Archive for the ‘Postgres DBA’ tag
AlmaLinux+PostgreSQL
This installs PostgreSQL 15 on AlmaLinux 9 (don’t forget the PostgreSQL 15 Documentation site). The executable is available in the script that the postgresql.org provides; however, it seems appropriate to show how to find that script for any platform.
When you launch the postgres.org web site, you will see the following dialog. Click the Download-> button to choose an operating system.
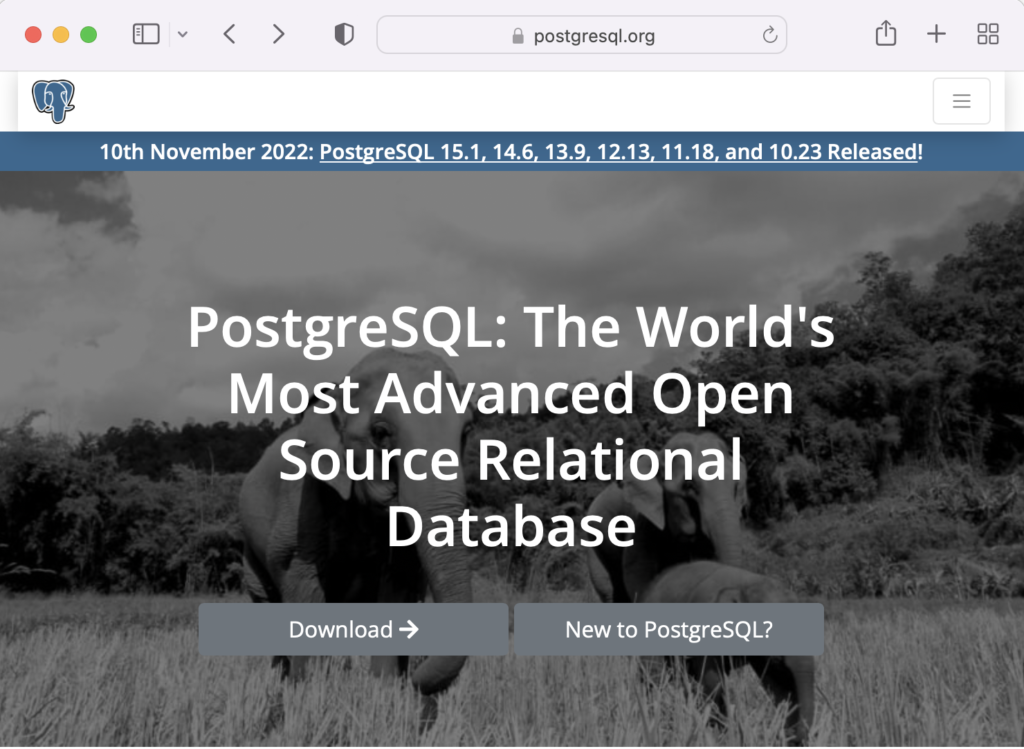
On the next webpage, click on the Linux icon button to proceed.
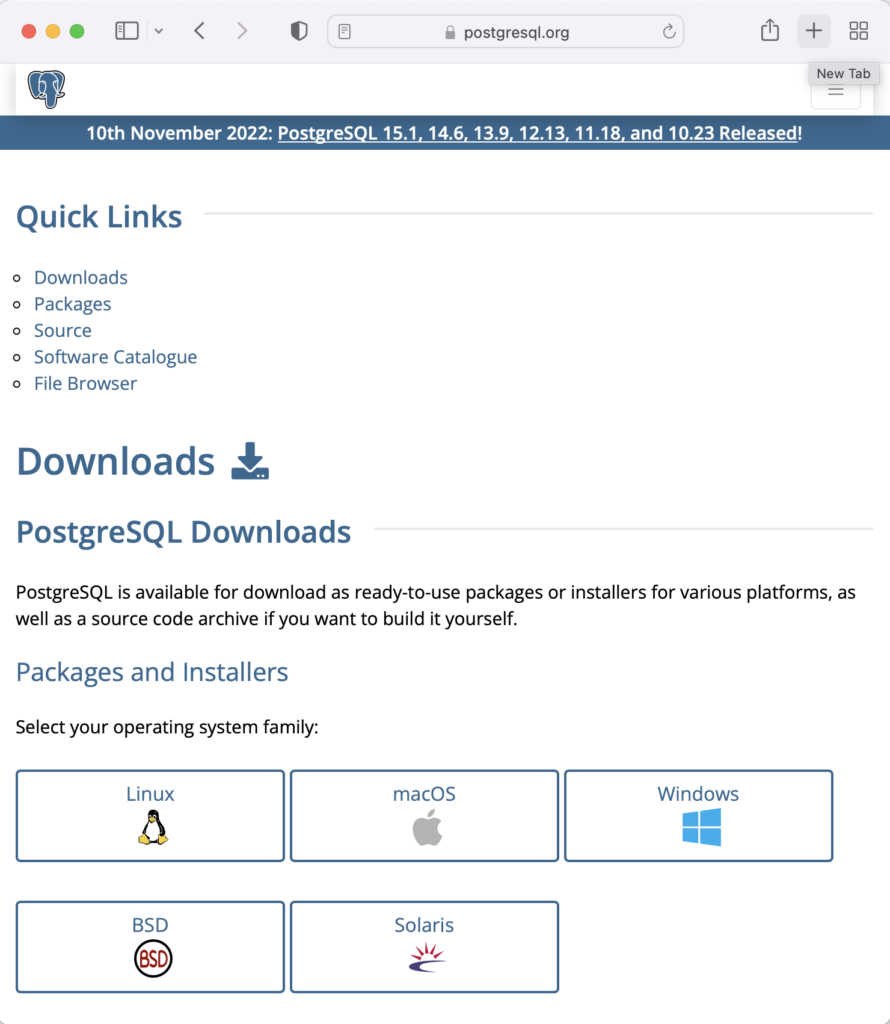
This page expands for you to choose a Linux distribution. Click on the Red Hat/Rocky/CentOS button to proceed.
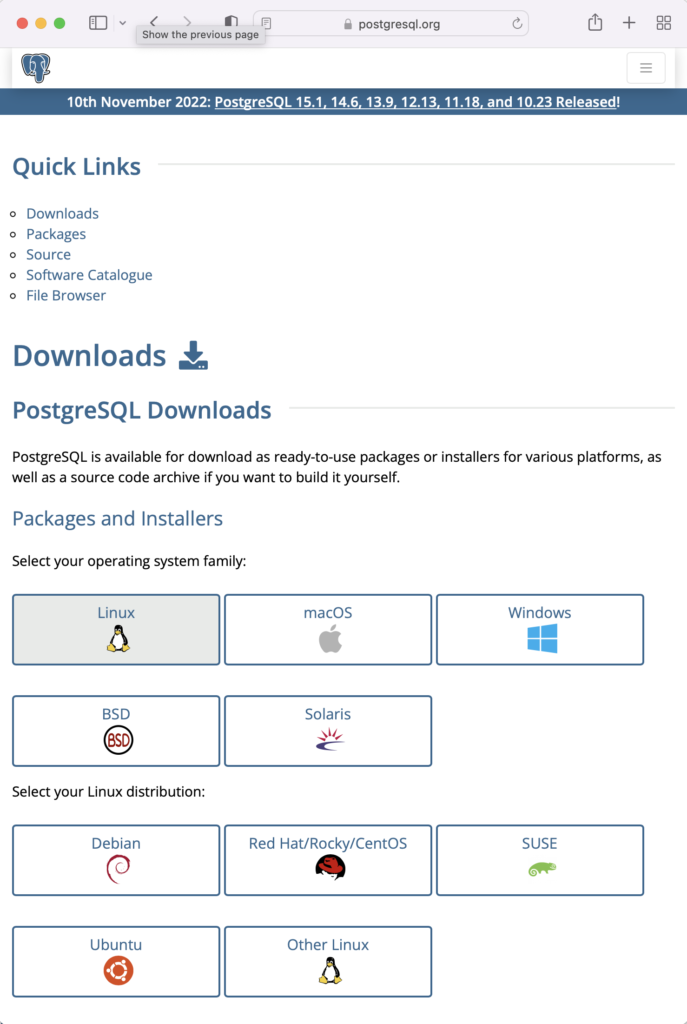
This web page lets you choose a platform, which should be Red Hat Enterprise, Rocky, or Oracle version 9.
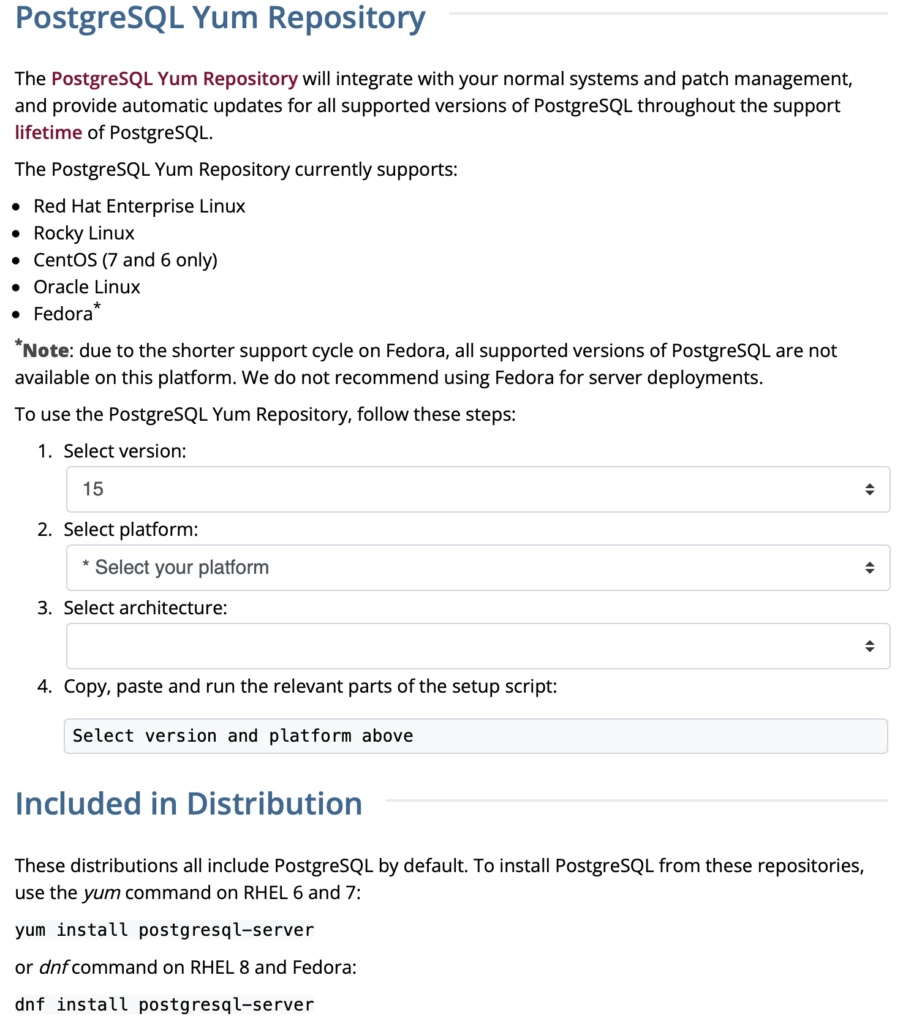
The selection fills out the web page and provides a setup script. The script installs the PostgreSQL packages, disables the built-in PostgreSQL module, installs PostgreSQL 15 Server, initialize, enable, and start PostgreSQL Server.
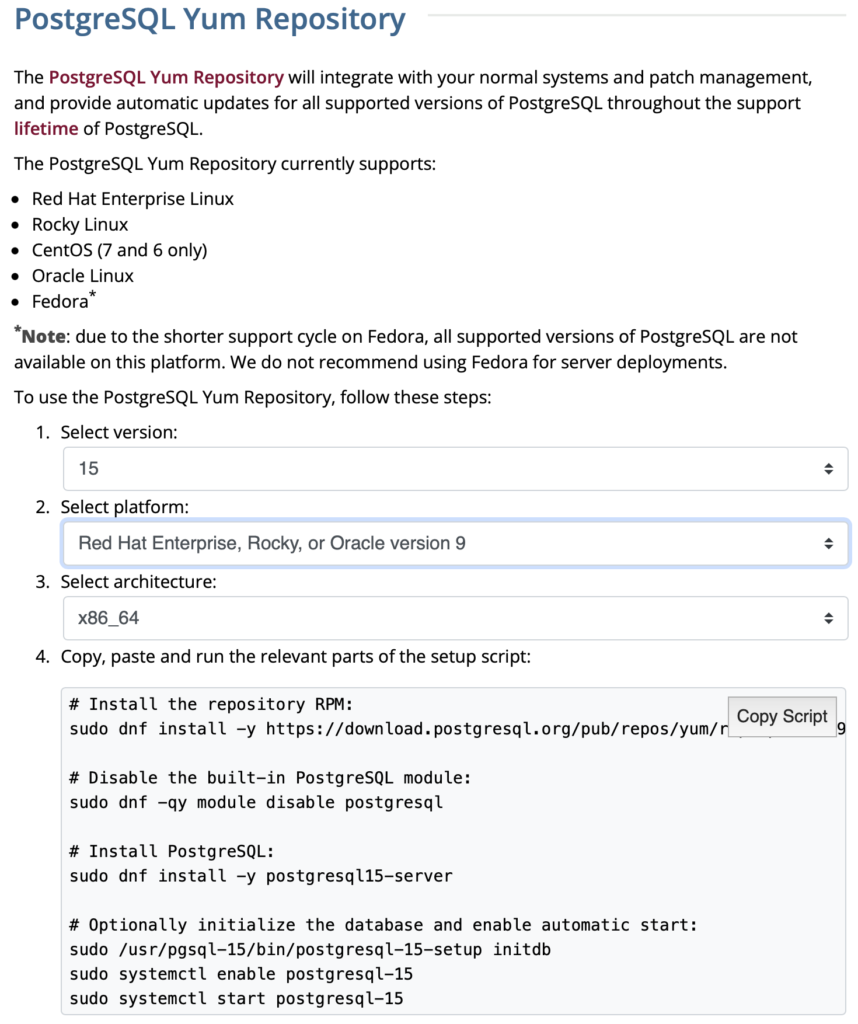
Here are the detailed steps:
- Install the PostgreSQL by updating dependent packages before installing it with the script provided by the PostgreSQL download web site:
# Install the repository RPM: sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm # Disable the built-in PostgreSQL module: sudo dnf -qy module disable postgresql # Install PostgreSQL: sudo dnf install -y postgresql15-server # Optionally initialize the database and enable automatic start: sudo /usr/pgsql-15/bin/postgresql-15-setup initdb sudo systemctl enable postgresql-15 sudo systemctl start postgresql-15
Display detailed console log →
Last metadata expiration check: 20:38:10 ago on Mon 21 Nov 2022 02:07:25 AM EST. pgdg-redhat-repo-latest.noarch.rpm 3.6 kB/s | 12 kB 00:03 Dependencies resolved. ================================================================================ Package Architecture Version Repository Size ================================================================================ Installing: pgdg-redhat-repo noarch 42.0-28 @commandline 12 k Transaction Summary ================================================================================ Install 1 Package Total size: 12 k Installed size: 14 k Downloading Packages: Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : pgdg-redhat-repo-42.0-28.noarch 1/1 Verifying : pgdg-redhat-repo-42.0-28.noarch 1/1 Installed: pgdg-redhat-repo-42.0-28.noarch Complete! Last metadata expiration check: 20:38:10 ago on Mon 21 Nov 2022 02:07:25 AM EST. pgdg-redhat-repo-latest.noarch.rpm 3.6 kB/s | 12 kB 00:03 Dependencies resolved. ================================================================================ Package Architecture Version Repository Size ================================================================================ Installing: pgdg-redhat-repo noarch 42.0-28 @commandline 12 k Transaction Summary ================================================================================ Install 1 Package Total size: 12 k Installed size: 14 k Downloading Packages: Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : pgdg-redhat-repo-42.0-28.noarch 1/1 Verifying : pgdg-redhat-repo-42.0-28.noarch 1/1 Installed: pgdg-redhat-repo-42.0-28.noarch Complete! Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Unable to resolve argument postgresql Error: Problems in request: missing groups or modules: postgresql Last metadata expiration check: 0:00:02 ago on Mon 21 Nov 2022 10:46:16 PM EST. Dependencies resolved. ================================================================================ Package Arch Version Repository Size ================================================================================ Installing: postgresql15-server x86_64 15.1-1PGDG.rhel9 pgdg15 6.0 M Installing dependencies: lz4 x86_64 1.9.3-5.el9 baseos 58 k postgresql15 x86_64 15.1-1PGDG.rhel9 pgdg15 1.5 M postgresql15-libs x86_64 15.1-1PGDG.rhel9 pgdg15 296 k Transaction Summary ================================================================================ Install 4 Packages Total download size: 7.8 M Installed size: 33 M Downloading Packages: (1/4): lz4-1.9.3-5.el9.x86_64.rpm 91 kB/s | 58 kB 00:00 (2/4): postgresql15-libs-15.1-1PGDG.rhel9.x86_6 97 kB/s | 296 kB 00:03 (3/4): postgresql15-15.1-1PGDG.rhel9.x86_64.rpm 214 kB/s | 1.5 MB 00:07 (4/4): postgresql15-server-15.1-1PGDG.rhel9.x86 371 kB/s | 6.0 MB 00:16 -------------------------------------------------------------------------------- Total 446 kB/s | 7.8 MB 00:17 PostgreSQL 15 for RHEL / Rocky 9 - x86_64 1.4 MB/s | 1.7 kB 00:00 Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Key imported successfully Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : postgresql15-libs-15.1-1PGDG.rhel9.x86_64 1/4 Running scriptlet: postgresql15-libs-15.1-1PGDG.rhel9.x86_64 1/4 Installing : lz4-1.9.3-5.el9.x86_64 2/4 Installing : postgresql15-15.1-1PGDG.rhel9.x86_64 3/4 Running scriptlet: postgresql15-15.1-1PGDG.rhel9.x86_64 3/4 Running scriptlet: postgresql15-server-15.1-1PGDG.rhel9.x86_64 4/4 Installing : postgresql15-server-15.1-1PGDG.rhel9.x86_64 4/4 Running scriptlet: postgresql15-server-15.1-1PGDG.rhel9.x86_64 4/4 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Verifying : lz4-1.9.3-5.el9.x86_64 1/4 Verifying : postgresql15-15.1-1PGDG.rhel9.x86_64 2/4 Verifying : postgresql15-libs-15.1-1PGDG.rhel9.x86_64 3/4 Verifying : postgresql15-server-15.1-1PGDG.rhel9.x86_64 4/4 Installed: lz4-1.9.3-5.el9.x86_64 postgresql15-15.1-1PGDG.rhel9.x86_64 postgresql15-libs-15.1-1PGDG.rhel9.x86_64 postgresql15-server-15.1-1PGDG.rhel9.x86_64 Complete! Initializing database ... /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 OK Created symlink /etc/systemd/system/multi-user.target.wants/postgresql-15.service → /usr/lib/systemd/system/postgresql-15.service.
- The simpmlest way to verify the installation is to check for the psql executable. You can do that with this command:
which psqlIt should return:
/usr/bin/psql
- Attempt to login with the following command-line interface (CLI) syntax:
psql -U postgres -W
It should fail and return the following:
psql: error: connection to server on socket "/var/run/postgresql/.s.PGSQL.5432" failed: FATAL: Peer authentication failed for user "postgres"
This error occurs because you’re not the postgres user, and all other users must designate that they’re connecting to an account with a password. The following steps let you configure the Operating System (OS).
-
You must shell out to the root superuser’s account, and then shell out to the postgres user’s account to test your connection because postgres user’s account disallows direct connection.
su - root su - postgres
You can verify the current postgres user with this command:
whoamiIt should return the following:
postgres
As the postgres user, you connect to the database without a password. You use the following syntax:
psql -U postgresIt should display the following:
psql (15.1) Type "help" for help.
-
At this point, you have some operating system (OS) stuff to setup before configuring a PostgreSQL sandboxed videodb database and student user. Exit psql with the following command:
postgres=# \q
Navigate to the PostgreSQL home database directory as the postgres user with this command:
cd /var/lib/pgsql/15/data
Edit the pg_hba.conf file to add lines for the postgres and student users:
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all peer local all postgres peer local all student peer # IPv4 local connections: host all all 127.0.0.1/32 scram-sha-256 # IPv6 local connections: host all all ::1/128 scram-sha-256 # Allow replication connections from localhost, by a user with the # replication privilege. local replication all scram-sha-256 host replication all 127.0.0.1/32 scram-sha-256 host replication all ::1/128 scram-sha-256
Navigate up the directory tree from the /var/lib/pgsql/15/data directory, which is also the data dictionary, to the following /var/lib/pgsql/15 base directory:
cd /var/lib/pgsql/15
Create a new video_db directory. This is where you will deploy the video_db tablespace. You create this directory with the following command:
mkdir video_dbChange the video_db permissions to read, write, and execute for only the owner with this syntax as the postgres user:
chmod 700 video_db
-
Exit the postgres user with the exit command and open PostgreSQL’s 5432 listener port as the root user. You can use the following command, as the root user:
firewall-cmd --zone=public --add-port 5432/tcp --permanent
-
You must shell out from the root user to the postgres user with the following command:
su - postgres
-
You must shell out to the root superuser’s account, and then shell out to the postgres user’s account to test your connection because postgres user’s account disallows direct connection.
- Connect to the postgres account and perform the following commands:
- After connecting as the postgres superuser, you can create a video_db tablespace with the following syntax:
CREATE TABLESPACE video_db OWNER postgres LOCATION 'C:\Users\username\video_db';
This will return the following:
CREATE TABLESPACE
You can query whether you successfully create the video_db tablespace with the following:
SELECT * FROM pg_tablespace;
It should return the following:
oid | spcname | spcowner | spcacl | spcoptions -------+------------+----------+--------+------------ 1663 | pg_default | 10 | | 1664 | pg_global | 10 | | 16389 | video_db | 10 | | (3 rows)
-
You need to know the PostgreSQL default collation before you create a new database. You can write the following query to determine the default correlation:
postgres=# SELECT datname, datcollate FROM pg_database WHERE datname = 'postgres';
It should return something like this:
datname | datcollate ----------+------------- postgres | en_US.UTF-8 (1 row)
The datcollate value of the postgres database needs to the same value for the LC_COLLATE and LC_CTYPE parameters when you create a database. You can create a videodb database with the following syntax provided you’ve made appropriate substitutions for the LC_COLLATE and LC_CTYPE values below:
CREATE DATABASE videodb WITH OWNER = postgres ENCODING = 'UTF8' TABLESPACE = video_db LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8' CONNECTION LIMIT = -1;
You can verify the creation of the videodb with the following command:
postgres# \l
It should show you a display like the following:
List of databases Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges -----------+----------+----------+-------------+-------------+------------+-----------------+----------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres videodb | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | (4 rows)Then, you can assign comment to the database with the following syntax:
COMMENT ON DATABASE videodb IS 'Video Store Database';
- After connecting as the postgres superuser, you can create a video_db tablespace with the following syntax:
- Create a Role, Grant, and User:
In this section you create a dba role, grant privileges on a videodb database to a role, and create a user with the role that you created previously with the following three statements. There are three steps in this sections.
- The first step creates a dba role:
CREATE ROLE dba WITH SUPERUSER;
- The second step grants all privileges on the videodb database to both the postgres superuser and the dba role:
GRANT TEMPORARY, CONNECT ON DATABASE videodb TO PUBLIC; GRANT ALL PRIVILEGES ON DATABASE videodb TO postgres; GRANT ALL PRIVILEGES ON DATABASE videodb TO dba;
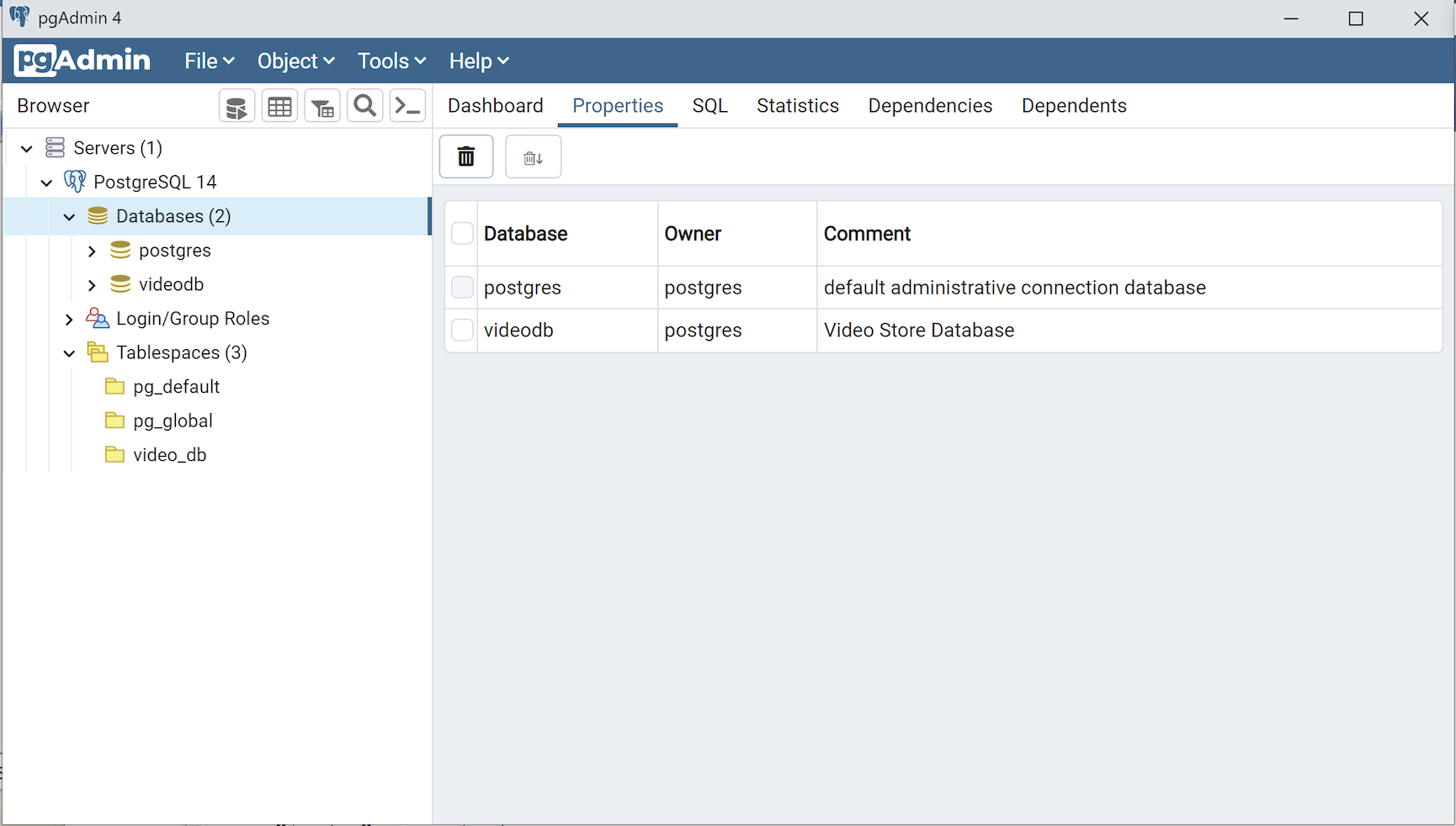
Any work in pgAdmin4 requires a grant on the videodb database to the postgres superuser. The grant enables visibility of the videodb database in the pgAdmin4 console as shown in the following image.
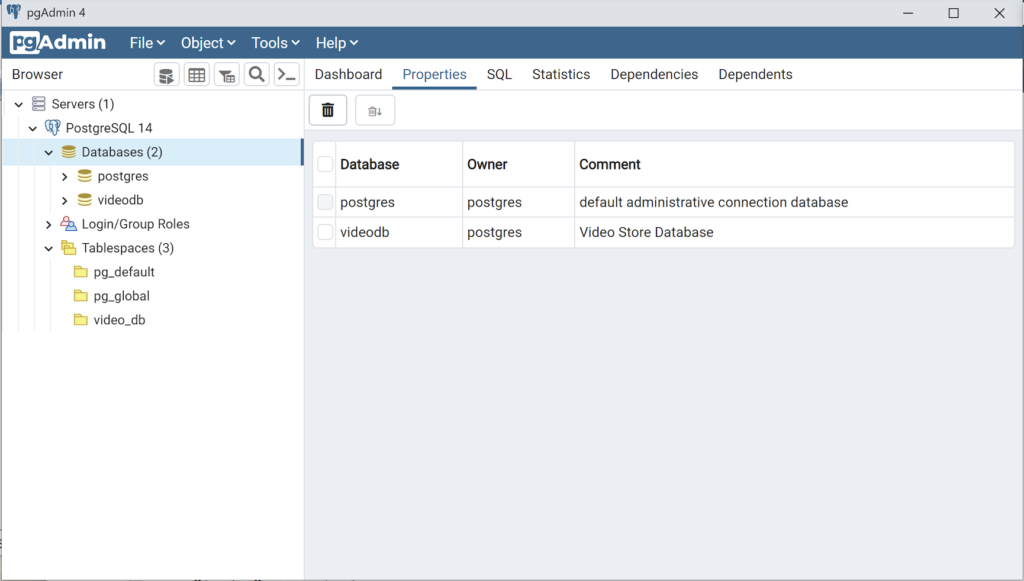
- The third step changes the ownership of the videodb database to the student user:
ALTER DATABASE videodb OWNER TO student;
You can verify the change of ownership for the videodb from the postgres user to student user with the following command:
postgres# \l
It should show you a display like the following:
List of databases Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges -----------+----------+----------+-------------+-------------+------------+-----------------+----------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres videodb | student | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =Tc/student + | | | | | | | student=CTc/student + | | | | | | | dba=CTc/student (4 rows) - The fourth step creates a student user with the dba role:
CREATE USER student WITH ROLE dba ENCRYPTED PASSWORD 'student';
After this step, you need to disconnect as the postgres superuser with the following command:
\q
- The first step creates a dba role:
- Connect to the videodb database as the student user with the PostgreSQL CLI, create a new_hire table and quit the database.
The following syntax lets you connect to a videodb database as the student user. You should note that the Linux OS student user name should match the database user name.
psql -Ustudent -W -dvideodb
You create the new_hire table in the public schema of the videodb database with the following syntax:
CREATE TABLE new_hire ( new_hire_id SERIAL CONSTRAINT new_hire_pk PRIMARY KEY , first_name VARCHAR(20) NOT NULL , middle_name VARCHAR(20) , last_name VARCHAR(20) NOT NULL , hire_date DATE NOT NULL , UNIQUE(first_name, middle_name, hire_date));
You can describe the new_hire table with the following command:
\d new_hire
You quit the psql connection with a quit; or \q, like so
quit;
- Installing, configuring, and launching pgadmin4 (don’t forget the pgAdmin 4 Documentation site):
- You need to install three sets of packages. They’re the pgadmin-server, policycoreutils-python-utils, and pgadmin4-desktop.
- Apply the pgadmin-server package:
sudo yum install https://ftp.postgresql.org/pub/pgadmin/pgadmin4/yum/redhat/rhel-9Server-x86_64/pgadmin4-server-6.16-1.el9.x86_64.rpm
Display detailed console log →
Last metadata expiration check: 0:36:13 ago on Mon 28 Nov 2022 12:59:07 AM EST. pgadmin4-server-6.16-1.el9.x86_64.rpm 1.9 MB/s | 73 MB 00:38 Dependencies resolved. ================================================================================================================================ Package Architecture Version Repository Size ================================================================================================================================ Installing: pgadmin4-server x86_64 6.16-1.el9 @commandline 73 M Transaction Summary ================================================================================================================================ Install 1 Package Total size: 73 M Installed size: 265 M Is this ok [y/N]: y Downloading Packages: Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : pgadmin4-server-6.16-1.el9.x86_64 1/1 Verifying : pgadmin4-server-6.16-1.el9.x86_64 1/1 Installed: pgadmin4-server-6.16-1.el9.x86_64 Complete!
- Apply or upgrade (which is the default at this point) the policycoreutils-python-utils package:
sudo dnf install policycoreutils-python-utils
Display detailed console log →
Last metadata expiration check: 0:50:44 ago on Mon 28 Nov 2022 12:59:07 AM EST. Package policycoreutils-python-utils-3.3-6.el9_0.noarch is already installed. Dependencies resolved. ================================================================================================================================ Package Architecture Version Repository Size ================================================================================================================================ Upgrading: libsemanage x86_64 3.4-2.el9 baseos 118 k policycoreutils x86_64 3.4-4.el9 baseos 202 k policycoreutils-devel x86_64 3.4-4.el9 appstream 139 k policycoreutils-python-utils noarch 3.4-4.el9 appstream 69 k python3-libsemanage x86_64 3.4-2.el9 appstream 80 k python3-policycoreutils noarch 3.4-4.el9 appstream 2.0 M Transaction Summary ================================================================================================================================ Upgrade 6 Packages Total download size: 2.6 M Is this ok [y/N]: y Downloading Packages: (1/6): policycoreutils-python-utils-3.4-4.el9.noarch.rpm 28 kB/s | 69 kB 00:02 (2/6): python3-libsemanage-3.4-2.el9.x86_64.rpm 32 kB/s | 80 kB 00:02 (3/6): policycoreutils-devel-3.4-4.el9.x86_64.rpm 55 kB/s | 139 kB 00:02 (4/6): libsemanage-3.4-2.el9.x86_64.rpm 189 kB/s | 118 kB 00:00 (5/6): python3-policycoreutils-3.4-4.el9.noarch.rpm 2.8 MB/s | 2.0 MB 00:00 (6/6): policycoreutils-3.4-4.el9.x86_64.rpm 302 kB/s | 202 kB 00:00 -------------------------------------------------------------------------------------------------------------------------------- Total 521 kB/s | 2.6 MB 00:05 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Upgrading : libsemanage-3.4-2.el9.x86_64 1/12 Upgrading : python3-libsemanage-3.4-2.el9.x86_64 2/12 Upgrading : policycoreutils-3.4-4.el9.x86_64 3/12 Running scriptlet: policycoreutils-3.4-4.el9.x86_64 3/12 Upgrading : python3-policycoreutils-3.4-4.el9.noarch 4/12 Upgrading : policycoreutils-python-utils-3.4-4.el9.noarch 5/12 Upgrading : policycoreutils-devel-3.4-4.el9.x86_64 6/12 Cleanup : policycoreutils-devel-3.3-6.el9_0.x86_64 7/12 Cleanup : policycoreutils-python-utils-3.3-6.el9_0.noarch 8/12 Cleanup : python3-policycoreutils-3.3-6.el9_0.noarch 9/12 Cleanup : python3-libsemanage-3.3-2.el9.x86_64 10/12 Running scriptlet: policycoreutils-3.3-6.el9_0.x86_64 11/12 Cleanup : policycoreutils-3.3-6.el9_0.x86_64 11/12 Cleanup : libsemanage-3.3-2.el9.x86_64 12/12 Running scriptlet: libsemanage-3.3-2.el9.x86_64 12/12 Verifying : policycoreutils-devel-3.4-4.el9.x86_64 1/12 Verifying : policycoreutils-devel-3.3-6.el9_0.x86_64 2/12 Verifying : policycoreutils-python-utils-3.4-4.el9.noarch 3/12 Verifying : policycoreutils-python-utils-3.3-6.el9_0.noarch 4/12 Verifying : python3-libsemanage-3.4-2.el9.x86_64 5/12 Verifying : python3-libsemanage-3.3-2.el9.x86_64 6/12 Verifying : python3-policycoreutils-3.4-4.el9.noarch 7/12 Verifying : python3-policycoreutils-3.3-6.el9_0.noarch 8/12 Verifying : libsemanage-3.4-2.el9.x86_64 9/12 Verifying : libsemanage-3.3-2.el9.x86_64 10/12 Verifying : policycoreutils-3.4-4.el9.x86_64 11/12 Verifying : policycoreutils-3.3-6.el9_0.x86_64 12/12 Upgraded: libsemanage-3.4-2.el9.x86_64 policycoreutils-3.4-4.el9.x86_64 policycoreutils-devel-3.4-4.el9.x86_64 policycoreutils-python-utils-3.4-4.el9.noarch python3-libsemanage-3.4-2.el9.x86_64 python3-policycoreutils-3.4-4.el9.noarch Complete!
- Apply the pgadmin4-desktop package:
sudo dnf install -y https://ftp.postgresql.org/pub/pgadmin/pgadmin4/yum/redhat/rhel-9Server-x86_64/pgadmin4-desktop-6.16-1.el9.x86_64.rpm
Display detailed console log →
Last metadata expiration check: 1:14:02 ago on Mon 28 Nov 2022 12:59:07 AM EST. pgadmin4-desktop-6.16-1.el9.x86_64.rpm 3.1 MB/s | 88 MB 00:28 Dependencies resolved. ================================================================================================================================ Package Architecture Version Repository Size ================================================================================================================================ Installing: pgadmin4-desktop x86_64 6.16-1.el9 @commandline 88 M Installing dependencies: libatomic x86_64 11.3.1-2.1.el9.alma baseos 56 k Transaction Summary ================================================================================================================================ Install 2 Packages Total size: 88 M Total download size: 56 k Installed size: 341 M Downloading Packages: libatomic-11.3.1-2.1.el9.alma.x86_64.rpm 83 kB/s | 56 kB 00:00 -------------------------------------------------------------------------------------------------------------------------------- Total 39 kB/s | 56 kB 00:01 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : libatomic-11.3.1-2.1.el9.alma.x86_64 1/2 Installing : pgadmin4-desktop-6.16-1.el9.x86_64 2/2 Running scriptlet: pgadmin4-desktop-6.16-1.el9.x86_64 2/2 Verifying : libatomic-11.3.1-2.1.el9.alma.x86_64 1/2 Verifying : pgadmin4-desktop-6.16-1.el9.x86_64 2/2 Installed: libatomic-11.3.1-2.1.el9.alma.x86_64 pgadmin4-desktop-6.16-1.el9.x86_64 Complete!
- Apply the pgadmin-server package:
- You configure your .bashrc file to add the pgadmin4 directory to your $PATH environment variable.
# Add the pgadmin4 executable to the $PATH. export set PATH=$PATH:/usr/pgadmin4/bin
You also configure your .bashrc file to add a pgadmin4 function, which simplifies how you call the pgadmin4 executable.
# Function to ensure pgadmin4 call is simplified and without warnings. pgadmin4 () { # Call the pgadmin4 executable. if [[ `type -t pgadmin4` = 'function' ]]; then if [ -f "/usr/pgadmin4/bin/pgadmin4" ]; then /usr/pgadmin4/bin/pgadmin4 2>/dev/null & else echo "[/usr/pgadmin4/bin/pgadmin4] is not found." fi else echo "[pgadmin4] is not a function" fi }
You can launch your pgadmin4 program file now with the following syntax as the student user:
pgadmin4
It takes a couple moments to launch the pgadmin4 desktop. The initial screen will look like:

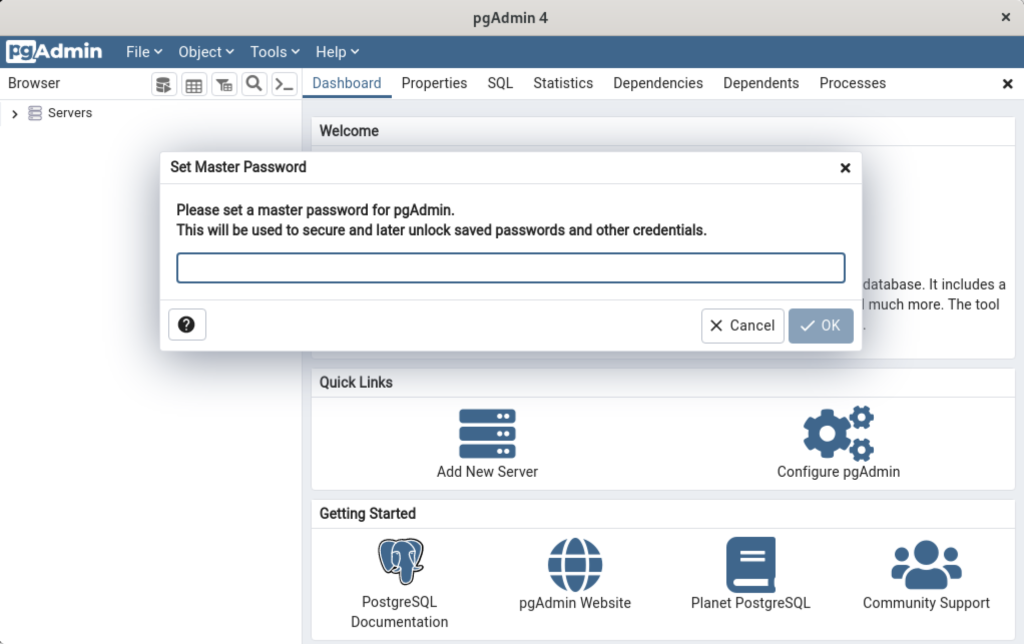
After pgadmin4 launches, you’re prompted for a master password. Enter the password and click the OK button to proceed.
After entering the password, you arrive at the base dialog, as shown.
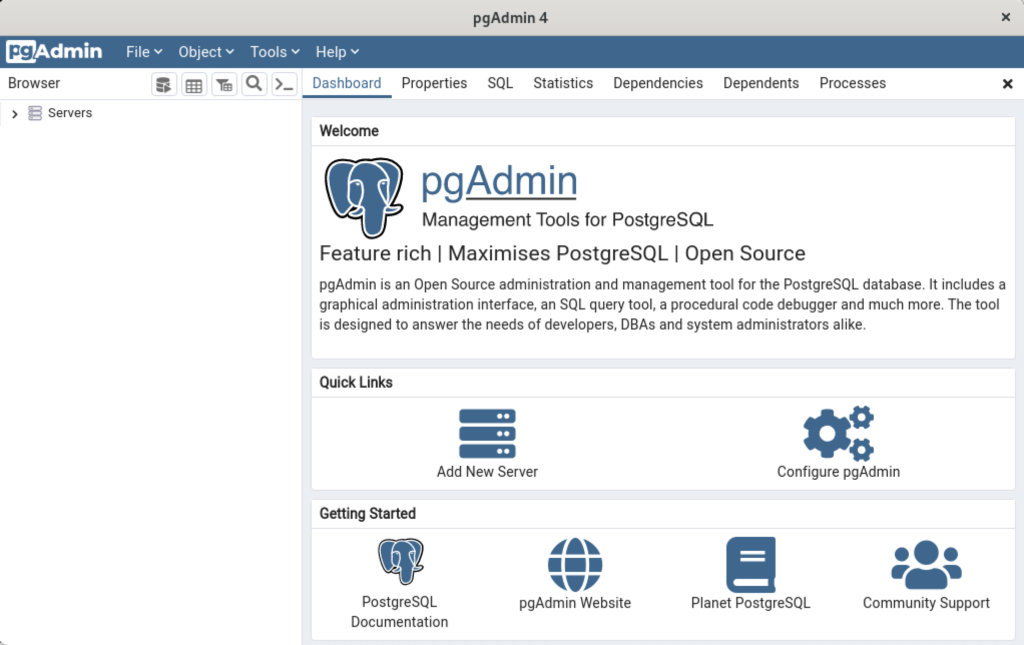
Click the Add New Server link, which prompts you to register your database. Enter videodb in the Name field and click the Connection tab to the right of the General tab.
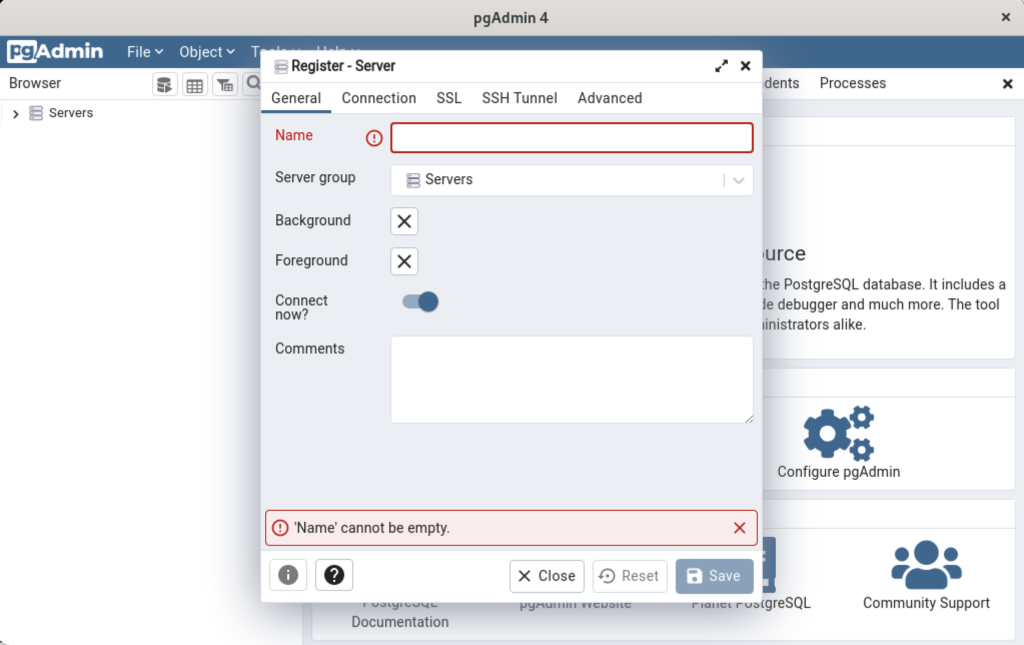
In the Connection dialog, enter the following values:
- Host name/address: localhost
- Port: 5432
- Maintenance database: postgres
- Username: student
- Password: student

Enter a name for your database. In this example, videodb is the Server Name. Click the Save button to proceed.

- You need to install three sets of packages. They’re the pgadmin-server, policycoreutils-python-utils, and pgadmin4-desktop.
This completes the instructions for installing, configuring, and using PostgreSQL on AlmaLinux. As always, I hope it helps those looking for instructions.
PostgreSQL Upsert Intro
Oracle and SQL Server use the MERGE statement, MySQL uses the REPLACE INTO statement or ON DUPLICATE KEY, but PostgreSQL uses an upsert. The upsert isn’t a statement per se. It is like MySQL’s INSERT statement with the ON DUPLICATE KEY clause. PostgreSQL uses an ON CONFLICT clause in the INSERT statement and there anonymous block without the $$ delimiters.
The general behaviors of upserts is covered in the PostgreSQL Tutorial. It has the following prototype:
INSERT INTO TABLE_NAME(column_list) VALUES(value_list) ON CONFLICT target action; |
The target can be a column name, an ON CONSTRAINT constraint name, or a WHERE predicate, while the action can be DO NOTHING (or ignore) or a DO UPDATE statement. I wrote the following example to show how to leverage a unique constraint with a DO NOTHING and DO UPDATE behavior.
My example conditionally drops a table, creates a table with a unique constraint, inserts a few rows, updates with a DO UPDATE clause, updates with DO NOTHING clause, and queries the results with a bit of formatting.
- Conditionally drop the
testtable./* Suppress warnings from the log file. */ SET client_min_messages = 'error'; /* Conditionally drop table. */ DROP TABLE IF EXISTS test;
- Create the
testtable./* Create a test table. */ CREATE TABLE test ( test_id SERIAL , first_name VARCHAR(20) , middle_name VARCHAR(20) , last_name VARCHAR(20) , updated INTEGER DEFAULT 0 , update_time TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT CURRENT_TIMESTAMP , CONSTRAINT test_uq_key UNIQUE (first_name,middle_name,last_name));
- Insert six rows into the
testtable./* Insert six rows. */ INSERT INTO test ( first_name, middle_name, last_name ) VALUES ('Harry','James','Potter') ,('Ginerva','Molly','Potter') ,('Lily','Luna','Potter') ,('Albus','Severus','Potter') ,('James',NULL,'Potter') ,('Lily',NULL,'Potter');
- Create a five second delay.
/* Sleep for 5 seconds. */ DO $$ BEGIN PERFORM pg_sleep(5); END; $$;
- Use the
INSERTstatement with aDO UPDATEclause that increments theupdatedcolumn of thetesttable./* Upsert on unique key constraint conflict. */ INSERT INTO test ( first_name , middle_name , last_name ) VALUES ('Harry' ,'James' ,'Potter') ON CONFLICT ON CONSTRAINT test_uq_key DO UPDATE SET updated = excluded.updated + 1 , update_time = CURRENT_TIMESTAMP;
- Use the
INSERTstatement with aDO NOTHINGclause./* Upsert on unique key constraint ignore update. */ INSERT INTO test ( first_name , middle_name , last_name ) VALUES ('Harry' ,'James' ,'Potter') ON CONFLICT ON CONSTRAINT test_uq_key DO NOTHING;
- Query the
testtable./* Formatted query to demonstrate result of UPSERT statement. */ SELECT test_id , last_name || ', ' || CASE WHEN middle_name IS NOT NULL THEN first_name || ' ' || middle_name ELSE first_name END AS full_name , updated , date_trunc('second',update_time AT TIME ZONE 'MST') AS "timestamp" FROM test ORDER BY last_name , first_name , CASE WHEN middle_name IS NOT NULL THEN middle_name ELSE 'A' END;
Display results:
test_id | full_name | updated | timestamp ---------+-----------------------+---------+--------------------- 4 | Potter, Albus Severus | 0 | 2019-11-24 19:23:10 2 | Potter, Ginerva Molly | 0 | 2019-11-24 19:23:10 1 | Potter, Harry James | 1 | 2019-11-24 19:23:15 5 | Potter, James | 0 | 2019-11-24 19:23:10 6 | Potter, Lily | 0 | 2019-11-24 19:23:10 3 | Potter, Lily Luna | 0 | 2019-11-24 19:23:10 (6 rows)
As always, I hope this helps those looking for clear examples to solve problems.
Postgres Overloaded Routines
Earlier I showed how to write an anonymous block in PostgreSQL PL/pgSQL to drop routines, like functions and procedures. However, it would only work when they’re not overloaded functions or procedures. The following lets you drop all routines, including overloaded functions and procedures. Overloaded procedures are those that share the same name but have different parameter lists.
Before you can test the anonymous block, you need to create a set of overloaded functions or procedures. You can create a set of overloaded hello procedures with the following syntax:
CREATE FUNCTION hello() RETURNS text AS $$ DECLARE output VARCHAR; BEGIN SELECT 'Hello World!' INTO output; RETURN output; END $$ LANGUAGE plpgsql; CREATE FUNCTION hello(whom text) RETURNS text AS $$ DECLARE output VARCHAR; BEGIN SELECT CONCAT('Hello ',whom,'!') INTO output; RETURN output; END $$ LANGUAGE plpgsql; CREATE FUNCTION hello(id int, whom text) RETURNS text AS $$ DECLARE output VARCHAR; BEGIN SELECT CONCAT('[',id,'] Hello ',whom,'!') INTO output; RETURN output; END $$ LANGUAGE plpgsql; |
You can test the overloaded hello function, like so from the videodb schema:
videodb=> SELECT hello(); hello -------------- Hello World! (1 ROW) videodb=> SELECT hello('Captain Marvel'); hello ----------------------- Hello Captain Marvel! (1 ROW) videodb=> SELECT hello(1,'Captain America'); hello ---------------------------- [1] Hello Captain America! (1 ROW) |
Then, you can query the information_schema to verify that you’ve created a set of overloaded procedures with the following query:
SELECT proc.specific_schema AS procedure_schema , proc.specific_name , proc.routine_name AS procedure_name , proc.external_language , args.parameter_name , args.parameter_mode , args.data_type FROM information_schema.routines proc left join information_schema.parameters args ON proc.specific_schema = args.specific_schema AND proc.specific_name = args.specific_name WHERE proc.routine_schema NOT IN ('pg_catalog', 'information_schema') AND proc.routine_type IN ('FUNCTION','PROCEDURE') ORDER BY procedure_schema , specific_name , procedure_name , args.ordinal_position; |
It should return the following:
procedure_schema | specific_name | procedure_name | external_language | parameter_name | parameter_mode | data_type ------------------+---------------+----------------+-------------------+----------------+----------------+----------- public | hello_35451 | hello | PLPGSQL | | | public | hello_35452 | hello | PLPGSQL | whom | IN | text public | hello_35453 | hello | PLPGSQL | id | IN | integer public | hello_35453 | hello | PLPGSQL | whom | IN | text (4 rows) |
The set session command maps the videodb catalog for the following anonymous block program.
SET SESSION "videodb.catalog_name" = 'videodb'; |
The following anonymous block lets you get rid of any ordinary or overloaded function and procedure:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 | DO $$ DECLARE /* Declare an indefinite length string for SQL statement. */ sql VARCHAR; /* Declare variables to manage cursor return values. */ row RECORD; arg VARCHAR; /* Declare parameter list. */ list VARCHAR; /* Declare a routine cursor. */ routine_cursor CURSOR FOR SELECT routine_name , specific_name , routine_type FROM information_schema.routines WHERE specific_catalog = current_setting('videodb.catalog_name') AND routine_schema = 'public'; /* Declare a parameter cursor. */ parameter_cursor CURSOR (cv_specific_name varchar) FOR SELECT args.data_type FROM information_schema.parameters args WHERE args.specific_schema = 'public' AND args.specific_name = cv_specific_name; BEGIN /* Open the cursor. */ OPEN routine_cursor; <<row_loop>> LOOP /* Fetch table names. */ FETCH routine_cursor INTO row; /* Exit when no more records are found. */ EXIT row_loop WHEN NOT FOUND; /* Initialize parameter list. */ list := '('; /* Open the parameter cursor. */ OPEN parameter_cursor(row.specific_name::varchar); <<parameter_loop>> LOOP FETCH parameter_cursor INTO arg; /* Exit the parameter loop. */ EXIT parameter_loop WHEN NOT FOUND; /* Add parameter and delimit more than one parameter with a comma. */ IF LENGTH(list) > 1 THEN list := CONCAT(list,',',arg); ELSE list := CONCAT(list,arg); END IF; END LOOP; /* Close the parameter list. */ list := CONCAT(list,')'); /* Close the parameter cursor. */ CLOSE parameter_cursor; /* Concatenate together a DDL to drop the table with prejudice. */ sql := 'DROP '||row.routine_type||' IF EXISTS '||row.routine_name||list; /* Execute the DDL statement. */ EXECUTE sql; END LOOP; /* Close the routine_cursor. */ CLOSE routine_cursor; END; $$; |
Now, you possess the magic to automate cleaning up your schema when you combine this with my earlier post on dynamically dropping tables, sequences, and triggers.
Postgres Drop Structures
While building my PostgreSQL environment for the class, I had to write a couple utilities. They do the following:
- Drops all the tables from a schema.
- Drops all the sequences from a schema that aren’t tied to an
_idcolumn with aSERIALdata type. - Drops all the functions and procedures (qualified as routines) from a schema.
- Drops all the triggers from a schema.
The following gives you the code for all four files: drop_tables.sql, drop_sequences.sql, drop_routines.sql, and drop_triggers.sql.
- The drop_tables.sql Script:
- The drop_sequences.sql script:
- The drop_routines.sql script:
- The drop_triggers.sql script:
/* Verify all tables present. */ SELECT table_name FROM information_schema.tables WHERE table_catalog = current_setting('videodb.catalog_name') AND table_schema = 'public'; DO $$ DECLARE /* Declare an indefinite length string and record variable. */ sql VARCHAR; row RECORD; /* Declare a cursor. */ table_cursor CURSOR FOR SELECT table_name FROM information_schema.tables WHERE table_catalog = current_setting('videodb.catalog_name') AND table_schema = 'public'; BEGIN /* Open the cursor. */ OPEN table_cursor; LOOP /* Fetch table names. */ FETCH table_cursor INTO row; /* Exit when no more records are found. */ EXIT WHEN NOT FOUND; /* Concatenate together a DDL to drop the table with prejudice. */ sql := 'DROP TABLE IF EXISTS '||row.table_name||' CASCADE'; /* Execute the DDL statement. */ EXECUTE sql; END LOOP; /* Close the cursor. */ CLOSE table_cursor; END; $$; /* Verify all tables are dropped. */ SELECT table_name FROM information_schema.tables WHERE table_catalog = current_setting('videodb.catalog_name') AND table_schema = 'public'; |
/* Verify all tables present. */ SELECT sequence_name FROM information_schema.sequences WHERE sequence_catalog = current_setting('videodb.catalog_name') AND sequence_schema = 'public'; DO $$ DECLARE /* Declare an indefinite length string and record variable. */ sql VARCHAR; row RECORD; /* Declare a cursor. */ sequence_cursor CURSOR FOR SELECT sequence_name FROM information_schema.sequences WHERE sequence_catalog = current_setting('videodb.catalog_name') AND sequence_schema = 'public'; BEGIN /* Open the cursor. */ OPEN sequence_cursor; LOOP /* Fetch table names. */ FETCH sequence_cursor INTO row; /* Exit when no more records are found. */ EXIT WHEN NOT FOUND; /* Concatenate together a DDL to drop the table with prejudice. */ sql := 'DROP SEQUENCE IF EXISTS '||row.sequence_name; /* Execute the DDL statement. */ EXECUTE sql; END LOOP; /* Close the cursor. */ CLOSE sequence_cursor; END; $$; /* Verify all tables are dropped. */ SELECT sequence_name FROM information_schema.sequences WHERE sequence_catalog = current_setting('videodb.catalog_name') AND sequence_schema = 'public'; |
/* Verify all tables present. */ SELECT routine_name , routine_type FROM information_schema.routines WHERE specific_catalog = current_setting('videodb.catalog_name') AND specific_schema = 'public'; DO $$ DECLARE /* Declare an indefinite length string and record variable. */ sql VARCHAR; row RECORD; /* Declare a cursor. */ routine_cursor CURSOR FOR SELECT routine_name , routine_type FROM information_schema.routines WHERE specific_catalog = current_setting('videodb.catalog_name') AND routine_schema = 'public'; BEGIN /* Open the cursor. */ OPEN routine_cursor; LOOP /* Fetch table names. */ FETCH routine_cursor INTO row; /* Exit when no more records are found. */ EXIT WHEN NOT FOUND; /* Concatenate together a DDL to drop the table with prejudice. */ sql := 'DROP '||row.routine_type||' IF EXISTS '||row.routine_name; /* Execute the DDL statement. */ EXECUTE sql; END LOOP; /* Close the cursor. */ CLOSE routine_cursor; END; $$; /* Verify all tables are dropped. */ SELECT routine_name , routine_type FROM information_schema.routines WHERE specific_catalog = 'videodb' AND specific_schema = 'public'; |
/* Verify all tables present. */ SELECT trigger_name FROM information_schema.triggers WHERE trigger_catalog = current_setting('videodb.catalog_name') AND trigger_schema = 'public'; DO $$ DECLARE /* Declare an indefinite length string and record variable. */ sql VARCHAR; row RECORD; /* Declare a cursor. */ trigger_cursor CURSOR FOR SELECT trigger_name FROM information_schema.triggers WHERE trigger_catalog = current_setting('videodb.catalog_name') AND trigger_schema = 'public'; BEGIN /* Open the cursor. */ OPEN trigger_cursor; LOOP /* Fetch table names. */ FETCH trigger_cursor INTO row; /* Exit when no more records are found. */ EXIT WHEN NOT FOUND; /* Concatenate together a DDL to drop the table with prejudice. */ sql := 'DROP TRIGGER IF EXISTS '||row.trigger_name; /* Execute the DDL statement. */ EXECUTE sql; END LOOP; /* Close the cursor. */ CLOSE trigger_cursor; END; $$; /* Verify all tables are dropped. */ SELECT trigger_name FROM information_schema.triggers WHERE trigger_catalog = current_setting('videodb.catalog_name') AND trigger_schema = 'public'; |
You can create a cleanup_catalog.sql script to call all four in sequence, like the following:
\i /home/student/Data/cit225/postgres/lib/utility/drop_tables.sql \i /home/student/Data/cit225/postgres/lib/utility/drop_sequences.sql \i /home/student/Data/cit225/postgres/lib/utility/drop_routines.sql \i /home/student/Data/cit225/postgres/lib/utility/drop_triggers.sql |
The nice thing about this approach is that you won’t see any notices when tables, sequences, routines, or triggers aren’t found. It’s a clean approach to cleaning the schema for a testing environment.
Postgres Print Debug Notes
A student asked how you print output from PL/pgSQL blocks. The student wanted to know if there was something like the following in Oracle’s PL/SQL programming language:
dbms_output.put_line('some string'); |
or, in Java programming the:
System.out.println("some string"); |
The RAISE NOTICE is the equivalent to these in Postgres PL/pgSQL, as shown in the following anonymous block:
do $$ BEGIN raise notice 'Hello World!'; END; $$; |
It prints:
NOTICE: Hello World! |
You can write a hello_world function as a named PL/pgSQL block:
CREATE FUNCTION hello_world() RETURNS text AS $$ DECLARE output VARCHAR(20); BEGIN /* Query the string into a local variable. */ SELECT 'Hello World!' INTO output; /* Return the output text variable. */ RETURN output; END $$ LANGUAGE plpgsql; |
You can call it with the following:
SELECT hello_world(); |
It prints:
hello_world -------------- Hello World! (1 row) |
Here’s a full test case with stored procedure in PL/pgSQL:
-- Drop the msg table. DROP TABLE msg; -- Create the msg table. CREATE TABLE msg ( comment VARCHAR(400) ); -- Transaction Management Example. DROP PROCEDURE IF EXISTS testing ( IN pv_one VARCHAR(30) , IN pv_two VARCHAR(10)); -- Transaction Management Example. CREATE OR REPLACE PROCEDURE testing ( IN pv_one VARCHAR(30) , IN pv_two VARCHAR(10)) AS $$ DECLARE /* Declare error handling variables. */ err_num TEXT; err_msg INTEGER; BEGIN /* Log actdual parameter values. */ INSERT INTO msg VALUES (pv_one||'.'||pv_two); EXCEPTION WHEN OTHERS THEN err_num := SQLSTATE; err_msg := SUBSTR(SQLERRM,1,100); RAISE NOTICE 'Trapped Error: %', err_msg; END $$ LANGUAGE plpgsql; do $$ DECLARE lv_one VARCHAR(30) := 'INDIVIDUAL'; lv_two VARCHAR(19) := 'R11-514-34'; BEGIN RAISE NOTICE '[%]', lv_one; RAISE NOTICE '[%]', lv_two; CALL testing( pv_one := lv_one, pv_two := lv_two ); END $$; -- Query any logged results. SELECT * FROM msg; |
It prints:
DROP TABLE
CREATE TABLE
DROP PROCEDURE
CREATE PROCEDURE
psql:fixed.sql:61: NOTICE: [INDIVIDUAL]
psql:fixed.sql:61: NOTICE: [R11-514-34]
DO
comment
-----------------------
INDIVIDUAL.R11-514-34
(1 row) |
I hope this helps those looking for a solution.
Postgres SQL Nuance
I ran across an interesting nuance between Oracle and Postgres with the double-pipe operator. I found that the following query failed to cross port from Oracle to Postgres:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | COL account_number FORMAT A10 HEADING "Account|Number" COL full_name FORMAT A16 HEADING "Name|(Last, First MI)" COL city FORMAT A12 HEADING "City" COL state_province FORMAT A10 HEADING "State" COL telephone FORMAT A18 HEADING "Telephone" SELECT m.account_number , c.last_name || ', ' || c.first_name || CASE WHEN c.middle_name IS NOT NULL THEN ' ' || c.middle_name END AS full_name , a.city , a.state_province , t.country_code || '-(' || t.area_code || ') ' || t.telephone_number AS telephone FROM member m INNER JOIN contact c ON m.member_id = c.member_id INNER JOIN address a ON c.contact_id = a.contact_id INNER JOIN street_address sa ON a.address_id = sa.address_id INNER JOIN telephone t ON c.contact_id = t.contact_id AND a.address_id = t.address_id WHERE c.last_name = 'Winn'; |
In Oracle, a CASE statement ignores the null of a missing ELSE clause between lines 4 and 5. Oracle assumes a null value is an empty string when concatenated to a string with the double-piped concatenation operator. Oracle’s implementation differs from the ANSI standard and is non-compliant.
It would display the following thanks to the SQL reporting features that don’t exist in other Command-Line Interface (CLI) implementations, like mysql, psql, sqlcmd, or cql:
Account Name Number (Last, First MI) City State Telephone ---------- ---------------- ------------ ---------- ------------------ B293-71445 Winn, Randi San Jose CA 001-(408) 111-1111 B293-71445 Winn, Brian San Jose CA 001-(408) 111-1111 |
However, it fails in Postgres without a notice, warning, or error. Postgres simply returns a null string for the missing ELSE clause and follows the rule that any string concatenated against a null is a null. That means it retunes a null value for the full_name column above. The Postgres behavior is the ANSI standard behavior. After years of working with Oracle it was interesting to have this pointed out while porting a query.
You can fix the statement in Postgres by adding an explicit ELSE clause on a new line 5 that appends an empty string, like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SELECT m.account_number , c.last_name || ', ' || c.first_name || CASE WHEN c.middle_name IS NOT NULL THEN ' ' || c.middle_name ELSE '' END AS full_name , a.city , a.state_province , t.country_code || '-(' || t.area_code || ') ' || t.telephone_number AS telephone FROM member m INNER JOIN contact c ON m.member_id = c.member_id INNER JOIN address a ON c.contact_id = a.contact_id INNER JOIN street_address sa ON a.address_id = sa.address_id INNER JOIN telephone t ON c.contact_id = t.contact_id AND a.address_id = t.address_id WHERE c.last_name = 'Winn'; |
It would display:
account_number | full_name | city | state_province | telephone ----------------+-------------+----------+----------------+-------------------- B293-71445 | Winn, Randi | San Jose | CA | 001-(408) 111-1111 B293-71445 | Winn, Brian | San Jose | CA | 001-(408) 111-1111 (2 rows) |
As always, I hope this helps those looking to solve a problem.
Postgres Foreign Constraints
You can’t disable a foreign key constraint in Postgres, like you can do in Oracle. However, you can remove the foreign key constraint from a column and then re-add it to the column.
Here’s a quick test case in five steps:
- Drop the
bigandlittletable if they exists. The firstdropstatement requires a cascade because there is a dependentlittletable that holds a foreign key constraint against the primary key column of thebigtable. The second drop statement does not require the cascade keyword because there is not a dependent foreign key constraint.DROP TABLE IF EXISTS big CASCADE; DROP TABLE IF EXISTS little;
- Create the
bigandlittletables:-- Create the big table. CREATE TABLE big ( big_id SERIAL , big_text VARCHAR(20) NOT NULL , CONSTRAINT pk_little_1 PRIMARY KEY (big_id)); -- Display the big table. \d big -- Create little table. CREATE TABLE little ( little_id SERIAL , big_id INTEGER NOT NULL , little_text VARCHAR(20) NOT NULL , CONSTRAINT fk_little_1 FOREIGN KEY (big_id) REFERENCES big (big_id)); -- Display the little table. \d little
If you failed to designate the
big_idcolumn as a primary key constrained, Postgres will raise the following exception:ERROR: there IS no UNIQUE CONSTRAINT matching given KEYS FOR referenced TABLE "big"
- Insert a non-compliant row in the
littletable. An insert statement into thelittletable with a value for the foreign key column that does not exist in thebig_idcolumn of thebigtable would fail with the following error:ERROR: INSERT OR UPDATE ON TABLE "little" violates FOREIGN KEY CONSTRAINT "fk_little_1" DETAIL: KEY (big_id)=(2) IS NOT present IN TABLE "big".
Re-enabling the foreign key constraint, the insert statement succeeds after you first insert a new row into the
bigtable with the foreign key value for thelittletable as its primary key. The following two insert statements add a row to both thebigandlittletable:-- Insert into a big table. INSERT INTO big (big_text) VALUES ('Cat in the Hat 2'); -- Insert into a little table. INSERT INTO little (big_id ,little_text) VALUES ( 2 ,'Thing 3');
Then, you can query it like this:
SELECT * FROM big b JOIN little l ON b.big_id = l.big_id;
big_id | big_text | little_id | big_id | little_text --------+------------------+-----------+--------+------------- 1 | Cat IN the Hat 1 | 1 | 1 | Thing 1 1 | Cat IN the Hat 1 | 2 | 1 | Thing 2 2 | Cat IN the Hat 2 | 3 | 2 | Thing 3 (3 ROWS)
- You can drop a foreign key constraint with the following syntax:
ALTER TABLE little DROP CONSTRAINT fk_little_1;
- You can add a foreign key constraint with the following syntax:
ALTER TABLE little ADD CONSTRAINT fk_little_1 FOREIGN KEY (big_id) REFERENCES big (big_id);
As always, I hope this helps you solve problems.
Postgres Remove Constraints
You can’t disable a not null constraint in Postgres, like you can do in Oracle. However, you can remove the not null constraint from a column and then re-add it to the column.
Here’s a quick test case in four steps:
- Drop a demo table if it exists:
DROP TABLE IF EXISTS demo;
- Create a
demotable if it exists:CREATE TABLE demo ( demo_id SERIAL , demo_text VARCHAR(20) NOT NULL );
- Insert a compliant row in the
demotable if it exists:INSERT INTO demo (demo_text) VALUES ('Thing 1');
Attempt to insert another row with a null value in the
demo_textcolumn:INSERT INTO demo (demo_text) VALUES (NULL);
It raises the following error:
INSERT 0 1 psql:remove_not_null.sql:22: ERROR: NULL VALUE IN COLUMN "demo_text" violates not-NULL CONSTRAINT DETAIL: Failing ROW contains (2, NULL).
- You can drop the not null constraint from the
demo_textcolumn:ALTER TABLE demo ALTER COLUMN demo_text DROP NOT NULL;
You can now successfully insert a row with a
demo_textcolumn value of null. After you have performed your table maintenance you can add the not null constraint back on to thedemo_textcolumn.You need to update the row with a null value in the
demo_textcolumn with a valid value before you re-add the not null constraint. The following shows an update statement that replaces the null value with a text string:UPDATE demo SET demo_text = 'Thing 2' WHERE demo_text IS NULL;
Now, you can change the
demo_textcolumn back to a not null constrained column with the following syntax.ALTER TABLE demo ALTER COLUMN demo_text SET NOT NULL;
While you can not defer the constraint, removing it and adding it back works well.
Postgres Check Constraints
The Postgres 11 database documentation says that it supports naming constraints. While you can create a table with named constraints inside the CREATE TABLE statement, the names are not assigned to the not null check constraint.
Here’s a quick test case in three steps:
- Drop a demo table if it exists:
DROP TABLE IF EXISTS demo;
- Drop a demo table if it exists:
CREATE TABLE demo ( demo_id SERIAL , demo_text VARCHAR(20) CONSTRAINT nn_demo_1 NOT NULL );
- Create a
demotable if it exists:SELECT substr(check_clause,1,strpos(check_clause,' ')-1) AS check_column , constraint_name FROM information_schema.check_constraints WHERE check_clause LIKE 'demo_text%';
You should see the following output with a parsed
check_columnname and the system generatedcheckconstraint name rather than thenn_demo_1constraint name:check_column | constraint_name --------------+----------------------- demo_text | 2200_18896_2_not_null (1 row)
On the bright side, you can name primary key and foreign key constraints.
