Archive for the ‘SQL Developer’ Category
Troubleshoot Oracle Errors
It’s always a bit difficult to trap errors in SQL*Developer when you’re running scripts that do multiple things. As old as it is, using the SQL*Plus utility and spooling to log files is generally the fastest way to localize errors across multiple elements of scripts. Unfortunately, you must break up you components into local components, like a when you create a type, procedure, function, or package.
This is part of my solution to leverage in-depth testing of the Oracle Database 23ai Free container from an Ubuntu native platform. You can find this prior post shows you how to setup Oracle*Client for Ubuntu and connect to the Oracle Database 23ai Free container.
After you’ve done that, put the following oracle_errors Bash shell function into your testing context, or into your .bashrc file:
# Troubleshooting errors utility function. oracle_errors () { # Oracle Error prefixes qualify groups of error types, like # this subset of error prefixes used in the Bash function. # ============================================================ # JMS - Java Messaging Errors # JZN - JSON Errors # KUP - External Table Access Errors # LGI - File I/O Errors # OCI - Oracle Call Interface Errors # ORA - Oracle Database Errors # PCC - Oracle Precompiler Errors # PLS - Oracle PL/SQL Errors # PLW - Oracle PL/SQL Warnings # SP2 - Oracle SQL*Plus Errors # SQL - SQL Library Errors # TNS - SQL*Net (networking) Errors # ============================================================ # Define a array of Oracle error prefixes. prefixes=("jms" "jzn" "kup" "lgi" "oci" "ora" "pcc" "pls" "plw" "sp2" "sql" "tns") # Prepend the -e for the grep utility to use regular expression pattern matching; and # use the ^before the Oracle error prefixes to avoid returning lines that may # contain the prefix in a comment, like the word lookup contains the prefix kup. for str in ${prefixes[@]}; do patterns+=" -e ^${str}" done # Display output from a SQL*Plus show errors command written to a log file when # a procedure, function, object type, or package body fails to compile. This # prints the warning message followed by the line number displayed. patterns+=" -e ^warning" patterns+=" -e ^[0-9]/[0-9]" # Assign any file filter to the ext variable. ext=${1} # Assign the extension or simply use a wildcard for all files. if [ ! -z ${ext} ]; then ext="*.${ext}" else ext="*" fi # Assign the number of qualifying files to a variable. fileNum=$(ls -l ${ext} 2>/dev/null | grep -v ^l | wc -l) # Evaluate the number of qualifying files and process. if [ ${fileNum} -eq "0" ]; then echo "[0] files exist." elif [ ${fileNum} -eq "1" ]; then fileName=$(ls ${ext}) find `pwd` -type f | grep -in ${ext} ${patterns} | while IFS='\n' read list; do echo "${fileName}:${list}" done else find `pwd` -type f | grep -in ${ext} ${patterns} | while IFS='\n' read list; do echo "${list}" done fi # Clear ${patterns} variable. patterns="" } |
Now, let’s create a debug.txt test file to demonstrate how to use the oracle_errors, like:
ORA-12704: character SET mismatch PLS-00124: name OF EXCEPTION expected FOR FIRST arg IN exception_init PRAGMA SP2-00200: Environment error JMS-00402: Class NOT found JZN-00001: END OF input |
You can navigate to your logging directory and call the oracle_errors function, like:
oracle_errors txt |
It’ll return the following, which is file number, line number, and error code:
debug.txt:1:ORA-12704: character set mismatch debug.txt:2:PLS-00124: name of exception expected for first arg in exception_init pragma debug.txt:3:SP2-00200: Environment error debug.txt:4:JMS-00402: Class not found debug.txt:5:JZN-00001: End of input |
There are other Oracle error prefixes but the ones I’ve selected are the more common errors for Java, JavaScript, PL/SQL, Python, and SQL testing. You can add others if your use cases require them to the prefixes array. Just a note for those new to Bash shell scripting the “${variable_name}” is required for arrays.
For a more complete example, I created the following files for a trivial example of procedure overloading in PL/SQL:
- tables.sql – that creates two tables.
- spec.sql – that creates a package specification.
- body.sql – that implements a package specification.
- test.sql – that implements a test case using the package.
- integration.sql – that calls the the scripts in proper order.
The tables.sql, spec.sql, body.sql, and test.sql use the SQL*Plus spool command to write log files, like:
SPOOL spec.txt
-- Insert code here ...
SPOOL OFF |
The body.sql file includes SQL*Plus list and show errors commands, like:
SPOOL spec.txt
-- Insert code here ...
LIST
SHOW ERRORS
SPOOL OFF |
The integration.sql script calls the tables.sql, spec.sql, body.sql, and test.sql in order. Corrupting the spec.sql file by adding a stray “x” to one of the parameter names causes a cascade of errors. After running the integration.sql file with the introduced error, the Bash oracle_errors function returns:
body.txt:2:Warning: Package Body created with compilation errors. body.txt:148:4/13 PLS-00323: subprogram or cursor 'WARNER_BROTHER' is declared in a test.txt:4:ORA-06550: line 2, column 3: test.txt:5:PLS-00306: wrong number or types of arguments in call to 'WARNER_BROTHER' test.txt:6:ORA-06550: line 2, column 3: |
I hope that helps those learning how to program and perform integration testing in an Oracle Database.
Oracle23ai Ubuntu Install

What to do with a Late 2015 iMac with an i7 Quad CPU running at 3.4 GHz, 32 GB or RAM, a 5K Display and an almost warn out hybrid 1 TB hard disk? You could sell it to Apple for pennies, but why enrich them. I opted to upgrade it with an OWC kit that had a 2 TB SSD Disk. Then, I installed Ubuntu 22.0.4 and built a DaaS (Database as a Service) machine with Oracle Database 23ai in a Docker container, and MySQL 8 and PostgreSQL 14 natively.
I’ve posted on installing MySQL 8 and PostgreSQL 14 on Ubuntu before when I repurposed my late 2014 MacBook Pro. This post covers the installation of Docker and Oracle Database 23ai.
Install Docker
Contrary to the instructions, you should do the following as a sudoer user:
sudo apt install -y docker.io |
Install all dependency packages using the following command:
sudo snap install docker |
You should see the following:
docker 20.10.24 from Canonical✓ installed |
You can verify the Docker install with the following command:
sudo docker --version |
It should show something like this:
Docker version 24.0.5, build 24.0.5-0ubuntu1~22.04.1 |
You can check the pulled containers with the following command but at this point there should be no pulled containers.
sudo docker images |
At this point, a docker group already exists but you need to add your user to the docker group with the following command:
sudo usermod -aG docker $USER |
Using the Docker Commands:
- To activate the logging, utilize the -f parameter.
- To divide JSON, use Docker by default; to extract individual keys, use JQ.
- In your Container file, there are quite a few areas where commands may be specified.
- Posting to the volumes could be more effective while the picture is being built.
- Docker offers a highly efficient way to create an alias for its own built-in commands. This makes it easier to set up and handle lengthy and enormous orders. These alias values are stored in the directories /.bashrc or and /.bash_aliases.
- Docker offers further assistance to remove unused code fragments from the installation of the container.
- Docker always favors reading statements from the container file that have not changed. Therefore, time savings may be realized by arranging what is shown in the container file in a way that ensures the elements that are susceptible to change are shown towards the end of the document and those that are most likely to undergo change are shown at the top.
Install Oracle Database 23ai Free in a Docker container
Use the following command to pull and install the Oracle Database 23ai container:
sudo docker run --name oracle23ai -p 1521:1521 -p 5500:5500 -e ORACLE_PWD=cangetin container-registry.oracle.com/database/free:latest |
After installing the Oracle Database 23ai Free container, you can access it as the root user by default with this syntax:
docker exec -it -u root oracle23ai bash |
At the root prompt, you can connect to the system schema with the following command:
sqlplus system/cangetin@FREE |
You should see the following:
SQL*Plus: RELEASE 23.0.0.0.0 - Production ON Thu May 9 03:56:57 2024 Version 23.4.0.24.05 Copyright (c) 1982, 2024, Oracle. ALL rights reserved. LAST SUCCESSFUL login TIME: Wed Apr 24 2024 21:23:00 +00:00 Connected TO: Oracle DATABASE 23ai Free RELEASE 23.0.0.0.0 - Develop, Learn, AND Run FOR Free Version 23.4.0.24.05 SQL> |
Create a c##student as a sandbox user:
After you create and provision the Oracle Database 21ai Free, you can create a c##student sand-boxed user with the following two step process.
- Create a c##student Oracle user account with the following command as the system user:
CREATE USER c##student IDENTIFIED BY student DEFAULT TABLESPACE users QUOTA 200M ON users TEMPORARY TABLESPACE temp;
- Grant necessary privileges to the newly created c##student user:
GRANT CREATE CLUSTER, CREATE INDEXTYPE, CREATE OPERATOR , CREATE PROCEDURE, CREATE SEQUENCE, CREATE SESSION , CREATE TABLE, CREATE TRIGGER, CREATE TYPE , CREATE VIEW TO c##student;
- Connect to the sandboxed user with the following syntax (by the way it’s a pluggable user account as qualified in Oracle Database 12c forward):
SQL> CONNECT c##student/student@FREE
or, disconnect and reconnect with this syntax:
sqlplus system/cangetin@FREE
Set Docker Oracle 23ai to start always
Assuming that your container name was oracle23ai, as qualified above, you can run the following command to automatically restart the Docker container:
docker update --restart=always `docker ps -aqf "name=oracle23ai"` |
The docker command inside the backquotes uses the Docker instance’s name to return the Docker container_id value, which can also be seen when you run the following command:
docker ps |
which returns:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES b211f494e692 container-registry.oracle.com/database/free:latest "/bin/bash -c $ORACL…" 13 days ago Up 18 minutes (healthy) 0.0.0.0:1521->1521/tcp, :::1521->1521/tcp, 0.0.0.0:5500->5500/tcp, :::5500->5500/tcp oracle23ai |
The Docker container_id value is required when you perform a Docker update operation.
Configuring your Docker Oracle 23ai environment
Unless you like memorizing the Docker command-line, you may automate connecting as the root user or add a sand boxed user. The root user typically has more power than you need to perform ordinary development and use-case testing tasks.
A sand boxed user has narrow access, can’t start and stop the database instance or perform Oracle Datasbase 23ai administration. In this segment, you’ll learn how to create a couple local Bash functions to simplify your use of the Oracle Database 23ai container; and how to extend the configuration of Oracle’s Docker container:
- Adding a student user to the Docker container and configuring it to access the Oracle Database 23ai locally from within the Docker container using a direct sqlplus connection.
- Configuring the Docker container to support external files and leverage a shared directory with your base operating system.
Automating Docker instance connections:
The following shows you how to add a local Bash function to automate access to the Docker container from the Linux command-line. You put the following Bash function in your base Linux operating system’s user .bashrc file:
- Create the following Bash function:
# User defined function to launch Oracle 23 ai container # as the root user. admin () { # Discover the fully qualified program name. path=`which docker 2>/dev/null` file='' # Parse the program name from the path. if [ -n ${path} ]; then file=${path##/*/} fi # Wrap when there is a file and it is rewrap. if [ -n ${file} ] && [[ ${file} = "docker" ]]; then python -c "import subprocess; subprocess.run(['docker exec -it --user root oracle23ai bash'], shell=True)" else echo "Docker is unavailable: Install the docker package." fi }
- After you source the .bashrc file or simply reconnect as to the terminal as your user, which resources the .bashrc file, you can access the oracle23ai Docker instance with this command:
admin
It will display a new prompt with the root user and the Docker container_id value, like:
[root@b211f494e692 oracle]#
You can exit the Docker container by typing exit at the Linux command line. If you curious what version of Linux you’re using inside the Docker instance, you can’t use the uname command because it returns the hosting Linux distribution (distro). You must use the following when inside the Docker instance:
cat /etc/os-release
or, outside the Docker instance you can use the following docker command:
docker exec oracle23ai cat /etc/os-release
Either way, for an Oracle Database 23ai container, it should return:
NAME="Oracle Linux Server" VERSION="8.9" ID="ol" ID_LIKE="fedora" VARIANT="Server" VARIANT_ID="server" VERSION_ID="8.9" PLATFORM_ID="platform:el8" PRETTY_NAME="Oracle Linux Server 8.9" ANSI_COLOR="0;31" CPE_NAME="cpe:/o:oracle:linux:8:9:server" HOME_URL="https://linux.oracle.com/" BUG_REPORT_URL="https://github.com/oracle/oracle-linux" ORACLE_BUGZILLA_PRODUCT="Oracle Linux 8" ORACLE_BUGZILLA_PRODUCT_VERSION=8.9 ORACLE_SUPPORT_PRODUCT="Oracle Linux" ORACLE_SUPPORT_PRODUCT_VERSION=8.9
Unfortunately, Oracle has appeared to block updates to the Oracle Unbreakable Linux 8 instance inside the container, which makes native SQL*Plus use more difficult. That’s because you’ll need to install the Oracle SQL*Plus client in the hosting Operating System.
I’ve written a separate blog post that instructs you on how to install and use Oracle SQL*Plus client on Ubuntu.
Install SQL Developer in the base Linux operating system
The first steps are installing the Java Runtime Environment and Java Development Kit, and then downloading, installing and configuring SQL Developer. These are the required steps:
- Install the Java Runtime Environment:
sudo apt install default-jre
The log file for this is:
Display detailed console log →
Reading package lists... Done Building dependency tree... Done Reading state information... Done The following additional packages will be installed: ca-certificates-java default-jre-headless fonts-dejavu-extra java-common libatk-wrapper-java libatk-wrapper-java-jni openjdk-11-jre openjdk-11-jre-headless Suggested packages: fonts-ipafont-gothic fonts-ipafont-mincho fonts-wqy-microhei | fonts-wqy-zenhei The following NEW packages will be installed: ca-certificates-java default-jre default-jre-headless fonts-dejavu-extra java-common libatk-wrapper-java libatk-wrapper-java-jni openjdk-11-jre openjdk-11-jre-headless 0 upgraded, 9 newly installed, 0 to remove and 4 not upgraded. Need to get 44.9 MB of archives. After this operation, 185 MB of additional disk space will be used. Do you want to continue? [Y/n] Y Get:1 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 java-common all 0.72build2 [6,782 B] Get:2 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 openjdk-11-jre-headless amd64 11.0.21+9-0ubuntu1~22.04 [42.5 MB] Get:3 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 default-jre-headless amd64 2:1.11-72build2 [3,042 B] Get:4 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 ca-certificates-java all 20190909ubuntu1.2 [12.1 kB] Get:5 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 openjdk-11-jre amd64 11.0.21+9-0ubuntu1~22.04 [214 kB] Get:6 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 default-jre amd64 2:1.11-72build2 [896 B] Get:7 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 fonts-dejavu-extra all 2.37-2build1 [2,041 kB] Get:8 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libatk-wrapper-java all 0.38.0-5build1 [53.1 kB] Get:9 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libatk-wrapper-java-jni amd64 0.38.0-5build1 [49.0 kB] Fetched 44.9 MB in 14s (3,270 kB/s) Selecting previously unselected package java-common. (Reading database ... 203118 files and directories currently installed.) Preparing to unpack .../0-java-common_0.72build2_all.deb ... Unpacking java-common (0.72build2) ... Selecting previously unselected package openjdk-11-jre-headless:amd64. Preparing to unpack .../1-openjdk-11-jre-headless_11.0.21+9-0ubuntu1~22.04_amd64 .deb ... Unpacking openjdk-11-jre-headless:amd64 (11.0.21+9-0ubuntu1~22.04) ... Selecting previously unselected package default-jre-headless. Preparing to unpack .../2-default-jre-headless_2%3a1.11-72build2_amd64.deb ... Unpacking default-jre-headless (2:1.11-72build2) ... Selecting previously unselected package ca-certificates-java. Preparing to unpack .../3-ca-certificates-java_20190909ubuntu1.2_all.deb ... Unpacking ca-certificates-java (20190909ubuntu1.2) ... Selecting previously unselected package openjdk-11-jre:amd64. Preparing to unpack .../4-openjdk-11-jre_11.0.21+9-0ubuntu1~22.04_amd64.deb ... Unpacking openjdk-11-jre:amd64 (11.0.21+9-0ubuntu1~22.04) ... Selecting previously unselected package default-jre. Preparing to unpack .../5-default-jre_2%3a1.11-72build2_amd64.deb ... Unpacking default-jre (2:1.11-72build2) ... Selecting previously unselected package fonts-dejavu-extra. Preparing to unpack .../6-fonts-dejavu-extra_2.37-2build1_all.deb ... Unpacking fonts-dejavu-extra (2.37-2build1) ... Selecting previously unselected package libatk-wrapper-java. Preparing to unpack .../7-libatk-wrapper-java_0.38.0-5build1_all.deb ... Unpacking libatk-wrapper-java (0.38.0-5build1) ... Selecting previously unselected package libatk-wrapper-java-jni:amd64. Preparing to unpack .../8-libatk-wrapper-java-jni_0.38.0-5build1_amd64.deb ... Unpacking libatk-wrapper-java-jni:amd64 (0.38.0-5build1) ... Setting up java-common (0.72build2) ... Setting up fonts-dejavu-extra (2.37-2build1) ... Setting up libatk-wrapper-java (0.38.0-5build1) ... Setting up libatk-wrapper-java-jni:amd64 (0.38.0-5build1) ... Setting up default-jre-headless (2:1.11-72build2) ... Setting up openjdk-11-jre-headless:amd64 (11.0.21+9-0ubuntu1~22.04) ... update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/java to provid e /usr/bin/java (java) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jjs to provide /usr/bin/jjs (jjs) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/keytool to pro vide /usr/bin/keytool (keytool) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/rmid to provid e /usr/bin/rmid (rmid) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/rmiregistry to provide /usr/bin/rmiregistry (rmiregistry) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/pack200 to pro vide /usr/bin/pack200 (pack200) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/unpack200 to p rovide /usr/bin/unpack200 (unpack200) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/lib/jexec to provi de /usr/bin/jexec (jexec) in auto mode Setting up openjdk-11-jre:amd64 (11.0.21+9-0ubuntu1~22.04) ... Setting up default-jre (2:1.11-72build2) ... Setting up ca-certificates-java (20190909ubuntu1.2) ... head: cannot open '/etc/ssl/certs/java/cacerts' for reading: No such file or dir ectory Adding debian:QuoVadis_Root_CA_1_G3.pem Adding debian:GlobalSign_Root_E46.pem Adding debian:T-TeleSec_GlobalRoot_Class_3.pem Adding debian:Certum_Trusted_Network_CA.pem Adding debian:Buypass_Class_2_Root_CA.pem Adding debian:NetLock_Arany_=Class_Gold=_Főtanúsítvány.pem Adding debian:e-Szigno_Root_CA_2017.pem Adding debian:emSign_Root_CA_-_G1.pem Adding debian:D-TRUST_BR_Root_CA_1_2020.pem Adding debian:Hongkong_Post_Root_CA_3.pem Adding debian:GlobalSign_ECC_Root_CA_-_R4.pem Adding debian:NAVER_Global_Root_Certification_Authority.pem Adding debian:UCA_Extended_Validation_Root.pem Adding debian:AffirmTrust_Premium.pem Adding debian:Entrust_Root_Certification_Authority.pem Adding debian:DigiCert_Trusted_Root_G4.pem Adding debian:CFCA_EV_ROOT.pem Adding debian:ePKI_Root_Certification_Authority.pem Adding debian:Hellenic_Academic_and_Research_Institutions_ECC_RootCA_2015.pem Adding debian:HARICA_TLS_RSA_Root_CA_2021.pem Adding debian:GlobalSign_Root_CA_-_R6.pem Adding debian:TWCA_Global_Root_CA.pem Adding debian:Trustwave_Global_ECC_P384_Certification_Authority.pem Adding debian:ISRG_Root_X1.pem Adding debian:Starfield_Services_Root_Certificate_Authority_-_G2.pem Adding debian:QuoVadis_Root_CA_3.pem Adding debian:Security_Communication_Root_CA.pem Adding debian:DigiCert_TLS_RSA4096_Root_G5.pem Adding debian:Entrust_Root_Certification_Authority_-_EC1.pem Adding debian:Security_Communication_RootCA3.pem Adding debian:TeliaSonera_Root_CA_v1.pem Adding debian:vTrus_ECC_Root_CA.pem Adding debian:AC_RAIZ_FNMT-RCM_SERVIDORES_SEGUROS.pem Adding debian:Certum_EC-384_CA.pem Adding debian:Microsec_e-Szigno_Root_CA_2009.pem Adding debian:ssl-cert-snakeoil.pem Adding debian:USERTrust_ECC_Certification_Authority.pem Adding debian:CA_Disig_Root_R2.pem Adding debian:Certum_Trusted_Network_CA_2.pem Adding debian:ACCVRAIZ1.pem Adding debian:TunTrust_Root_CA.pem Adding debian:Buypass_Class_3_Root_CA.pem Adding debian:D-TRUST_Root_Class_3_CA_2_2009.pem Adding debian:Security_Communication_ECC_RootCA1.pem Adding debian:GTS_Root_R2.pem Adding debian:Certigna.pem Adding debian:SSL.com_EV_Root_Certification_Authority_RSA_R2.pem Adding debian:Entrust.net_Premium_2048_Secure_Server_CA.pem Adding debian:E-Tugra_Global_Root_CA_ECC_v3.pem Adding debian:Hongkong_Post_Root_CA_1.pem Adding debian:SZAFIR_ROOT_CA2.pem Adding debian:TUBITAK_Kamu_SM_SSL_Kok_Sertifikasi_-_Surum_1.pem Adding debian:Atos_TrustedRoot_2011.pem Adding debian:DigiCert_High_Assurance_EV_Root_CA.pem Adding debian:emSign_Root_CA_-_C1.pem Adding debian:Go_Daddy_Root_Certificate_Authority_-_G2.pem Adding debian:GDCA_TrustAUTH_R5_ROOT.pem Adding debian:GlobalSign_Root_CA_-_R3.pem Adding debian:DigiCert_Assured_ID_Root_G3.pem Adding debian:Autoridad_de_Certificacion_Firmaprofesional_CIF_A62634068_2.pem Adding debian:Certainly_Root_R1.pem Adding debian:vTrus_Root_CA.pem Adding debian:Certainly_Root_E1.pem Adding debian:Autoridad_de_Certificacion_Firmaprofesional_CIF_A62634068.pem Adding debian:TWCA_Root_Certification_Authority.pem Adding debian:Starfield_Root_Certificate_Authority_-_G2.pem Adding debian:Amazon_Root_CA_3.pem Adding debian:GTS_Root_R1.pem Adding debian:SwissSign_Gold_CA_-_G2.pem Adding debian:Certum_Trusted_Root_CA.pem Adding debian:Hellenic_Academic_and_Research_Institutions_RootCA_2015.pem Adding debian:AffirmTrust_Networking.pem Adding debian:emSign_ECC_Root_CA_-_G3.pem Adding debian:HARICA_TLS_ECC_Root_CA_2021.pem Adding debian:certSIGN_ROOT_CA.pem Adding debian:Actalis_Authentication_Root_CA.pem Adding debian:SSL.com_Root_Certification_Authority_RSA.pem Adding debian:Certigna_Root_CA.pem Adding debian:XRamp_Global_CA_Root.pem Adding debian:Baltimore_CyberTrust_Root.pem Adding debian:Trustwave_Global_ECC_P256_Certification_Authority.pem Adding debian:QuoVadis_Root_CA_2_G3.pem Adding debian:GTS_Root_R3.pem Adding debian:COMODO_RSA_Certification_Authority.pem Adding debian:ISRG_Root_X2.pem Adding debian:SwissSign_Silver_CA_-_G2.pem Adding debian:IdenTrust_Public_Sector_Root_CA_1.pem Adding debian:Microsoft_ECC_Root_Certificate_Authority_2017.pem Adding debian:UCA_Global_G2_Root.pem Adding debian:DigiCert_Assured_ID_Root_CA.pem Adding debian:Entrust_Root_Certification_Authority_-_G2.pem Adding debian:QuoVadis_Root_CA_2.pem Adding debian:Trustwave_Global_Certification_Authority.pem Adding debian:OISTE_WISeKey_Global_Root_GB_CA.pem Adding debian:HiPKI_Root_CA_-_G1.pem Adding debian:E-Tugra_Certification_Authority.pem Adding debian:GTS_Root_R4.pem Adding debian:Amazon_Root_CA_2.pem Adding debian:Amazon_Root_CA_1.pem Adding debian:SecureTrust_CA.pem Adding debian:GlobalSign_Root_R46.pem Adding debian:IdenTrust_Commercial_Root_CA_1.pem Adding debian:DigiCert_Global_Root_G2.pem Adding debian:Comodo_AAA_Services_root.pem Adding debian:SSL.com_Root_Certification_Authority_ECC.pem Adding debian:T-TeleSec_GlobalRoot_Class_2.pem Adding debian:Starfield_Class_2_CA.pem Adding debian:DigiCert_Global_Root_CA.pem Adding debian:SecureSign_RootCA11.pem Adding debian:certSIGN_Root_CA_G2.pem Adding debian:DigiCert_TLS_ECC_P384_Root_G5.pem Adding debian:Entrust_Root_Certification_Authority_-_G4.pem Adding debian:OISTE_WISeKey_Global_Root_GC_CA.pem Adding debian:DigiCert_Global_Root_G3.pem Adding debian:Secure_Global_CA.pem Adding debian:Microsoft_RSA_Root_Certificate_Authority_2017.pem Adding debian:DigiCert_Assured_ID_Root_G2.pem Adding debian:Telia_Root_CA_v2.pem Adding debian:emSign_ECC_Root_CA_-_C3.pem Adding debian:COMODO_Certification_Authority.pem Adding debian:AffirmTrust_Premium_ECC.pem Adding debian:GLOBALTRUST_2020.pem Adding debian:E-Tugra_Global_Root_CA_RSA_v3.pem Adding debian:Amazon_Root_CA_4.pem Adding debian:COMODO_ECC_Certification_Authority.pem Adding debian:AffirmTrust_Commercial.pem Adding debian:SSL.com_EV_Root_Certification_Authority_ECC.pem Adding debian:AC_RAIZ_FNMT-RCM.pem Adding debian:Go_Daddy_Class_2_CA.pem Adding debian:QuoVadis_Root_CA_3_G3.pem Adding debian:D-TRUST_EV_Root_CA_1_2020.pem Adding debian:GlobalSign_Root_CA.pem Adding debian:GlobalSign_ECC_Root_CA_-_R5.pem Adding debian:USERTrust_RSA_Certification_Authority.pem Adding debian:D-TRUST_Root_Class_3_CA_2_EV_2009.pem Adding debian:Izenpe.com.pem Adding debian:ANF_Secure_Server_Root_CA.pem Adding debian:Security_Communication_RootCA2.pem done. Processing triggers for mailcap (3.70+nmu1ubuntu1) ... Processing triggers for fontconfig (2.13.1-4.2ubuntu5) ... Processing triggers for desktop-file-utils (0.26-1ubuntu3) ... Processing triggers for hicolor-icon-theme (0.17-2) ... Processing triggers for gnome-menus (3.36.0-1ubuntu3) ... Processing triggers for man-db (2.10.2-1) ... Processing triggers for ca-certificates (20230311ubuntu0.22.04.1) ... Updating certificates in /etc/ssl/certs... 0 added, 0 removed; done. Running hooks in /etc/ca-certificates/update.d... done. done.
- Install the Java Runtime Environment:
sudo apt install -y default-idk
The log file for this is:
Display detailed console log →
Reading package lists... Done Building dependency tree... Done Reading state information... Done The following additional packages will be installed: default-jdk-headless libice-dev libpthread-stubs0-dev libsm-dev libx11-dev libxau-dev libxcb1-dev libxdmcp-dev libxt-dev openjdk-11-jdk openjdk-11-jdk-headless x11proto-dev xorg-sgml-doctools xtrans-dev Suggested packages: libice-doc libsm-doc libx11-doc libxcb-doc libxt-doc openjdk-11-demo openjdk-11-source visualvm The following NEW packages will be installed: default-jdk default-jdk-headless libice-dev libpthread-stubs0-dev libsm-dev libx11-dev libxau-dev libxcb1-dev libxdmcp-dev libxt-dev openjdk-11-jdk openjdk-11-jdk-headless x11proto-dev xorg-sgml-doctools xtrans-dev 0 upgraded, 15 newly installed, 0 to remove and 4 not upgraded. Need to get 76.9 MB of archives. After this operation, 90.6 MB of additional disk space will be used. Get:1 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 openjdk-11-jdk-headless amd64 11.0.21+9-0ubuntu1~22.04 [73.5 MB] Get:2 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 default-jdk-headless amd64 2:1.11-72build2 [942 B] Get:3 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 openjdk-11-jdk amd64 11.0.21+9-0ubuntu1~22.04 [1,327 kB] Get:4 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 default-jdk amd64 2:1.11-72build2 [908 B] Get:5 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 xorg-sgml-doctools all 1:1.11-1.1 [10.9 kB] Get:6 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 x11proto-dev all 2021.5-1 [604 kB] Get:7 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libice-dev amd64 2:1.0.10-1build2 [51.4 kB] Get:8 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libpthread-stubs0-dev amd64 0.4-1build2 [5,516 B] Get:9 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libsm-dev amd64 2:1.2.3-1build2 [18.1 kB] Get:10 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libxau-dev amd64 1:1.0.9-1build5 [9,724 B] Get:11 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libxdmcp-dev amd64 1:1.1.3-0ubuntu5 [26.5 kB] Get:12 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 xtrans-dev all 1.4.0-1 [68.9 kB] Get:13 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libxcb1-dev amd64 1.14-3ubuntu3 [86.5 kB] Get:14 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libx11-dev amd64 2:1.7.5-1ubuntu0.3 [744 kB] Get:15 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libxt-dev amd64 1:1.2.1-1 [396 kB] Fetched 76.9 MB in 6s (12.7 MB/s) Selecting previously unselected package openjdk-11-jdk-headless:amd64. (Reading database ... 203527 files and directories currently installed.) Preparing to unpack .../00-openjdk-11-jdk-headless_11.0.21+9-0ubuntu1~22.04_amd6 4.deb ... Unpacking openjdk-11-jdk-headless:amd64 (11.0.21+9-0ubuntu1~22.04) ... Selecting previously unselected package default-jdk-headless. Preparing to unpack .../01-default-jdk-headless_2%3a1.11-72build2_amd64.deb ... Unpacking default-jdk-headless (2:1.11-72build2) ... Selecting previously unselected package openjdk-11-jdk:amd64. Preparing to unpack .../02-openjdk-11-jdk_11.0.21+9-0ubuntu1~22.04_amd64.deb ... Unpacking openjdk-11-jdk:amd64 (11.0.21+9-0ubuntu1~22.04) ... Selecting previously unselected package default-jdk. Preparing to unpack .../03-default-jdk_2%3a1.11-72build2_amd64.deb ... Unpacking default-jdk (2:1.11-72build2) ... Selecting previously unselected package xorg-sgml-doctools. Preparing to unpack .../04-xorg-sgml-doctools_1%3a1.11-1.1_all.deb ... Unpacking xorg-sgml-doctools (1:1.11-1.1) ... Selecting previously unselected package x11proto-dev. Preparing to unpack .../05-x11proto-dev_2021.5-1_all.deb ... Unpacking x11proto-dev (2021.5-1) ... Selecting previously unselected package libice-dev:amd64. Preparing to unpack .../06-libice-dev_2%3a1.0.10-1build2_amd64.deb ... Unpacking libice-dev:amd64 (2:1.0.10-1build2) ... Selecting previously unselected package libpthread-stubs0-dev:amd64. Preparing to unpack .../07-libpthread-stubs0-dev_0.4-1build2_amd64.deb ... Unpacking libpthread-stubs0-dev:amd64 (0.4-1build2) ... Selecting previously unselected package libsm-dev:amd64. Preparing to unpack .../08-libsm-dev_2%3a1.2.3-1build2_amd64.deb ... Unpacking libsm-dev:amd64 (2:1.2.3-1build2) ... Selecting previously unselected package libxau-dev:amd64. Preparing to unpack .../09-libxau-dev_1%3a1.0.9-1build5_amd64.deb ... Unpacking libxau-dev:amd64 (1:1.0.9-1build5) ... Selecting previously unselected package libxdmcp-dev:amd64. Preparing to unpack .../10-libxdmcp-dev_1%3a1.1.3-0ubuntu5_amd64.deb ... Unpacking libxdmcp-dev:amd64 (1:1.1.3-0ubuntu5) ... Selecting previously unselected package xtrans-dev. Preparing to unpack .../11-xtrans-dev_1.4.0-1_all.deb ... Unpacking xtrans-dev (1.4.0-1) ... Selecting previously unselected package libxcb1-dev:amd64. Preparing to unpack .../12-libxcb1-dev_1.14-3ubuntu3_amd64.deb ... Unpacking libxcb1-dev:amd64 (1.14-3ubuntu3) ... Selecting previously unselected package libx11-dev:amd64. Preparing to unpack .../13-libx11-dev_2%3a1.7.5-1ubuntu0.3_amd64.deb ... Unpacking libx11-dev:amd64 (2:1.7.5-1ubuntu0.3) ... Selecting previously unselected package libxt-dev:amd64. Preparing to unpack .../14-libxt-dev_1%3a1.2.1-1_amd64.deb ... Unpacking libxt-dev:amd64 (1:1.2.1-1) ... Setting up openjdk-11-jdk-headless:amd64 (11.0.21+9-0ubuntu1~22.04) ... update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jar to provide /usr/bin/jar (jar) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jarsigner to p rovide /usr/bin/jarsigner (jarsigner) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/javac to provi de /usr/bin/javac (javac) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/javadoc to pro vide /usr/bin/javadoc (javadoc) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/javap to provi de /usr/bin/javap (javap) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jcmd to provid e /usr/bin/jcmd (jcmd) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jdb to provide /usr/bin/jdb (jdb) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jdeprscan to p rovide /usr/bin/jdeprscan (jdeprscan) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jdeps to provi de /usr/bin/jdeps (jdeps) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jfr to provide /usr/bin/jfr (jfr) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jimage to prov ide /usr/bin/jimage (jimage) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jinfo to provi de /usr/bin/jinfo (jinfo) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jlink to provi de /usr/bin/jlink (jlink) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jmap to provid e /usr/bin/jmap (jmap) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jmod to provid e /usr/bin/jmod (jmod) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jps to provide /usr/bin/jps (jps) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jrunscript to provide /usr/bin/jrunscript (jrunscript) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jshell to prov ide /usr/bin/jshell (jshell) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jstack to prov ide /usr/bin/jstack (jstack) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jstat to provi de /usr/bin/jstat (jstat) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jstatd to prov ide /usr/bin/jstatd (jstatd) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/rmic to provid e /usr/bin/rmic (rmic) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/serialver to p rovide /usr/bin/serialver (serialver) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jaotc to provi de /usr/bin/jaotc (jaotc) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jhsdb to provi de /usr/bin/jhsdb (jhsdb) in auto mode Setting up libpthread-stubs0-dev:amd64 (0.4-1build2) ... Setting up xtrans-dev (1.4.0-1) ... Setting up default-jdk-headless (2:1.11-72build2) ... Setting up openjdk-11-jdk:amd64 (11.0.21+9-0ubuntu1~22.04) ... update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jconsole to pr ovide /usr/bin/jconsole (jconsole) in auto mode Setting up xorg-sgml-doctools (1:1.11-1.1) ... Setting up default-jdk (2:1.11-72build2) ... Processing triggers for sgml-base (1.30) ... Setting up x11proto-dev (2021.5-1) ... Setting up libxau-dev:amd64 (1:1.0.9-1build5) ... Setting up libice-dev:amd64 (2:1.0.10-1build2) ... Setting up libsm-dev:amd64 (2:1.2.3-1build2) ... Processing triggers for man-db (2.10.2-1) ... Setting up libxdmcp-dev:amd64 (1:1.1.3-0ubuntu5) ... Setting up libxcb1-dev:amd64 (1.14-3ubuntu3) ... Setting up libx11-dev:amd64 (2:1.7.5-1ubuntu0.3) ... Setting up libxt-dev:amd64 (1:1.2.1-1) ...
- Download SQL Developer from here; and then install SQL Developer to the /opt directory on your Ubuntu local instance:
Use the following command to unzip the SQL Developer files to the /opt directory:
sudo unzip ~/Downloads/sqldeveloper-23.1.0.097.1607-no-jre.zip
- Create the following /usr/local/bin/sqldeveloper symbolic link:
sudo ln -s /opt/sqldeveloper/sqldeveloper.sh /usr/local/bin/sqldeveloper
- Edit the /opt/sqldeveloper/sqldeveloper.sh file by replacing the following line:
cd "`dirname $0`"/sqldeveloper/bin && bash sqldeveloper $*
with this version:
/opt/sqldeveloper/sqldeveloper/bin/sqldeveloper $*
- Now, you can launch SQL Developer from any location on your local Ubuntu operating system, like:
sqldeveloper
- You can now connect as the system user through SQL Developer to the Oracle Database 23ai Free Docker instance with the following connection information:
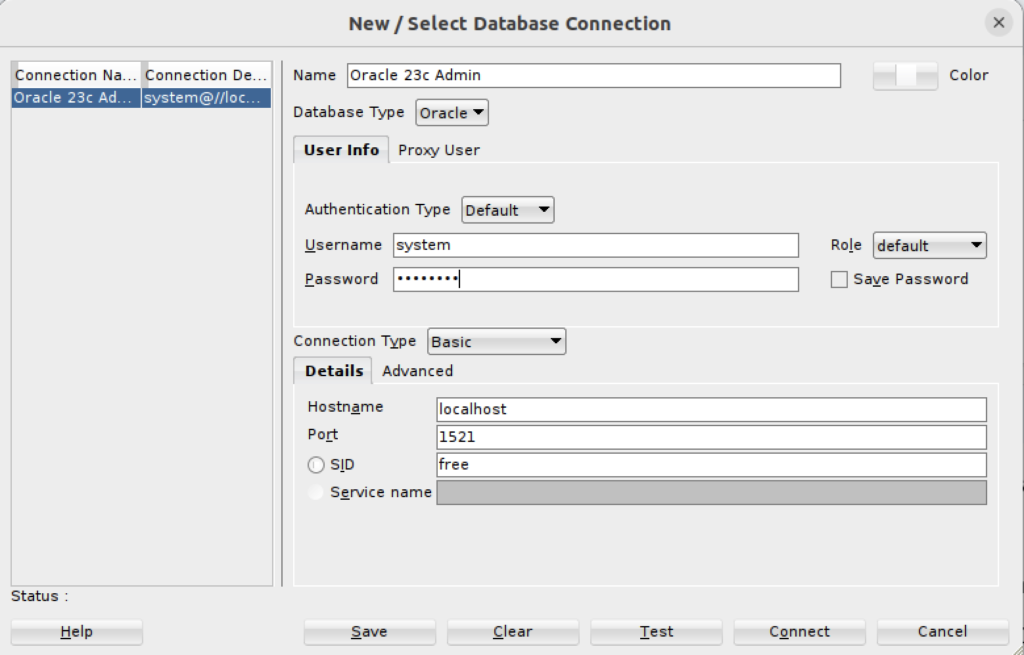
(Excuse recycling the version from 21c but I didn’t see any utility in making a new screen shot.)
- You can also create a Desktop shortcut by creating the sqldeveloper.desktop file in the /usr/share/applications directory. The SQL Developer icon is provided in the sqldeveloper base directory.

You should create the following sqldeveloper.desktop file to use a Desktop shortcut:
[Desktop Entry] Name=Oracle SQL Developer Comment=SQL Developer from Oracle GenericName=SQL Tool Exec=/usr/local/bin/sqldeveloper Icon=/opt/sqldeveloper/icon.png Type=Application StartupNotify=true Categories=Utility;Oracle;Development;SQL;
As always, I hope this helps those trying to accomplish this task.
SQL Developer on Ubuntu
The following steps show how to install and configure SQL Developer on Ubuntu 22.0.4 to work with Oracle Database 23c Free in a Docker container. The first steps are installing the Java Runtime Environment and Java Development Kit, and then downloading, installing and configuring SQL Developer. These are the required steps:
- Install the Java Runtime Environment:
sudo apt install default-jre
The log file for this is:
Display detailed console log →
Reading package lists... Done Building dependency tree... Done Reading state information... Done The following additional packages will be installed: ca-certificates-java default-jre-headless fonts-dejavu-extra java-common libatk-wrapper-java libatk-wrapper-java-jni openjdk-11-jre openjdk-11-jre-headless Suggested packages: fonts-ipafont-gothic fonts-ipafont-mincho fonts-wqy-microhei | fonts-wqy-zenhei The following NEW packages will be installed: ca-certificates-java default-jre default-jre-headless fonts-dejavu-extra java-common libatk-wrapper-java libatk-wrapper-java-jni openjdk-11-jre openjdk-11-jre-headless 0 upgraded, 9 newly installed, 0 to remove and 4 not upgraded. Need to get 44.9 MB of archives. After this operation, 185 MB of additional disk space will be used. Do you want to continue? [Y/n] Y Get:1 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 java-common all 0.72build2 [6,782 B] Get:2 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 openjdk-11-jre-headless amd64 11.0.21+9-0ubuntu1~22.04 [42.5 MB] Get:3 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 default-jre-headless amd64 2:1.11-72build2 [3,042 B] Get:4 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 ca-certificates-java all 20190909ubuntu1.2 [12.1 kB] Get:5 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 openjdk-11-jre amd64 11.0.21+9-0ubuntu1~22.04 [214 kB] Get:6 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 default-jre amd64 2:1.11-72build2 [896 B] Get:7 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 fonts-dejavu-extra all 2.37-2build1 [2,041 kB] Get:8 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libatk-wrapper-java all 0.38.0-5build1 [53.1 kB] Get:9 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libatk-wrapper-java-jni amd64 0.38.0-5build1 [49.0 kB] Fetched 44.9 MB in 14s (3,270 kB/s) Selecting previously unselected package java-common. (Reading database ... 203118 files and directories currently installed.) Preparing to unpack .../0-java-common_0.72build2_all.deb ... Unpacking java-common (0.72build2) ... Selecting previously unselected package openjdk-11-jre-headless:amd64. Preparing to unpack .../1-openjdk-11-jre-headless_11.0.21+9-0ubuntu1~22.04_amd64 .deb ... Unpacking openjdk-11-jre-headless:amd64 (11.0.21+9-0ubuntu1~22.04) ... Selecting previously unselected package default-jre-headless. Preparing to unpack .../2-default-jre-headless_2%3a1.11-72build2_amd64.deb ... Unpacking default-jre-headless (2:1.11-72build2) ... Selecting previously unselected package ca-certificates-java. Preparing to unpack .../3-ca-certificates-java_20190909ubuntu1.2_all.deb ... Unpacking ca-certificates-java (20190909ubuntu1.2) ... Selecting previously unselected package openjdk-11-jre:amd64. Preparing to unpack .../4-openjdk-11-jre_11.0.21+9-0ubuntu1~22.04_amd64.deb ... Unpacking openjdk-11-jre:amd64 (11.0.21+9-0ubuntu1~22.04) ... Selecting previously unselected package default-jre. Preparing to unpack .../5-default-jre_2%3a1.11-72build2_amd64.deb ... Unpacking default-jre (2:1.11-72build2) ... Selecting previously unselected package fonts-dejavu-extra. Preparing to unpack .../6-fonts-dejavu-extra_2.37-2build1_all.deb ... Unpacking fonts-dejavu-extra (2.37-2build1) ... Selecting previously unselected package libatk-wrapper-java. Preparing to unpack .../7-libatk-wrapper-java_0.38.0-5build1_all.deb ... Unpacking libatk-wrapper-java (0.38.0-5build1) ... Selecting previously unselected package libatk-wrapper-java-jni:amd64. Preparing to unpack .../8-libatk-wrapper-java-jni_0.38.0-5build1_amd64.deb ... Unpacking libatk-wrapper-java-jni:amd64 (0.38.0-5build1) ... Setting up java-common (0.72build2) ... Setting up fonts-dejavu-extra (2.37-2build1) ... Setting up libatk-wrapper-java (0.38.0-5build1) ... Setting up libatk-wrapper-java-jni:amd64 (0.38.0-5build1) ... Setting up default-jre-headless (2:1.11-72build2) ... Setting up openjdk-11-jre-headless:amd64 (11.0.21+9-0ubuntu1~22.04) ... update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/java to provid e /usr/bin/java (java) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jjs to provide /usr/bin/jjs (jjs) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/keytool to pro vide /usr/bin/keytool (keytool) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/rmid to provid e /usr/bin/rmid (rmid) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/rmiregistry to provide /usr/bin/rmiregistry (rmiregistry) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/pack200 to pro vide /usr/bin/pack200 (pack200) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/unpack200 to p rovide /usr/bin/unpack200 (unpack200) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/lib/jexec to provi de /usr/bin/jexec (jexec) in auto mode Setting up openjdk-11-jre:amd64 (11.0.21+9-0ubuntu1~22.04) ... Setting up default-jre (2:1.11-72build2) ... Setting up ca-certificates-java (20190909ubuntu1.2) ... head: cannot open '/etc/ssl/certs/java/cacerts' for reading: No such file or dir ectory Adding debian:QuoVadis_Root_CA_1_G3.pem Adding debian:GlobalSign_Root_E46.pem Adding debian:T-TeleSec_GlobalRoot_Class_3.pem Adding debian:Certum_Trusted_Network_CA.pem Adding debian:Buypass_Class_2_Root_CA.pem Adding debian:NetLock_Arany_=Class_Gold=_Főtanúsítvány.pem Adding debian:e-Szigno_Root_CA_2017.pem Adding debian:emSign_Root_CA_-_G1.pem Adding debian:D-TRUST_BR_Root_CA_1_2020.pem Adding debian:Hongkong_Post_Root_CA_3.pem Adding debian:GlobalSign_ECC_Root_CA_-_R4.pem Adding debian:NAVER_Global_Root_Certification_Authority.pem Adding debian:UCA_Extended_Validation_Root.pem Adding debian:AffirmTrust_Premium.pem Adding debian:Entrust_Root_Certification_Authority.pem Adding debian:DigiCert_Trusted_Root_G4.pem Adding debian:CFCA_EV_ROOT.pem Adding debian:ePKI_Root_Certification_Authority.pem Adding debian:Hellenic_Academic_and_Research_Institutions_ECC_RootCA_2015.pem Adding debian:HARICA_TLS_RSA_Root_CA_2021.pem Adding debian:GlobalSign_Root_CA_-_R6.pem Adding debian:TWCA_Global_Root_CA.pem Adding debian:Trustwave_Global_ECC_P384_Certification_Authority.pem Adding debian:ISRG_Root_X1.pem Adding debian:Starfield_Services_Root_Certificate_Authority_-_G2.pem Adding debian:QuoVadis_Root_CA_3.pem Adding debian:Security_Communication_Root_CA.pem Adding debian:DigiCert_TLS_RSA4096_Root_G5.pem Adding debian:Entrust_Root_Certification_Authority_-_EC1.pem Adding debian:Security_Communication_RootCA3.pem Adding debian:TeliaSonera_Root_CA_v1.pem Adding debian:vTrus_ECC_Root_CA.pem Adding debian:AC_RAIZ_FNMT-RCM_SERVIDORES_SEGUROS.pem Adding debian:Certum_EC-384_CA.pem Adding debian:Microsec_e-Szigno_Root_CA_2009.pem Adding debian:ssl-cert-snakeoil.pem Adding debian:USERTrust_ECC_Certification_Authority.pem Adding debian:CA_Disig_Root_R2.pem Adding debian:Certum_Trusted_Network_CA_2.pem Adding debian:ACCVRAIZ1.pem Adding debian:TunTrust_Root_CA.pem Adding debian:Buypass_Class_3_Root_CA.pem Adding debian:D-TRUST_Root_Class_3_CA_2_2009.pem Adding debian:Security_Communication_ECC_RootCA1.pem Adding debian:GTS_Root_R2.pem Adding debian:Certigna.pem Adding debian:SSL.com_EV_Root_Certification_Authority_RSA_R2.pem Adding debian:Entrust.net_Premium_2048_Secure_Server_CA.pem Adding debian:E-Tugra_Global_Root_CA_ECC_v3.pem Adding debian:Hongkong_Post_Root_CA_1.pem Adding debian:SZAFIR_ROOT_CA2.pem Adding debian:TUBITAK_Kamu_SM_SSL_Kok_Sertifikasi_-_Surum_1.pem Adding debian:Atos_TrustedRoot_2011.pem Adding debian:DigiCert_High_Assurance_EV_Root_CA.pem Adding debian:emSign_Root_CA_-_C1.pem Adding debian:Go_Daddy_Root_Certificate_Authority_-_G2.pem Adding debian:GDCA_TrustAUTH_R5_ROOT.pem Adding debian:GlobalSign_Root_CA_-_R3.pem Adding debian:DigiCert_Assured_ID_Root_G3.pem Adding debian:Autoridad_de_Certificacion_Firmaprofesional_CIF_A62634068_2.pem Adding debian:Certainly_Root_R1.pem Adding debian:vTrus_Root_CA.pem Adding debian:Certainly_Root_E1.pem Adding debian:Autoridad_de_Certificacion_Firmaprofesional_CIF_A62634068.pem Adding debian:TWCA_Root_Certification_Authority.pem Adding debian:Starfield_Root_Certificate_Authority_-_G2.pem Adding debian:Amazon_Root_CA_3.pem Adding debian:GTS_Root_R1.pem Adding debian:SwissSign_Gold_CA_-_G2.pem Adding debian:Certum_Trusted_Root_CA.pem Adding debian:Hellenic_Academic_and_Research_Institutions_RootCA_2015.pem Adding debian:AffirmTrust_Networking.pem Adding debian:emSign_ECC_Root_CA_-_G3.pem Adding debian:HARICA_TLS_ECC_Root_CA_2021.pem Adding debian:certSIGN_ROOT_CA.pem Adding debian:Actalis_Authentication_Root_CA.pem Adding debian:SSL.com_Root_Certification_Authority_RSA.pem Adding debian:Certigna_Root_CA.pem Adding debian:XRamp_Global_CA_Root.pem Adding debian:Baltimore_CyberTrust_Root.pem Adding debian:Trustwave_Global_ECC_P256_Certification_Authority.pem Adding debian:QuoVadis_Root_CA_2_G3.pem Adding debian:GTS_Root_R3.pem Adding debian:COMODO_RSA_Certification_Authority.pem Adding debian:ISRG_Root_X2.pem Adding debian:SwissSign_Silver_CA_-_G2.pem Adding debian:IdenTrust_Public_Sector_Root_CA_1.pem Adding debian:Microsoft_ECC_Root_Certificate_Authority_2017.pem Adding debian:UCA_Global_G2_Root.pem Adding debian:DigiCert_Assured_ID_Root_CA.pem Adding debian:Entrust_Root_Certification_Authority_-_G2.pem Adding debian:QuoVadis_Root_CA_2.pem Adding debian:Trustwave_Global_Certification_Authority.pem Adding debian:OISTE_WISeKey_Global_Root_GB_CA.pem Adding debian:HiPKI_Root_CA_-_G1.pem Adding debian:E-Tugra_Certification_Authority.pem Adding debian:GTS_Root_R4.pem Adding debian:Amazon_Root_CA_2.pem Adding debian:Amazon_Root_CA_1.pem Adding debian:SecureTrust_CA.pem Adding debian:GlobalSign_Root_R46.pem Adding debian:IdenTrust_Commercial_Root_CA_1.pem Adding debian:DigiCert_Global_Root_G2.pem Adding debian:Comodo_AAA_Services_root.pem Adding debian:SSL.com_Root_Certification_Authority_ECC.pem Adding debian:T-TeleSec_GlobalRoot_Class_2.pem Adding debian:Starfield_Class_2_CA.pem Adding debian:DigiCert_Global_Root_CA.pem Adding debian:SecureSign_RootCA11.pem Adding debian:certSIGN_Root_CA_G2.pem Adding debian:DigiCert_TLS_ECC_P384_Root_G5.pem Adding debian:Entrust_Root_Certification_Authority_-_G4.pem Adding debian:OISTE_WISeKey_Global_Root_GC_CA.pem Adding debian:DigiCert_Global_Root_G3.pem Adding debian:Secure_Global_CA.pem Adding debian:Microsoft_RSA_Root_Certificate_Authority_2017.pem Adding debian:DigiCert_Assured_ID_Root_G2.pem Adding debian:Telia_Root_CA_v2.pem Adding debian:emSign_ECC_Root_CA_-_C3.pem Adding debian:COMODO_Certification_Authority.pem Adding debian:AffirmTrust_Premium_ECC.pem Adding debian:GLOBALTRUST_2020.pem Adding debian:E-Tugra_Global_Root_CA_RSA_v3.pem Adding debian:Amazon_Root_CA_4.pem Adding debian:COMODO_ECC_Certification_Authority.pem Adding debian:AffirmTrust_Commercial.pem Adding debian:SSL.com_EV_Root_Certification_Authority_ECC.pem Adding debian:AC_RAIZ_FNMT-RCM.pem Adding debian:Go_Daddy_Class_2_CA.pem Adding debian:QuoVadis_Root_CA_3_G3.pem Adding debian:D-TRUST_EV_Root_CA_1_2020.pem Adding debian:GlobalSign_Root_CA.pem Adding debian:GlobalSign_ECC_Root_CA_-_R5.pem Adding debian:USERTrust_RSA_Certification_Authority.pem Adding debian:D-TRUST_Root_Class_3_CA_2_EV_2009.pem Adding debian:Izenpe.com.pem Adding debian:ANF_Secure_Server_Root_CA.pem Adding debian:Security_Communication_RootCA2.pem done. Processing triggers for mailcap (3.70+nmu1ubuntu1) ... Processing triggers for fontconfig (2.13.1-4.2ubuntu5) ... Processing triggers for desktop-file-utils (0.26-1ubuntu3) ... Processing triggers for hicolor-icon-theme (0.17-2) ... Processing triggers for gnome-menus (3.36.0-1ubuntu3) ... Processing triggers for man-db (2.10.2-1) ... Processing triggers for ca-certificates (20230311ubuntu0.22.04.1) ... Updating certificates in /etc/ssl/certs... 0 added, 0 removed; done. Running hooks in /etc/ca-certificates/update.d... done. done.
- Install the Java Runtime Environment:
sudo apt install -y default-idk
The log file for this is:
Display detailed console log →
Reading package lists... Done Building dependency tree... Done Reading state information... Done The following additional packages will be installed: default-jdk-headless libice-dev libpthread-stubs0-dev libsm-dev libx11-dev libxau-dev libxcb1-dev libxdmcp-dev libxt-dev openjdk-11-jdk openjdk-11-jdk-headless x11proto-dev xorg-sgml-doctools xtrans-dev Suggested packages: libice-doc libsm-doc libx11-doc libxcb-doc libxt-doc openjdk-11-demo openjdk-11-source visualvm The following NEW packages will be installed: default-jdk default-jdk-headless libice-dev libpthread-stubs0-dev libsm-dev libx11-dev libxau-dev libxcb1-dev libxdmcp-dev libxt-dev openjdk-11-jdk openjdk-11-jdk-headless x11proto-dev xorg-sgml-doctools xtrans-dev 0 upgraded, 15 newly installed, 0 to remove and 4 not upgraded. Need to get 76.9 MB of archives. After this operation, 90.6 MB of additional disk space will be used. Get:1 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 openjdk-11-jdk-headless amd64 11.0.21+9-0ubuntu1~22.04 [73.5 MB] Get:2 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 default-jdk-headless amd64 2:1.11-72build2 [942 B] Get:3 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 openjdk-11-jdk amd64 11.0.21+9-0ubuntu1~22.04 [1,327 kB] Get:4 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 default-jdk amd64 2:1.11-72build2 [908 B] Get:5 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 xorg-sgml-doctools all 1:1.11-1.1 [10.9 kB] Get:6 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 x11proto-dev all 2021.5-1 [604 kB] Get:7 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libice-dev amd64 2:1.0.10-1build2 [51.4 kB] Get:8 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libpthread-stubs0-dev amd64 0.4-1build2 [5,516 B] Get:9 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libsm-dev amd64 2:1.2.3-1build2 [18.1 kB] Get:10 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libxau-dev amd64 1:1.0.9-1build5 [9,724 B] Get:11 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libxdmcp-dev amd64 1:1.1.3-0ubuntu5 [26.5 kB] Get:12 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 xtrans-dev all 1.4.0-1 [68.9 kB] Get:13 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libxcb1-dev amd64 1.14-3ubuntu3 [86.5 kB] Get:14 http://us.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libx11-dev amd64 2:1.7.5-1ubuntu0.3 [744 kB] Get:15 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 libxt-dev amd64 1:1.2.1-1 [396 kB] Fetched 76.9 MB in 6s (12.7 MB/s) Selecting previously unselected package openjdk-11-jdk-headless:amd64. (Reading database ... 203527 files and directories currently installed.) Preparing to unpack .../00-openjdk-11-jdk-headless_11.0.21+9-0ubuntu1~22.04_amd6 4.deb ... Unpacking openjdk-11-jdk-headless:amd64 (11.0.21+9-0ubuntu1~22.04) ... Selecting previously unselected package default-jdk-headless. Preparing to unpack .../01-default-jdk-headless_2%3a1.11-72build2_amd64.deb ... Unpacking default-jdk-headless (2:1.11-72build2) ... Selecting previously unselected package openjdk-11-jdk:amd64. Preparing to unpack .../02-openjdk-11-jdk_11.0.21+9-0ubuntu1~22.04_amd64.deb ... Unpacking openjdk-11-jdk:amd64 (11.0.21+9-0ubuntu1~22.04) ... Selecting previously unselected package default-jdk. Preparing to unpack .../03-default-jdk_2%3a1.11-72build2_amd64.deb ... Unpacking default-jdk (2:1.11-72build2) ... Selecting previously unselected package xorg-sgml-doctools. Preparing to unpack .../04-xorg-sgml-doctools_1%3a1.11-1.1_all.deb ... Unpacking xorg-sgml-doctools (1:1.11-1.1) ... Selecting previously unselected package x11proto-dev. Preparing to unpack .../05-x11proto-dev_2021.5-1_all.deb ... Unpacking x11proto-dev (2021.5-1) ... Selecting previously unselected package libice-dev:amd64. Preparing to unpack .../06-libice-dev_2%3a1.0.10-1build2_amd64.deb ... Unpacking libice-dev:amd64 (2:1.0.10-1build2) ... Selecting previously unselected package libpthread-stubs0-dev:amd64. Preparing to unpack .../07-libpthread-stubs0-dev_0.4-1build2_amd64.deb ... Unpacking libpthread-stubs0-dev:amd64 (0.4-1build2) ... Selecting previously unselected package libsm-dev:amd64. Preparing to unpack .../08-libsm-dev_2%3a1.2.3-1build2_amd64.deb ... Unpacking libsm-dev:amd64 (2:1.2.3-1build2) ... Selecting previously unselected package libxau-dev:amd64. Preparing to unpack .../09-libxau-dev_1%3a1.0.9-1build5_amd64.deb ... Unpacking libxau-dev:amd64 (1:1.0.9-1build5) ... Selecting previously unselected package libxdmcp-dev:amd64. Preparing to unpack .../10-libxdmcp-dev_1%3a1.1.3-0ubuntu5_amd64.deb ... Unpacking libxdmcp-dev:amd64 (1:1.1.3-0ubuntu5) ... Selecting previously unselected package xtrans-dev. Preparing to unpack .../11-xtrans-dev_1.4.0-1_all.deb ... Unpacking xtrans-dev (1.4.0-1) ... Selecting previously unselected package libxcb1-dev:amd64. Preparing to unpack .../12-libxcb1-dev_1.14-3ubuntu3_amd64.deb ... Unpacking libxcb1-dev:amd64 (1.14-3ubuntu3) ... Selecting previously unselected package libx11-dev:amd64. Preparing to unpack .../13-libx11-dev_2%3a1.7.5-1ubuntu0.3_amd64.deb ... Unpacking libx11-dev:amd64 (2:1.7.5-1ubuntu0.3) ... Selecting previously unselected package libxt-dev:amd64. Preparing to unpack .../14-libxt-dev_1%3a1.2.1-1_amd64.deb ... Unpacking libxt-dev:amd64 (1:1.2.1-1) ... Setting up openjdk-11-jdk-headless:amd64 (11.0.21+9-0ubuntu1~22.04) ... update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jar to provide /usr/bin/jar (jar) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jarsigner to p rovide /usr/bin/jarsigner (jarsigner) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/javac to provi de /usr/bin/javac (javac) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/javadoc to pro vide /usr/bin/javadoc (javadoc) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/javap to provi de /usr/bin/javap (javap) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jcmd to provid e /usr/bin/jcmd (jcmd) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jdb to provide /usr/bin/jdb (jdb) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jdeprscan to p rovide /usr/bin/jdeprscan (jdeprscan) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jdeps to provi de /usr/bin/jdeps (jdeps) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jfr to provide /usr/bin/jfr (jfr) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jimage to prov ide /usr/bin/jimage (jimage) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jinfo to provi de /usr/bin/jinfo (jinfo) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jlink to provi de /usr/bin/jlink (jlink) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jmap to provid e /usr/bin/jmap (jmap) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jmod to provid e /usr/bin/jmod (jmod) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jps to provide /usr/bin/jps (jps) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jrunscript to provide /usr/bin/jrunscript (jrunscript) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jshell to prov ide /usr/bin/jshell (jshell) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jstack to prov ide /usr/bin/jstack (jstack) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jstat to provi de /usr/bin/jstat (jstat) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jstatd to prov ide /usr/bin/jstatd (jstatd) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/rmic to provid e /usr/bin/rmic (rmic) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/serialver to p rovide /usr/bin/serialver (serialver) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jaotc to provi de /usr/bin/jaotc (jaotc) in auto mode update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jhsdb to provi de /usr/bin/jhsdb (jhsdb) in auto mode Setting up libpthread-stubs0-dev:amd64 (0.4-1build2) ... Setting up xtrans-dev (1.4.0-1) ... Setting up default-jdk-headless (2:1.11-72build2) ... Setting up openjdk-11-jdk:amd64 (11.0.21+9-0ubuntu1~22.04) ... update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/jconsole to pr ovide /usr/bin/jconsole (jconsole) in auto mode Setting up xorg-sgml-doctools (1:1.11-1.1) ... Setting up default-jdk (2:1.11-72build2) ... Processing triggers for sgml-base (1.30) ... Setting up x11proto-dev (2021.5-1) ... Setting up libxau-dev:amd64 (1:1.0.9-1build5) ... Setting up libice-dev:amd64 (2:1.0.10-1build2) ... Setting up libsm-dev:amd64 (2:1.2.3-1build2) ... Processing triggers for man-db (2.10.2-1) ... Setting up libxdmcp-dev:amd64 (1:1.1.3-0ubuntu5) ... Setting up libxcb1-dev:amd64 (1.14-3ubuntu3) ... Setting up libx11-dev:amd64 (2:1.7.5-1ubuntu0.3) ... Setting up libxt-dev:amd64 (1:1.2.1-1) ...
- Download SQL Developer from here; and then install SQL Developer to the /opt directory on your Ubuntu local instance:
Use the following command to unzip the SQL Developer files to the /opt directory:
sudo unzip ~/Downloads/sqldeveloper-23.1.0.097.1607-no-jre.zip
- Create the following /usr/local/bin/sqldeveloper symbolic link:
sudo ln -s /opt/sqldeveloper/sqldeveloper.sh /usr/local/bin/sqldeveloper
- Edit the /opt/sqldeveloper/sqldeveloper.sh file by replacing the following line:
cd "`dirname $0`"/sqldeveloper/bin && bash sqldeveloper $*
with this version:
/opt/sqldeveloper/sqldeveloper/bin/sqldeveloper $*
- Now, you can launch SQL Developer from any location on your local Ubuntu operating system, like:
sqldeveloper
- You can now connect as the system user through SQL Developer to the Oracle Database 23c Free Docker instance with the following connection information:
- You can also create a Desktop shortcut by creating the sqldeveloper.desktop file in the /usr/share/applications directory. The SQL Developer icon is provided in the sqldeveloper base directory.
You should create the following sqldeveloper.desktop file to use a Desktop shortcut:
[Desktop Entry] Name=Oracle SQL Developer Comment=SQL Developer from Oracle GenericName=SQL Tool Exec=/usr/local/bin/sqldeveloper Icon=/opt/sqldeveloper/icon.png Type=Application StartupNotify=true Categories=Utility;Oracle;Development;SQL;
You can create a sandboxed container c##student user with the instructions from this earlier post on Oracle Database 18c, which remains the correct syntax.
As always, I hope this helps those trying to accomplish this task.
SQL Developer & PostgreSQL
I had a request from one of the adjunct professors to connect SQL Developer to the PostgreSQL database. This is in support of our database programming class that teaches students how to write PL/SQL against the Oracle database and pgPL/SQL against the PostgreSQL database. We also demonstrate transactional management through Node.js, Python and Java.
Naturally, this is also a frequent step taken by those required to migrate PostgreSQL data models to an Oracle database. While my final solution requires mimicking Oracle’s database user to schema, it does work for migration purposes. I’ll update this post when I determine how to populate the database drop-down list.
The first step was figuring out where to put the PostgreSQL JDBC Java ARchive (.jar) file on a Linux distribution. You navigate to the end-user student account in a Terminal and change to the .sqldeveloper directory. Then, create a jdbc subdirectory as the student user with the following command:
mkdir /home/student/.sqldeveloper/jdbc |
Then, download the most current PostgreSQL JDBC Java ARchive (.jar) file and copy it into the /home/student/.sqldeveloper/jdbc, which you can see afterward with the following command:
ll /home/student/.sqldeveloper/jdbc |
It should display:
-rw-r--r--. 1 student student 1041081 Aug 9 13:46 postgresql-42.3.7.jar |
The next series of steps are done within SQL Developer. Launch SQL Developer and navigate to Tools and Preferences, like this:
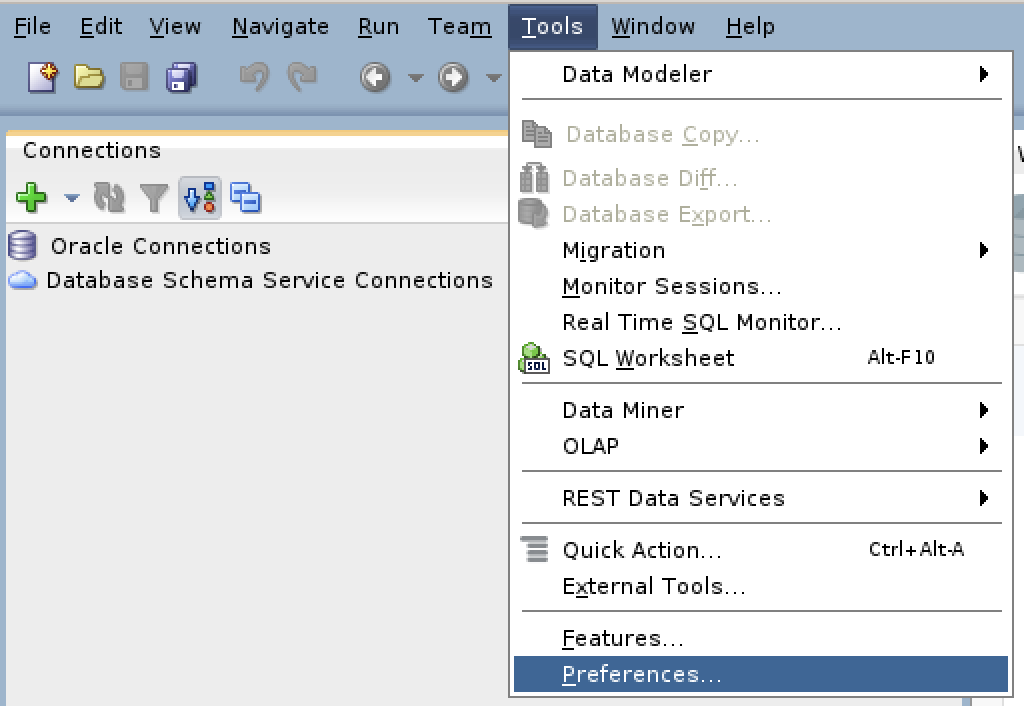
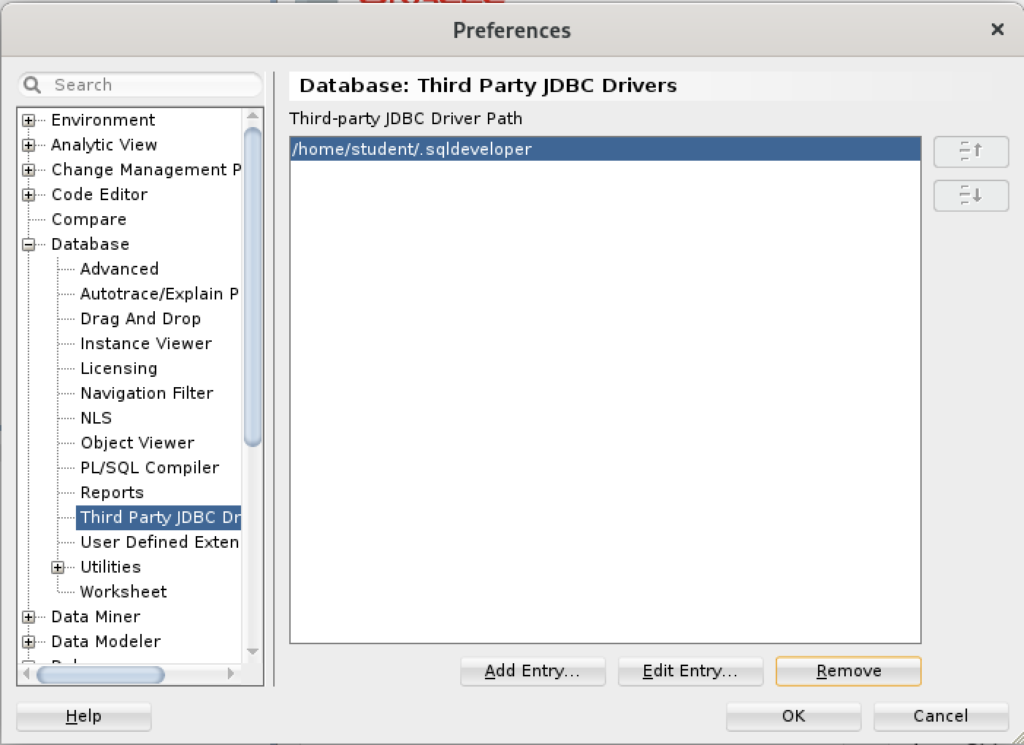
Inside the Preferences dialog, navigate to Database and Third Party JDBC Drivers like shown and click the Add Entry button to proceed:
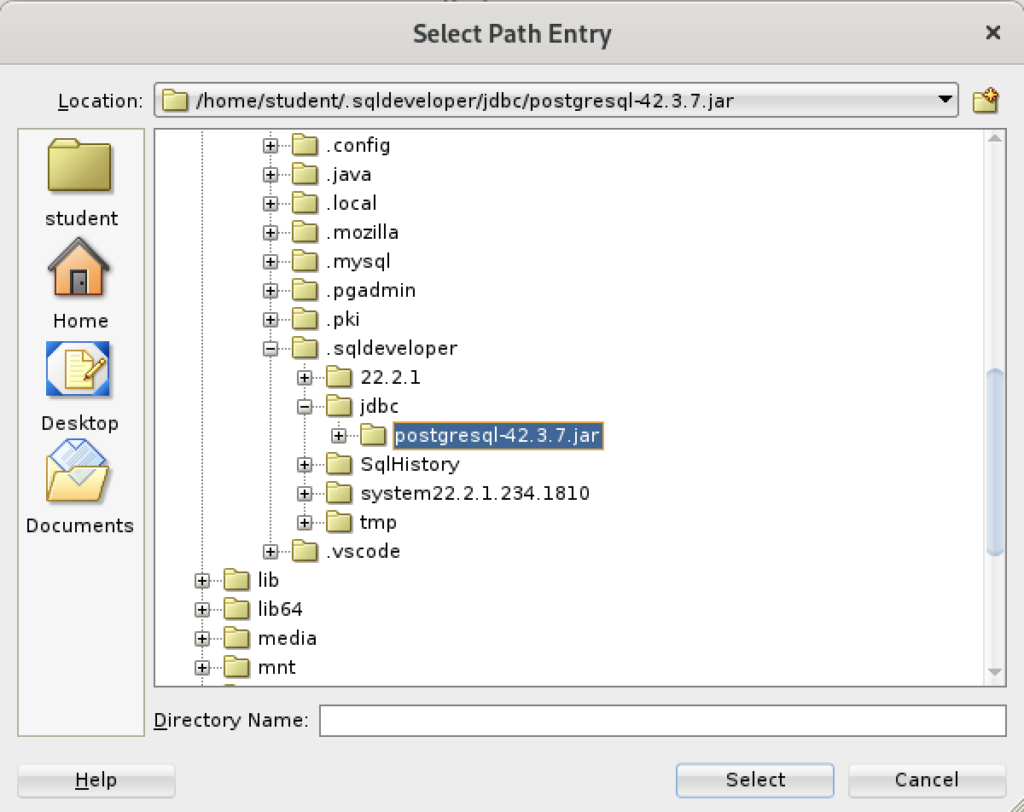
Inside the Select Path Entry dialog, select the current PostgreSQL JDBC Java ARchive (.jar) file, which is postgresql-42-3.7.jar in this example. Then, click the Select button.
You are returned to the Preferences dialog as shown below. Click the OK button to continue.
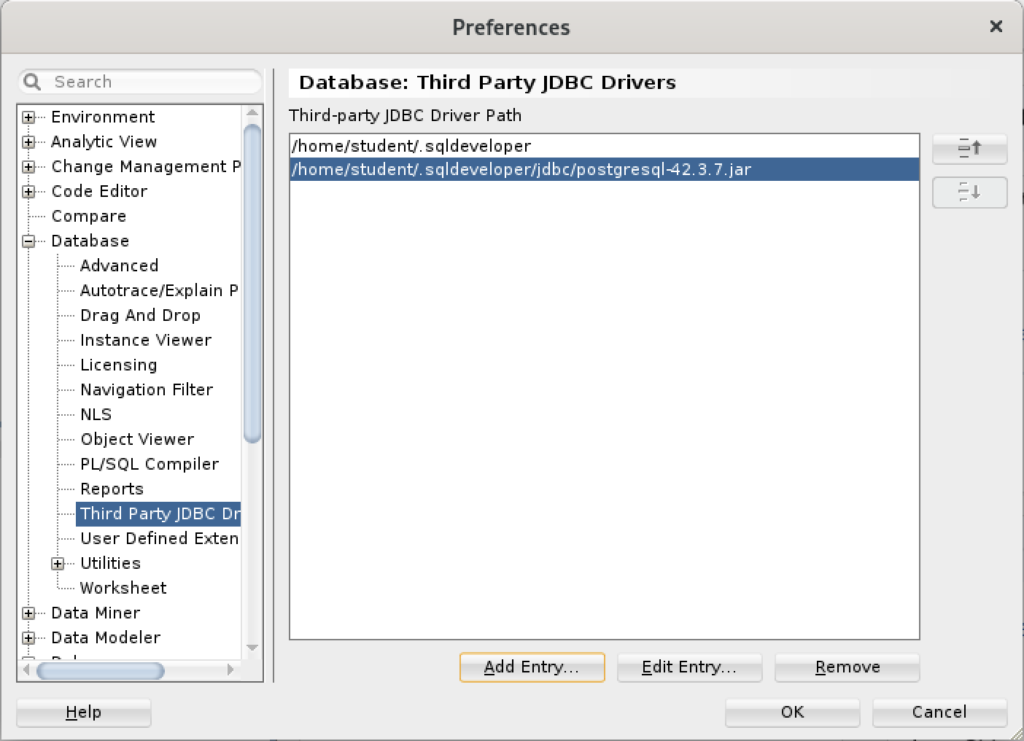
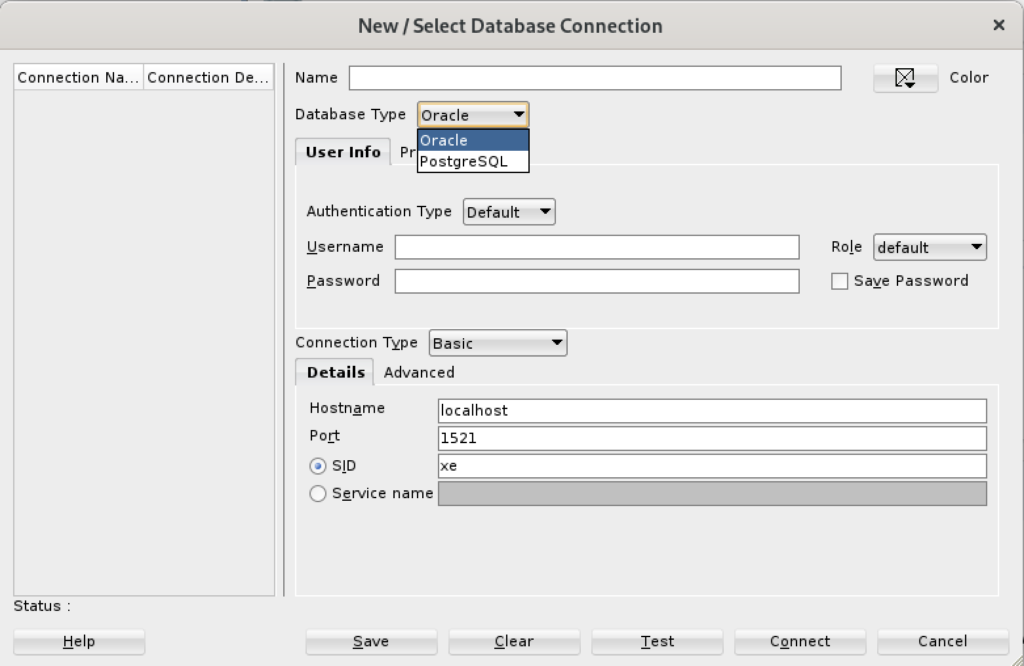
After completing the 3rd Party Java Driver setup, you attempt to create a new connection to the PostgreSQL database. You should see that you now have two available Database Type values: Oracle and PostgreSQL, as shown below:
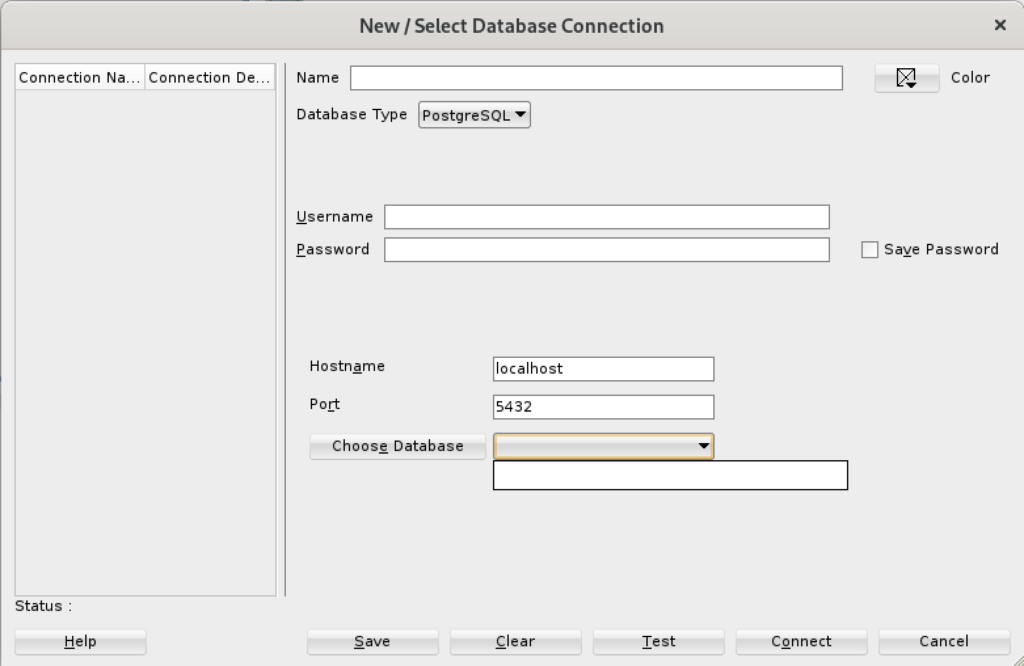
When you click on the PostgreSQL Database Type, the dialog updates to the following view. Unfortunately, I couldn’t discover how to set the values in the list for the Choose Database drop down. Naturally, a sandboxed user can’t connect to the PostgreSQL database without qualifying the database name.
Unless you qualify the PostgreSQL database or connect as the postgres user with a privileged password, SQL Developer translates the absence of a database selection to a database name equivalent to the user’s name. That’s the default behavior for the Oracle database but differs from the behavior for MySQL, PostgreSQL, and Microsoft SQL Server. It returns the following
Status: Failure - Test failed: FATAL: database "student" does not exist |
As seen in the diaglog’s result when testing the connection:
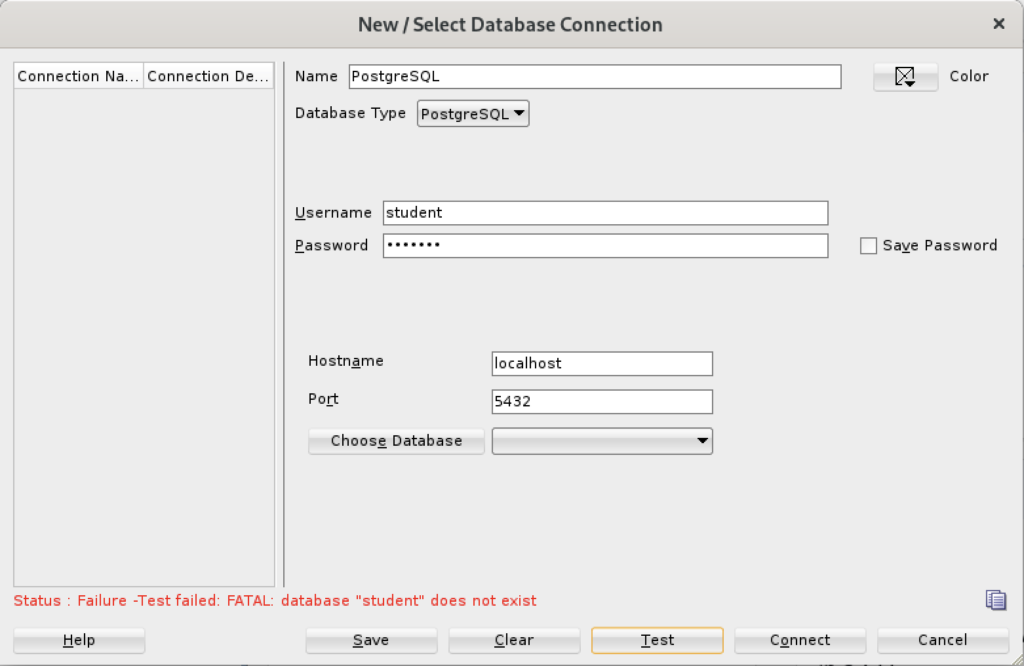
Based on my hunch and not knowing how to populate the database field for the connection, I did the following:
- Created a Linux OS videodb user.
- Copied the .bashrc file with all the standard Oracle environment variables.
- Created the /home/videodb/.sqldeveloper/jdbc directory.
- Copied the postgresql-42.3.7.jar into the new jdbc directory.
- Connected as the postgres super user and created the PostgreSQL videodb user with this syntax:
CREATE USER videodb WITH ROLE dba ENCRYPTED PASSWORD 'cangetin';
- As the postgres super user, granted the following privileges:
-- Grant privileges on videodb database videodb user. GRANT ALL ON DATABASE "videodb" TO "videodb"; -- Connect to the videodb database. \c -- Grant privileges. GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO videodb; GRANT ALL PRIVILEGES ON ALL SEQUENCES IN SCHEMA public TO videodb;
- Added the following line to the pg_hba.conf file in the /var/lib/pgsql/15/data directory as the postgres user:
local all videodb peer - Connected as the switched from the student to videodb Linux user, and launched SQL Developer. Then, I used the Tools menu to create the 3rd party PostgreSQL JDBC Java ARchive (.jar) file in context of the SQL Developer program. Everything completed correctly.
- Created a new PostgreSQL connection in SQL Developer and tested it with success as shown:
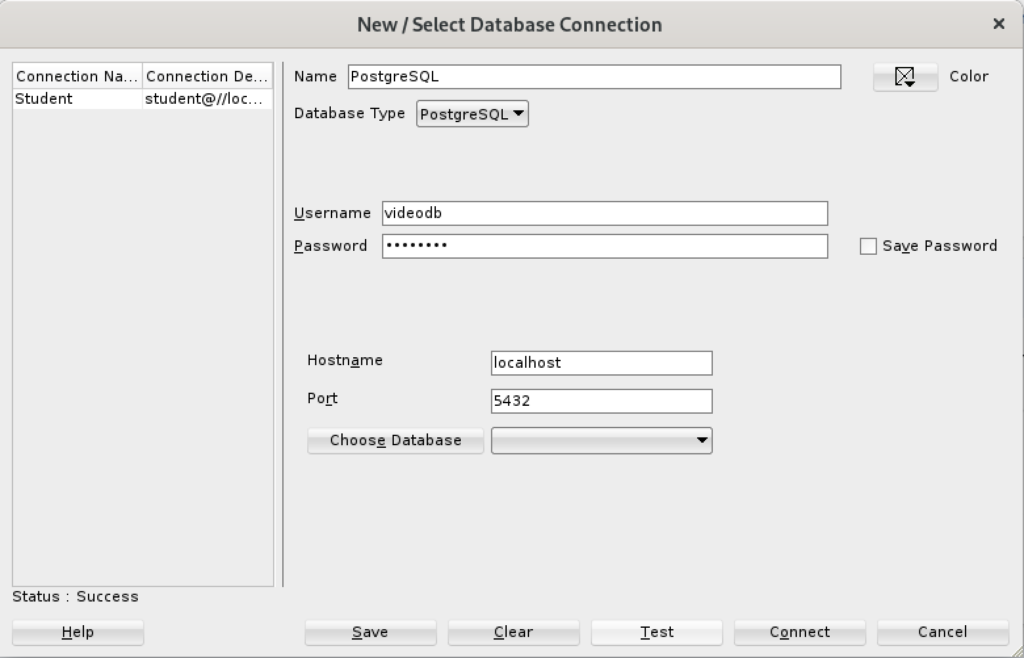
- Saving the new PostgreSQL connection, I opened the connection and could run SQL statements and display the catalog information, as shown:
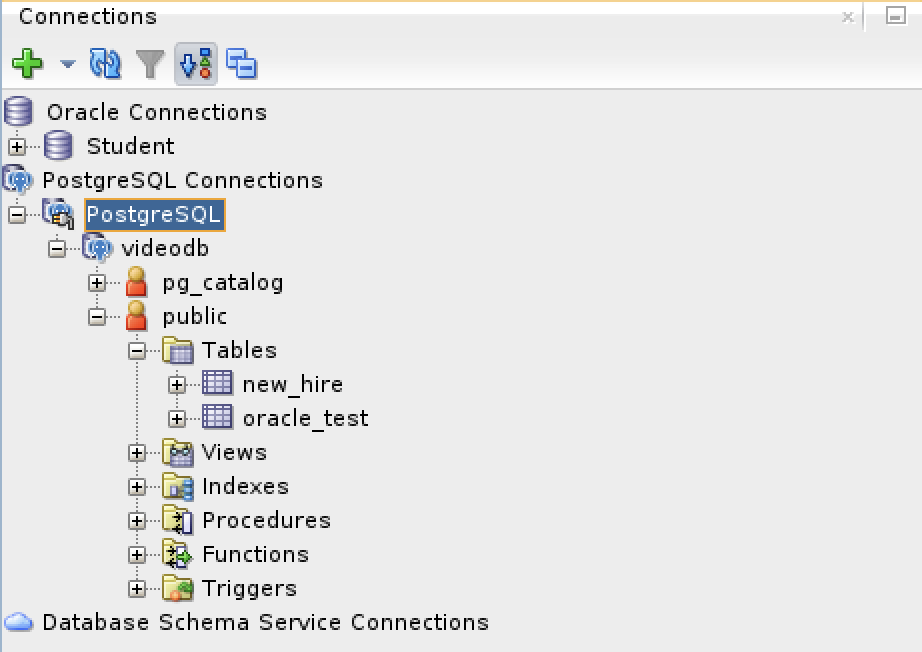
Connected as the videodb user to the videodb database I can display tables owned by student and videodb users:
-- List tables. \d List of relations Schema | Name | Type | Owner --------+--------------------------+----------+--------- public | new_hire | table | student public | new_hire_new_hire_id_seq | sequence | student public | oracle_test | table | videodb (3 rows)
In SQL Developer, you can also inspect the tables, as shown:

At this point, I’m working on trying to figure out how to populate the database drop-down table. However, I’ve either missed a key document or it’s unfortunate that SQL Developer isn’t as friendly as MySQL Workbench in working with 3rd Party drivers.
AWS EC2 TNS Listener
Having configured an AlmaLinux 8.6 with Oracle Database 11g XE, MySQL 8.0.30, and PostgreSQL 15, we migrated it to AWS EC2 and provisioned it. We used the older and de-supported Oracle Database 11g XE because it didn’t require any kernel modifications and had a much smaller footprint.
I had to address why attempting to connect with the sqlplus utility raised the following error after provisioning a copy with a new static IP address:
ERROR: ORA-12514: TNS:listener does NOT currently know OF service requested IN CONNECT descriptor |
A connection from SQL Developer raises a more addressable error, like:
ORA-17069 |
I immediately tried to check the connection with the tnsping utility and found that tnsping worked fine. However, when I tried to connect with the sqlplus utility it raised an ORA-12514 connection error.
There were no diagnostic steps beyond checking the tnsping utility. So, I had to experiment with what might block communication.
I changed the host name from ip-172-58-65-82.us-west-2.compute.internal to a localhost string in both the listener.ora and tnsnames.ora. The listener.ora file:
# listener.ora Network Configuration FILE: SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME = PLSExtProc) (ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe) (PROGRAM = extproc) ) ) LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) (ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)) ) ) DEFAULT_SERVICE_LISTENER = (XE) |
The tnsnames.ora file:
# tnsnames.ora Network Configuration FILE: XE = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = XE) ) ) EXTPROC_CONNECTION_DATA = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) ) (CONNECT_DATA = (SID = PLSExtProc) (PRESENTATION = RO) ) ) |
I suspected that it might be related to the localhost value. So, I checked the /etc/hostname and /etc/hosts files.
Then, I modified /etc/hostname file by removing the AWS EC2 damain address. I did it on a memory that Oracle’s TNS raises errors for dots or periods in some addresses.
The /etc/hostname file:
ip-172-58-65-82 |
The /etc/hosts file:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ip-172-58-65-82 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 ip-172-58-65-82 |
Now, we can connect to the Oracle Database 11g XE instance with the sqlplus utility. I believe this type of solution will work for other AWS EC2 provisioned Oracle databases.
INSERT Statement
INSERT Statement
Learning Outcomes
- Learn how to use positional- and named-notation in INSERT statements.
- Learn how to use the VALUES clause in INSERT statements.
- Learn how to use subqueries in INSERT statements.
The INSERT statement lets you enter data into tables and views in two ways: via an INSERT statement with a VALUES clause and via an INSERT statement with a query. The VALUES clause takes a list of literal values (strings, numbers, and dates represented as strings), expression values (return values from functions), or variable values.
Query values are results from SELECT statements that are subqueries (covered earlier in this appendix). INSERT statements work with scalar, single-row, and multiple-row subqueries. The list of columns in the VALUES clause or SELECT clause of a query (a SELECT list) must map to the positional list of columns that defines the table. That list is found in the data dictionary or catalog. Alternatively to the list of columns from the data catalog, you can provide a named list of those columns. The named list overrides the positional (or default) order from the data catalog and must provide at least all mandatory columns in the table definition. Mandatory columns are those that are not null constrained.
Oracle databases differ from other databases in how they implement the INSERT statement. Oracle doesn’t support multiple-row inserts with a VALUES clause. Oracle does support default and override signatures as qualified in the ANSI SQL standards. Oracle also provides a multiple- table INSERT statement. This section covers how you enter data with an INSERT statement that is based on a VALUES clause or a subquery result statement. It also covers multiple-table INSERT statements.
The INSERT statement has one significant limitation: its default signature. The default signature is the list of columns that defines the table in the data catalog. The list is defined by the position and data type of columns. The CREATE statement defines the initial default signature, and the ALTER statement can change the number, data types, or ordering of columns in the default signature.
The default prototype for an INSERT statement allows for an optional column list that overrides the default list of columns. When you provide the column list you choose to implement named-notation, which is the right way to do it. Relying on the insertion order of the columns is a bad idea. An INSERT statement without a list of column names is a position-notation statement. Position-notation is bad because somebody can alter that order and previously written INSERT statements will break or put data in the wrong columns.
Like methods in OOPLs, an INSERT statement without the optional column list constructs an instance (or row) of the table using the default constructor. The override constructor for a row is defined by any INSERT statement when you provide an optional column list. That’s because it overrides the default constructor.
The generic prototype for an INSERT statement is confusing when it tries to capture both the VALUES clause and the result set from a query. Therefore, I’ve opted to provide two generic prototypes.
Insert by value
The first uses the VALUES clause:
INSERT INTO table_name [( column1, column2, column3, ...)] VALUES ( value1, value2, value3, ...); |
Notice that the prototype for an INSERT statement with the result set from a query doesn’t use the VALUES clause at all. A parsing error occurs when the VALUES clause and query both occur in an INSERT statement.
The second prototype uses a query and excludes the VALUES clause. The subquery may return one to many rows of data. The operative rule is that all columns in the query return the same number of rows of data, because query results should be rectangles—rectangles made up of one to many rows of columns.
Insert by subquery
Here’s the prototype for an INSERT statement that uses a subquery:
INSERT INTO table_name [( column1, column2, column3, ...)] ( SELECT value1, value2, value3, ... FROM table_name WHERE ...); |
A query, or SELECT statement, returns a SELECT list. The SELECT list is the list of columns, and it’s evaluated by position and data type. The SELECT list must match the definition of the table or the override signature provided.
Default signatures present a risk of data corruption through insertion anomalies, which occur when you enter bad data in tables. Mistakes transposing or misplacing values can occur more frequently with a default signature, because the underlying table structure can change. As a best practice, always use named notation by providing the optional list of values; this should help you avoid putting the right data in the wrong place.
The following subsections provide examples that use the default and override syntax for INSERT statements in Oracle databases. The subsections also cover multiple-table INSERT statements and a RETURNING INTO clause, which is an extension of the ANSI SQL standard. Oracle uses the RETURNING INTO clause to manage large objects, to return autogenerated identity column values, and to support some of the features of Oracle’s dynamic SQL. Note that Oracle also supports a bulk INSERT statement, which requires knowledge of PL/SQL.
Insert by Values →
An INSERT statement with a VALUES clause can only insert one row at a time in and Oracle database. Other databases, like Microsoft SQL Server and MySQL allow you to insert a comma delimited set of values inside the VALUES clause. Oracle adheres to the ANSI standard that support single row inserts with a VALUES clause and multiple row inserts with a subquery.
Inserting by the VALUES clause is the most common type of INSERT statement. It’s most useful when interacting with single-row inserts.
You typically use this type of INSERT statement when working with data entered through end-user web forms. In some cases, users can enter more than one row of data using a form, which occurs, for example, when a user places a meal order in a restaurant and the meal and drink are treated as order items. The restaurant order entry system would enter a single-row in the order table and two rows in the order_item table (one for the meal and the other for the drink). PL/SQL programmers usually handle the insertion of related rows typically inside a loop structure when they use dynamic INSERT statements. Dynamic inserts are typically performed using NDS (Native Dynamic SQL) statements.
Oracle supports only a single-row insert through the VALUES clause. Multiple-row inserts require an INSERT statement from a query.
The VALUES clause of an INSERT statement accepts scalar values, such as strings, numbers, and dates. It also accepts calls to arrays, lists, or user-defined object types, which are called flattened objects. Oracle supports VARRAY as arrays and nested tables as lists. They can both contain elements of a scalar data type or user-defined object type.
The following sections discuss how you use the VALUES clause with scalar data types, how you convert various data types, and how you use the VALUES clause with nested tables and user-defined object data types.
Inserting Scalar Data Types
Instruction Details →
This section shows you how to INSERT scalar values into tables.
The basic syntax for an INSERT statement with a VALUES clause can include an optional override signature between the table name and VALUES keyword. With an override signature, you designate the column names and the order of entry for the VALUES clause elements. Without an override signature, the INSERT signature checks the definition of the table in the database catalog. The positional order of the column in the data catalog defines the positional, or default, signature for the INSERT statement. As shown previously, you can discover the structure of a table in Oracle with the DESCRIBE command issued at the SQL*Plus command line:
DESCRIBE table_name |
You’ll see the following after describing the rental table in SQL*Plus:
Name Null? Type ------------------------------------ -------- -------- RENTAL_ID NOT NULL NUMBER CUSTOMER_ID NOT NULL NUMBER CHECK_OUT_DATE NOT NULL DATE RETURN_DATE DATE CREATED_BY NOT NULL NUMBER CREATION_DATE NOT NULL DATE LAST_UPDATED_BY NOT NULL NUMBER LAST_UPDATE_DATE NOT NULL DATE |
The rental_id column is a surrogate key, or an artificial numbering sequence. The combination of the customer_id and check_out_date columns serves as a natural key because a DATE data type is a date-time value. If it were only a date, the customer would be limited to a single entry for each day, and limiting customer rentals to one per day isn’t a good business model.
The basic INSERT statement would require that you look up the next sequence value before using it. You should also look up the surrogate key column value that maps to the row where your unique customer is stored in the contact table. For this example, assume the following facts:
- Next sequence value is 1086
- Customer’s surrogate key value is 1009
- Current date-time is represented by the value from the SYSDATE function
- Return date is the fifth date from today
- User adding and updating the row has a primary (surrogate) key value of 1
- Creation and last update date are the value returned from the SYSDATE function.
An INSERT statement must include a list of values that match the positional data types of the database catalog, or it must use an override signature for all mandatory columns.
You can now write the following INSERT statement, which relies on the default signature:
Name Null? Type ------------------------------------ -------- -------- RENTAL_ID NOT NULL NUMBER CUSTOMER_ID NOT NULL NUMBER CHECK_OUT_DATE NOT NULL DATE RETURN_DATE DATE CREATED_BY NOT NULL NUMBER CREATION_DATE NOT NULL DATE LAST_UPDATED_BY NOT NULL NUMBER LAST_UPDATE_DATE NOT NULL DATE |
The rental_id column is a surrogate key, or an artificial numbering sequence. The combination of the customer_id and check_out_date columns serves as a natural key because a DATE data type is a date-time value. If it were only a date, the customer would be limited to a single entry for each day, and limiting customer rentals to one per day isn’t a good business model.
The basic INSERT statement would require that you look up the next sequence value before using it. You should also look up the surrogate key column value that maps to the row where your unique customer is stored in the contact table. For this example, assume the following facts:
- Next sequence value is 1086
- Customer’s surrogate key value is 1009
- Current date-time is represented by the value from the SYSDATE function
- Return date is the fifth date from today
- User adding and updating the row has a primary (surrogate) key value of 1
- Creation and last update date are the value returned from the SYSDATE function.
An INSERT statement must include a list of values that match the positional data types of the database catalog, or it must use an override signature for all mandatory columns.
You can now write the following INSERT statement, which relies on the default signature:
SQL> INSERT INTO rental 2 VALUES 3 ( 1086 4 , 1009 5 , SYSDATE 6 , TRUNC(SYSDATE + 5) 7 ,1 8 , SYSDATE 9 , 1 10 , SYSDATE); |
If you weren’t using SYSDATE for the date-time value on line 5, you could manually enter a date-time with the following Oracle proprietary syntax:
5 , TO_DATE('15-APR-2011 12:53:01','DD-MON-YYYY HH24:MI:SS') |
The TO_DATE function is an Oracle-specific function. The generic conversion function would be the CAST function. The problem with a CAST function by itself is that it can’t handle a format mask other than the database defaults (‘DD-MON-RR‘ or ‘DD-MON-YYYY‘). For example, consider this syntax:
5 , CAST('15-APR-2011 12:53:02' AS DATE) |
It raises the following error:
5 , CAST('15-APR-2011 12:53:02' AS DATE) FROM dual * ERROR AT line 1: ORA-01830: DATE format picture ends before converting entire input string |
You actually need to double cast this type of format mask when you want to store it as a DATE data type. The working syntax casts the date-time string as a TIMESTAMP data type before recasting the TIMESTAMP to a DATE, like
5 , CAST(CAST('15-APR-2011 12:53:02' AS TIMESTAMP) AS DATE) |
Before you could write the preceding INSERT statement, you would need to run some queries to find the values. You would secure the next value from a rental_s1 sequence in an Oracle database with the following command:
SQL> SELECT rental_s1.NEXTVAL FROM dual; |
This assumes two things, because sequences are separate objects from tables. First, code from which the values in a table’s surrogate key column come must appear in the correct sequence. Second, a sequence value is inserted only once into a table as a primary key value.
In place of a query that finds the next sequence value, you would simply use a call against the .nextval pseudocolumn in the VALUES clause. You would replace line 3 with this:
3 ( rental_s1.NEXTVAL |
The .nextval is a pseudocolumn, and it instantiates an instance of a sequence in the current session. After a call to a sequence with the .nextval pseudocolumn, you can also call back the prior sequence value with the .currval pseudocolumn.
Assuming the following query would return a single-row, you can use the contact_id value as the customer_id value in the rental table:
SQL> SELECT contact_id 2 FROM contact 3 WHERE last_name = 'Potter' 4 AND first_name = 'Harry'; |
Taking three steps like this is unnecessary, however, because you can call the next sequence value and find the valid customer_id value inside the VALUES clause of the INSERT statement. The following INSERT statement uses an override signature and calls for the next sequence value on line 11. It also uses a scalar subquery to look up the correct customer_id value with a scalar subquery on lines 12 through 15.
SQL> INSERT INTO rental 2 ( rental_id 3 , customer_id 4 , check_out_date 5 , return_date 6 , created_by 7 , creation_date 8 , last_updated_by 9 , last_update_date ) 10 VALUES 11 ( rental_s1.NEXTVAL 12 ,(SELECT contact_id 13 FROM contact 14 WHERE last_name = 'Potter' 15 AND first_name = 'Harry') 16 , SYSDATE 17 , TRUNC(SYSDATE + 5) 18 , 1 19 , SYSDATE 20 , 3 21 , SYSDATE); |
When a subquery returns two or more rows because the conditions in the WHERE clause failed to find and return a unique row, the INSERT statement would fail with the following message:
,(SELECT contact_id * ERROR AT line 3: ORA-01427: single-ROW subquery returns more than one ROW |
In fact, the statement could fail when there are two or more “Harry Potter” names in the data set because three columns make up the natural key of the contact table. The third column is the member_id, and all three should be qualified inside a scalar subquery to guarantee that it returns only one row of data.
Handling Oracle’s Large Objects
Instruction Details →
This section shows you how to INSERT large object values into tables.
Oracle’s large objects present a small problem when they’re not null constrained in the table definition. You must insert empty object containers or references when you perform an INSERT statement.
Assume, for example, that you have the following three large object columns in a table:
Name Null? Type ------------------------------- -------- ----------------------- ITEM_DESC NOT NULL CLOB ITEM_ICON NOT NULL BLOB ITEM_PHOTO BINARY FILE LOB |
The item_desc column uses a CLOB (Character Large Object) data type, and it is a required column; it could hold a lengthy description of a movie, for example. The item_icon column uses a BLOB (Binary Large Object) data type, and it is also a required column. It could hold a graphic image. The item_photo column uses a binary file (an externally managed file) but is fortunately null allowed or an optional column in any INSERT statement. It can hold a null or a reference to an external graphic image.
Oracle provides two functions that let you enter an empty large object, and they are:
EMPTY_BLOB() EMPTY_CLOB() |
Although you could insert a null value in the item_photo column, you can also enter a reference to an Oracle database virtual directory file. Here’s the syntax to enter a valid BFILE name with the BFILENAME function call:
10 , BFILENAME('VIRTUAL_DIRECTORY_NAME', 'file_name.png') |
You can insert a large character or binary stream into BLOB and CLOB data types by using the stored procedures and functions available in the dbms_lob package. Chapter 13 covers the dbms_lob package.
You can use an empty_clob function or a string literal up to 32,767 bytes long in a VALUES clause. You must use the dbms_lob package when you insert a string that is longer than 32,767 bytes. That also changes the nature of the INSERT statement and requires that you append the RETURNING INTO clause. Here’s the prototype for this Oracle proprietary syntax:
INSERT INTO some_table [( column1, column2, column3, ...)] VALUES ( value1, value2, value3, ...) RETURNING column1 INTO local_variable; |
The local_variable is a reference to a procedural programming language. It lets you insert a character stream into a target CLOB column or insert a binary stream into a BLOB column.
Capturing the Last Sequence Value
Instruction Details →
This section shows you how to INSERT a new sequence in a parent table and a copy of that new sequence as a foreign key value in a child table.
Sometimes you insert into a series of tables in the scope of a transaction. In this scenario, one table gets the new sequence value (with a call to sequence_name.nextval) and enters it as the surrogate primary key, and another table needs a copy of that primary key to enter into a foreign key column. While scalar subqueries can solve this problem, Oracle provides the .currval pseudocolumn for this purpose.
The steps to demonstrate this behavior require a parent table and a child table. The parent table is defined as follows:
Name Null? Type ------------------------------------ -------- -------------- PARENT_ID NOT NULL NUMBER PARENT_NAME VARCHAR2(10) |
The parent_id column is the primary key for the parent table. You include the parent_id column in the child table. In the child table, the parent_id column holds a copy of a valid primary key column value as a foreign key to the parent table.
Name Null? Type ------------------------------------ -------- -------------- CHILD_ID NOT NULL NUMBER PARENT_ID NUMBER PARENT_NAME VARCHAR2(10) |
After creating the two tables, you can manage inserts into them with the .nextval and .currval pseudocolumns. The sequence calls with the .nextval pseudocolumn insert primary key values, and the sequence calls with the .currval pseudocolumn insert foreign key values.
You would perform these two INSERT statements as a group:
SQL> INSERT INTO parent 2 VALUES 3 ( parent_s1.NEXTVAL 4 ,'One Parent'); SQL> INSERT INTO child 2 VALUES 3 ( child_s1.NEXTVAL 4 , parent_s1.CURRVAL 5 ,'One Child'); |
The .currval pseudocolumn for any sequence fetches the value placed in memory by call to the .nextval pseudocolumn. Any attempt to call the .currval pseudocolumn before the .nextval pseudocolumn raises an ORA-02289 exception. The text message for that error says the sequence doesn’t exist, which actually means that it doesn’t exist in the scope of the current session. Line 4 in the insert into the child table depends on line 3 in the insert into the parent table.
You can use comments in INSERT statements to map to columns in the table. For example, the following shows the technique for the child table from the preceding example:
SQL> INSERT INTO child 2 VALUES 3 ( child_s1.NEXTVAL -- CHILD_ID 4 , parent_s1.CURRVAL -- PARENT_ID 5 ,'One Child') -- CHILD_NAME 6 / |
Comments on the lines of the VALUES clause identify the columns where the values are inserted. A semicolon doesn’t execute this statement, because a trailing comment would trigger a runtime exception. You must use the semicolon or forward slash on the line below the last VALUES element to include the last comment.
Insert by Subquery Results →
An INSERT statement with a subquery can insert one to many rows of data into any table provided the SELECT-list of the subquery matches the data dictionary definition of the table or the named-notation list provided by the INSERT statement. An INSERT statement with a subquery cannot have a VALUES keyword in it, or it raises an error.
The generic prototype for an INSERT statement follows the pattern of an INSERT statement by value prototype with one exception, it excludes the VALUES keyword and replaces the common delimited list of values with a SELECT-list from a subquery. If you want to rely on the positional definition of the table, exclude the list of comma delimited column values. The optional comma-delimited list of column values is necessary when you want to insert columns in a different order or exclude optional columns.
The generic prototype is:
INSERT INTO table_name [( column1, column2, column3, ...)] ( SELECT value1, value2, value3, ... FROM table_name WHERE ...); |
The subquery, or SELECT statement, must return a SELECT-list that maps to the column definition in the data dictionary or the optional comma-delimited column list.
Tiny SQL Developer
The first time you launch SQL Developer, you may see a very small or tiny display on the screen. With some high resolution screens the text is unreadable. Unless you manually configure the sqldeveloper shortcut, you generally can’t use it.
On my virtualization on a 27″ screen it looks like:

As an Administrator user, you right click the SQLDeveloper icon and click the Compatibility tab, which should look like the following dialog. You need to check the Compatibility Mode, which by default is unchecked with Windows 8 displayed in the select list.

Check the Compatibility Mode box and the select list will no longer be gray scaled. Click on the select list box and choose Windows 7. After the change you should see the following:

After that change, you need to click on the Change high DPI settings gray scaled button, which will display the following dialog box.

Click the Override high DPI scaling behavior check box. It will change the gray highlighted Scaling Performed by select box to white. Then, you click the Scaling Performed by select box and choose the System option.

Click the OK button on the nested SQLDeveloper Properties dialog box. Then, click the Apply button on the SQLDeveloper Properties button and the OK button. You will see a workable SQL Developer interface when you launch the program through your modified shortcut.
SQL Developer JDK
In my classes, we use a VMware Linux install with SQL Developer. One of my students called me in a panic after an upgrade of packages when SQL Developer failed to launch. The student was astute enough to try running it from the command line where it generates an error like:
Oracle SQL Developer Copyright (c) 2005, 2018, Oracle and/or its affiliates. All rights reserved. /opt/sqldeveloper/sqldeveloper/bin/../../ide/bin/launcher.sh: line 954: [: : integer expression expected The JDK (/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.fc30.x86_64/) is not a valid JDK. The JDK was specified by a SetJavaHome directive in a .conf file or by a --setjavahome option. Type the full pathname of a JDK installation (or Ctrl-C to quit), the path will be stored in /home/student/.sqldeveloper/19.2.0/product.conf Error: Unable to get APP_JAVA_HOME input from stdin after 10 tries |
The error is simple, the SQL Developer package update wipe clean the configuration of the SetJavaHome variable in the user’s ~/.sqldeveloper/19.2.0/product.conf file. The fix is three steps because its very likely that the Java packages were also updated. Here’s how to fix it:
- Navigate to the directory where you’ve installed the Java Virtual Machine (JVM) and find the current version of the JVM installed:
cd /usr/lib/jvm ls java*
It will return a set of files, like:
java java-1.8.0 java-1.8.0-openjdk java-1.8.0-openjdk-1.8.0.252.b09-0.fc30.x86_64 java-openjdk jre jre-1.8.0 jre-1.8.0-openjdk jre-1.8.0-openjdk-1.8.0.252.b09-0.fc30.x86_64 jre-openjdk
- Navigate to your user’s product configuration file with this command:
cd ~/.sqldeveloper/19.2.0
- Add the following line to the
product.conffile:# SetJavaHome /path/jdk SetJavaHome /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-0.fc30.x86_64/
Now, you should be able to run it from the command line. The shortcut icon should also work if one was installed. Also, don’t forget to update your $JAVA_HOME variable in the master Bash resource file, or your local user’s .bashrc files.
As always, I hope this helps those looking for a quick solution.
SQL Developer Error
It’s been a couple releases trying to fix the following error thrown by SQL Developer on Fedora 30 and shown as the following dialog:

When you click the Detail button it shows the following error stack:
java.lang.NoClassDefFoundError: javafx/embed/swing/JFXPanel at oracle.dbtools.raptor.javafx.ui.JFXPanelFactory.createJFXPanelImpl(JFXPanelFactory.java:58) at oracle.dbtools.raptor.javafx.ui.JFXPanelFactory.createJFXPanel(JFXPanelFactory.java:34) at oracle.dbtools.raptor.startpage.StartPageViewer.createGUIComponent(StartPageViewer.java:179) at oracle.dbtools.raptor.startpage.StartPageViewer.getEditorContent(StartPageViewer.java:136) at oracle.ide.editor.AsynchronousEditor$2.run(AsynchronousEditor.java:345) at oracle.ide.editor.AsynchronousEditor$5.run(AsynchronousEditor.java:555) at org.openide.util.RequestProcessor$Task.run(RequestProcessor.java:1443) at org.netbeans.modules.openide.util.GlobalLookup.execute(GlobalLookup.java:68) at org.openide.util.lookup.Lookups.executeWith(Lookups.java:303) at org.openide.util.RequestProcessor$Processor.run(RequestProcessor.java:2058) Caused by: java.lang.ClassNotFoundException: javafx.embed.swing.JFXPanel cannot be found by oracle.sqldeveloper_19.2.0 at org.eclipse.osgi.internal.loader.BundleLoader.findClassInternal(BundleLoader.java:501) at org.eclipse.osgi.internal.loader.BundleLoader.findClass(BundleLoader.java:421) at org.eclipse.osgi.internal.loader.BundleLoader.findClass(BundleLoader.java:412) at org.eclipse.osgi.internal.baseadaptor.DefaultClassLoader.loadClass(DefaultClassLoader.java:107) at org.netbeans.modules.netbinox.NetbinoxLoader.loadClass(NetbinoxLoader.java:81) at java.lang.ClassLoader.loadClass(ClassLoader.java:352) ... 10 more |
I thought applying the Open Java FX package might fix the problem. I installed the package like the following:
yum install -y openjfx |
The installation log:
Last metadata expiration check: 4:03:29 ago on Tue 21 Apr 2020 06:42:26 PM MDT. Dependencies resolved. ============================================================================================= Package Architecture Version Repository Size ============================================================================================= Installing: openjfx x86_64 8.0.202-8.b07.fc30 updates 8.8 M Transaction Summary ============================================================================================= Install 1 Package Total download size: 8.8 M Installed size: 11 M Downloading Packages: openjfx-8.0.202-8.b07.fc30.x86_64.rpm 2.5 MB/s | 8.8 MB 00:03 --------------------------------------------------------------------------------------------- Total 2.1 MB/s | 8.8 MB 00:04 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Installing : openjfx-8.0.202-8.b07.fc30.x86_64 1/1 Running scriptlet: openjfx-8.0.202-8.b07.fc30.x86_64 1/1 Verifying : openjfx-8.0.202-8.b07.fc30.x86_64 1/1 Installed: openjfx-8.0.202-8.b07.fc30.x86_64 Complete! |
After installing the software, I determined the new JAR files. Then, I added them to my $CLASSPATH environment variable, like:
export CLASSPATH=/usr/share/java/mysql-connector-java.jar:/usr/lib/jvm/openjfx/rt/lib/ext/fxrt.jar:/usr/lib/jvm/openjfx/rt/lib/jfxswt.jar:. |
While it appears to load faster with these JAR files, it still raises the same Dialog error. I simply have to continue to look for a complete fix.
Fedora SQL*Developer
After you download SQL Developer 18 on Fedora 27, you can install it with the yum utility, like
yum install -y sqldeveloper-18.2.0.183.1748-1.noarch.rpm |
The installation should generate the following log file:
Last metadata expiration check: 2:26:23 ago on Sat 25 Aug 2018 07:10:16 PM MDT. Dependencies resolved. ================================================================================================ Package Arch Version Repository Size ================================================================================================ Installing: sqldeveloper noarch 18.2.0.183.1748-1 @commandline 338 M Transaction Summary ================================================================================================ Install 1 Package Total size: 338 M Installed size: 420 M Downloading Packages: Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Installing : sqldeveloper-18.2.0.183.1748-1.noarch 1/1 Running scriptlet: sqldeveloper-18.2.0.183.1748-1.noarch 1/1 Verifying : sqldeveloper-18.2.0.183.1748-1.noarch 1/1 Installed: sqldeveloper.noarch 18.2.0.183.1748-1 Complete! |
After you install SQL Developer, you won’t be able to launch it. Attempts to launch it won’t raise an error message either. The problem is that there is a post-installation step, which requires you to configure the product.conf file.
You can see the error by navigating to the /opt/sqldeveloper directory. You will find the sqldeveloper.sh file in that directory. You will see the error when you run the command as the root user from the command-line interface (CLI), as follows:
/opt/sqldeveloper/sqldeveloper.sh |
Oracle SQL Developer Copyright (c) 2005, 2018, Oracle and/or its affiliates. All rights reserved. Type the full pathname of a JDK installation (or Ctrl-C to quit), the path will be stored in /root/.sqldeveloper/18.2.0/product.conf |
You can find the Oracle home by searching for the rt.jar file as the root user. You use the following find command syntax from the / topmost directory.
find . -name rt.jar |
On Fedora 27, you should see the following absolute file name:
./usr/lib/jvm/java-1.8.0-openjdk-1.8.0.171-1.b10.fc27.x86_64/jre/lib/rt.jar |
You discard the /jre/lib portion of the directory path and the rt.jar file name to get the Java home’s fully qualified path. This should update the product.conf file but if you have to change it manually you should edit the following file:
/root/.sqldeveloper/18.2.0/product.conf |
You need to configure the SetJavaHome parameter value in the product.conf file. The SetJavaHome parameter needs to point to the Java home directory on your Fedora instance. It should look like this:
# # By default, the product launcher will search for a JDK to use, and if none # can be found, it will ask for the location of a JDK and store its location # in this file. If a particular JDK should be used instead, uncomment the # line below and set the path to your preferred JDK. # SetJavaHome /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.171-1.b10.fc27.x86_64 |
It’s possible that an attempt to launch SQL Developer by another user may have copied the product.conf file into a local directory. You should change those manually by editing their respective product.conf files. Assuming you attempted to launch SQL Developer by a student user before you changed the root user’s copy of the SQL Developer’s product.conf file.
