif |
You define the writestr.c shared library, which differs from the example in the book. The difference is the #include statement of the writestr.h header file. The source code follows:
1 2 3 4 5 6 7 8 | #include <stdio.h> #include "writestr.h" void writestr(char *path, char *message) { FILE *file_name; file_name = fopen(path,"w"); fprintf(file_name,"%s\n",message); fclose(file_name); } |
You define the main.c testing program as:
1 2 3 4 5 6 7 8 9 10 11 12 | #include <stdio.h> #include "writestr.h" /* Declare two integer variables. */ char path[255], message[4000]; /* The executable main method. */ int main() { printf("Enter file name and message: "); scanf("%s %[^\n]%*c", &path, &message); writestr(path, message); return(0); } |
Before you begin the process to compile these, you should create an environment file that sets the $LD_LIBRARY_PATH environment variable or add it to your .bashrc file. You should point the $LD_LIBRARY_PATH variable to the directory where you’ve put your shared libraries.
# Set the LD_LIBRARY_PATH environment variable. export LD_LIBRARY_PATH=/home/student/Code/c/trylib/libfile |
With programs defined, you need to first compile the writestr.c shared library first. You use the following syntax from the parent directory of the src and bin subdirectories.
gcc -shared -fPIC -o bin/writestr.so src/writestr.c |
If you haven’t set the $LD_LIBRARY_PATH, you may raise an exception. There’s also an alternative to setting the $LD_LIBRARY_PATH before you call the gcc executable. You can use the -L option set the $LD_LIBRARY_PATH for a given all to the gcc executable, like:
gcc -L /home/student/Code/c/trylib/libfile -shared -fPIC -o bin/writestr.so src/writestr.c |
Then, you compile the main.c program. You must put the writestr.so shared library before you designate the main target object and main.c source files, like this:
gcc bin/writestr.so -o bin/main src/main.c |
Now, you can perform a C-only unit test case by calling the main executable. However, you must have set the $LD_LIBRARY_PATH environment variable at runtime too. You see the following reply to the “Enter file name and message” question when you run the main program unit:
bin/main Enter file name and message: /home/student/Code/c/trylib/libfile/test.txt A long native string is the second input to this C program. |
You can now see that the a new test.txt file has been written to the target directory, and that it contains the following string:
A long native string is the second input to this C program. |
As always, I hope this helps those you want to write shared libraries in the C programming language.
Popular Programming Languages
First of all, Happy New Year!
IEEE Spectrum published a ranking of the most popular programming languages. Computational journalist Nick Diakopoulos wrote the article. While it may surprise some, I wasn’t surprised to find SQL in the top ten.
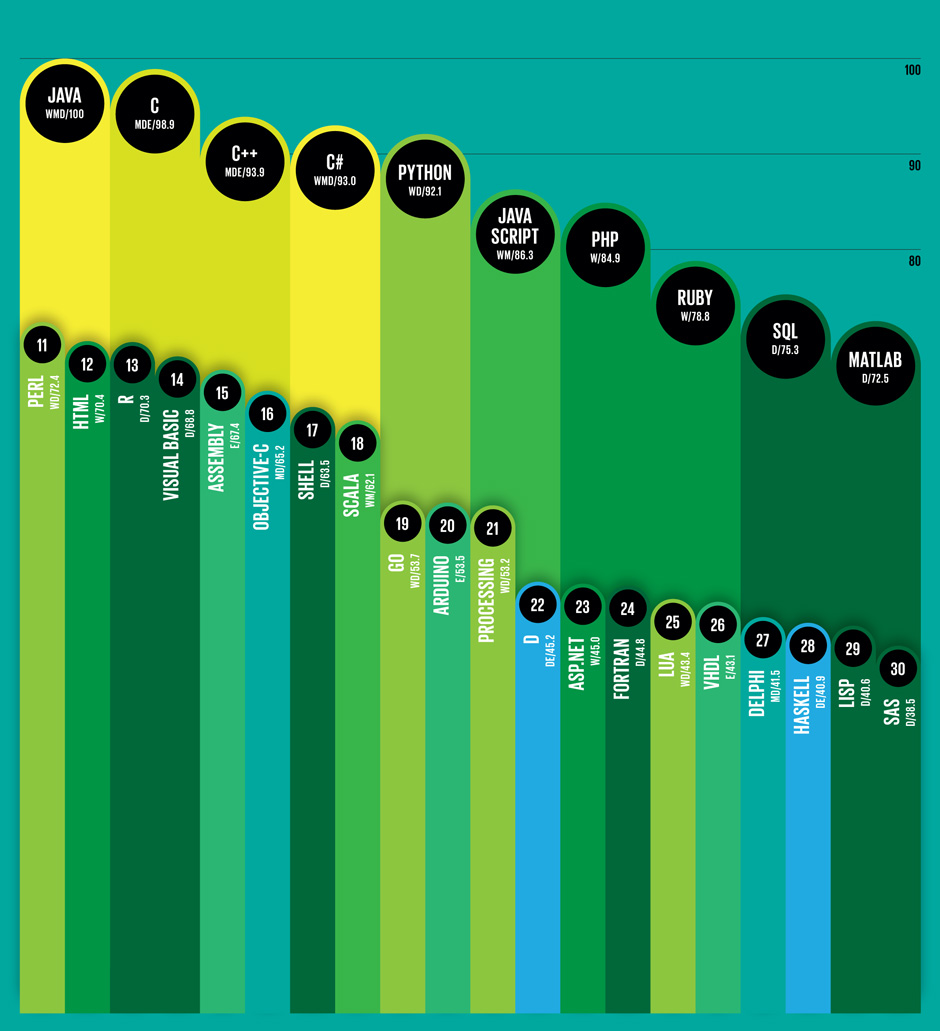 Nick weighted and combined 12 metrics from 10 sources (including IEEE Xplore, Google, and GitHub) to rank the most popular programming languages.
Nick weighted and combined 12 metrics from 10 sources (including IEEE Xplore, Google, and GitHub) to rank the most popular programming languages.
- Compiled programming languages (Java [#1], C [#2], C++ [#3], C# [#4], Objective-C [#16])
- Interpreted programming languages (Python [#5], JavaScript [#6], PHP [#7], Ruby [#8], Perl [#11], HTML [#12])
- Data languages (SQL [#9], MATLAB [#10], R [#13])
I couldn’t resist including Objective-C because it shows how the iPhone, iPad, and Mac OS impact our daily lives. At the same time, Assembly [#15] is actually more popular than Objective-C. Shell [#17] follows Objective-C. While the Visual Basic [#14] programming language still remains very popular.
There are many “why” questions raised by this list of popular programming languages. The “why” from my perspective deals with what are the market drivers for their popularity. The money drivers I see are as follows:
- Business software: Java, C++, C#, and AIDE – Android IDE (works with Java and C++ source code)
- OS X and iOS Development: Objective-C
- Development Tools: Java, C, C++, and Python
- System Admin/Utilities Tools: C, Perl, and Shell
- Web Development: Python, PHP, Ruby, and Perl
- Data Analysis: SQL, MATLAB, and R
Business Intelligence (BI) software manages most high-level data analysis tools and they’ll continue to get better over time. However, if SQL has shown us anything over 30 years it’s that ultimately we revert to it to solve problems. The conclusion from the reality of BI probably means the programming languages that develop those tools will continue to rise and so will the underlying data languages.
It’s also interesting to note that nine out of ten of the popular programming languages work with databases, like Oracle, MySQL, PostgreSQL, or SQL Server. While JavaScript doesn’t access the database typically, it’s JSON (JavaScript Object Notation) is supported in all the databases.
Why Stored Programs?
Why should you use stored programs? Great question, here’s my little insight into a situation that I heard about in a large organization.
A very large organization is having a technology argument. In someway, like politics, half-truth drives this type of discussion. This company has hundreds of databases and they’re about half SQL Server and Oracle. The argument (half-truth) states that using T-SQL or PL/SQL yields “spaghetti” code!
It seems like an old argument from my perspective. After all, I’ve been working with T-SQL and PL/SQL for a long time. Spaghetti code exists in every language when unskilled programmers solve problems but the point here is one of software architecture, and an attempt to malign stored programming in general. Let’s examine the merit of the argument against stored programs.
First of all, the argument against stored programs is simply not true. SQL DML statements, like the INSERT, UPDATE, and DELETE statements should maintain ACID compliant interactions with a single table in a database. Unfortunately, the same statements create anomalies (errors) in a poorly designed database.
Stored programs provide the ability to perform ACID compliant interactions across a series of tables in a database. They may also hide database design errors and protect the data from corruption. The same can’t be said for Java or C# developers. Java and C# developers frequently fail to see database design errors or they overlook them as inconsequential. This type of behavior results in corrupt data.
It typically raises cost, errors, and overall application complexity when key logic migrates outside the database. If you’re asking why, that’s great. Here are my thoughts on why:
- Making a Java or C# programmer responsible for managing the transaction scope across multiple tables in a database is not trivial. It requires a Java programmer that truly has mastered SQL. As a rule, it means a programmer writes many more lines of logic in their code because they don’t understand how to use SQL. It often eliminates joins from being performed in the database where they would considerably outperform external language operations.
- Identifying bottlenecks and poor usage of data becomes much more complex for DBAs because small queries that avoid joins don’t appear problematic inside the database. DBAs don’t look at the execution or scope of transactions running outside of the database and you generally are left with anecdotal customer complaints about the inefficiency of the application. Therefore, you have diminished accountability.
- Developing a library of stored procedures (and functions) ensures the integrity of transaction management. It also provides a series of published interfaces to developers writing the application logic. The published interface provides a modular interface, and lets developers focus on delivering quality applications without worrying about the database design. It lowers costs and increases quality by focusing developers on their strengths rather than trying to make them generalists. That having been said, it should never mask a poorly designed database!
- Service level agreements are critical metrics in any organization because they compel efficiency. If you mix the logic of the database and the application layer together, you can’t hold the development team responsible for the interface or batch processing metrics because they’ll always “blame” the database. Likewise, you can’t hold the database team responsible for performance when their metrics will only show trivial DML statement processing. Moreover, the DBA team will always show you that it’s not their fault because they’ve got metrics!
- Removing transaction controls from the database server generally means you increase the analysis and design costs. That’s because few developers have deep understanding of a non-database programming language and the database. Likewise, input from DBAs is marginalized because the solution that makes sense is disallowed by design fiat. Systems designed in this type of disparate way often evolve into extremely awkward application models.
Interestingly, the effective use of T-SQL or PL/SQL often identifies, isolates, and manages issues in poorly designed database models. That’s because they focus on the integrity of transactions across tables and leverage native database features. They also act like CSS files, effectively avoiding the use of inline style or embedded SQL and transaction control statements.
Let’s face this fact; any person who writes something like “spaghetti” code in the original context is poorly informed. They’re typically trying to sidestep blame for an existing bad application design or drive a change of platform without cost justification.
My take on this argument is two fold. Technologists in the organization may want to dump what they have and play with something else; or business and IT management may want to sidestep the wrath of angry users by blaming their failure on technology instead of how they didn’t design, manage, or deliver it.
Oh, wait … isn’t that last paragraph the reason for the existence of pre-package software? 😉 Don’t hesitate to chime in, after all it’s just my off-the-cuff opinion.
Bioinformatics Conference
This week I attended the first ACM conference on Bioinformatics and Computational Biology in Niagara Falls, NY. The next conference is in Rome next January. It was interesting to note who’s using what technology in their research.
Here’s a breakdown:
- Databases: MySQL is the de facto winner for research. Oracle for clinical systems, mostly Oracle 10g implementations. That means moving data between the two is a critical skill. Specifically, exporting data from Oracle and importing it into MySQL. Oracle was criticized for being a DBA-preserve and unfriendly to development. When I probed this trend, it seemed to point to DBAs over managing sandbox instances at companies with site licenses. Microsoft SQL Server didn’t find a lot of popularity in the research community.
- Programming Skills: C#, C++, Objective-C and PHP were high on the list. C# to import data into Microsoft SharePoint and develop Windows SmartPhones. C++ to extend MySQL. Objective-C to develop iPhone and iPad applications. PHP to build applications to manage studies and facilitate input, but there were a couple using Perl (not many).
- Collaboration Tools: Microsoft SharePoint won handily. It’s made a home in the clinical and research communities.
Overall, they want programmers who understand biology and chemistry. They’d like knowledge through Medical Microbiology and Introductory Biochemistry, and they want strong math and statistical knowledge in their programming staff. They like Scrum development frameworks. They seem to emphasize a chief engineering team, which means the developers get maximum face-time with the domain experts. The developers also have to speak and walk the talk of science to be very successful.
As to Niagara Falls, I’m glad that I took my passport. The Canadian side is where I spent most of my extra time and money. It has the best views of the falls, the best food, and ambiance. Goat Island and the Cave of the Winds are the only two features I really liked on the U.S. side of Niagara Falls. The U.S. side is dreary unless you like gambling in the Seneca Niagara Casino & Hotel. Since I’m originally from Nevada, I never entered it to check it out. Technically, when you step on the casino property you enter the Seneca Nation of New York. The New York state government in Albany really needs to address the imbalance or they’ll continue to see Canada score the preponderance of tourist dollars.
External C Procedure
Somebody wanted to know how to write an external procedure in C. I entered the reply as a comment and then thought it would be better as a blog post. Here are the instructions for deploying and calling an external procedure.
The quick list of things to do, summarized from Chapter 13 on External Procedures from my Oracle Database 11g PL/SQL Programming book are:
1. Configure your tnsnames.ora file with a callout listener, which is required because the IPC/TCP layers must be separated. That means your LISTENER should only support the TCP protocol, which means you’ll remove the IPC line from your listener.ora file. If you fail to take this step, you’ll encounter the following error:
ORA-28595: Extproc agent: Invalid DLL Path |
Your callout listener has two parts, the CALLOUT_LISTENER and the SID_LIST_CALLOUT_LISTENER listener. Your listener.ora file should look like this:
CALLOUT_LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = IPC) (KEY = extproc) ) ) ) ) SID_LIST_CALLOUT_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME = PLSExtProc) (ORACLE_HOME = <oracle_home_directory>) (PROGRAM = extproc) (ENV = "EXTPROC_DLLS=ONLY:/<customlib>/writestr1.so,LD_LIBRARY_PATH=/lib") ) ) |
2. You also need to have a tnsnames.ora file with an instance TNS alias and EXTPROC alias, like:
ORCL = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP) (HOST = <host_name>.<domain_name>) (PORT = 1521) ) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = <database_sid>) ) ) EXTPROC_CONNECTION_DATA = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = IPC) (KEY = EXTPROC) ) ) (CONNECT_DATA = (SID = PLSExtProc) (PRESENTATION = RO) ) ) |
3. Create a shared library, like this:
#include <stdio.h> void writestr(char *path, char *message) { FILE *file_name; file_name = fopen(path,"w"); fprintf(file_name,"%s\n",message); fclose(file_name); } |
4. In Linux, compile the shared library from Step #1 with the following syntax:
gcc -shared -o writestr1.so writestr1.c |
If you encounter an error like this:
/usr/bin/ld: /tmp/ccTIWHVA.o: relocation R_X86_64_32 against `.rodata' can not be used when making a shared object; recompile with -fPIC /tmp/ccTIWHVA.o: could not read symbols: Bad value collect2: ld returned 1 exit status |
Then, use this alternative syntax:
gcc -shared -fPIC -o writestr.so writestr.c |
5. Create a library. Granting CREATE LIBRARY is a potentially large security risk, and a DBA should put all external procedure libraries in a single schema with additional monitoring protocols.
CREATE [OR REPLACE] LIBRARY library_write_string AS | IS '/<customlib>/writestr1.so |
6. Write a wrapper to the library.
CREATE OR REPLACE PROCEDURE write_string ( PATH VARCHAR2, message VARCHAR2 ) AS EXTERNAL LIBRARY library_write_string NAME "writestr" PARAMETERS (PATH STRING, message STRING); |
7. Call the wrapper procedure with valid values:
BEGIN write_string('/tmp/file.txt','Hello World!'); END; / |
Hope this helps some folks.
