Archive for the ‘Database’ Category
Troubleshoot Oracle Errors
It’s always a bit difficult to trap errors in SQL*Developer when you’re running scripts that do multiple things. As old as it is, using the SQL*Plus utility and spooling to log files is generally the fastest way to localize errors across multiple elements of scripts. Unfortunately, you must break up you components into local components, like a when you create a type, procedure, function, or package.
This is part of my solution to leverage in-depth testing of the Oracle Database 23ai Free container from an Ubuntu native platform. You can find this prior post shows you how to setup Oracle*Client for Ubuntu and connect to the Oracle Database 23ai Free container.
After you’ve done that, put the following oracle_errors Bash shell function into your testing context, or into your .bashrc file:
# Troubleshooting errors utility function. oracle_errors () { # Oracle Error prefixes qualify groups of error types, like # this subset of error prefixes used in the Bash function. # ============================================================ # JMS - Java Messaging Errors # JZN - JSON Errors # KUP - External Table Access Errors # LGI - File I/O Errors # OCI - Oracle Call Interface Errors # ORA - Oracle Database Errors # PCC - Oracle Precompiler Errors # PLS - Oracle PL/SQL Errors # PLW - Oracle PL/SQL Warnings # SP2 - Oracle SQL*Plus Errors # SQL - SQL Library Errors # TNS - SQL*Net (networking) Errors # ============================================================ # Define a array of Oracle error prefixes. prefixes=("jms" "jzn" "kup" "lgi" "oci" "ora" "pcc" "pls" "plw" "sp2" "sql" "tns") # Prepend the -e for the grep utility to use regular expression pattern matching; and # use the ^before the Oracle error prefixes to avoid returning lines that may # contain the prefix in a comment, like the word lookup contains the prefix kup. for str in ${prefixes[@]}; do patterns+=" -e ^${str}" done # Display output from a SQL*Plus show errors command written to a log file when # a procedure, function, object type, or package body fails to compile. This # prints the warning message followed by the line number displayed. patterns+=" -e ^warning" patterns+=" -e ^[0-9]/[0-9]" # Assign any file filter to the ext variable. ext=${1} # Assign the extension or simply use a wildcard for all files. if [ ! -z ${ext} ]; then ext="*.${ext}" else ext="*" fi # Assign the number of qualifying files to a variable. fileNum=$(ls -l ${ext} 2>/dev/null | grep -v ^l | wc -l) # Evaluate the number of qualifying files and process. if [ ${fileNum} -eq "0" ]; then echo "[0] files exist." elif [ ${fileNum} -eq "1" ]; then fileName=$(ls ${ext}) find `pwd` -type f | grep -in ${ext} ${patterns} | while IFS='\n' read list; do echo "${fileName}:${list}" done else find `pwd` -type f | grep -in ${ext} ${patterns} | while IFS='\n' read list; do echo "${list}" done fi # Clear ${patterns} variable. patterns="" } |
Now, let’s create a debug.txt test file to demonstrate how to use the oracle_errors, like:
ORA-12704: character SET mismatch PLS-00124: name OF EXCEPTION expected FOR FIRST arg IN exception_init PRAGMA SP2-00200: Environment error JMS-00402: Class NOT found JZN-00001: END OF input |
You can navigate to your logging directory and call the oracle_errors function, like:
oracle_errors txt |
It’ll return the following, which is file number, line number, and error code:
debug.txt:1:ORA-12704: character set mismatch debug.txt:2:PLS-00124: name of exception expected for first arg in exception_init pragma debug.txt:3:SP2-00200: Environment error debug.txt:4:JMS-00402: Class not found debug.txt:5:JZN-00001: End of input |
There are other Oracle error prefixes but the ones I’ve selected are the more common errors for Java, JavaScript, PL/SQL, Python, and SQL testing. You can add others if your use cases require them to the prefixes array. Just a note for those new to Bash shell scripting the “${variable_name}” is required for arrays.
For a more complete example, I created the following files for a trivial example of procedure overloading in PL/SQL:
- tables.sql – that creates two tables.
- spec.sql – that creates a package specification.
- body.sql – that implements a package specification.
- test.sql – that implements a test case using the package.
- integration.sql – that calls the the scripts in proper order.
The tables.sql, spec.sql, body.sql, and test.sql use the SQL*Plus spool command to write log files, like:
SPOOL spec.txt
-- Insert code here ...
SPOOL OFF |
The body.sql file includes SQL*Plus list and show errors commands, like:
SPOOL spec.txt
-- Insert code here ...
LIST
SHOW ERRORS
SPOOL OFF |
The integration.sql script calls the tables.sql, spec.sql, body.sql, and test.sql in order. Corrupting the spec.sql file by adding a stray “x” to one of the parameter names causes a cascade of errors. After running the integration.sql file with the introduced error, the Bash oracle_errors function returns:
body.txt:2:Warning: Package Body created with compilation errors. body.txt:148:4/13 PLS-00323: subprogram or cursor 'WARNER_BROTHER' is declared in a test.txt:4:ORA-06550: line 2, column 3: test.txt:5:PLS-00306: wrong number or types of arguments in call to 'WARNER_BROTHER' test.txt:6:ORA-06550: line 2, column 3: |
I hope that helps those learning how to program and perform integration testing in an Oracle Database.
Listener for APEX
Unless dbca lets us build the listener.ora file, we often leave off some component. For example, running listener control program the following status indicates an incorrectly configured listener.ora file.
lsnrctl status |
It returns the following, which displays an endpoint for the XDB Server (I’m using Oracle Database 11g XE because it’s pre-containerized and has a small testing footprint):
LSNRCTL for Linux: Version 11.2.0.2.0 - Production on 24-MAR-2023 00:59:06 Copyright (c) 1991, 2011, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC_FOR_XE))) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 11.2.0.2.0 - Production Start Date 21-MAR-2023 21:17:37 Uptime 2 days 3 hr. 41 min. 29 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Default Service XE Listener Parameter File /u01/app/oracle/product/11.2.0/xe/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/localhost/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC_FOR_XE))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=8080))(Presentation=HTTP)(Session=RAW)) Services Summary... Service "PLSExtProc" has 1 instance(s). Instance "PLSExtProc", status UNKNOWN, has 1 handler(s) for this service... Service "XE" has 1 instance(s). Instance "XE", status READY, has 1 handler(s) for this service... Service "XEXDB" has 1 instance(s). Instance "XE", status READY, has 1 handler(s) for this service... The command completed successfully |
The listener is missing the second SID_LIST_LISTENER value of CLRExtProc value. A complete listener.ora file should be as follows for the Oracle Database XE:
# listener.ora Network Configuration FILE: SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME = PLSExtProc) (ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe) (PROGRAM = extproc) ) (SID_DESC = (SID_NAME = CLRExtProc) (ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe) (PROGRAM = extproc) ) ) LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) (ADDRESS = (PROTOCOL = TCP)(HOST = localhost.localdomain)(PORT = 1521)) ) ) DEFAULT_SERVICE_LISTENER = (XE) |
With this listener.ora file, the Oracle listener control utility will return the following correct status, which hides the XDB Server’s endpoint:
LSNRCTL for Linux: Version 11.2.0.2.0 - Production on 24-MAR-2023 02:38:57 Copyright (c) 1991, 2011, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC_FOR_XE))) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 11.2.0.2.0 - Production Start Date 24-MAR-2023 02:38:15 Uptime 0 days 0 hr. 0 min. 42 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Default Service XE Listener Parameter File /u01/app/oracle/product/11.2.0/xe/network/admin/listener.ora Listener Log File /u01/app/oracle/product/11.2.0/xe/log/diag/tnslsnr/localhost/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC_FOR_XE))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1521))) Services Summary... Service "CLRExtProc" has 1 instance(s). Instance "CLRExtProc", status UNKNOWN, has 1 handler(s) for this service... Service "PLSExtProc" has 1 instance(s). Instance "PLSExtProc", status UNKNOWN, has 1 handler(s) for this service... The command completed successfully |
It seems a number of examples on the web left the SID_LIST_LISTENER value of CLRExtProc value out of the listener.ora file. As always, I hope this helps those looking for a complete solution rather than generic instructions without a concrete example.
AWS EC2 TNS Listener
Having configured an AlmaLinux 8.6 with Oracle Database 11g XE, MySQL 8.0.30, and PostgreSQL 15, we migrated it to AWS EC2 and provisioned it. We used the older and de-supported Oracle Database 11g XE because it didn’t require any kernel modifications and had a much smaller footprint.
I had to address why attempting to connect with the sqlplus utility raised the following error after provisioning a copy with a new static IP address:
ERROR: ORA-12514: TNS:listener does NOT currently know OF service requested IN CONNECT descriptor |
A connection from SQL Developer raises a more addressable error, like:
ORA-17069 |
I immediately tried to check the connection with the tnsping utility and found that tnsping worked fine. However, when I tried to connect with the sqlplus utility it raised an ORA-12514 connection error.
There were no diagnostic steps beyond checking the tnsping utility. So, I had to experiment with what might block communication.
I changed the host name from ip-172-58-65-82.us-west-2.compute.internal to a localhost string in both the listener.ora and tnsnames.ora. The listener.ora file:
# listener.ora Network Configuration FILE: SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME = PLSExtProc) (ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe) (PROGRAM = extproc) ) ) LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) (ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)) ) ) DEFAULT_SERVICE_LISTENER = (XE) |
The tnsnames.ora file:
# tnsnames.ora Network Configuration FILE: XE = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = XE) ) ) EXTPROC_CONNECTION_DATA = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) ) (CONNECT_DATA = (SID = PLSExtProc) (PRESENTATION = RO) ) ) |
I suspected that it might be related to the localhost value. So, I checked the /etc/hostname and /etc/hosts files.
Then, I modified /etc/hostname file by removing the AWS EC2 damain address. I did it on a memory that Oracle’s TNS raises errors for dots or periods in some addresses.
The /etc/hostname file:
ip-172-58-65-82 |
The /etc/hosts file:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ip-172-58-65-82 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 ip-172-58-65-82 |
Now, we can connect to the Oracle Database 11g XE instance with the sqlplus utility. I believe this type of solution will work for other AWS EC2 provisioned Oracle databases.
Data Engineer?

Students often ask me about data engineering. I try to explain some of the aspects, and how the tasks can be organized but I never laid out all the titles. I really like this illustration (click on image for larger size) from the Gartner Group because it does that. You can download the full “What Are the Essential Roles for Data and Analytics” paper here).
An excerpt from Gartner’s paper:
Data Engineer
Data engineering is the practice of making the appropriate data available to various data consumers (including data scientists, data and business analysts, citizen integrators, and line-of-business users). It is a discipline that involves collaboration across business and IT units. This key discipline requires skilled data engineers to support both IT and business teams.
Data engineers are primarily responsible for building, managing and operationalizing data pipelines in support of key D&A use cases. They are also primarily responsible for leading the tedious (and often complex) task of:
- Curating datasets and data pipelines created by nontechnical users (e.g., through self-service data preparation tools), data scientists or even IT resources.
- Operationalizing data delivery for production-level deployments.
I hope the summary is helpful and Gartner’s paper interesting.
Updating SQL_MODE
This is an update for MySQL 8 Stored PSM to add the ONLY_FULL_GROUP_BY mode to the global SQL_MODE variable when it’s not set during a session. Here’s the code:
/* Drop procedure conditionally on whether it exists already. */ DROP PROCEDURE IF EXISTS set_full_group_by; /* Reset delimter to allow semicolons to terminate statements. */ DELIMITER $$ /* Create a procedure to verify and set connection parameter. */ CREATE PROCEDURE set_full_group_by() LANGUAGE SQL NOT DETERMINISTIC SQL SECURITY DEFINER COMMENT 'Set connection parameter when not set.' BEGIN /* Check whether full group by is set in the connection and if unset, set it in the scope of the connection. */ IF EXISTS (SELECT TRUE WHERE NOT REGEXP_LIKE(@@SESSION.SQL_MODE,'ONLY_FULL_GROUP_BY')) THEN SET @@GLOBAL.SQL_MODE := CONCAT(@@SESSION.sql_mode,',ONLY_FULL_GROUP_BY'); END IF; END; $$ /* Reset the default delimiter. */ DELIMITER ; |
You can call the set_full_group_by procedure with the CALL command:
CALL set_full_group_by(); |
You can see the SQL_MODE variable with the following query:
SELECT @@GLOBAL.SQL_MODE; |
It’ll return:
+---------------------------------------------------------------+ | @@GLOBAL.SQL_MODE | +---------------------------------------------------------------+ | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION | +---------------------------------------------------------------+ 1 row in set (0.00 sec) |
As always, I hope this helps those looking to solve this type of problem.
DML Event Management
Data Manipulation Language (DML)
DML statements add data to, change data in, and remove data from tables. This section examines four DML statements—the INSERT, UPDATE, DELETE, and MERGE statements—and builds on concepts of data transactions. The INSERT statement adds new data, the UPDATE statement changes data, the DELETE statement removes data from the database, and the MERGE statement either adds new data or changes existing data.
Any INSERT, UPDATE, MERGE, or DELETE SQL statement that adds, updates, or deletes rows in a table locks rows in a table and hides the information until the change is committed or undone (that is, rolled back). This is the nature of ACID-compliant SQL statements. Locks prevent other sessions from making a change while a current session is working with the data. Locks also restrict other sessions from seeing any changes until they’re made permanent. The database keeps two copies of rows that are undergoing change. One copy of the rows with pending changes is visible to the current session, while the other displays committed changes only.
ACID Compliant Transactions
ACID compliance relies on a two-phase commit (2PC) protocol and ensures that the current session is the only one that can see new inserts, updated column values, and the absence of deleted rows. Other sessions run by the same or different users can’t see the changes until you commit them.
ACID Compliant INSERT Statements
The INSERT statement adds rows to existing tables and uses a 2PC protocol to implement ACID- compliant guarantees. The SQL INSERT statement is a DML statement that adds one or more rows to a table. Oracle supports a VALUES clause when adding a single-row, and support a subquery when adding one to many rows.
The figure below shows a flow chart depicting an INSERT statement. The process of adding one or more rows to a table occurs during the first phase of an INSERT statement. Adding the rows exhibits both atomic and consistent properties. Atomic means all or nothing: it adds one or more rows and succeeds, or it doesn’t add any rows and fails. Consistent means that the addition of rows is guaranteed whether the database engine adds them sequentially or concurrently in threads.
Concurrent behaviors happen when the database parallelizes DML statements. This is similar to the concept of threads as lightweight processes that work under the direction of a single process. The parallel actions of a single SQL statement delegate and manage work sent to separate threads. Oracle supports all ACID properties and implements threaded execution as parallel operations. All tables support parallelization.

After adding the rows to a table, the isolation property prevents any other session from seeing the new rows—that means another session started by the same user or by another user with access to the same table. The atomic, consistent, and isolation properties occur in the first phase of any INSERT statement. The durable property is exclusively part of the second phase of an INSERT statement, and rows become durable when the COMMIT statement ratifies the insertion of the new data.
ACID Compliant UPDATE Statements
An UPDATE statement changes column values in one-to-many rows. With a WHERE clause, you update only rows of interest, but if you forget the WHERE clause, an UPDATE statement would run against all rows in a table. Although you can update any column in a row, it’s generally bad practice to update a primary or foreign key column because you can break referential integrity. You should only update non-key data in tables—that is, the data that doesn’t make a row unique within a table.
Changes to column values are atomic when they work. For scalability reasons, the database implementation of updates to many rows is often concurrent, in threads through parallelization. This process can span multiple process threads and uses a transaction paradigm that coordinates changes across the threads. The entire UPDATE statement fails when any one thread fails.
Similar to the INSERT statement, UPDATE statement changes to column values are also hidden until they are made permanent with the application of the isolation property. The changes are hidden from other sessions, including sessions begun by the same database user.
It’s possible that another session might attempt to lock or change data in a modified but uncommitted row. When this happens, the second DML statement encounters a lock and goes into a wait state until the row becomes available for changes. If you neglected to set a timeout value for the wait state, such as this clause, the FOR UPDATE clause waits until the target rows are unlocked:
WAIT n |
As the figure below shows, actual updates are first-phase commit elements. While an UPDATE statement changes data, it changes only the current session values until it is made permanent by a COMMIT statement. Like the INSERT statement, the atomic, consistent, and isolation properties of an UPDATE statement occur during the first phase of a 2PC process. Changes to column values are atomic when they work. Any column changes are hidden from other sessions until the UPDATE statement is made permanent by a COMMIT or ROLLBACK statement, which is an example of the isolation property.
Any changes to column values can be modified by an ON UPDATE trigger before a COMMIT statement. ON UPDATE triggers run inside the first phase of the 2PC process. A COMMIT or ROLLBACK statement ends the transaction scope of the UPDATE statement.
The Oracle database engine can dispatch changes to many threads when an UPDATE statement works against many rows. UPDATE statements are consistent when these changes work in a single thread-of-control or across multiple threads with the same results.

As with the INSERT statement, the atomic, consistent, and isolation properties occur during the first phase of any UPDATE statement, and the COMMIT statement is the sole activity of the second phase. Column value changes become durable only with the execution of a COMMIT statement.
ACID Compliant DELETE Statements
A DELETE statement removes rows from a table. Like an UPDATE statement, the absence of a WHERE clause in a DELETE statement deletes all rows in a table. Deleted rows remain visible outside of the transaction scope where it has been removed. However, any attempts to UPDATE those deleted rows are held in a pending status until they are committed or rolled back.
You delete rows when they’re no longer useful. Deleting rows can be problematic when rows in another table have a dependency on the deleted rows. Consider, for example, a customer table that contains a list of cell phone contacts and an address table that contains the addresses for some but not all of the contacts. If you delete a row from the customer table that still has related rows in the address table, those address table rows are now orphaned and useless.
As a rule, you delete data from the most dependent table to the least dependent table, which is the opposite of the insertion process. Basically, you delete the child record before you delete the parent record. The parent record holds the primary key value, and the child record holds the foreign key value. You drop the foreign key value, which is a copy of the primary key, before you drop the primary key record. For example, you would insert a row in the customer table before you insert a row in the address table, and you delete rows from the address table before you delete rows in the customer table.
The figure below shows the logic behind a DELETE statement. Like the INSERT and UPDATE statements, acid, consistency, and isolation properties of the ACID-compliant transaction are managed during the first phase of a 2PC. The durability property is managed by the COMMIT or ROLLBACK statement.

There’s no discussion or diagrams for the MERGE statement because it does either an INSERT or UPDATE statement based on it’s internal logic. That means a MERGE statement is ACID compliant like an INSERT or UPDATE statement.
MySQL PNG Files
LAMP (Linux, Apache, MySQL, Perl/PHP/Python) Architecture is very flexible. All the components can be positioned on the same server or different servers. The servers are divided into two types. The types are known as the Application or database tiers. Generally, the application tier holds the Apache Server, any Apache Modules, and local copies of Server Side Includes (SSI) programs.
In many development environments, you also deploy the client to the same machine. This means a single machine runs the database server, the application server, and the browser. The lab for this section assumes these configurations.
Before you test an installation, you should make sure that you’ve started the database and Apache server. In an Oracle LAMP configuration (known as an OLAP – Oracle, Linux, Apache, Perl/PHP/Python), you must start both the Oracle Listener and database. MySQL starts the listener when you start the database. You must also start the Apache Server. The Apache Server also starts an Apache Listener, which listens for incoming HTTP/HTTPS requests. It listens on Port 80 unless you override that setting in the httpd.conf file.

The URI reaches the server and is redirected to an Apache Module based on configuration information found in the httpd.conf file. Spawned or child processes of the Apache Module then read programs into memory from the file system and run them. If you’ve uploaded a file the locally stored program can move it from a secure cache location to another local area for processing. The started programs can run independently or include other files as libraries, and they can communicate to the database server.
Working though PHP test cases against the MySQL database for my AlmaLinux installation and configuration, I discovered that the php-gd library weren’t installed by default. I had to add it to get my PHP programs to upload and display PNG files.
The log file for applying the php-gd packages:
Display detailed console log →
Last metadata expiration check: 3:59:15 ago on Wed 28 Dec 2022 08:17:58 PM EST. Dependencies resolved. ================================================================================ Package Architecture Version Repository Size ================================================================================ Installing: php-gd x86_64 8.0.20-3.el9 appstream 43 k Transaction Summary ================================================================================ Install 1 Package Total download size: 43 k Installed size: 110 k Downloading Packages: php-gd-8.0.20-3.el9.x86_64.rpm 196 kB/s | 43 kB 00:00 -------------------------------------------------------------------------------- Total 39 kB/s | 43 kB 00:01 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Installing : php-gd-8.0.20-3.el9.x86_64 1/1 Running scriptlet: php-gd-8.0.20-3.el9.x86_64 1/1 Verifying : php-gd-8.0.20-3.el9.x86_64 1/1 Installed: php-gd-8.0.20-3.el9.x86_64 Complete! |
The balance of this page demonstrates how to upload, store, and manage Text (Character Large Data Streams) and BLOBs (Binary Large Objects). It provides MySQL equivalent instructions to those for manaing LOBs in an Oracle database. As covered in Chapter 8 in my Oracle Database 11g PL/SQL Programming book.
Before you begin these steps, you should have already installed Zend Server Community Edition. If you haven’t done so, please click here for instructions.
Create directories or folders, and position code →
This section provides you with instructions on how to position the code components in Windows, at least for the newbie. If you’re on Linux, you probably know how to do most if not all of this already. Likewise, if you already know how to put things in the right place, please choose your own locations.
- Create a
LOB(Large Object) directory for the PHP files inside thehtdocsdirectory.
![]()
- You can down the MySQL PHP Upload LOB Web Code zip file and unzip it into the directory you just created. It can co-exist with the Oracle equivalent if you’ve done that already.
Load a TEXT (like an Oracle CLOB) column to the MySQL database →
This is a copy of the three files required to load a large string to a MySQL database into a mediumtext data type. The code is in clear text because somebody asked for it. They’re nervous about zip files. Click the title above to expand all the code text.
MySQLCredentials.inc
1 2 3 4 5 6 7 | <?php // Connection variables. define('HOSTNAME',"localhost"); define('USERNAME',"student"); define('PASSWORD',"student"); define('DATABASE',"sampledb"); ?> |
UploadItemDescMySQLForm.htm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | <html>
<head>
<title>
UploadItemDescMySQLForm.htm
</title>
</head>
<body>
<form id="uploadForm"
action="UploadItemDescMySQL.php"
enctype="multipart/form-data"
method="post">
<table border=0 cellpadding=0 cellspacing=0>
<tr>
<td width=125>Item Number</td>
<td>
<input id="id" name="id" type="text">
</td>
</tr>
<tr>
<td width=125>Item Title</td>
<td>
<input id="title" name="title" type="text">
</td>
</tr>
<tr>
<td width=125>Select File</td>
<td>
<input id="uploadfilename" name="userfile" type="file">
</td>
</tr>
<tr>
<td width=125>Click Button to</td>
<td><input type="submit" value="Upload File"></td>
</tr>
</table>
</form>
</body>
</html> |
UploadItemDescMySQL.php
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 | <?php // Set database credentials. include_once("MySQLCredentials.inc"); // Displayed moved file in web page. $item_desc = process_uploaded_file(); // Return successful attempt to connect to the database. if (!$c = @mysqli_connect(HOSTNAME,USERNAME,PASSWORD,DATABASE)) { // Print user message. print "Sorry! The connection to the database failed. Please try again later."; // Assign the mysqli_error() and format double and single quotes. print mysqli_error(); // Kill the resource. die(); } else { // Declare input variables. $id = (isset($_POST['id'])) ? (int) $_POST['id'] : $id = 21; $title = (isset($_POST['title'])) ? $_POST['title'] : $title = "Harry #1"; // Initialize a statement in the scope of the connection. $stmt = mysqli_stmt_init($c); // Declare a PL/SQL execution command. $sql = "Update item set item_desc = ? where item_id = ?"; // Prepate statement and link it to a connection. if (mysqli_stmt_prepare($stmt,$sql)) { mysqli_stmt_bind_param($stmt,"si",$item_desc,$id); // Execute it and print success or failure message. if (mysqli_stmt_execute($stmt)) { query_insert($id,$title); } else { print "You're target row doesn't exist."; } } // Disconnect from database. mysqli_close($c); } // Query results afret an insert. function query_insert($id,$title) { // Return successful attempt to connect to the database. if (!$c = @mysqli_connect(HOSTNAME,USERNAME,PASSWORD,DATABASE)) { // Print user message. print "Sorry! The connection to the database failed. Please try again later."; // Assign the OCI error and format double and single quotes. print mysqli_error(); // Kill the resource. die(); } else { // Initialize a statement in the scope of the connection. $stmt = mysqli_stmt_init($c); // Declare a SQL SELECT statement returning a CLOB. $sql = "SELECT item_desc FROM item WHERE item_id = ?"; // Prepare statement. if (mysqli_stmt_prepare($stmt,$sql)) { mysqli_stmt_bind_param($stmt,"i",$id); // Execute it and print success or failure message. if (mysqli_stmt_execute($stmt)) { // Bind result to local variable. mysqli_stmt_bind_result($stmt, $desc); // Read result. mysqli_stmt_fetch($stmt); // Format HTML table to display biography. $out = '<table border="1" cellpadding="3" cellspacing="0">'; $out .= '<tr>'; $out .= '<td align="center" class="e">'.$title.'</td>'; $out .= '</tr>'; $out .= '<tr>'; $out .= '<td class="v">'.$desc.'</td>'; $out .= '</tr>'; $out .= '</table>'; // Print the HTML table. print $out; } } // Disconnect from database. mysqli_close($c); } } // Manage file upload and return file as string. function process_uploaded_file() { // Declare a variable for file contents. $contents = ""; // Define the upload file name for Windows or Linux. if (preg_match(".Win32.",$_SERVER["SERVER_SOFTWARE"])) $upload_file = "C:\\temp\\".$_FILES['userfile']['name']; else $upload_file = "/tmp/".$_FILES['userfile']['name']; // Check for and move uploaded file. if (is_uploaded_file($_FILES['userfile']['tmp_name'])) move_uploaded_file($_FILES['userfile']['tmp_name'],$upload_file); // Open a file handle and suppress an error for a missing file. if ($fp = @fopen($upload_file,"r")) { // Read until the end-of-file marker. while (!feof($fp)) $contents .= fgetc($fp); // Close an open file handle. fclose($fp); } // Return file content as string. return $contents; } ?> |
Load a BLOB column to the MySQL database →
This is a copy of the four files required to load a large image to a MySQL database into a MEDIUMBLOB data type. The fourth file reads the binary image and translates it into an HTML header and image that can be read through a call to the src attribute of an img tag. You can find the call to the forth file in the UploadItemBlobMySQL.php.
The code is in clear text because somebody asked for it. They’re nervous about zip files. Click the title above to expand all the code text.
MySQLCredentials.inc
1 2 3 4 5 6 7 | <?php // Connection variables. define('HOSTNAME',"localhost"); define('USERNAME',"student"); define('PASSWORD',"student"); define('DATABASE',"sampledb"); ?> |
UploadItemBlobMySQLForm.htm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | <html>
<head>
<title>
UploadItemBlobMySQLForm.htm
</title>
</head>
<body>
<form id="uploadForm"
action="UploadItemBlobMySQL.php"
enctype="multipart/form-data"
method="post">
<table border=0 cellpadding=0 cellspacing=0>
<tr>
<td width=125>Item Number</td>
<td>
<input id="id" name="id" type="text">
</td>
</tr>
<tr>
<td width=125>Item Title</td>
<td>
<input id="title" name="title" type="text">
</td>
</tr>
<tr>
<td width=125>Select File</td>
<td>
<input id="uploadfilename" name="userfile" type="file">
</td>
</tr>
<tr>
<td width=125>Click Button to</td>
<td><input type="submit" value="Upload File"></td>
</tr>
</table>
</form>
</body>
</html> |
UploadItemBlobMySQL.php
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 | <?php // Set database credentials. include_once("MySQLCredentials.inc"); // Displayed moved file in web page. $item_blob = process_uploaded_file(); // Return successful attempt to connect to the database. if (!$c = @mysqli_connect(HOSTNAME,USERNAME,PASSWORD,DATABASE)) { // Print user message. print "Sorry! The connection to the database failed. Please try again later."; // Assign the mysqli_error() error and format double and single quotes. print mysqli_error(); // Kill the resource. die(); } else { // Declare input variables. $id = (isset($_POST['id'])) ? (int) $_POST['id'] : 1021; $title = (isset($_POST['title'])) ? $_POST['title'] : "Harry #1"; // Initialize a statement in the scope of the connection. $stmt = mysqli_stmt_init($c); // Declare a PL/SQL execution command. $sql = "UPDATE item SET item_blob = ? WHERE item_id = ?"; // Prepare statement and link it to a connection. if (mysqli_stmt_prepare($stmt,$sql)) { mysqli_stmt_bind_param($stmt,"bi",$item_blob,$id); $start = 0; $chunk = 8192; while ($start < strlen($item_blob)) { mysqli_stmt_send_long_data($stmt,0,substr($item_blob,$start,$chunk)); $start += $chunk; } // Execute the PL/SQL statement. if (mysqli_stmt_execute($stmt)) { query_insert($id,$title); } else { print "Your target row doesn't exist."; } } else { print "mysqli_stmt_prepare() failed."; } // Disconnect from database. mysqli_close($c); } // Query results afret an insert. function query_insert($id,$title) { // Return successful attempt to connect to the database. if (!$c = @mysqli_connect(HOSTNAME,USERNAME,PASSWORD,DATABASE)) { // Print user message. print "Sorry! The connection to the database failed. Please try again later."; // Assign the OCI error and format double and single quotes. print mysqli_error(); // Kill the resource. die(); } else { // Initialize a statement in the scope of the connection. $stmt = mysqli_stmt_init($c); // Declare a SQL SELECT statement returning a CLOB. $sql = "SELECT item_desc FROM item WHERE item_id = ?"; // Prepare statement and link it to a connection. if (mysqli_stmt_prepare($stmt,$sql)) { mysqli_stmt_bind_param($stmt,"i",$id); // Execute the PL/SQL statement. if (mysqli_stmt_execute($stmt)) { // Bind result to local variable. mysqli_stmt_bind_result($stmt, $data); // Read result. mysqli_stmt_fetch($stmt); // Format HTML table to display BLOB photo and CLOB description. $out = '<table border="1" cellpadding="5" cellspacing="0">'; $out .= '<tr>'; $out .= '<td align="center" class="e">'.$title.'</td>'; $out .= '</tr>'; $out .= '<tr><td class="v">'; $out .= '<div>'; $out .= '<div style="margin-right:5px;float:left">'; $out .= '<img src="ConvertMySQLBlobToImage.php?id='.$id.'">'; $out .= '</div>'; $out .= '<div style="position=relative;">'.$data.'</div>'; $out .= '</div>'; $out .= '</td></tr>'; $out .= '</table>'; // Print the HTML table. print $out; } else { print "You're target row doesn't exist."; } } // Disconnect from database. mysqli_close($c); } } // Manage file upload and return file as string. function process_uploaded_file() { // Declare a variable for file contents. $contents = ""; // Define the upload file name for Windows or Linux. if (preg_match(".Win32.",$_SERVER["SERVER_SOFTWARE"])) $upload_file = "C:\\TEMP\\".$_FILES['userfile']['name']; else $upload_file = "/tmp/".$_FILES['userfile']['name']; // Check for and move uploaded file. if (is_uploaded_file($_FILES['userfile']['tmp_name'])) move_uploaded_file($_FILES['userfile']['tmp_name'],$upload_file); // Open a file handle and suppress an error for a missing file. if ($fp = @fopen($upload_file,"r")) { // Read until the end-of-file marker. while (!feof($fp)) $contents .= fgetc($fp); // Close an open file handle. fclose($fp); } // Return file content as string. return $contents; } ?> |
ConvertMySQLBlobToImage.php
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | <?php // Database credentials must be set manually because an include_once() function // call puts something ahead of the header, which causes a failure when rendering // an image. // Return successful attempt to connect to the database. if (!$c = @mysqli_connect("localhost","student","student","sampledb")) { // Print user message. print "Sorry! The connection to the database failed. Please try again later."; // Assign the OCI error and format double and single quotes. print mysqli_error(); // Kill the resource. die(); } else { // Declare input variables. $id = (isset($_GET['id'])) ? (int) $_GET['id'] : 1023; // Initialize a statement in the scope of the connection. $stmt = mysqli_stmt_init($c); // Declare a SQL SELECT statement returning a MediumBLOB. $sql = "SELECT item_blob FROM item WHERE item_id = ?"; // Prepare statement and link it to a connection. if (mysqli_stmt_prepare($stmt,$sql)) { mysqli_stmt_bind_param($stmt,"i",$id); // Execute the PL/SQL statement. if (mysqli_stmt_execute($stmt)) { // Bind result to local variable. mysqli_stmt_bind_result($stmt, $image); // Read result. mysqli_stmt_fetch($stmt); } } // Disconnect from database. mysqli_close($c); // Print the header first. header('Content-type: image/x-png'); imagepng(imagecreatefromstring($image)); } ?> |
- Create a
tempdirectory for the upload target location, as qualified in the PHP code. The PHP code works regardless of whether you’re on Windows or Linux, but it does depend on the creation of this directory.
![]()
- Create a directory or folder for the large file source directories. This directory is probably on your test machine (laptop) but it mimics a client laptop and would work if your server was on a different machine.
![]()
- Inside the Upload directory, you should create the following two directories:

- You should download the CLOB Text File zip file and unzip it into the
textfiles directory; then download the BLOB Image File zip file and unzip it into the imagefiles directory.Assuming you’ve downloaded the zip files and extracted them into the correct locations, this section is done.
Prepare the MySQL database →
This section provides you with instructions on how to ensure everything will work once the PHP programs call the database. Even if you have one of my sample Video Store databases, you should verify and add appropriate columns. This post assumes you’ve downloaded the one of my basic Video Store models
- Navigate to the directory that you created for SQL scripts, which should be
/home/student/Data/mysql. In that directory at the command prompt, connect as thestudentuser, which should be student. You connect to the MySQL database, with the following syntax as student (if you need more help, check this blog post on configuring MySQL).
mysql -ustudent -pstudent |
Once connected to the database, you run the files to create the database, like:
mysql> source /Data/mysql/create_mysql_store.sql mysql> source /Data/mysql/seed_mysql_store.sql |
- Navigate to the directory that you created for SQL scripts, which should be
/home/student/Data/mysql. In that directory at the command prompt, connect as thestudentuser, or whichever account you’re using. You should confirm that you have aitem_desccolumn ofTEXTdata type, and anitem_blobcolumn ofMEDIUMBLOBtype in theitemtable. If you don’t have those columns, you can add them with the following statement:
ALTER TABLE item ADD (item_desc TEXT, item_blob MEDIUMBLOB); |
After ensuring that you have those two columns, you’ve completed this section.
Test the Configuration →
This section shows you how to test all that you’ve done. It works provided you created the directories and extracted the zip file contents to their respective directories. The virtual URL actually maps to the /var/www/html/lob directory.
- Enter the
http://localhost/lob/UploadItemDescMySQLForm.htmURL, and complete the form by choosing a validitem_idcolumn value and text file from your/home/student/Upload/TextFilesdirectory. Then, click the Upload File button (you can see a larger version of the image by clicking on it).

- This page displays after you successfully upload the text file to the database.

- Enter the
http://localhost/lob/UploadItemBlobFormMySQL.htmURL, and complete the form by choosing a validitem_idcolumn value and image file from your/home/student/Upload/ImageFilesdirectory. Then, click the Upload File button (you can see a larger version of the image by clicking on it).

- This page displays after you successfully upload the image file to the database.

Troubleshooting the Configuration →
This section shows you how to check why something isn’t working.
- The first thing to check are the credentials. They’re in the
MySQLCredentials.incfile. They’re posted with alocalhostmachine name,studentusername,studentpassword, andsampledbdatabase.
- Not to be funny, but the second thing to check are credentials. Specifically, you need to check the credentials in the
ConvertBlobToImage.phpfile. They’re individually entered in the connect string of this file because otherwise they put something in front of the header, which is disallowed to render the image.
- Check to see if the text or image file made it to the
/var/www/html/lob/tempdirectory. If they made it that far but no further, check to see if you have valid procedures in thestudentschema.
- Check whether the
TEXTandMEDIUMBLOBare loaded into the database. You use theLENGTHfunction, like this:
SELECT i.item_id , length(i.item_desc) , length(i.item_blob) FROM item i WHERE i.item_desc IS NOT NULL OR i.item_blob IS NOT NULL; |
- Check if the
item_idvalue is found in the list of values.
- If you’re stumped, add a comment and explain what’s up.
If you find any problems, please let me know. I’ll be happy to fix them.
AlmaLinux Install & Configuration

This is a collection of blog posts for installing and configuring AlmaLinux with the Oracle, PostgreSQL, MySQL databases and several programming languages. Sample programs show how to connect PHP and Python to the MySQL database.
- Installing AlmaLinux operating system
- Installing and configuring MySQL
- Installing Python-MySQL connector and provide sample programs
- Configuring Flask for Python on AlmaLinux with a complete software router instruction set.
- Installing Rust programming language and writing a sample program
- Installing and configuring LAMP stack with PHP and MySQL and a self-signed security key
- MySQL PNG Images in LAMP with PHP Programming
- Demonstration of how to write Perl that connects to MySQL
- Installing and configuring MySQL Workbench
- Installing and configuring PostgreSQL and pgAdmin4
- Identifying the required libnsl2-devel packages for SQL*Plus
- Writing and deploying a sqlplus function to use a read line wrapper
- Installing and configuring Visual Studio Code Editor
- Installing and configuring Java with connectivity to MySQL
- Installing and configuring Oracle SQL Developer
I used Oracle Database 11g XE in this instance to keep the footprint as small as possible. It required a few tricks and discovering the missing library that caused folks grief eleven years ago. I build another with a current Oracle Database XE after the new year.
If you see something that I missed or you’d like me to add, let me know. As time allows, I’ll try to do that. Naturally, the post will get updates as things are added later.
AlmaLinux MySQL Workbench
AlmaLinux doesn’t natively support MySQL Workbench but these notes will help you install it. The great news is that MySQL Workbench works perfectly once you’ve installed all the dependent libraries. It’ll look like the following:
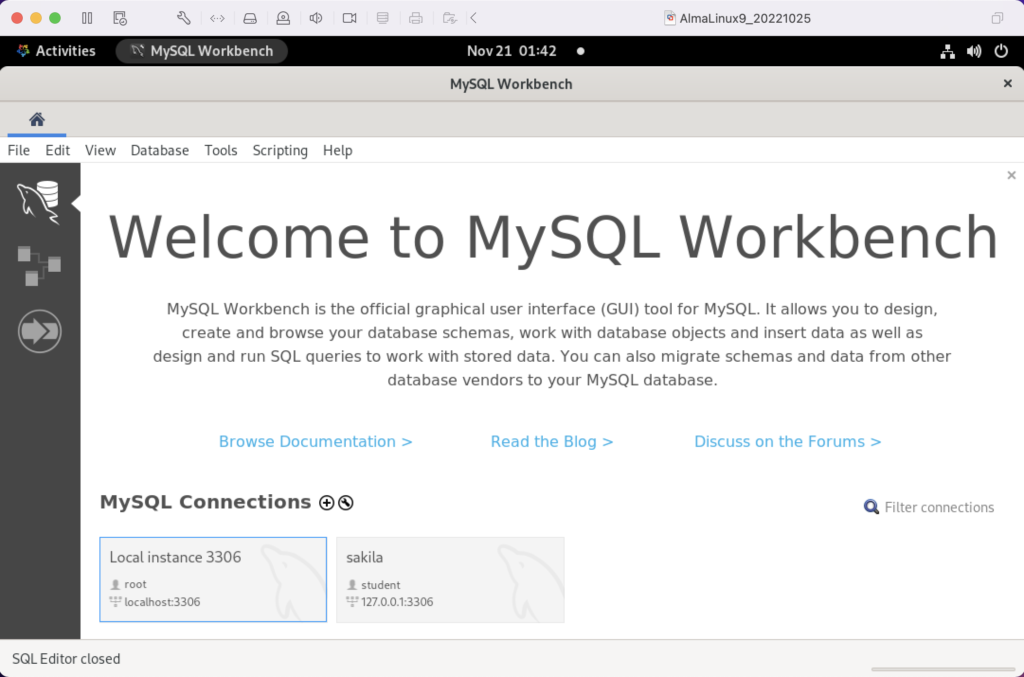
Disclaimer of sorts:
AlmaLinux is an open-source, community-driven project that intends to fill the gap left by the demise of the CentOS stable release. AlmaLinux is a 1:1 binary compatible fork of RHEL® 9 and it is built by the AlmaLinux OS Foundation as a standalone, completely free OS. The AlmaLinux OS Foundation will support future RHEL® releases by updating AlmaLinux. Ongoing development efforts are governed by the members of the community.
You can download MySQL Workbench from the following website:
https://dev.mysql.com/downloads/workbench |
When you open this page, select the Red Hat Enterprise Linux 9 / Oracle Linux 9 (x86, 64-bit), RPM Package from the dropdown menu. Then, click the Download button. You may be prompted for your credentials or to create new credentials, but you can skip that by clicking on the No thanks, just start my download link.
When the download completes, open a terminal session as the student user. Navigate to the Downloads directory with the following command:
cd $HOME/Downloads |
List the files in the $HOME/Downloads directory and you should see:
mysql-workbench-community-8.0.31-1.el9.x86_64.rpm |
As the sudoer user or root, run the following command (naturally, exclude sudo if you’re the root user):
sudo dnf install -y mysql-workbench-community-8.0.31-1.el9.x86_64.rpm |
It will most likely fail with an error message like this:
Last metadata expiration check: 2:50:04 ago on Thu 17 Nov 2022 09:33:15 AM EST. Error: Problem: conflicting requests - nothing provides gtkmm30-devel needed by mysql-workbench-community-8.0.31-1.el9.src - nothing provides libzip-devel needed by mysql-workbench-community-8.0.31-1.el9.src - nothing provides proj-devel needed by mysql-workbench-community-8.0.31-1.el9.src - nothing provides swig >= 3.0 needed by mysql-workbench-community-8.0.31-1.el9.src (try to add '--skip-broken' to skip uninstallable packages or '--nobest' to use not only best candidate packages) |
AlmaLinux doesn’t install these prerequisite packages. You’ll need to resolve these dependencies by installing them in the right order and groups before you can run the MySQL Workbench packages.
You can discover missing packages at the pkgs.org website. You need to resolve all four prerequisites before installing MySQL Workbench.
- Let’s start with the gtkmm30-devel package, which has eight separate dependencies. Assuming you’re still in your $HOME/Downloads directory, you can run the following command to get the gtkmm30-devel for AlmaLinux 9:
wget https://repo.almalinux.org/almalinux/9/CRB/x86_64/os/Packages/gtkmm30-devel-3.24.5-1.el9.x86_64.rpm
It downloads the following package:
gtkmm30-devel-3.24.5-1.el9.x86_64.rpm
If you attempt to run it, the gtkmm30-devel package raises the following errors:
sudo dnf install -y gtkmm30-devel-3.24.5-1.el9.x86_64.rpm Last metadata expiration check: 0:41:13 ago on Thu 17 Nov 2022 02:39:59 PM EST. Error: Problem: conflicting requests - nothing provides pkgconfig(atkmm-1.6) >= 2.24.2 needed by gtkmm30-devel-3.24.5-1.el9.x86_64 - nothing provides pkgconfig(cairomm-1.0) >= 1.12.0 needed by gtkmm30-devel-3.24.5-1.el9.x86_64 - nothing provides pkgconfig(giomm-2.4) >= 2.54.0 needed by gtkmm30-devel-3.24.5-1.el9.x86_64 - nothing provides pkgconfig(pangomm-1.4) >= 1.12.0 needed by gtkmm30-devel-3.24.5-1.el9.x86_64 (try to add '--skip-broken' to skip uninstallable packages or '--nobest' to use not only best candidate packages)
While you only get four errors, there are more packages required. You need to use the wget utility to download these packages. I would recommend you create a temporary gtkmm30 subdirectory inside your $HOME/Downloads directory and change to that directory before downloading these files.
wget https://repo.almalinux.org/almalinux/9/CRB/x86_64/os/Packages/atkmm-devel-2.28.2-2.el9.x86_64.rpm wget https://repo.almalinux.org/almalinux/9/CRB/x86_64/os/Packages/cairomm-devel-1.14.2-10.el9.x86_64.rpm wget https://repo.almalinux.org/almalinux/9/AppStream/x86_64/os/Packages/gdk-pixbuf2-devel-2.42.6-2.el9.x86_64.rpm wget https://repo.almalinux.org/almalinux/9/CRB/x86_64/os/Packages/glibmm24-devel-2.66.1-1.el9.x86_64.rpm wget https://repo.almalinux.org/almalinux/9/AppStream/x86_64/os/Packages/gtk3-devel-3.24.31-2.el9.x86_64.rpm wget https://repo.almalinux.org/almalinux/9/CRB/x86_64/os/Packages/pangomm-devel-2.46.1-1.el9.x86_64.rpm wget https://repo.almalinux.org/almalinux/9/CRB/x86_64/os/Packages/libsigc++20-devel-2.10.7-2.el9.x86_64.rpm
You need to run these as a set of prerequisites, so from your gtkmm30 subdirectory use the following dnf command as the sudoer user:
sudo dnf install -y *.rpm
The log file for this is:
Display detailed console log →
Last metadata expiration check: 0:09:20 ago on Sun 20 Nov 2022 12:52:28 AM EST. Dependencies resolved. ================================================================================ Package Arch Version Repository Size ================================================================================ Installing: atkmm-devel x86_64 2.28.2-2.el9 @commandline 45 k cairomm-devel x86_64 1.14.2-10.el9 @commandline 62 k gdk-pixbuf2-devel x86_64 2.42.6-2.el9 @commandline 64 k glibmm24-devel x86_64 2.66.1-1.el9 @commandline 497 k gtk3-devel x86_64 3.24.31-2.el9 @commandline 4.1 M libsigc++20-devel x86_64 2.10.7-2.el9 @commandline 67 k pangomm-devel x86_64 2.46.1-1.el9 @commandline 65 k Upgrading: dbus-common noarch 1:1.12.20-6.el9 baseos 14 k dbus-daemon x86_64 1:1.12.20-6.el9 appstream 196 k dbus-libs x86_64 1:1.12.20-6.el9 baseos 151 k dbus-tools x86_64 1:1.12.20-6.el9 baseos 50 k fontconfig x86_64 2.14.0-1.el9 appstream 274 k freetype x86_64 2.10.4-9.el9 baseos 387 k fribidi x86_64 1.0.10-6.el9.2 appstream 84 k harfbuzz x86_64 2.7.4-8.el9 baseos 624 k harfbuzz-icu x86_64 2.7.4-8.el9 appstream 14 k libblkid x86_64 2.37.4-9.el9 baseos 107 k libfdisk x86_64 2.37.4-9.el9 baseos 154 k libmount x86_64 2.37.4-9.el9 baseos 133 k libselinux x86_64 3.4-3.el9 baseos 85 k libselinux-utils x86_64 3.4-3.el9 baseos 158 k libsepol x86_64 3.4-1.1.el9 baseos 315 k libsmartcols x86_64 2.37.4-9.el9 baseos 63 k libtiff x86_64 4.4.0-2.el9 appstream 195 k libuuid x86_64 2.37.4-9.el9 baseos 27 k libxml2 x86_64 2.9.13-2.el9 baseos 746 k pcre2 x86_64 10.40-2.el9 baseos 236 k pcre2-syntax noarch 10.40-2.el9 baseos 143 k pcre2-utf16 x86_64 10.40-2.el9 appstream 216 k pcre2-utf32 x86_64 10.40-2.el9 appstream 205 k python3-libselinux x86_64 3.4-3.el9 appstream 185 k python3-libxml2 x86_64 2.9.13-2.el9 baseos 226 k util-linux x86_64 2.37.4-9.el9 baseos 2.2 M util-linux-core x86_64 2.37.4-9.el9 baseos 434 k util-linux-user x86_64 2.37.4-9.el9 baseos 30 k Installing dependencies: at-spi2-atk-devel x86_64 2.38.0-4.el9 appstream 9.5 k at-spi2-core-devel x86_64 2.40.3-1.el9 appstream 134 k atk-devel x86_64 2.36.0-5.el9 appstream 172 k brotli x86_64 1.0.9-6.el9 appstream 313 k brotli-devel x86_64 1.0.9-6.el9 appstream 31 k bzip2-devel x86_64 1.0.8-8.el9 appstream 213 k cairo-devel x86_64 1.17.4-7.el9 appstream 190 k cairo-gobject-devel x86_64 1.17.4-7.el9 appstream 10 k dbus-devel x86_64 1:1.12.20-6.el9 appstream 33 k fontconfig-devel x86_64 2.14.0-1.el9 appstream 128 k freetype-devel x86_64 2.10.4-9.el9 appstream 1.1 M fribidi-devel x86_64 1.0.10-6.el9.2 appstream 25 k glib2-devel x86_64 2.68.4-5.el9 appstream 475 k graphite2-devel x86_64 1.3.14-9.el9 appstream 21 k harfbuzz-devel x86_64 2.7.4-8.el9 appstream 305 k libX11-devel x86_64 1.7.0-7.el9 appstream 940 k libXau-devel x86_64 1.0.9-8.el9 appstream 13 k libXcomposite-devel x86_64 0.4.5-7.el9 appstream 15 k libXcursor-devel x86_64 1.2.0-7.el9 appstream 21 k libXdamage-devel x86_64 1.1.5-7.el9 appstream 9.3 k libXext-devel x86_64 1.3.4-8.el9 appstream 72 k libXfixes-devel x86_64 5.0.3-16.el9 appstream 12 k libXft-devel x86_64 2.3.3-8.el9 appstream 18 k libXi-devel x86_64 1.7.10-8.el9 appstream 99 k libXinerama-devel x86_64 1.1.4-10.el9 appstream 13 k libXrandr-devel x86_64 1.5.2-8.el9 appstream 19 k libXrender-devel x86_64 0.9.10-16.el9 appstream 16 k libXtst-devel x86_64 1.2.3-16.el9 appstream 15 k libblkid-devel x86_64 2.37.4-9.el9 appstream 17 k libdatrie-devel x86_64 0.2.13-4.el9 appstream 132 k libepoxy-devel x86_64 1.5.5-4.el9 appstream 133 k libffi-devel x86_64 3.4.2-7.el9 appstream 29 k libglvnd-core-devel x86_64 1:1.3.4-1.el9 appstream 17 k libglvnd-devel x86_64 1:1.3.4-1.el9 appstream 155 k libicu-devel x86_64 67.1-9.el9 appstream 830 k libmount-devel x86_64 2.37.4-9.el9 appstream 18 k libpng-devel x86_64 2:1.6.37-12.el9 appstream 290 k libselinux-devel x86_64 3.4-3.el9 appstream 113 k libsepol-devel x86_64 3.4-1.1.el9 appstream 40 k libthai-devel x86_64 0.1.28-8.el9 appstream 117 k libtiff-devel x86_64 4.4.0-2.el9 appstream 513 k libxcb-devel x86_64 1.13.1-9.el9 appstream 1.0 M libxkbcommon-devel x86_64 1.0.3-4.el9 appstream 61 k libxml2-devel x86_64 2.9.13-2.el9 appstream 828 k pango-devel x86_64 1.48.7-2.el9 appstream 141 k pcre-cpp x86_64 8.44-3.el9.3 appstream 26 k pcre-devel x86_64 8.44-3.el9.3 appstream 470 k pcre-utf16 x86_64 8.44-3.el9.3 appstream 184 k pcre-utf32 x86_64 8.44-3.el9.3 appstream 174 k pcre2-devel x86_64 10.40-2.el9 appstream 474 k perl-Filter x86_64 2:1.60-4.el9 appstream 81 k perl-encoding x86_64 4:3.00-462.el9 appstream 62 k perl-open noarch 1.12-479.el9 appstream 25 k pixman-devel x86_64 0.40.0-5.el9 appstream 17 k sysprof-capture-devel x86_64 3.40.1-3.el9 appstream 59 k wayland-devel x86_64 1.19.0-4.el9 appstream 132 k xorg-x11-proto-devel noarch 2021.4-2.el9 appstream 262 k Transaction Summary ================================================================================ Install 64 Packages Upgrade 28 Packages Total size: 23 M Total download size: 18 M Downloading Packages: (1/85): at-spi2-atk-devel-2.38.0-4.el9.x86_64.r 38 kB/s | 9.5 kB 00:00 (2/85): atk-devel-2.36.0-5.el9.x86_64.rpm 334 kB/s | 172 kB 00:00 (3/85): brotli-devel-1.0.9-6.el9.x86_64.rpm 354 kB/s | 31 kB 00:00 (4/85): at-spi2-core-devel-2.40.3-1.el9.x86_64. 167 kB/s | 134 kB 00:00 (5/85): cairo-devel-1.17.4-7.el9.x86_64.rpm 1.9 MB/s | 190 kB 00:00 (6/85): cairo-gobject-devel-1.17.4-7.el9.x86_64 179 kB/s | 10 kB 00:00 (7/85): brotli-1.0.9-6.el9.x86_64.rpm 413 kB/s | 313 kB 00:00 (8/85): dbus-devel-1.12.20-6.el9.x86_64.rpm 549 kB/s | 33 kB 00:00 (9/85): bzip2-devel-1.0.8-8.el9.x86_64.rpm 505 kB/s | 213 kB 00:00 (10/85): fribidi-devel-1.0.10-6.el9.2.x86_64.rp 492 kB/s | 25 kB 00:00 (11/85): fontconfig-devel-2.14.0-1.el9.x86_64.r 891 kB/s | 128 kB 00:00 (12/85): graphite2-devel-1.3.14-9.el9.x86_64.rp 316 kB/s | 21 kB 00:00 (13/85): glib2-devel-2.68.4-5.el9.x86_64.rpm 1.1 MB/s | 475 kB 00:00 (14/85): harfbuzz-devel-2.7.4-8.el9.x86_64.rpm 850 kB/s | 305 kB 00:00 (15/85): freetype-devel-2.10.4-9.el9.x86_64.rpm 1.7 MB/s | 1.1 MB 00:00 (16/85): libXau-devel-1.0.9-8.el9.x86_64.rpm 170 kB/s | 13 kB 00:00 (17/85): libXcomposite-devel-0.4.5-7.el9.x86_64 273 kB/s | 15 kB 00:00 (18/85): libXcursor-devel-1.2.0-7.el9.x86_64.rp 344 kB/s | 21 kB 00:00 (19/85): libXdamage-devel-1.1.5-7.el9.x86_64.rp 133 kB/s | 9.3 kB 00:00 (20/85): libXfixes-devel-5.0.3-16.el9.x86_64.rp 256 kB/s | 12 kB 00:00 (21/85): libXext-devel-1.3.4-8.el9.x86_64.rpm 768 kB/s | 72 kB 00:00 (22/85): libXft-devel-2.3.3-8.el9.x86_64.rpm 324 kB/s | 18 kB 00:00 (23/85): libXinerama-devel-1.1.4-10.el9.x86_64. 205 kB/s | 13 kB 00:00 (24/85): libXi-devel-1.7.10-8.el9.x86_64.rpm 913 kB/s | 99 kB 00:00 (25/85): libXrender-devel-0.9.10-16.el9.x86_64. 295 kB/s | 16 kB 00:00 (26/85): libXrandr-devel-1.5.2-8.el9.x86_64.rpm 289 kB/s | 19 kB 00:00 (27/85): libXtst-devel-1.2.3-16.el9.x86_64.rpm 261 kB/s | 15 kB 00:00 (28/85): libblkid-devel-2.37.4-9.el9.x86_64.rpm 284 kB/s | 17 kB 00:00 (29/85): libX11-devel-1.7.0-7.el9.x86_64.rpm 1.4 MB/s | 940 kB 00:00 (30/85): libepoxy-devel-1.5.5-4.el9.x86_64.rpm 1.2 MB/s | 133 kB 00:00 (31/85): libdatrie-devel-0.2.13-4.el9.x86_64.rp 876 kB/s | 132 kB 00:00 (32/85): libffi-devel-3.4.2-7.el9.x86_64.rpm 426 kB/s | 29 kB 00:00 (33/85): libglvnd-core-devel-1.3.4-1.el9.x86_64 233 kB/s | 17 kB 00:00 (34/85): libmount-devel-2.37.4-9.el9.x86_64.rpm 280 kB/s | 18 kB 00:00 (35/85): libglvnd-devel-1.3.4-1.el9.x86_64.rpm 976 kB/s | 155 kB 00:00 (36/85): libpng-devel-1.6.37-12.el9.x86_64.rpm 1.9 MB/s | 290 kB 00:00 (37/85): libselinux-devel-3.4-3.el9.x86_64.rpm 801 kB/s | 113 kB 00:00 (38/85): libsepol-devel-3.4-1.1.el9.x86_64.rpm 636 kB/s | 40 kB 00:00 (39/85): libthai-devel-0.1.28-8.el9.x86_64.rpm 630 kB/s | 117 kB 00:00 (40/85): libicu-devel-67.1-9.el9.x86_64.rpm 1.3 MB/s | 830 kB 00:00 (41/85): libtiff-devel-4.4.0-2.el9.x86_64.rpm 1.6 MB/s | 513 kB 00:00 (42/85): libxkbcommon-devel-1.0.3-4.el9.x86_64. 710 kB/s | 61 kB 00:00 (43/85): pango-devel-1.48.7-2.el9.x86_64.rpm 914 kB/s | 141 kB 00:00 (44/85): pcre-cpp-8.44-3.el9.3.x86_64.rpm 425 kB/s | 26 kB 00:00 (45/85): pcre-devel-8.44-3.el9.3.x86_64.rpm 1.8 MB/s | 470 kB 00:00 (46/85): pcre-utf16-8.44-3.el9.3.x86_64.rpm 1.5 MB/s | 184 kB 00:00 (47/85): libxml2-devel-2.9.13-2.el9.x86_64.rpm 1.2 MB/s | 828 kB 00:00 (48/85): libxcb-devel-1.13.1-9.el9.x86_64.rpm 1.2 MB/s | 1.0 MB 00:00 (49/85): pcre-utf32-8.44-3.el9.3.x86_64.rpm 1.4 MB/s | 174 kB 00:00 (50/85): perl-Filter-1.60-4.el9.x86_64.rpm 704 kB/s | 81 kB 00:00 (51/85): perl-encoding-3.00-462.el9.x86_64.rpm 916 kB/s | 62 kB 00:00 (52/85): perl-open-1.12-479.el9.noarch.rpm 476 kB/s | 25 kB 00:00 (53/85): pixman-devel-0.40.0-5.el9.x86_64.rpm 272 kB/s | 17 kB 00:00 (54/85): sysprof-capture-devel-3.40.1-3.el9.x86 797 kB/s | 59 kB 00:00 (55/85): pcre2-devel-10.40-2.el9.x86_64.rpm 1.3 MB/s | 474 kB 00:00 (56/85): wayland-devel-1.19.0-4.el9.x86_64.rpm 1.0 MB/s | 132 kB 00:00 (57/85): xorg-x11-proto-devel-2021.4-2.el9.noar 1.3 MB/s | 262 kB 00:00 (58/85): dbus-daemon-1.12.20-6.el9.x86_64.rpm 1.3 MB/s | 196 kB 00:00 (59/85): fontconfig-2.14.0-1.el9.x86_64.rpm 1.7 MB/s | 274 kB 00:00 (60/85): harfbuzz-icu-2.7.4-8.el9.x86_64.rpm 217 kB/s | 14 kB 00:00 (61/85): fribidi-1.0.10-6.el9.2.x86_64.rpm 700 kB/s | 84 kB 00:00 (62/85): libtiff-4.4.0-2.el9.x86_64.rpm 1.5 MB/s | 195 kB 00:00 (63/85): pcre2-utf32-10.40-2.el9.x86_64.rpm 1.2 MB/s | 205 kB 00:00 (64/85): python3-libselinux-3.4-3.el9.x86_64.rp 1.5 MB/s | 185 kB 00:00 (65/85): pcre2-utf16-10.40-2.el9.x86_64.rpm 995 kB/s | 216 kB 00:00 (66/85): dbus-common-1.12.20-6.el9.noarch.rpm 203 kB/s | 14 kB 00:00 (67/85): dbus-tools-1.12.20-6.el9.x86_64.rpm 856 kB/s | 50 kB 00:00 (68/85): dbus-libs-1.12.20-6.el9.x86_64.rpm 1.3 MB/s | 151 kB 00:00 (69/85): libblkid-2.37.4-9.el9.x86_64.rpm 1.6 MB/s | 107 kB 00:00 (70/85): libfdisk-2.37.4-9.el9.x86_64.rpm 1.6 MB/s | 154 kB 00:00 (71/85): freetype-2.10.4-9.el9.x86_64.rpm 1.5 MB/s | 387 kB 00:00 (72/85): libmount-2.37.4-9.el9.x86_64.rpm 1.3 MB/s | 133 kB 00:00 (73/85): libselinux-3.4-3.el9.x86_64.rpm 820 kB/s | 85 kB 00:00 (74/85): harfbuzz-2.7.4-8.el9.x86_64.rpm 1.4 MB/s | 624 kB 00:00 (75/85): libselinux-utils-3.4-3.el9.x86_64.rpm 1.4 MB/s | 158 kB 00:00 (76/85): libuuid-2.37.4-9.el9.x86_64.rpm 448 kB/s | 27 kB 00:00 (77/85): libsmartcols-2.37.4-9.el9.x86_64.rpm 793 kB/s | 63 kB 00:00 (78/85): libsepol-3.4-1.1.el9.x86_64.rpm 1.6 MB/s | 315 kB 00:00 (79/85): pcre2-syntax-10.40-2.el9.noarch.rpm 1.2 MB/s | 143 kB 00:00 (80/85): pcre2-10.40-2.el9.x86_64.rpm 1.6 MB/s | 236 kB 00:00 (81/85): python3-libxml2-2.9.13-2.el9.x86_64.rp 1.4 MB/s | 226 kB 00:00 (82/85): libxml2-2.9.13-2.el9.x86_64.rpm 1.5 MB/s | 746 kB 00:00 (83/85): util-linux-user-2.37.4-9.el9.x86_64.rp 618 kB/s | 30 kB 00:00 (84/85): util-linux-core-2.37.4-9.el9.x86_64.rp 1.1 MB/s | 434 kB 00:00 (85/85): util-linux-2.37.4-9.el9.x86_64.rpm 1.9 MB/s | 2.2 MB 00:01 -------------------------------------------------------------------------------- Total 2.4 MB/s | 18 MB 00:07 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Installing : xorg-x11-proto-devel-2021.4-2.el9.noarch 1/120 Upgrading : libuuid-2.37.4-9.el9.x86_64 2/120 Upgrading : libblkid-2.37.4-9.el9.x86_64 3/120 Running scriptlet: libblkid-2.37.4-9.el9.x86_64 3/120 Upgrading : harfbuzz-2.7.4-8.el9.x86_64 4/120 Upgrading : freetype-2.10.4-9.el9.x86_64 5/120 Upgrading : libxml2-2.9.13-2.el9.x86_64 6/120 Upgrading : pcre2-syntax-10.40-2.el9.noarch 7/120 Upgrading : pcre2-10.40-2.el9.x86_64 8/120 Upgrading : libsepol-3.4-1.1.el9.x86_64 9/120 Upgrading : libselinux-3.4-3.el9.x86_64 10/120 Running scriptlet: libselinux-3.4-3.el9.x86_64 10/120 Upgrading : libmount-2.37.4-9.el9.x86_64 11/120 Upgrading : dbus-libs-1:1.12.20-6.el9.x86_64 12/120 Installing : libpng-devel-2:1.6.37-12.el9.x86_64 13/120 Installing : dbus-devel-1:1.12.20-6.el9.x86_64 14/120 Installing : libxml2-devel-2.9.13-2.el9.x86_64 15/120 Upgrading : libsmartcols-2.37.4-9.el9.x86_64 16/120 Installing : libsigc++20-devel-2.10.7-2.el9.x86_64 17/120 Installing : libffi-devel-3.4.2-7.el9.x86_64 18/120 Installing : wayland-devel-1.19.0-4.el9.x86_64 19/120 Upgrading : util-linux-core-2.37.4-9.el9.x86_64 20/120 Running scriptlet: util-linux-core-2.37.4-9.el9.x86_64 20/120 Installing : libxkbcommon-devel-1.0.3-4.el9.x86_64 21/120 Upgrading : dbus-tools-1:1.12.20-6.el9.x86_64 22/120 Installing : libsepol-devel-3.4-1.1.el9.x86_64 23/120 Upgrading : pcre2-utf16-10.40-2.el9.x86_64 24/120 Upgrading : pcre2-utf32-10.40-2.el9.x86_64 25/120 Installing : pcre2-devel-10.40-2.el9.x86_64 26/120 Installing : libselinux-devel-3.4-3.el9.x86_64 27/120 Upgrading : fontconfig-2.14.0-1.el9.x86_64 28/120 Running scriptlet: fontconfig-2.14.0-1.el9.x86_64 28/120 Upgrading : harfbuzz-icu-2.7.4-8.el9.x86_64 29/120 Installing : libblkid-devel-2.37.4-9.el9.x86_64 30/120 Installing : libmount-devel-2.37.4-9.el9.x86_64 31/120 Upgrading : libfdisk-2.37.4-9.el9.x86_64 32/120 Upgrading : util-linux-2.37.4-9.el9.x86_64 33/120 Installing : libXau-devel-1.0.9-8.el9.x86_64 34/120 Installing : libxcb-devel-1.13.1-9.el9.x86_64 35/120 Installing : libX11-devel-1.7.0-7.el9.x86_64 36/120 Installing : libXext-devel-1.3.4-8.el9.x86_64 37/120 Installing : libXfixes-devel-5.0.3-16.el9.x86_64 38/120 Installing : libXrender-devel-0.9.10-16.el9.x86_64 39/120 Installing : libXi-devel-1.7.10-8.el9.x86_64 40/120 Installing : libXtst-devel-1.2.3-16.el9.x86_64 41/120 Installing : libXcursor-devel-1.2.0-7.el9.x86_64 42/120 Installing : libXrandr-devel-1.5.2-8.el9.x86_64 43/120 Installing : libXcomposite-devel-0.4.5-7.el9.x86_64 44/120 Installing : libXdamage-devel-1.1.5-7.el9.x86_64 45/120 Installing : libXinerama-devel-1.1.4-10.el9.x86_64 46/120 Upgrading : dbus-common-1:1.12.20-6.el9.noarch 47/120 Running scriptlet: dbus-common-1:1.12.20-6.el9.noarch 47/120 Upgrading : libtiff-4.4.0-2.el9.x86_64 48/120 Installing : libtiff-devel-4.4.0-2.el9.x86_64 49/120 Upgrading : fribidi-1.0.10-6.el9.2.x86_64 50/120 Installing : fribidi-devel-1.0.10-6.el9.2.x86_64 51/120 Installing : sysprof-capture-devel-3.40.1-3.el9.x86_64 52/120 Installing : pixman-devel-0.40.0-5.el9.x86_64 53/120 Installing : perl-Filter-2:1.60-4.el9.x86_64 54/120 Installing : perl-encoding-4:3.00-462.el9.x86_64 55/120 Installing : perl-open-1.12-479.el9.noarch 56/120 Installing : pcre-utf32-8.44-3.el9.3.x86_64 57/120 Installing : pcre-utf16-8.44-3.el9.3.x86_64 58/120 Installing : pcre-cpp-8.44-3.el9.3.x86_64 59/120 Installing : pcre-devel-8.44-3.el9.3.x86_64 60/120 Installing : glib2-devel-2.68.4-5.el9.x86_64 61/120 Installing : atk-devel-2.36.0-5.el9.x86_64 62/120 Installing : glibmm24-devel-2.66.1-1.el9.x86_64 63/120 Installing : at-spi2-core-devel-2.40.3-1.el9.x86_64 64/120 Installing : at-spi2-atk-devel-2.38.0-4.el9.x86_64 65/120 Installing : gdk-pixbuf2-devel-2.42.6-2.el9.x86_64 66/120 Installing : libicu-devel-67.1-9.el9.x86_64 67/120 Installing : libglvnd-core-devel-1:1.3.4-1.el9.x86_64 68/120 Installing : libglvnd-devel-1:1.3.4-1.el9.x86_64 69/120 Installing : libepoxy-devel-1.5.5-4.el9.x86_64 70/120 Installing : libdatrie-devel-0.2.13-4.el9.x86_64 71/120 Installing : libthai-devel-0.1.28-8.el9.x86_64 72/120 Installing : graphite2-devel-1.3.14-9.el9.x86_64 73/120 Installing : bzip2-devel-1.0.8-8.el9.x86_64 74/120 Installing : brotli-1.0.9-6.el9.x86_64 75/120 Installing : brotli-devel-1.0.9-6.el9.x86_64 76/120 Installing : harfbuzz-devel-2.7.4-8.el9.x86_64 77/120 Installing : freetype-devel-2.10.4-9.el9.x86_64 78/120 Installing : fontconfig-devel-2.14.0-1.el9.x86_64 79/120 Installing : cairo-devel-1.17.4-7.el9.x86_64 80/120 Installing : cairo-gobject-devel-1.17.4-7.el9.x86_64 81/120 Installing : cairomm-devel-1.14.2-10.el9.x86_64 82/120 Installing : libXft-devel-2.3.3-8.el9.x86_64 83/120 Installing : pango-devel-1.48.7-2.el9.x86_64 84/120 Installing : gtk3-devel-3.24.31-2.el9.x86_64 85/120 Installing : pangomm-devel-2.46.1-1.el9.x86_64 86/120 Installing : atkmm-devel-2.28.2-2.el9.x86_64 87/120 Running scriptlet: dbus-daemon-1:1.12.20-6.el9.x86_64 88/120 Upgrading : dbus-daemon-1:1.12.20-6.el9.x86_64 88/120 Running scriptlet: dbus-daemon-1:1.12.20-6.el9.x86_64 88/120 Upgrading : util-linux-user-2.37.4-9.el9.x86_64 89/120 Upgrading : python3-libselinux-3.4-3.el9.x86_64 90/120 Upgrading : libselinux-utils-3.4-3.el9.x86_64 91/120 Upgrading : python3-libxml2-2.9.13-2.el9.x86_64 92/120 Cleanup : python3-libxml2-2.9.13-1.el9_0.1.x86_64 93/120 Running scriptlet: dbus-daemon-1:1.12.20-5.el9.x86_64 94/120 Cleanup : dbus-daemon-1:1.12.20-5.el9.x86_64 94/120 Running scriptlet: dbus-daemon-1:1.12.20-5.el9.x86_64 94/120 Cleanup : libselinux-utils-3.3-2.el9.x86_64 95/120 Cleanup : fontconfig-2.13.94-2.el9.x86_64 96/120 Running scriptlet: fontconfig-2.13.94-2.el9.x86_64 96/120 Cleanup : dbus-tools-1:1.12.20-5.el9.x86_64 97/120 Cleanup : python3-libselinux-3.3-2.el9.x86_64 98/120 Cleanup : util-linux-user-2.37.4-3.el9.x86_64 99/120 Cleanup : util-linux-2.37.4-3.el9.x86_64 100/120 Cleanup : util-linux-core-2.37.4-3.el9.x86_64 101/120 Cleanup : libmount-2.37.4-3.el9.x86_64 102/120 Cleanup : libfdisk-2.37.4-3.el9.x86_64 103/120 Cleanup : libselinux-3.3-2.el9.x86_64 104/120 Cleanup : harfbuzz-icu-2.7.4-5.el9.x86_64 105/120 Cleanup : pcre2-10.37-5.el9_0.x86_64 106/120 Cleanup : libblkid-2.37.4-3.el9.x86_64 107/120 Cleanup : freetype-2.10.4-6.el9.x86_64 108/120 Cleanup : pcre2-utf32-10.37-5.el9_0.x86_64 109/120 Cleanup : pcre2-utf16-10.37-5.el9_0.x86_64 110/120 Cleanup : pcre2-syntax-10.37-5.el9_0.noarch 111/120 Running scriptlet: dbus-common-1:1.12.20-5.el9.noarch 112/120 Cleanup : dbus-common-1:1.12.20-5.el9.noarch 112/120 Running scriptlet: dbus-common-1:1.12.20-5.el9.noarch 112/120 Cleanup : harfbuzz-2.7.4-5.el9.x86_64 113/120 Cleanup : libuuid-2.37.4-3.el9.x86_64 114/120 Cleanup : libsepol-3.3-2.el9.x86_64 115/120 Cleanup : libsmartcols-2.37.4-3.el9.x86_64 116/120 Cleanup : dbus-libs-1:1.12.20-5.el9.x86_64 117/120 Cleanup : libxml2-2.9.13-1.el9_0.1.x86_64 118/120 Cleanup : libtiff-4.2.0-3.el9.x86_64 119/120 Cleanup : fribidi-1.0.10-6.el9.x86_64 120/120 Running scriptlet: fontconfig-2.14.0-1.el9.x86_64 120/120 Running scriptlet: fribidi-1.0.10-6.el9.x86_64 120/120 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Verifying : at-spi2-atk-devel-2.38.0-4.el9.x86_64 1/120 Verifying : at-spi2-core-devel-2.40.3-1.el9.x86_64 2/120 Verifying : atk-devel-2.36.0-5.el9.x86_64 3/120 Verifying : brotli-1.0.9-6.el9.x86_64 4/120 Verifying : brotli-devel-1.0.9-6.el9.x86_64 5/120 Verifying : bzip2-devel-1.0.8-8.el9.x86_64 6/120 Verifying : cairo-devel-1.17.4-7.el9.x86_64 7/120 Verifying : cairo-gobject-devel-1.17.4-7.el9.x86_64 8/120 Verifying : dbus-devel-1:1.12.20-6.el9.x86_64 9/120 Verifying : fontconfig-devel-2.14.0-1.el9.x86_64 10/120 Verifying : freetype-devel-2.10.4-9.el9.x86_64 11/120 Verifying : fribidi-devel-1.0.10-6.el9.2.x86_64 12/120 Verifying : glib2-devel-2.68.4-5.el9.x86_64 13/120 Verifying : graphite2-devel-1.3.14-9.el9.x86_64 14/120 Verifying : harfbuzz-devel-2.7.4-8.el9.x86_64 15/120 Verifying : libX11-devel-1.7.0-7.el9.x86_64 16/120 Verifying : libXau-devel-1.0.9-8.el9.x86_64 17/120 Verifying : libXcomposite-devel-0.4.5-7.el9.x86_64 18/120 Verifying : libXcursor-devel-1.2.0-7.el9.x86_64 19/120 Verifying : libXdamage-devel-1.1.5-7.el9.x86_64 20/120 Verifying : libXext-devel-1.3.4-8.el9.x86_64 21/120 Verifying : libXfixes-devel-5.0.3-16.el9.x86_64 22/120 Verifying : libXft-devel-2.3.3-8.el9.x86_64 23/120 Verifying : libXi-devel-1.7.10-8.el9.x86_64 24/120 Verifying : libXinerama-devel-1.1.4-10.el9.x86_64 25/120 Verifying : libXrandr-devel-1.5.2-8.el9.x86_64 26/120 Verifying : libXrender-devel-0.9.10-16.el9.x86_64 27/120 Verifying : libXtst-devel-1.2.3-16.el9.x86_64 28/120 Verifying : libblkid-devel-2.37.4-9.el9.x86_64 29/120 Verifying : libdatrie-devel-0.2.13-4.el9.x86_64 30/120 Verifying : libepoxy-devel-1.5.5-4.el9.x86_64 31/120 Verifying : libffi-devel-3.4.2-7.el9.x86_64 32/120 Verifying : libglvnd-core-devel-1:1.3.4-1.el9.x86_64 33/120 Verifying : libglvnd-devel-1:1.3.4-1.el9.x86_64 34/120 Verifying : libicu-devel-67.1-9.el9.x86_64 35/120 Verifying : libmount-devel-2.37.4-9.el9.x86_64 36/120 Verifying : libpng-devel-2:1.6.37-12.el9.x86_64 37/120 Verifying : libselinux-devel-3.4-3.el9.x86_64 38/120 Verifying : libsepol-devel-3.4-1.1.el9.x86_64 39/120 Verifying : libthai-devel-0.1.28-8.el9.x86_64 40/120 Verifying : libtiff-devel-4.4.0-2.el9.x86_64 41/120 Verifying : libxcb-devel-1.13.1-9.el9.x86_64 42/120 Verifying : libxkbcommon-devel-1.0.3-4.el9.x86_64 43/120 Verifying : libxml2-devel-2.9.13-2.el9.x86_64 44/120 Verifying : pango-devel-1.48.7-2.el9.x86_64 45/120 Verifying : pcre-cpp-8.44-3.el9.3.x86_64 46/120 Verifying : pcre-devel-8.44-3.el9.3.x86_64 47/120 Verifying : pcre-utf16-8.44-3.el9.3.x86_64 48/120 Verifying : pcre-utf32-8.44-3.el9.3.x86_64 49/120 Verifying : pcre2-devel-10.40-2.el9.x86_64 50/120 Verifying : perl-Filter-2:1.60-4.el9.x86_64 51/120 Verifying : perl-encoding-4:3.00-462.el9.x86_64 52/120 Verifying : perl-open-1.12-479.el9.noarch 53/120 Verifying : pixman-devel-0.40.0-5.el9.x86_64 54/120 Verifying : sysprof-capture-devel-3.40.1-3.el9.x86_64 55/120 Verifying : wayland-devel-1.19.0-4.el9.x86_64 56/120 Verifying : xorg-x11-proto-devel-2021.4-2.el9.noarch 57/120 Verifying : atkmm-devel-2.28.2-2.el9.x86_64 58/120 Verifying : cairomm-devel-1.14.2-10.el9.x86_64 59/120 Verifying : gdk-pixbuf2-devel-2.42.6-2.el9.x86_64 60/120 Verifying : glibmm24-devel-2.66.1-1.el9.x86_64 61/120 Verifying : gtk3-devel-3.24.31-2.el9.x86_64 62/120 Verifying : libsigc++20-devel-2.10.7-2.el9.x86_64 63/120 Verifying : pangomm-devel-2.46.1-1.el9.x86_64 64/120 Verifying : dbus-daemon-1:1.12.20-6.el9.x86_64 65/120 Verifying : dbus-daemon-1:1.12.20-5.el9.x86_64 66/120 Verifying : fontconfig-2.14.0-1.el9.x86_64 67/120 Verifying : fontconfig-2.13.94-2.el9.x86_64 68/120 Verifying : fribidi-1.0.10-6.el9.2.x86_64 69/120 Verifying : fribidi-1.0.10-6.el9.x86_64 70/120 Verifying : harfbuzz-icu-2.7.4-8.el9.x86_64 71/120 Verifying : harfbuzz-icu-2.7.4-5.el9.x86_64 72/120 Verifying : libtiff-4.4.0-2.el9.x86_64 73/120 Verifying : libtiff-4.2.0-3.el9.x86_64 74/120 Verifying : pcre2-utf16-10.40-2.el9.x86_64 75/120 Verifying : pcre2-utf16-10.37-5.el9_0.x86_64 76/120 Verifying : pcre2-utf32-10.40-2.el9.x86_64 77/120 Verifying : pcre2-utf32-10.37-5.el9_0.x86_64 78/120 Verifying : python3-libselinux-3.4-3.el9.x86_64 79/120 Verifying : python3-libselinux-3.3-2.el9.x86_64 80/120 Verifying : dbus-common-1:1.12.20-6.el9.noarch 81/120 Verifying : dbus-common-1:1.12.20-5.el9.noarch 82/120 Verifying : dbus-libs-1:1.12.20-6.el9.x86_64 83/120 Verifying : dbus-libs-1:1.12.20-5.el9.x86_64 84/120 Verifying : dbus-tools-1:1.12.20-6.el9.x86_64 85/120 Verifying : dbus-tools-1:1.12.20-5.el9.x86_64 86/120 Verifying : freetype-2.10.4-9.el9.x86_64 87/120 Verifying : freetype-2.10.4-6.el9.x86_64 88/120 Verifying : harfbuzz-2.7.4-8.el9.x86_64 89/120 Verifying : harfbuzz-2.7.4-5.el9.x86_64 90/120 Verifying : libblkid-2.37.4-9.el9.x86_64 91/120 Verifying : libblkid-2.37.4-3.el9.x86_64 92/120 Verifying : libfdisk-2.37.4-9.el9.x86_64 93/120 Verifying : libfdisk-2.37.4-3.el9.x86_64 94/120 Verifying : libmount-2.37.4-9.el9.x86_64 95/120 Verifying : libmount-2.37.4-3.el9.x86_64 96/120 Verifying : libselinux-3.4-3.el9.x86_64 97/120 Verifying : libselinux-3.3-2.el9.x86_64 98/120 Verifying : libselinux-utils-3.4-3.el9.x86_64 99/120 Verifying : libselinux-utils-3.3-2.el9.x86_64 100/120 Verifying : libsepol-3.4-1.1.el9.x86_64 101/120 Verifying : libsepol-3.3-2.el9.x86_64 102/120 Verifying : libsmartcols-2.37.4-9.el9.x86_64 103/120 Verifying : libsmartcols-2.37.4-3.el9.x86_64 104/120 Verifying : libuuid-2.37.4-9.el9.x86_64 105/120 Verifying : libuuid-2.37.4-3.el9.x86_64 106/120 Verifying : libxml2-2.9.13-2.el9.x86_64 107/120 Verifying : libxml2-2.9.13-1.el9_0.1.x86_64 108/120 Verifying : pcre2-10.40-2.el9.x86_64 109/120 Verifying : pcre2-10.37-5.el9_0.x86_64 110/120 Verifying : pcre2-syntax-10.40-2.el9.noarch 111/120 Verifying : pcre2-syntax-10.37-5.el9_0.noarch 112/120 Verifying : python3-libxml2-2.9.13-2.el9.x86_64 113/120 Verifying : python3-libxml2-2.9.13-1.el9_0.1.x86_64 114/120 Verifying : util-linux-2.37.4-9.el9.x86_64 115/120 Verifying : util-linux-2.37.4-3.el9.x86_64 116/120 Verifying : util-linux-core-2.37.4-9.el9.x86_64 117/120 Verifying : util-linux-core-2.37.4-3.el9.x86_64 118/120 Verifying : util-linux-user-2.37.4-9.el9.x86_64 119/120 Verifying : util-linux-user-2.37.4-3.el9.x86_64 120/120 Upgraded: dbus-common-1:1.12.20-6.el9.noarch dbus-daemon-1:1.12.20-6.el9.x86_64 dbus-libs-1:1.12.20-6.el9.x86_64 dbus-tools-1:1.12.20-6.el9.x86_64 fontconfig-2.14.0-1.el9.x86_64 freetype-2.10.4-9.el9.x86_64 fribidi-1.0.10-6.el9.2.x86_64 harfbuzz-2.7.4-8.el9.x86_64 harfbuzz-icu-2.7.4-8.el9.x86_64 libblkid-2.37.4-9.el9.x86_64 libfdisk-2.37.4-9.el9.x86_64 libmount-2.37.4-9.el9.x86_64 libselinux-3.4-3.el9.x86_64 libselinux-utils-3.4-3.el9.x86_64 libsepol-3.4-1.1.el9.x86_64 libsmartcols-2.37.4-9.el9.x86_64 libtiff-4.4.0-2.el9.x86_64 libuuid-2.37.4-9.el9.x86_64 libxml2-2.9.13-2.el9.x86_64 pcre2-10.40-2.el9.x86_64 pcre2-syntax-10.40-2.el9.noarch pcre2-utf16-10.40-2.el9.x86_64 pcre2-utf32-10.40-2.el9.x86_64 python3-libselinux-3.4-3.el9.x86_64 python3-libxml2-2.9.13-2.el9.x86_64 util-linux-2.37.4-9.el9.x86_64 util-linux-core-2.37.4-9.el9.x86_64 util-linux-user-2.37.4-9.el9.x86_64 Installed: at-spi2-atk-devel-2.38.0-4.el9.x86_64 at-spi2-core-devel-2.40.3-1.el9.x86_64 atk-devel-2.36.0-5.el9.x86_64 atkmm-devel-2.28.2-2.el9.x86_64 brotli-1.0.9-6.el9.x86_64 brotli-devel-1.0.9-6.el9.x86_64 bzip2-devel-1.0.8-8.el9.x86_64 cairo-devel-1.17.4-7.el9.x86_64 cairo-gobject-devel-1.17.4-7.el9.x86_64 cairomm-devel-1.14.2-10.el9.x86_64 dbus-devel-1:1.12.20-6.el9.x86_64 fontconfig-devel-2.14.0-1.el9.x86_64 freetype-devel-2.10.4-9.el9.x86_64 fribidi-devel-1.0.10-6.el9.2.x86_64 gdk-pixbuf2-devel-2.42.6-2.el9.x86_64 glib2-devel-2.68.4-5.el9.x86_64 glibmm24-devel-2.66.1-1.el9.x86_64 graphite2-devel-1.3.14-9.el9.x86_64 gtk3-devel-3.24.31-2.el9.x86_64 harfbuzz-devel-2.7.4-8.el9.x86_64 libX11-devel-1.7.0-7.el9.x86_64 libXau-devel-1.0.9-8.el9.x86_64 libXcomposite-devel-0.4.5-7.el9.x86_64 libXcursor-devel-1.2.0-7.el9.x86_64 libXdamage-devel-1.1.5-7.el9.x86_64 libXext-devel-1.3.4-8.el9.x86_64 libXfixes-devel-5.0.3-16.el9.x86_64 libXft-devel-2.3.3-8.el9.x86_64 libXi-devel-1.7.10-8.el9.x86_64 libXinerama-devel-1.1.4-10.el9.x86_64 libXrandr-devel-1.5.2-8.el9.x86_64 libXrender-devel-0.9.10-16.el9.x86_64 libXtst-devel-1.2.3-16.el9.x86_64 libblkid-devel-2.37.4-9.el9.x86_64 libdatrie-devel-0.2.13-4.el9.x86_64 libepoxy-devel-1.5.5-4.el9.x86_64 libffi-devel-3.4.2-7.el9.x86_64 libglvnd-core-devel-1:1.3.4-1.el9.x86_64 libglvnd-devel-1:1.3.4-1.el9.x86_64 libicu-devel-67.1-9.el9.x86_64 libmount-devel-2.37.4-9.el9.x86_64 libpng-devel-2:1.6.37-12.el9.x86_64 libselinux-devel-3.4-3.el9.x86_64 libsepol-devel-3.4-1.1.el9.x86_64 libsigc++20-devel-2.10.7-2.el9.x86_64 libthai-devel-0.1.28-8.el9.x86_64 libtiff-devel-4.4.0-2.el9.x86_64 libxcb-devel-1.13.1-9.el9.x86_64 libxkbcommon-devel-1.0.3-4.el9.x86_64 libxml2-devel-2.9.13-2.el9.x86_64 pango-devel-1.48.7-2.el9.x86_64 pangomm-devel-2.46.1-1.el9.x86_64 pcre-cpp-8.44-3.el9.3.x86_64 pcre-devel-8.44-3.el9.3.x86_64 pcre-utf16-8.44-3.el9.3.x86_64 pcre-utf32-8.44-3.el9.3.x86_64 pcre2-devel-10.40-2.el9.x86_64 perl-Filter-2:1.60-4.el9.x86_64 perl-encoding-4:3.00-462.el9.x86_64 perl-open-1.12-479.el9.noarch pixman-devel-0.40.0-5.el9.x86_64 sysprof-capture-devel-3.40.1-3.el9.x86_64 wayland-devel-1.19.0-4.el9.x86_64 xorg-x11-proto-devel-2021.4-2.el9.noarch Complete!
Now return to your $HOME/Downloads directory and run the following command. You’ll notice that it installs and upgrades many more packages than you might expect.
sudo dnf install -y gtkmm30-devel-3.24.5-1.el9.x86_64.rpm
The log file for this is:
Display detailed console log →
Last metadata expiration check: 1:22:32 ago on Sun 20 Nov 2022 12:52:28 AM EST. Dependencies resolved. ================================================================================ Package Architecture Version Repository Size ================================================================================ Installing: gtkmm30-devel x86_64 3.24.5-1.el9 @commandline 605 k Transaction Summary ================================================================================ Install 1 Package Total size: 605 k Installed size: 4.7 M Downloading Packages: Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : gtkmm30-devel-3.24.5-1.el9.x86_64 1/1 Running scriptlet: gtkmm30-devel-3.24.5-1.el9.x86_64 1/1 Verifying : gtkmm30-devel-3.24.5-1.el9.x86_64 1/1 Installed: gtkmm30-devel-3.24.5-1.el9.x86_64 Complete!
All that done and you’ve only got the first of four dependencies resovled.
- Next, start with the libzip-devel package, which has a couple dependencies. Assuming you’re still in your $HOME/Downloads directory, you can run the following command to get the libzip-devel and its prerequisite packages for AlmaLinux 9:
wget https://repo.almalinux.org/almalinux/9/CRB/x86_64/os/Packages/libzip-devel-1.7.3-7.el9.x86_64.rpm wget https://repo.almalinux.org/almalinux/9/AppStream/x86_64/os/Packages/cmake-filesystem-3.20.2-7.el9.x86_64.rpm wget https://repo.almalinux.org/almalinux/9/AppStream/x86_64/os/Packages/libzip-1.7.3-7.el9.x86_64.rpm
You can run the prerequisites with the following command:
sudo dnf install -y cmake*.rpm libzip-1.7.3*.rpm
Now, you can run the libzip-devel package with this syntax:
sudo dnf install -y libzip-devel*.rpm
Having resolved the two dependencies, you can install the compression development kit. This completes the second step.
-
Next, you need to apply the proj_devel package for AlmaLinux 9:
wget https://download-ib01.fedoraproject.org/pub/epel/9/Everything/x86_64/Packages/p/proj-devel-8.2.0-1.el9.x86_64.rpm
Now, you can run the proj-devel package with this syntax:
sudo dnf install -y proj-devel-8.2.0-1.el9.x86_64.rpm
-
Next, you need to apply the swig packages for AlmaLinux 9:
wget https://repo.almalinux.org/almalinux/9/CRB/x86_64/os/Packages/swig-4.0.2-8.el9.x86_64.rpm wget https://repo.almalinux.org/almalinux/9/CRB/x86_64/os/Packages/swig-doc-4.0.2-8.el9.noarch.rpm wget https://repo.almalinux.org/almalinux/9/CRB/x86_64/os/Packages/swig-gdb-4.0.2-8.el9.x86_64.rpm
sudo dnf install -y swig*.rpm
-
Next, you need to apply the mysql-community-workbench packages for AlmaLinux 9. The download instructions where provided above. You apply the packages with the following command.
sudo dnf install -y mysql-workbench-community-8.0.31-1.el9.x86_64.rpm
Display detailed console log →
Last metadata expiration check: 1:06:04 ago on Sun 20 Nov 2022 03:28:30 PM EST. Dependencies resolved. ================================================================================ Package Arch Version Repository Size ================================================================================ Installing: mysql-workbench-community x86_64 8.0.31-1.el9 @commandline 39 M Upgrading: proj x86_64 8.2.0-1.el9 epel 2.5 M Transaction Summary ================================================================================ Install 1 Package Upgrade 1 Package Total size: 41 M Total download size: 2.5 M Downloading Packages: proj-8.2.0-1.el9.x86_64.rpm 388 kB/s | 2.5 MB 00:06 -------------------------------------------------------------------------------- Total 354 kB/s | 2.5 MB 00:07 Extra Packages for Enterprise Linux 9 - x86_64 1.6 MB/s | 1.6 kB 00:00 Importing GPG key 0x3228467C: Userid : "Fedora (epel9) <epel@fedoraproject.org>" Fingerprint: FF8A D134 4597 106E CE81 3B91 8A38 72BF 3228 467C From : /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-9 Key imported successfully Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Upgrading : proj-8.2.0-1.el9.x86_64 1/3 Installing : mysql-workbench-community-8.0.31-1.el9.x86_64 2/3 Running scriptlet: mysql-workbench-community-8.0.31-1.el9.x86_64 2/3 Cleanup : proj-4.8.0-4.el7.x86_64 3/3 Running scriptlet: proj-4.8.0-4.el7.x86_64 3/3 Verifying : mysql-workbench-community-8.0.31-1.el9.x86_64 1/3 Verifying : proj-8.2.0-1.el9.x86_64 2/3 Verifying : proj-4.8.0-4.el7.x86_64 3/3 Upgraded: proj-8.2.0-1.el9.x86_64 Installed: mysql-workbench-community-8.0.31-1.el9.x86_64 Complete!
After applying the dependent and mysql-community-workbench packages, you can launch MySQL Workbench by clicking the Activities symbol in the upper left hand corner. That displays the nine-dots for Show Applications icon. Click the Show Applications icon and choose the MySQL Workbench icon to launch MySQL Workbench.
You’ll be prompted with the following dialog. Just click Don’t show this message again checkbox and the OK button to launch MySQL Workbench.
As always, I hope this helps those looking to solve a real problem.
AlmaLinux MySQL+Perl
A quick primer on Perl programs connecting to the MySQL database. It’s another set of coding examples for the AlmaLinux instance that I’m building for students. This one demonstrates basic Perl programs, connecting to MySQL, returning data sets by reference and position, dynamic queries, and input parameters to dynamic queries.
- Naturally, a hello.pl is a great place to start:
#!/usr/bin/perl # Hello World program. print "Hello World!\n";
After setting the permissions to -rwxr-xr-x. with this command:
chmod 755 hello.pl
You call it like this from the Command-Line Interface (CLI):
./hello.pl
It prints:
Hello World! - Next, a connect.pl program lets us test the Perl::DBI connection to the MySQL database.
#!/usr/bin/perl # Import libraries. use strict; use warnings; use v5.10; # for say() function use DBI; # Print with say() function message. say "Perl MySQL Connect Attempt."; # MySQL data source name should have a valid database as the # third argument; this uses the sakila demo database. my $dsn = "DBI:mysql:sakila"; # Local variables to build the connection string. my $username = "student"; my $password = "student"; # Set arguments for MySQL database error management. my %attr = ( PrintError=>0, # turn off error reporting via warn() RaiseError=>1); # turn on error reporting via die() # Create connction with a data source name, user name and password. my $dbh = DBI->connect($dsn,$username,$password, \%attr); # Print with say() function valid connection message. say "Connected to the MySQL database.";
After setting the permissions to -rwxr-xr-x. you call it with this CLI command:
./connect.pl
It prints:
Perl MySQL Connect Attempt. Connected to the MySQL database.
- After connecting to the database lets query a couple columns by reference notation in a static.pl program. This one just returns the result of the MySQL version() and database() functions.
#!/usr/bin/perl # Import libraries. use strict; use warnings; use v5.10; # for say() function use DBI; # Print with say() function message. say "Perl MySQL Connect Attempt."; # MySQL data source name must have a valid database as the # third argument; this uses the sakila demo database. my $dsn = "DBI:mysql:sakila"; # Local variables to build the connection string. my $username = "student"; my $password = "student"; # Set arguments for MySQL database error management. my %attr = ( PrintError=>0, # turn off error reporting via warn() RaiseError=>1); # turn on error reporting via die() # Create connction with a data source name, user name and password. my $dbh = DBI->connect($dsn,$username,$password, \%attr); # Creaet a static SQL statement or query. my $sth = $dbh->prepare("SELECT version() AS version \ , database() AS db_name"); # Execute the static statement. $sth->execute() or die "Execution failed: $dbh->errstr()"; # Read data and print by reference. print "----------------------------------------\n"; while (my $ref = $sth->fetchrow_hashref()) { print "MySQL Version: $ref->{'version'}\nMySQL Database: $ref->{'db_name'}\n"; } print "----------------------------------------\n"; # Close the statement. $sth->finish; # Disconnect from database connection. $dbh->disconnect(); # Print with say() function valid connection message. say "Connected to the MySQL database.";
After setting the permissions to -rwxr-xr-x. you call it with this CLI command:
./static.pl
It prints:
Perl MySQL Connect Attempt. ---------------------------------------- MySQL Version: 8.0.30 MySQL Database: sakila ---------------------------------------- Connected to the MySQL database.
- After connecting to the database and securing variables by reference notation, lets return the value as an array of rows in a columns.pl program. This one just returns data from the film table of the sakila database. It is a static query because all the values are contained inside the SQL statement.
#!/usr/bin/perl # Import libraries. use strict; use warnings; use v5.10; # for say() function use DBI; # Print with say() function message. say "Perl MySQL Connect Attempt."; # MySQL data source name must have a valid database as the # third argument; this uses the sakila demo database. my $dsn = "DBI:mysql:sakila"; # Local variables to build the connection string. my $username = "student"; my $password = "student"; # Set arguments for MySQL database error management. my %attr = ( PrintError=>0, # turn off error reporting via warn() RaiseError=>1); # turn on error reporting via die() # Create connction with a data source name, user name and password. my $dbh = DBI->connect($dsn,$username,$password, \%attr); # Creaet a static SQL statement or query. my $sth = $dbh->prepare("SELECT title \ , release_year \ , rating \ FROM film \ WHERE title LIKE 'roc%'"); # Execute the static statement. $sth->execute() or die "Execution failed: $dbh->errstr()"; # Read data and print by comma-delimited row position. print "----------------------------------------\n"; while (my @row = $sth->fetchrow_array()) { print join(", ", @row), "\n"; } print "----------------------------------------\n"; # Close the statement. $sth->finish; # Disconnect from database connection. $dbh->disconnect(); # Print with say() function valid connection message. say "Connected to the MySQL database.";
After setting the permissions to -rwxr-xr-x. you call it with this CLI command:
./columns.pl
It prints:
Perl MySQL Connect Attempt. ---------------------------------------- ROCK INSTINCT, 2006, G ROCKETEER MOTHER, 2006, PG-13 ROCKY WAR, 2006, PG-13 ---------------------------------------- Connected to the MySQL database.
- After connecting to the database and securing variables by reference notation, lets return the value as an array of rows in a dynamic.pl program. This one just returns data from the film table of the sakila database. It is a dynamic query because a string passed to the execute method and that value is bound to a ? placeholder in the SQL statement.
#!/usr/bin/perl # Import libraries. use strict; use warnings; use v5.10; # for say() function use DBI; # Print with say() function message. say "Perl MySQL Connect Attempt."; # MySQL data source name must have a valid database as the # third argument; this uses the sakila demo database. my $dsn = "DBI:mysql:sakila"; # Local variables to build the connection string. my $username = "student"; my $password = "student"; # Set arguments for MySQL database error management. my %attr = ( PrintError=>0, # turn off error reporting via warn() RaiseError=>1); # turn on error reporting via die() # Create connction with a data source name, user name and password. my $dbh = DBI->connect($dsn,$username,$password, \%attr); # Creaet a static SQL statement or query. my $sth = $dbh->prepare("SELECT title \ , release_year \ , rating \ FROM film \ WHERE title LIKE CONCAT(?,'%')"); # Execute the dynamic statement by providing an input parameter. $sth->execute('roc') or die "Execution failed: $dbh->errstr()"; # Read data and print by comma-delimited row position. print "----------------------------------------\n"; while (my @row = $sth->fetchrow_array()) { print join(", ", @row), "\n"; } print "----------------------------------------\n"; # Close the statement. $sth->finish; # Disconnect from database connection. $dbh->disconnect(); # Print with say() function valid connection message. say "Connected to the MySQL database.";
After setting the permissions to -rwxr-xr-x. you call it with this CLI command:
./dynamic.pl
It prints:
Perl MySQL Connect Attempt. ---------------------------------------- ROCK INSTINCT, 2006, G ROCKETEER MOTHER, 2006, PG-13 ROCKY WAR, 2006, PG-13 ---------------------------------------- Connected to the MySQL database.
- After connecting to the database and securing variables by reference notation, lets return the value as an array of rows in a input.pl program. This one just returns data from the film table of the sakila database. It is a dynamic query because an input parameter is passed to a local variable and the local variable is bound to a ? placeholder in the SQL statement.
#!/usr/bin/perl # Import libraries. use strict; use warnings; use v5.10; # for say() function use DBI; # Get the index value of the maximum argument in the # argument. my $argc = $#ARGV; # Accept first argument value as parameter. my $param = $ARGV[$argc]; # Verify variable value assigned. if (not defined $param) { die "Need parameter value.\n"; } # Print with say() function message. say "Perl MySQL Connect Attempt."; # MySQL data source name must have a valid database as the # third argument; this uses the sakila demo database. my $dsn = "DBI:mysql:sakila"; # Local variables to build the connection string. my $username = "student"; my $password = "student"; # Set arguments for MySQL database error management. my %attr = ( PrintError=>0, # turn off error reporting via warn() RaiseError=>1); # turn on error reporting via die() # Create connction with a data source name, user name and password. my $dbh = DBI->connect($dsn,$username,$password, \%attr); # Creaet a static SQL statement or query. my $sth = $dbh->prepare("SELECT title \ , release_year \ , rating \ FROM film \ WHERE title LIKE CONCAT(?,'%')"); # Execute the static statement. $sth->execute($param) or die "Execution failed: $dbh->errstr()"; # Read data and print by comma-delimited row position. print "----------------------------------------\n"; while (my @row = $sth->fetchrow_array()) { print join(", ", @row), "\n"; } print "----------------------------------------\n"; # Close the statement. $sth->finish; # Disconnect from database connection. $dbh->disconnect(); # Print with say() function valid connection message. say "Connected to the MySQL database.";
After setting the permissions to -rwxr-xr-x. you call it with this CLI command:
./input.pl ta
It prints:
Perl MySQL Connect Attempt. ---------------------------------------- TADPOLE PARK, 2006, PG TALENTED HOMICIDE, 2006, PG TARZAN VIDEOTAPE, 2006, PG-13 TAXI KICK, 2006, PG-13 ---------------------------------------- Connected to the MySQL database.
I think these examples cover most of the basic elements of writing Perl against the MySQL database. If I missed something you think would be useful, please advise. As always, I hope this helps those working with the MySQL and Perl products.
