Archive for the ‘MySQL 8’ Category
Is SQL Programming

Is SQL, or Structured Query Language, a programming language? That’s a great question! A question that many answer with emphasis: “No, SQL is not a programming language!” There are some who answer yes; and they usually qualify that answer with something like: “SQL is a programming language designed to communicate with relational databases.”
It strikes me that those saying “yes” are saying that SQL is only a collection of interface methods to read from and write to a database engine. Those saying SQL is not a programming language often qualify that a programming language must have conditional logic and iterative structures, which don’t exist in SQL.
There’s a third group that are fence sitters. They decline to say whether SQL is a programming language, but they also say individuals who only write SQL aren’t programmers. That’s a bit harsh from my perspective.
Before determining whether SQL is a programming language let’s define a programming language. Let’s define a programming language as a collection of lexical units, or building blocks, that build program units. Lexical units are typically organized as delimiters, identifiers, literals, and comments:
- Delimiters include single or double quotes to identify strings and operators that let you assign and compare values.
- Identifiers are reserved words, keywords, predefined identifiers (like data type names), user-defined variables, subroutines, or types.
- Literals are typically numbers and strings, where some strings qualify as dates because they implement a default format mask to convert strings to dates or date-times.
- Comments are simply delimited text that the program ignores but the programmer uses.
That means a programming language must let you define a variable, assign a value to a variable, iterate across a set of values, and make conditional statements. SQL meets these four conditions, but it does, as a set-programming language, qualify all variables as lists of tuples. Though it is possible to have variables with zero to many elements and one to many members in any given tuple. That means you can assign a literal value to to a one-element list with a single-member tuple, like you would a string or integer to a variable of that type.
As Kris Köhntopp commented, computer science defines a programming language as Turing Complete. As his comment qualifies and the Wikipedia page explains: “Turing completeness in declarative SQL is implemented through recursive common table expressions. Unsurprisingly, procedural extensions to SQL (PLSQL, etc.) are also Turing-complete.” While PostgreSQL introduces recursive query syntax through CTEs, it recently added the search and cycle feature in PostgreSQL 14. The recursive query feature has existed in the Oracle database since Oracle 8, but their documentation calls them hierarchical queries. I wrote a quick a tutorial on hierarchical queries in 2008.
For clarity, define and declare are two words that give grief to some newbies. Let’s qualify what they mean. Declare means to give a variable a name and data type. Define means to declare a variable and assign it a value. Another word for assigning a variable is initializing it. Unassigned variables are automatically assigned a default value or a null dependent on the programming language.
Let’s first declare a local variable, assign it to variable, and display the variable. The following example uses Node.js to define the input variable, assign the input variable to the display variable, and then print the display variable to console. Node.js requires that you assign an empty string to the display variable to define it as a string otherwise its type would be undefined, which is common behavior in dynamically typed languages.
/* Declare the display variable as a string. */ var display = "" /* Define the input variable. */ var input = "Hello World!" /* Assign the input variable contents to the display variable. */ display = input /* Print the display variable contents to console. */ console.log(display) |
It prints:
Hello World! |
Let’s write the same type of program in MySQL. Like the Node.js, there are implementation differences. The biggest difference in MySQL or other relational databases occurs because SQL is a declarative set-based language. That means every variable is a collection of a record structure . You can only mimic a scalar or primitive data type variable by creating a record structure with a single member.
In the case below, there are four processing steps:
- The ‘Hello World!’ literal value is assigned to an input variable.
- The SELECT-list (or comma-delimited set of values in the SELECT clause) is assigned like a tuple to the struct collection variable by treating the query of the literal value as an expression.
- The FROM clause returns the struct collection as the data set or as a derived table.
- The topmost SELECT clause evaluates the struct collection row-by-row, like a loop, and assigns the input member to a display variable.
The query is:
SELECT struct.input AS display FROM (SELECT 'Hello World!' AS input) struct; |
Since the struct collection contains only one element, it displays the original literal value one time, like
+--------------+ | display | +--------------+ | Hello World! | +--------------+ 1 row in set (0.00 sec) |
Let’s update the SQL syntax to the more readable, ANSI 1999 and forward, syntax with a Common Table Expression (CTE). CTEs are implemented by the WITH clause.
WITH struct AS (SELECT 'Hello World!' AS input) SELECT struct.input AS display FROM struct; |
The best thing about CTE values they run one-time and are subsequently available anywhere in your query, subqueries, or correlated subqueries. In short, there’s never an excuse to write a subquery twice in the same query.
Let’s look at loops and if-statements. Having established that we can assign a literal to a variable, re-assign the value from one variable to another, and then display the new variable, let’s assign a set of literal values to an array variable. As before, let’s use Node.js to structure the initial problem.
The program now assigns an array of strings to the input variable, uses a for-loop to read the values from the input array, and uses an if-statement with a regular expression evaluation. The if-statement determines which of the array value meets the condition by using a negating logical expression. That’s because the search() function returns a 0 or greater value when the needle value is found in the string and a -1 when not found. After validating that the needle variable value is found in an input string, the input value is assigned to the display variable.
/* Declare the display variable as a string. */ var display = "" /* Declare a lookup variable. */ var needle = "Goodbye" /* Define the input variable as an array of strings. */ var input = ["Hello World!" ,"Goodbye, Cruel World!" ,"Good morning, too early ..."] /* Read through an array and assign the value that meets * the condition to the display variable. */ for (i = 0; i < input.length; i++) if (!(input[i].search(needle) < 0)) display = input[i] /* Print the display variable contents to console. */ console.log(display) |
Then, it prints the display value:
Goodbye, Cruel World! |
To replicate the coding approach in a query, there must be two CTEs. The needle CTE assigns a literal value of ‘goodbye’ to a one-element collection of a single-member tuple variable. The struct CTE creates a collection of strings by using the UNION ALL operator to append three unique tuples instead of one tuple as found in the early example.
The needle CTE returns a one-element collection of a single-member tuple variable. The struct CTE returns a three-element collection of a single-member tuple, which mimics an array of strings. The needle and struct CTEs return distinct variables with different data types. A cross join operation between the two CTEs puts their results together into the same context. It returns a Cartesian product that:
- Adds a single-row tuples to each row of the query’s result set or derived table.
- Adds a multiple-tuples to each row of the query’s result set or derived table by creating copies of each row (following the Cartesian set theory which multiplies rows and adds columns).
In this case, the Cartesian join adds a one-element needle CTE value to each element, or row, returned by the multiple-element struct CTE and produces the following derived table:
+-----------------------------+---------+ | display | lookup | +-----------------------------+---------+ | Hello World! | goodbye | | Goodbye, cruel world! | goodbye | | Good morning, too early ... | goodbye | +-----------------------------+---------+ 3 rows in set (0.00 sec) |
The following query reads through the CTE collection like a loop and filters out any invalid input values. It uses the MySQL regular expression like function in the WHERE clause, which acts as a conditional or if-statement.
WITH needle AS (SELECT 'goodbye' AS lookup) , struct AS (SELECT 'Hello World!' AS input UNION ALL SELECT 'Goodbye, cruel world!' AS input UNION ALL SELECT 'Good morning, too early ...' AS input) SELECT struct.input AS display FROM struct CROSS JOIN needle WHERE REGEXP_LIKE(struct.input, CONCAT('^.*',needle.lookup,'.*$'),'i'); |
It returns the one display value that meets the criteria:
+-----------------------+ | display | +-----------------------+ | Goodbye, cruel world! | +-----------------------+ 1 row in set (0.00 sec) |
The comparisons of the imperative programming approach in Node.js and declarative programming approach should have established that SQL has all the elements of a programming language. That is, SQL has variable declaration and assignment and both iterative and conditional statements. SQL also has different styles for implementing variable declaration and the examples covered subqueries and CTEs with cross joins placing variables in common scope.
Comparative Approaches:
Next, let’s examine a problem that a programmer might encounter when they think SQL only queries or inserts, updates, or deletes single rows. With that perspective of SQL there’s often a limited perspective on how to write queries. Developers with this skill set level typically write only basic queries, which may include inner and outer joins and some aggregation statements.
Let’s assume the following for this programming assignment:
- A sale table as your data source, and
- A requirement to display the type, number, pre-tax sale amount, and percentage by type.
The sale table definition:
+------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+--------------+------+-----+---------+----------------+ | sale_id | int unsigned | NO | PRI | NULL | auto_increment | | item_desc | varchar(20) | YES | | NULL | | | unit_price | decimal(8,2) | YES | | NULL | | | serial_no | varchar(10) | YES | | NULL | | +------------+--------------+------+-----+---------+----------------+ |
A basic Node.js program may contain a SQL query that returns the item_desc and unit_price columns while counting the number of serial_no rows and summing the unit_price amounts (that assumes no discount sales, after all its Apple). That type of query leaves calculating the total amount of sales and percentage by type to the Node.js program.
const mysql = require('mysql') const connection = mysql.createConnection({ host: 'localhost', user: 'student', password: 'student', database: 'studentdb' }) connection.connect((err) => { if (err) throw err else { console.log('Connected to MySQL Server!\n') connection.query("SELECT s.item_desc " + ", s.unit_price " + ", COUNT(s.serial_no) AS quantity_sold " + ", SUM(s.unit_price) AS sales " + "FROM sale s " + "GROUP BY s.item_desc " + ", s.unit_price", function (err, result) { if (err) throw err else { // Prints the index value in the RowDataPacket. console.log(result) connection.end() }})} }) |
This program would return a JSON structure, like:
[ RowDataPacket { item_desc: 'MacBook Pro 16', unit_price: 2499, quantity_sold: 16, sales: 39984 }, ... RowDataPacket { item_desc: 'MacBook Air M1', unit_price: 999, quantity_sold: 22, sales: 21978 } ] |
While the remaining JavaScript code isn’t difficult to write, it’s unnecessary effort if the developer knew SQL well enough to program in it. The developer could simply re-write the query like the following and return the percentage by type value in the base JSON structure.
WITH sales AS (SELECT SUM(unit_price) AS total FROM sale) SELECT s.item_desc , s.unit_price , COUNT(s.serial_no) AS quantity_sold , SUM(s.unit_price) AS sales , CONCAT(FORMAT((s.unit_price * COUNT(s.serial_no))/sales.total * 100,2),'%') AS percentage FROM sale s CROSS JOIN sales GROUP BY s.item_desc , s.unit_price , sales.total; |
The query uses the sales CTE to calculate and define a tuple with the total sales and adds a derived column calculating the percentage by type of device. It’s probably important to note that aggregation rules require you add the sales.total CTE tuple to the group by clause.
The new query returns this JSON list:
[ RowDataPacket { item_desc: 'MacBook Pro 16', unit_price: 2499, quantity_sold: 16, sales: 39984, percentage: '17.70%' }, ... RowDataPacket { item_desc: 'MacBook Air M1', unit_price: 999, quantity_sold: 22, sales: 21978, percentage: '9.73%' } ] |
The developer would get a complete JSON list when the new query replaces the old. It also would eliminate the need to write additional JavaScript to calculate the percentage by type of device.
Conclusions:
Leveraging the programming power of SQL is frequently possible in many frontend and backend programming solutions. However, the programming power of SQL is infrequently found in programming solutions. That leaves me to ask: “Is it possible that the almost systemic failure to leverage the programming capabilities of SQL is a result of biases by instructors and mentors to their own limited skill sets?” That likely might be true if their instructors and mentors held the belief that: “No, SQL is not a programming language!”
Candidly, folks that write SQL at the programming level almost always have concurrent mastery in two or more imperative programming languages. They’re probably the ones who say, “SQL is a programming language designed to communicate with relational databases.”
Who are those pesky fence sitters? You remember those, don’t you. They’re the ones who declined to take a position on whether SQL is a programming language. Are they the developers who are still learning, and those without an entrenched, preconceived, or learned bias? Or, do they wonder if SQL is Turing complete?
Node.js MySQL Error
While I blogged about how to setup Node.js and MySQL almost two years ago, it was interesting when a student ran into a problem. The student said they’d configured the environment but were unable to use Node.js to access MySQL.
The error is caused by this import statement:
const mysql = require('mysql') |
The student got the following error, which simply says that they hadn’t installed the Node.js package for MySQL driver.
internal/modules/cjs/loader.js:638 throw err; ^ Error: Cannot find module 'mysql' at Function.Module._resolveFilename (internal/modules/cjs/loader.js:636:15) at Function.Module._load (internal/modules/cjs/loader.js:562:25) at Module.require (internal/modules/cjs/loader.js:692:17) at require (internal/modules/cjs/helpers.js:25:18) at Object.<anonymous> (/home/student/Data/cit325/oracle-s/lib/Oracle12cPLSQLCode/Introduction/query.js:4:15) at Module._compile (internal/modules/cjs/loader.js:778:30) at Object.Module._extensions..js (internal/modules/cjs/loader.js:789:10) at Module.load (internal/modules/cjs/loader.js:653:32) at tryModuleLoad (internal/modules/cjs/loader.js:593:12) at Function.Module._load (internal/modules/cjs/loader.js:585:3) |
I explained they could fix the problem with the following two Node.js Package Manager (NPM) commands:
npm init --y npm install --save mysql |
The student was able to retest the code with success. The issue was simply that the Node.js couldn’t find the NPM MySQL module.
MySQL Partitioned Tables
MySQL Partitioned Tables
Learning Outcomes
- Learn about List Partitioning.
- Learn about Range Partitioning.
- Learn about Columns Partitioning.
- Learn about Hash Partitioning.
- Learn about Key Partitioning.
- Learn about Subpartitioning.
Lesson Material
MySQL supports partitioning of tables. It supports range, list, hash, and key partitioning. Range partitioning lets you partition based on column values that fall within given ranges. List partitioning lets you partition based on columns matching one of a set of discrete values. Hash partitioning lets you partition based on the return value from a user-defined expression (the result from a stored SQL/PSM function). Key partitioning performs like hash partitioning, but it lets a user select one or more columns from the set of columns in a table; a hash manages the selection process for you. A hash is a method of organizing keys to types of data, and hashes speed access to read and change data in tables.
Each of the following subsections discusses one of the supported forms of partitioning in MySQL. Naturally, there are differences between other databases and MySQL’s implementation.
List Partitioning
A MySQL list partition works by identifying a column that contains an integer value, the franchise_number in the following example. Partitioning clauses follow the list of columns and constraints and require a partitioning key to be in the primary key or indexed.
The following list partition works with literal numeric values. MySQL uses the IN keyword for list partitions. Note that there’s no primary key designated and an index is on the auto-incrementing surrogate key column. A complete example is provided to avoid confusion on how to index the partitioning key:
CREATE TABLE franchise ( franchise_id INT UNSIGNED AUTO_INCREMENT , franchise_number INT UNSIGNED , franchise_name VARCHAR(20) , city VARCHAR(20) , state VARCHAR(20) , index idx (franchise_id)) PARTITION BY LIST(franchise_number) ( PARTITION offshore VALUES IN (49,50) , PARTITION west VALUES IN (34,45,48) , PARTITION desert VALUES IN (46,47) , PARTITION rockies VALUES IN (38,41,42,44)); |
The inclusion of a PRIMARY KEY constraint on the franchise_id column would trigger an ERROR 1503 when the partitioning key isn’t the primary key. The reason for the error message is that a primary key implicitly creates a unique index, and that index would conflict with the partitioning by list instruction. The use of a non-unique idx index on the franchise_id column is required when you want to partition on a non-primary key column.
Range Partitioning
Range partitioning works only with an integer value or an expression that resolves to an integer against the primary key column. The limitation of the integer drives the necessity of choosing an integer column for range partitioning. You can’t define a range-partitioned table with a PRIMARY KEY constraint unless the primary key becomes your partitioning key, like
the one below.
CREATE TABLE ordering ( ordering_id INT UNSIGNED AUTO_INCREMENT , item_id INT UNSIGNED , rental_amount DECIMAL(15,2) , rental_date DATE , index idx (ordering_id)) PARTITION BY RANGE(item_id) ( PARTITION jan2011 VALUES LESS THAN (10000) , PARTITION feb2011 VALUES LESS THAN (20000) , PARTITION mar2011 VALUES LESS THAN (30000)); |
Range partitioning is best suited to large tables that you want to break into smaller pieces based on the integer column. You can also use stored functions that return integers as the partitioning key instead of the numeric literals shown. Few other options are available in MySQL.
Columns Partitioning
Columns partitioning is a new variant of range and list partitioning. It is included in MySQL 5.5 and forward. Both range and list partitioning work on an integer-based column (using TINYINT, SMALLINT, MEDIUMINT, INT [alias INTEGER], and BIGINT). Columns partitioning extends those models by expanding the possible data types for the partitioning column to include CHAR, VARCHAR, BINARY, and VARBINARY string data types, and DATE, DATETIME, or TIMESTAMP data types. You still can’t use other number data types such as DECIMAL and FLOAT. The TIMESTAMP data type is also available only in range partitions with the caveat that you use a UNIX_TIMESTAMP function, according to MySQL Bug 42849.
Hash Partitioning
Hash partitions ensure an even distribution of rows across a predetermined number of partitions. It is probably the easiest way to partition a table quickly to test the result of partitioning on a large table. You should base hash partitions on a surrogate or natural primary key.
The following provides a modified example of the ordering table:
CREATE TABLE ordering ( ordering_id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT , item_id INT UNSIGNED , rental_amount DECIMAL(15,2) , rental_date DATE) PARTITION BY HASH(ordering_id) PARTITIONS 8; |
This is the partitioning type that benefits from a PRIMARY KEY constraint because it automatically creates a unique index that can be used by the hash. A non-unique index such as the list partitioning example doesn’t work for a hash partition.
Key Partitioning
Key partitioning is valuable because you can partition on columns that aren’t integers. It performs along the line of hash partitioning, except the MySQL Server uses its own hashing expression.
CREATE TABLE orders_list ( order_list_id INT UNSIGNED AUTO_INCREMENT , customer_surname VARCHAR(30) , store_id INT UNSIGNED , salesperson_id INT UNSIGNED , order_date DATE , index idx (order_list_id)) PARTITION BY KEY (order_date) PARTITIONS 8; |
This is the only alternative when you want to partition by date ranges. Like the hash partition, it’s easy to deploy. The only consideration is the number of slices that you want to make of the data in the table.
Subpartitioning
The concept of subpartitioning is also known as composite partitioning. You can subpartition range or list partitions with a hash, linear hash, or linear key.
A slight change to the previously created ordering table is required to demonstrate composite partitioning: we’ll add a store_id column to the table definition. The following is an example of a range partition subpartitioned by a hash:
CREATE TABLE ordering INT UNSIGNED INT UNSIGNED DATE ( ordering_id INT UNSIGNED AUTO_INCREMENT , item_id INT UNSIGNED , store_id INT UNSIGNED , rental_amount DECIMAL(15,2) , rental_date DATE , index idx (ordering_id)) PARTITION BY RANGE(item_id) SUBPARTITION BY HASH(store_id) SUBPARTITIONS 4 ( PARTITION jan2011 VALUES LESS THAN (10000) , PARTITION feb2011 VALUES LESS THAN (20000) , PARTITION mar2011 VALUES LESS THAN (30000)); |
Composite partitioning is non-trivial and might require some experimentation to achieve optimal results. Plan on making a few tests of different scenarios before you deploy a solution.
MySQL Windows DSN
Almost a Ripley’s Believe It or Not. An prior data science student told me that his new IT department setup a Windows component that let him connect his Excel Spreadsheets to their production MySQL database without a password. Intrigued, I asked if it was a MySQL Connector/ODBC Data Source Configuration, or DSN (Data Source Name)?
He wasn’t sure, so I asked him to connect to PowerShell and run the following command:
Get-Item -Path Registry::HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC.INI\MySQL |
It returned something like this (substituting output from one of my test systems):
Hive: HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC.INI
Name Property
---- --------
MySQL Driver : C:\Program Files\MySQL\Connector ODBC 8.0\myodbc8w.dll
DESCRIPTION : MySQL ODBC Connector
SERVER : localhost
UID : student
PWD : student
DATABASE : studentdb
PORT : 3306 |
The student was stunned and concerned he was compromising his employer’s system security. I suggested he share the information with his IT department so they could provide a different approach for his access to the production database. His IT department immediately agreed. Unfortunately, he’s bummed he can’t simply access the data through Excel.
I told him they were welcome to use the MySQL Connect Dialog PowerShell solution that I wrote. It creates a minimal MySQL DSN and requires a manual password entry through the PowerShell Dialog box. I also suggested that they look into the PowerShell Excel Module.
I also suggested they develop a query only copy of the production database, or shift access to a data warehouse. Needless to say, it wasn’t a large corporation.
As always, I hope this helps others.
Fedora for macOS ARM64
I’m always updating VMs, and I was gratified to notice that there’s a Fedora arm64 ISO. If you’re interested in it, you can download the Live Workstation from here or the Fedora Server from here.
Unfortunately, I only have macOS running on i7 and i9 Intel Processors. It would be great to hear back how it goes for somebody one of the new Apple M1 chip.
I typically install the workstation version because it meets my needs to run MySQL and other native Linux development tools. However, the server version is also available. Fedora is a wonderful option, as a small footprint for testing things on my MacBookPro.
MySQL RegExp Default
We had an interesting set of questions regarding the REGEXP comparison operator in MySQL today in both sections of Database Design and Development. They wanted to know the default behavior.
For example, we built a little movie table so that we didn’t change their default sakila example database. The movie table was like this:
CREATE TABLE movie ( movie_id int unsigned primary key auto_increment , movie_title varchar(60)) auto_increment=1001; |
Then, I inserted the following rows:
INSERT INTO movie ( movie_title ) VALUES ('The King and I') ,('I') ,('The I Inside') ,('I am Legend'); |
Querying all results with this query:
SELECT * FROM movie; |
It returns the following results:
+----------+----------------+ | movie_id | movie_title | +----------+----------------+ | 1001 | The King and I | | 1002 | I | | 1003 | The I Inside | | 1004 | I am Legend | +----------+----------------+ 4 rows in set (0.00 sec) |
The following REGEXP returns all the rows because it looks for a case insensitive “I” anywhere in the string.
SELECT movie_title FROM movie WHERE movie_title REGEXP 'I'; |
The implicit regular expression is actually:
WHERE movie_title REGEXP '^.*I.*$'; |
It looks for zero-to-many of any character before and after the “I“. You can get any string beginning with an “I” with the “^I“; and any string ending with an “I” with the “I$“. Interestingly, the “I.+$” should only match strings with one or more characters after the “I“, but it returns:
+----------------+ | movie_title | +----------------+ | The King and I | | The I Inside | | I am Legend | +----------------+ 3 rows in set (0.00 sec) |
This caught me by surprise because I was lazy. As pointed out in the comment, it only appears to substitute a “.*“, or zero-to-many evaluation for the “.+” because it’s a case-insensitive search. There’s another lowercase “i” in the “The King and I” and that means the regular expression returns true because that “i” has one-or-more following characters. If we convert it to a case-sensitive comparison with the keyword binary, it works as expected because it ignores the lowercase “i“.
WHERE binary movie_title REGEXP '^.*I.*$'; |
This builds on my 10-year old post on Regular Expressions. As always, I hope these notes helps others discovering features and behaviors of the MySQL database, and Bill thanks for catching my error.
MySQL CSV Output
Saturday, I posted how to use Microsoft ODBC DSN to connect to MySQL. Somebody didn’t like the fact that the PowerShell program failed to write a *.csv file to disk because the program used the Write-Host command to write to the content of the query to the console.
I thought that approach was a better as an example. However, it appears that it wasn’t because not everybody knows simple redirection. The original program can transfer the console output to a file, like:
powershell .\MySQLODBC.ps1 > output.csv |
So, the first thing you need to do is add a parameter list, like:
2 3 4 | param ( [Parameter(Mandatory)][string]$fileName ) |
Anyway, it’s trivial to demonstrate how to modify the PowerShell program to write to a disk. You should also create a virtual PowerShell drive before writing the file. That’s because you can change the physical directory anytime you want with minimal changes to rest of your code’s file references.
You can create a PowerShell virtual drive with the following command:
7 8 | New-PSDrive -Name test -PSProvider FileSystem -Description 'Test area' ` -Root C:\Data\cit225\mysql\test |
but, it will write the following to console:
Name Used (GB) Free (GB) Provider Root CurrentLocation ---- --------- --------- -------- ---- --------------- test 0.00 28.74 FileSystem C:\Data\cit225\mysql\test |
You can suppress the console output with Microsoft’s version of redirection to the void (> /dev/null), which pipes (|) the standard out (stdout) to Out-Null, like:
7 8 | New-PSDrive -Name test -PSProvider FileSystem -Description 'Test area' ` -Root C:\Data\cit225\mysql\test | Out-Null |
Since the program may run before an output file has been created, or after its been created and removed, you need to check whether the file exists before attempting to remove it. PowerShell provides the Test-Path command to check for the existence of a file and the Remove-Item command to remove a file, like:
11 12 | if (Test-Path test:$fileName) { Remove-Item -Path test:$fileName } |
Then, you simply replace the Write-Host call in the other program with the Add-Content command:
Add-Content -Value $output -Path test:$fileName |
Now, the PowerShell script file writes the MySQL query’s output to an output.csv file. You can call the MySQLContact.ps1 script file with the following syntax:
powershell MySQLContact.ps1 output.csv |
In case these changes don’t make sense outside the scope of the full script, here is the rewritten script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | # Define parameter list for mandatory file name. param ( [Parameter(Mandatory)][string]$fileName ) # Define a PowerShell Virtual Drive. New-PSDrive -Name test -PSProvider FileSystem -Description 'Test area' ` -Root C:\Data\cit225\mysql\test | Out-Null # Remove the file only when it exists. if (Test-Path test:$fileName) { Remove-Item -Path test:$fileName } # Define a ODBC DSN connection string. $ConnectionString = 'DSN=MySQLODBC2' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT last_name " + ", first_name " + "FROM contact " + "ORDER BY 1, 2"; # Attempt to read SQL command. try { $row = $Command.ExecuteReader(); # Read while records are found. while ($row.Read()) { # Initialize output for each row. $output = "" # Navigate across all columns (only two in this example). for ($column = 0; $column -lt $row.FieldCount; $column += 1) { # Mechanic for comma-delimit between last and first name. if ($output.length -eq 0) { $output += $row[$column] } else { $output += ", " + $row[$column] } } # Write the output from the database to a file. Add-Content -Value $output -Path test:$fileName } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $row.Close() } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
While I understand you might want to go to this level of effort if you where building a formal cmdlet, I’m not convinced its worth the effort in an ordinary PowerShell script. However, I don’t like to leave a question unanswered.
MySQL ODBC DSN
This post explains and demonstrates how to install, configure, and use the MySQL’s ODBC libraries and a DSN (Data Source Name) to connect your Microsoft PowerShell programs to a locally or remotely installed MySQL database. After you’ve installed the MySQL ODBC library, use Windows search field to find the ODBC Data Sources dialog and run it as administrator.
There are four steps to setup, test, and save your ODBC Data Source Name (DSN) for MySQL. You can click on the images on the right to launch them in a more readable format or simply read the instructions.
MySQL ODBC Setup Steps
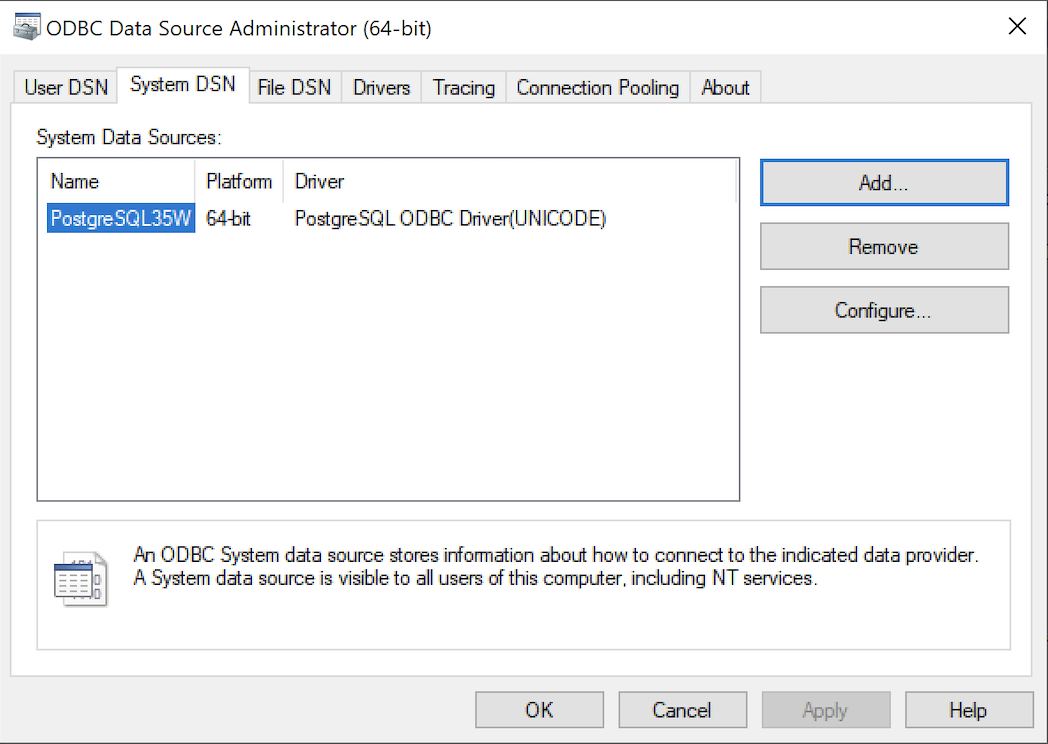
- Click the SystemDSN tab to see he view which is exactly like the User DSN tab. Click the Add button to start the workflow.
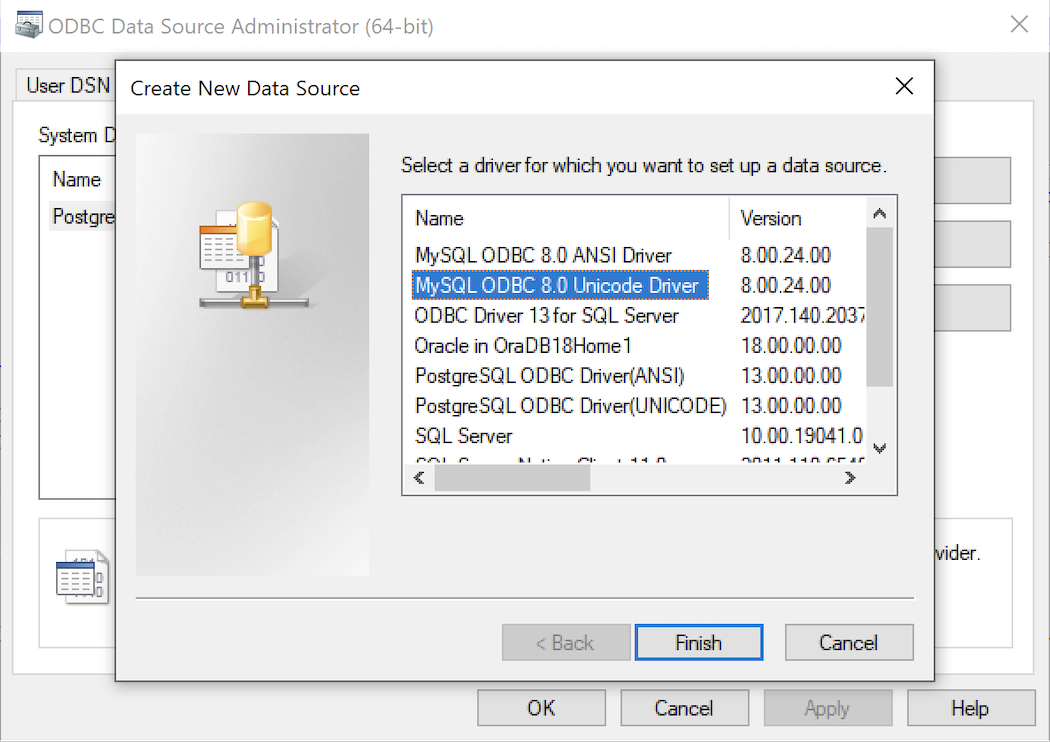
- The Create New Data Source dialog requires you select the MySQL ODBC Driver(UNICODE) option from the list and click the Finish button to proceed.
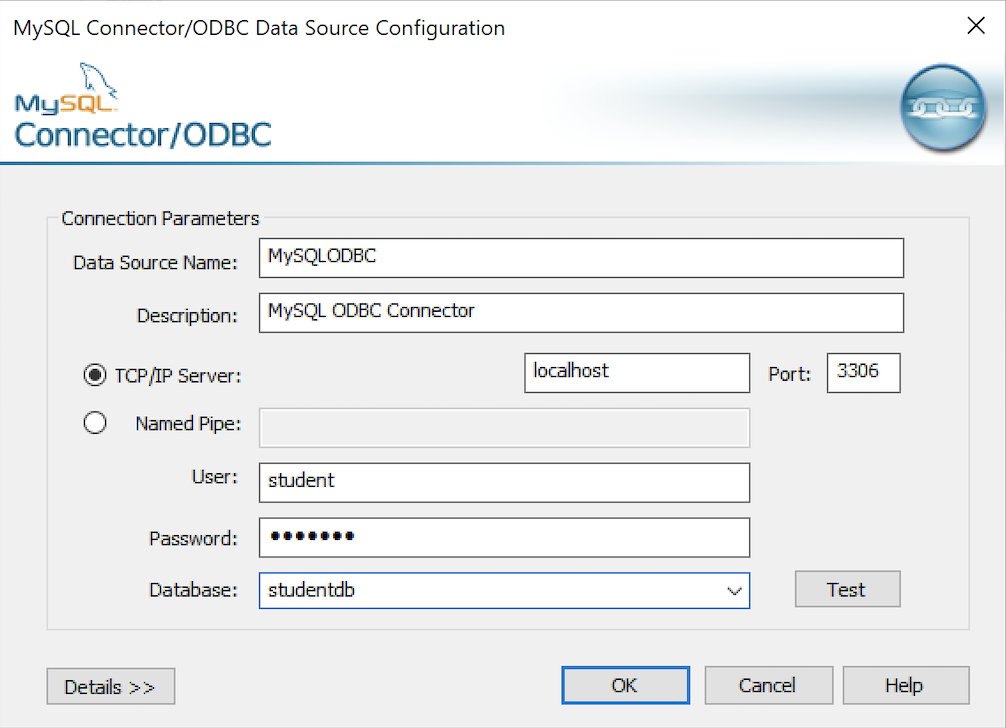
- The MySQL Unicode ODBC Driver Setup dialog should complete the prompts as follows below. If you opt for localhost as the server value and you have a DCHP IP address, make sure you’ve configured your hosts file in the C:\Windows\System32\drivers\etc directory. You should enter the following two lines in the hosts file:
127.0.0.1 localhost ::1 localhost
These are the string values you should enter in the MySQL Unicode ODBC Driver Setup dialog:
Data Source: MySQLODBC Database: studentdb Server: localhost User Name: student Description: MySQL ODBC Connector Port: 3306 Password: student
After you complete the entry, click the Test button.
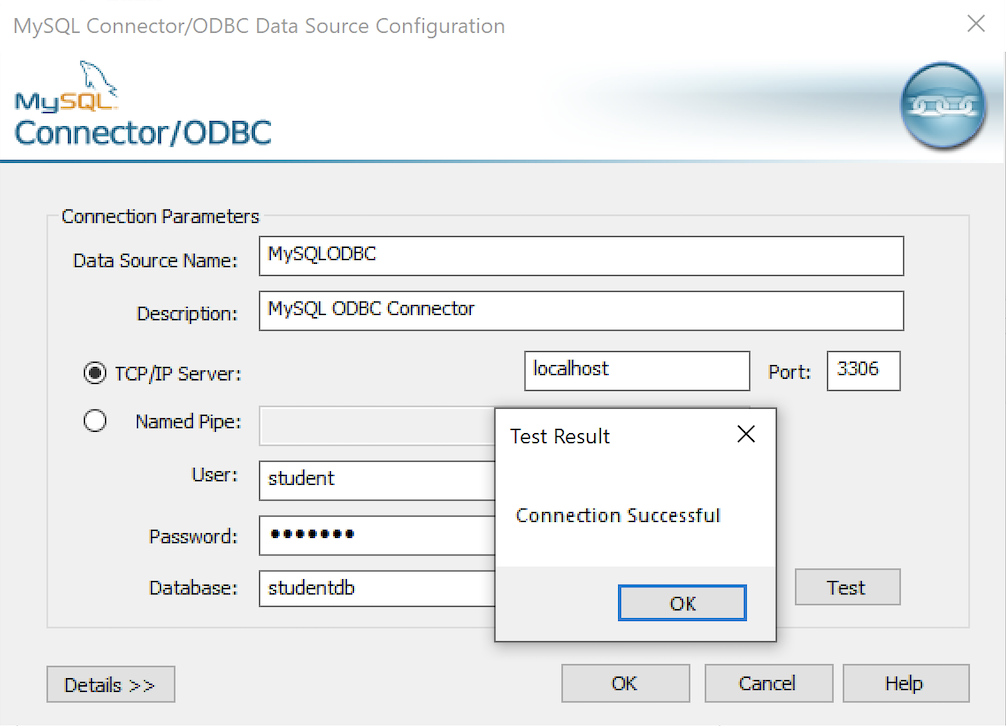
- The Connection Test dialog should return a “Connection successful” message. Click the OK button to continue, and then click the OK button in the next two screens.
After you have created the System MySQL ODBC Setup, it’s time to build a PowerShell Cmdlet (or, Commandlet). Some documentation and blog notes incorrectly suggest you need to write a connection string with a UID and password, like:
$ConnectionString = 'DSN=MySQLODBC;Uid=student;Pwd=student' |
You can do that if you leave the UID and password fields empty in the MySQL ODBC Setup but it’s recommended to enter them there to avoid putting them in your PowerShell script file.
The UID and password are unnecessary in the connection string when they’re in MySQL ODBC DSN. You can use a connection string like the following when the UID and password are in the DSN:
$ConnectionString = 'DSN=MySQLODBC' |
You can create a MySQLCursor.ps1 Cmdlet like the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | # Define a ODBC DSN connection string. $ConnectionString = 'DSN=MySQLODBC' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT database();"; # Attempt to read SQL command. try { $Reader = $Command.ExecuteReader(); # Read while records are found. while ($Reader.Read()) { Write-Host "Current Database [" $Reader[0] "]"} } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $Reader.Close() } } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
Line 14 assigns a SQL query that returns a single row with one column as the CommandText of a Command object. Line 22 reads the zero position of a row or record set with only one column.
You call the MySQLCursor.ps1 Cmdlet with the following syntax:
powershell .\MySQLCursor.ps1 |
It returns:
Current Database [ studentdb ] |
A more realistic way to write a query would return multiple rows with a set of two or more columns. The following program queries a table with multiple rows of two columns, but the program logic can manage any number of columns.
# Define a ODBC DSN connection string. $ConnectionString = 'DSN=MySQLODBC' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT last_name, first_name FROM contact ORDER BY 1, 2"; # Attempt to read SQL command. try { $row = $Command.ExecuteReader(); # Read while records are found. while ($row.Read()) { # Initialize output for each row. $output = "" # Navigate across all columns (only two in this example). for ($column = 0; $column -lt $row.FieldCount; $column += 1) { # Mechanic for comma-delimit between last and first name. if ($output.length -eq 0) { $output += $row[$column] } else { $output += ", " + $row[$column] } } # Write the output from the database. Write-Host $output } } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $row.Close() } } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
You call the MySQLContact.ps1 Cmdlet with the following syntax:
powershell .\MySQLContact.ps1 |
It returns an ordered set of comma-separated values, like
Clinton, Goeffrey Gretelz, Simon Moss, Wendy Potter, Ginny Potter, Harry Potter, Lily Royal, Elizabeth Smith, Brian Sweeney, Ian Sweeney, Matthew Sweeney, Meaghan Vizquel, Doreen Vizquel, Oscar Winn, Brian Winn, Randi |
As always, I hope this helps those looking for a complete concrete example of how to make Microsoft Powershell connect and query results from a MySQL database.
MySQL 5-Table Procedure
A student wanted a better example of writing a MySQL Persistent Stored Module (PSM) that maintains transactional scope across a couple tables. Here’s the one I wrote about ten years ago to build the MySQL Video Store model. It looks I neglected to put it out there before, so here it is for reference.
-- Conditionally drop procedure if it exists. DROP PROCEDURE IF EXISTS contact_insert; -- Reset the delimiter so that a semicolon can be used as a statement and block terminator. DELIMITER $$ SELECT 'CREATE PROCEDURE contact_insert' AS "Statement"; CREATE PROCEDURE contact_insert ( pv_member_type CHAR(12) , pv_account_number CHAR(19) , pv_credit_card_number CHAR(19) , pv_credit_card_type CHAR(12) , pv_first_name CHAR(20) , pv_middle_name CHAR(20) , pv_last_name CHAR(20) , pv_contact_type CHAR(12) , pv_address_type CHAR(12) , pv_city CHAR(30) , pv_state_province CHAR(30) , pv_postal_code CHAR(20) , pv_street_address CHAR(30) , pv_telephone_type CHAR(12) , pv_country_code CHAR(3) , pv_area_code CHAR(6) , pv_telephone_number CHAR(10)) MODIFIES SQL DATA BEGIN /* Declare variables to manipulate auto generated sequence values. */ DECLARE member_id int unsigned; DECLARE contact_id int unsigned; DECLARE address_id int unsigned; DECLARE street_address_id int unsigned; DECLARE telephone_id int unsigned; /* Declare local constants for who-audit columns. */ DECLARE lv_created_by int unsigned DEFAULT 1001; DECLARE lv_creation_date DATE DEFAULT UTC_DATE(); DECLARE lv_last_updated_by int unsigned DEFAULT 1001; DECLARE lv_last_update_date DATE DEFAULT UTC_DATE(); /* Declare a locally scoped variable. */ DECLARE duplicate_key INT DEFAULT 0; /* Declare a duplicate key handler */ DECLARE CONTINUE HANDLER FOR 1062 SET duplicate_key = 1; /* Start the transaction context. */ START TRANSACTION; /* Create a SAVEPOINT as a recovery point. */ SAVEPOINT all_or_none; /* Insert into the first table in sequence based on inheritance of primary keys by foreign keys. */ INSERT INTO member ( member_type , account_number , credit_card_number , credit_card_type , created_by , creation_date , last_updated_by , last_update_date ) VALUES ((SELECT common_lookup_id FROM common_lookup WHERE common_lookup_context = 'MEMBER' AND common_lookup_type = pv_member_type) , pv_account_number , pv_credit_card_number ,(SELECT common_lookup_id FROM common_lookup WHERE common_lookup_context = 'MEMBER' AND common_lookup_type = pv_credit_card_type) , lv_created_by , lv_creation_date , lv_last_updated_by , lv_last_update_date ); /* Preserve the sequence by a table related variable name. */ SET member_id = last_insert_id(); /* Insert into the first table in sequence based on inheritance of primary keys by foreign keys. */ INSERT INTO contact VALUES ( null , member_id ,(SELECT common_lookup_id FROM common_lookup WHERE common_lookup_context = 'CONTACT' AND common_lookup_type = pv_contact_type) , pv_first_name , pv_middle_name , pv_last_name , lv_created_by , lv_creation_date , lv_last_updated_by , lv_last_update_date ); /* Preserve the sequence by a table related variable name. */ SET contact_id = last_insert_id(); /* Insert into the first table in sequence based on inheritance of primary keys by foreign keys. */ INSERT INTO address VALUES ( null , last_insert_id() ,(SELECT common_lookup_id FROM common_lookup WHERE common_lookup_context = 'MULTIPLE' AND common_lookup_type = pv_address_type) , pv_city , pv_state_province , pv_postal_code , lv_created_by , lv_creation_date , lv_last_updated_by , lv_last_update_date ); /* Preserve the sequence by a table related variable name. */ SET address_id = last_insert_id(); /* Insert into the first table in sequence based on inheritance of primary keys by foreign keys. */ INSERT INTO street_address VALUES ( null , last_insert_id() , pv_street_address , lv_created_by , lv_creation_date , lv_last_updated_by , lv_last_update_date ); /* Insert into the first table in sequence based on inheritance of primary keys by foreign keys. */ INSERT INTO telephone VALUES ( null , contact_id , address_id ,(SELECT common_lookup_id FROM common_lookup WHERE common_lookup_context = 'MULTIPLE' AND common_lookup_type = pv_telephone_type) , pv_country_code , pv_area_code , pv_telephone_number , lv_created_by , lv_creation_date , lv_last_updated_by , lv_last_update_date); /* This acts as an exception handling block. */ IF duplicate_key = 1 THEN /* This undoes all DML statements to this point in the procedure. */ ROLLBACK TO SAVEPOINT all_or_none; END IF; /* This commits the write when successful and is harmless otherwise. */ COMMIT; END; $$ -- Reset the standard delimiter to let the semicolon work as an execution command. DELIMITER ; |
You can then call the procedure, like:
SELECT 'CALL contact_insert() PROCEDURE 5 times' AS "Statement"; CALL contact_insert('INDIVIDUAL','R11-514-34','1111-1111-1111-1111','VISA_CARD','Goeffrey','Ward','Clinton','CUSTOMER','HOME','Provo','Utah','84606','118 South 9th East','HOME','011','801','423\-1234'); CALL contact_insert('INDIVIDUAL','R11-514-35','1111-2222-1111-1111','VISA_CARD','Wendy',null,'Moss','CUSTOMER','HOME','Provo','Utah','84606','1218 South 10th East','HOME','011','801','423-1234'); CALL contact_insert('INDIVIDUAL','R11-514-36','1111-1111-2222-1111','VISA_CARD','Simon','Jonah','Gretelz','CUSTOMER','HOME','Provo','Utah','84606','2118 South 7th East','HOME','011','801','423-1234'); CALL contact_insert('INDIVIDUAL','R11-514-37','1111-1111-1111-2222','MASTER_CARD','Elizabeth','Jane','Royal','CUSTOMER','HOME','Provo','Utah','84606','2228 South 14th East','HOME','011','801','423-1234'); CALL contact_insert('INDIVIDUAL','R11-514-38','1111-1111-3333-1111','VISA_CARD','Brian','Nathan','Smith','CUSTOMER','HOME','Spanish Fork','Utah','84606','333 North 2nd East','HOME','011','801','423-1234'); |
I hope this code complete approach helps those looking to learn how to write MySQL PSMs.
Setting SQL_MODE
In MySQL, the @@sql_mode parameter should generally use ONLY_FULL_GROUP_BY. If it doesn’t include it and you don’t have the ability to change the database parameters, you can use a MySQL PSM (Persistent Stored Module), like:
Create the set_full_group_by procedure:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | -- Drop procedure conditionally on whether it exists already. DROP PROCEDURE IF EXISTS set_full_group_by; -- Reset delimter to allow semicolons to terminate statements. DELIMITER $$ -- Create a procedure to verify and set connection parameter. CREATE PROCEDURE set_full_group_by() LANGUAGE SQL NOT DETERMINISTIC SQL SECURITY DEFINER COMMENT 'Set connection parameter when not set.' BEGIN /* Check whether full group by is set in the connection and if unset, set it in the scope of the connection. */ IF NOT EXISTS (SELECT NULL WHERE REGEXP_LIKE(@@SQL_MODE,'ONLY_FULL_GROUP_BY')) THEN SET SQL_MODE=(SELECT CONCAT(@@sql_mode,',ONLY_FULL_GROUP_BY')); END IF; END; $$ -- Reset the default delimiter. DELIMITER ; |
Run the following SQL command before you attempt the exercises in the same session scope:
CALL set_full_group_by(); |
As always, I hope this helps those looking for a solution. Naturally, you can simply use the SET command on line #21 above.
