PostgreSQL on Ubuntu
Fresh install of Ubuntu on my MacBook Pro i7 because Apple said the OS X was no longer upgradable. Time to install and configure MySQL Server. These are the steps to install MySQL on the Ubuntu Desktop.
Installation
- Update the Ubuntu OS by checking for, inspecting, and upgrading any available updates with the following commands:
sudo apt update sudo apt list sudo apt upgrade
- Check for available PostgreSQL Server packages with this command:
sudo apt install postgresql postgresql-contrib
- Connect as the postgres user with the following command:
sudo -i -u postgres
Then, you can connect to PostgreSQL with this command:
psql
It displays your connection as the root user. Then, you can use the show data_directory; command to find the data directory:
psql (14.8 (Ubuntu 14.8-0ubuntu0.22.04.1)) Type "help" for help. postgres=# show data_directory; data_directory ----------------------------- /var/lib/postgresql/14/main (1 row)\q
- At this point, you have some operating system (OS) stuff to setup before configuring a PostgreSQL sandboxed videodb database and student user.
- Assume the role of the root superuser on Ubuntu with this command:
sudo sh
As the root user, navigate to /etc/postgresql/14/main directory and edit the pg_hba.conf file. Add lines for the postgres and student users, as shown below:
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all peer local all postgres peer local all student peer # IPv4 local connections: host all all 127.0.0.1/32 scram-sha-256 # IPv6 local connections: host all all ::1/128 scram-sha-256 # Allow replication connections from localhost, by a user with the # replication privilege. local replication all scram-sha-256 host replication all 127.0.0.1/32 scram-sha-256 host replication all ::1/128 scram-sha-256
- As the root user, navigate to the /var/lib/postgresql/14 directory, and make the video_db directory with the following command:
mkdir video_db - Change the video_db ownership and group to the respective postgres user and primary group:
chown postgres:postgres video_db - Change the video_db permissions to read, write, and execute for only the owner with this syntax as the postgres user:
chmod 700 video_db
- Assume the role of the root superuser on Ubuntu with this command:
- Connect to the postgres account and perform the following commands:
- Connect as the postgres user with the following command:
sudo -i -u postgres
- After connecting as the postgres superuser, you can create a video_db tablespace with the following syntax:
CREATE TABLESPACE video_db OWNER postgres LOCATION '/var/lib/postgresql/14/video_db';
This will return the following:
CREATE TABLESPACE
You can query whether you successfully create the video_db tablespace with the following:
SELECT * FROM pg_tablespace;
It should return the following:
oid | spcname | spcowner | spcacl | spcoptions -------+------------+----------+--------+------------ 1663 | pg_default | 10 | | 1664 | pg_global | 10 | | 16389 | video_db | 10 | | (3 rows)
-
You need to know the PostgreSQL default collation before you create a new database. You can write the following query to determine the default correlation:
postgres=# SELECT datname, datcollate FROM pg_database WHERE datname = 'postgres';
It should return something like this:
datname | datcollate ----------+------------- postgres | en_US.UTF-8 (1 row)
The datcollate value of the postgres database needs to the same value for the LC_COLLATE and LC_CTYPE parameters when you create a database. You can create a videodb database with the following syntax provided you’ve made appropriate substitutions for the LC_COLLATE and LC_CTYPE values below:
CREATE DATABASE videodb WITH OWNER = postgres ENCODING = 'UTF8' TABLESPACE = video_db LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8' CONNECTION LIMIT = -1;
You can verify the creation of the videodb with the following command:
postgres# \l
It should show you a display like the following:
List of databases Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges -----------+----------+----------+-------------+-------------+------------+-----------------+----------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres videodb | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | (4 rows)Then, you can assign comment to the database with the following syntax:
COMMENT ON DATABASE videodb IS 'Video Store Database';
- Create a Role, Grant, and User:
In this section you create a dba role, grant privileges on a videodb database to a role, and create a user with the role that you created previously with the following three statements. There are three steps in this sections.
- The first step creates a dba role:
CREATE ROLE dba WITH SUPERUSER;
- The second step grants all privileges on the videodb database to both the postgres superuser and the dba role:
GRANT TEMPORARY, CONNECT ON DATABASE videodb TO PUBLIC; GRANT ALL PRIVILEGES ON DATABASE videodb TO postgres; GRANT ALL PRIVILEGES ON DATABASE videodb TO dba;
Any work in pgAdmin4 requires a grant on the videodb database to the postgres superuser. The grant enables visibility of the videodb database in the pgAdmin4 console as shown in the following image.
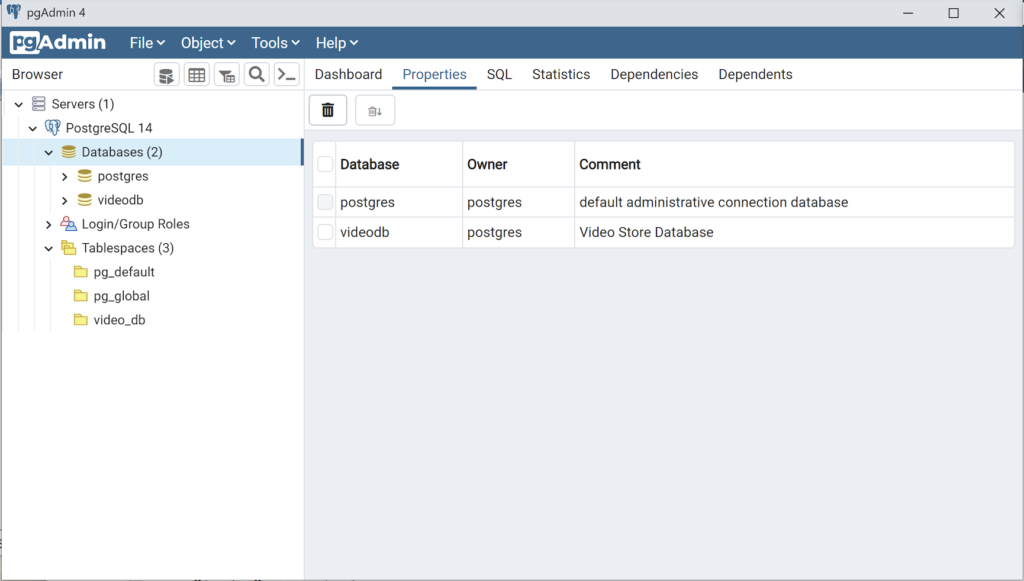
- The third step creates a student user:
CREATE USER student WITH ROLE dba ENCRYPTED PASSWORD 'student';
- The fourth step changes the ownership of the videodb database to the student user:
ALTER DATABASE videodb OWNER TO student;
You can verify the change of ownership for the videodb from the postgres user to student user with the following command:
postgres# \l
It should show you a display like the following:
List of databases Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges -----------+----------+----------+-------------+-------------+------------+-----------------+----------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres videodb | student | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =Tc/student + | | | | | | | student=CTc/student + | | | | | | | dba=CTc/student (4 rows)
Installation of PGAdmin4
These are the steps to install pgAdmin4. They include some preconditions.
You need to install the curl utility as a precondition.
sudo apt install curl
Install the public key for the repository (if not done previously):
curl -fsSL https://www.pgadmin.org/static/packages_pgadmin_org.pub | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/pgadmin.gpg
- The first step creates a dba role:
- Connect as the postgres user with the following command:
MySQL on Ubuntu

Fresh install of Ubuntu on my MacBook Pro i7 because Apple said the OS X was no longer upgradable. Time to install and configure MySQL Server. These are the steps to install MySQL on the Ubuntu Desktop.
Installation
- Update the Ubuntu OS by checking for, inspecting, and upgrading any available updates with the following commands:
sudo apt update sudo apt list sudo apt upgrade
- Check for available MySQL Server packages with this command:
apt-cache search binaries | grep -i mysql
It should return:
mysql-server - MySQL database server binaries and system database setup mysql-server-8.0 - MySQL database server binaries and system database setup mysql-server-core-8.0 - MySQL database server binaries default-mysql-server - MySQL database server binaries and system database setup (metapackage) default-mysql-server-core - MySQL database server binaries (metapackage) mariadb-server-10.6 - MariaDB database core server binaries mariadb-server-core-10.6 - MariaDB database core server files
- Check for more details on the MySQL packages with this command:
apt info -a mysql-server-8.0
- Install MySQL Server packages with this command:
sudo apt install mysql-server-8.0
- Start the MySQL Server service with this command:
sudo systemctl start mysql.service - Before you can run the mysql_secure_installation script, you must set the root password. If you skip this step the mysql_secure_installation script will enter an infinite loop and lock your terminal session. Log in to the mysql monitor with the following command:
sudo mysqlEnter a password with the following command (password is an insecure example):
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'C4nGet1n!';
Quit the mysql monitor session:
quit; - Run the mysql_secure_installation script with this command:
sudo mysql_secure_installationHere’s the typical output from running the mysql_secure_installation script:
Securing the MySQL server deployment. Enter password for user root: VALIDATE PASSWORD COMPONENT can be used to test passwords and improve security. It checks the strength of password and allows the users to set only those passwords which are secure enough. Would you like to setup VALIDATE PASSWORD component? Press y|Y for Yes, any other key for No: Y There are three levels of password validation policy: LOW Length >= 8 MEDIUM Length >= 8, numeric, mixed case, and special characters STRONG Length >= 8, numeric, mixed case, special characters and dictionary file Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 2 Using existing password for root. Estimated strength of the password: 100 Change the password for root ? ((Press y|Y for Yes, any other key for No) : N ... skipping. By default, a MySQL installation has an anonymous user, allowing anyone to log into MySQL without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? (Press y|Y for Yes, any other key for No) : Y Success. Normally, root should only be allowed to connect from 'localhost'. This ensures that someone cannot guess at the root password from the network. Disallow root login remotely? (Press y|Y for Yes, any other key for No) : Y Success. By default, MySQL comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. Remove test database and access to it? (Press y|Y for Yes, any other key for No) : Y - Dropping test database... Success. - Removing privileges on test database... Success. Reloading the privilege tables will ensure that all changes made so far will take effect immediately. Reload privilege tables now? (Press y|Y for Yes, any other key for No) : Y Success. All done!
Configuration
The next step is configuration. It requires setting up the sample sakila and studentdb database. The syntax has changed from prior releases. Here are the new three steps:
- Grant the root user the privilege to grant to others, which root does not have by default. You use the following syntax as the MySQL root user:
mysql> GRANT ALL ON *.* TO 'root'@'localhost';
- Download the sakila database, which you can download from this site. Click on the sakila database’s TGZ download.

When you download the sakila zip file it creates a sakila-db folder in the /home/student/Downloads directory. Copy the sakila-db folder into the /home/student/Data/sakila directory. Then, change to the /home/student/Data/sakila/sakila-db directory, connect to mysql as the root user, and run the following command:
mysql> SOURCE /home/student/Data/sakila/sakila-db/sakila-schema.sql mysql> SOURCE /home/student/Data/sakila/sakila-db/sakila-data.sql
- Create the studentdb database with the following command as the MySQL root user:
mysql> CREATE DATABASE studentdb; - Create the user with a clear English password and grant the user student full privileges on the sakila and studentdb databases:
mysql> CREATE USER 'student'@'localhost' IDENTIFIED WITH mysql_native_password BY 'Stud3nt!'; mysql> GRANT ALL ON studentdb.* TO 'student'@'localhost'; mysql> GRANT ALL ON sakila.* TO 'student'@'localhost';
You can now connect to a sandboxed sakila database with the student user’s credentials, like:
mysql -ustudent -p -Dsakila |
or, you can now connect to a sandboxed studentdb database with the student user’s credentials, like:
mysql -ustudent -p -Dstudentdb |
MySQL Workbench Installation
sudo snap install mysql-workbench-community |
You have now configure the MySQL Server 8.0.
Ubuntu Desktop 22.04

I finally got around to installing Ubuntu Desktop, Version 22.04, on my MacBook Pro 2014 since OS X stopped allowing upgrades on the device in 2021. While I replaced it in 2021 with a new MacBook Pro with an i9 Intel Chip. The Ubuntu documentation gave clear instructions on how to create a bootable USB drive before replacing the Mac OS software..
Unfortunately, networking was not well covered. It left me with two questions:
- How to configure Ubuntu Desktop 22.04 to the network?
You need to use an RJ45 network cable (in this case also an RJ45 to Thunderbolt adapter) and reboot the OS. It will automatically configure your DCHP connection.
- How to configure Wifi for Ubuntu Desktop 22.04?
You need to download and install a library, which is covered below.
After the Ubuntu Desktop installation, I noticed it didn’t provide any opportunity to update the software or configure the network. It also was not connected to the network. I connected the MacBook Pro to a physical Internet cable and rebooted the Ubuntu OS. It recognized the wired network. Then, I upgraded the installed libraries, which is almost always the best choice.
At this point, I noticed that the libraries to enable a WiFi connection were not installed. So, I installed the missing Wifi libraries with this command:
sudo apt-get install dbms bcmwl-kernel-source |
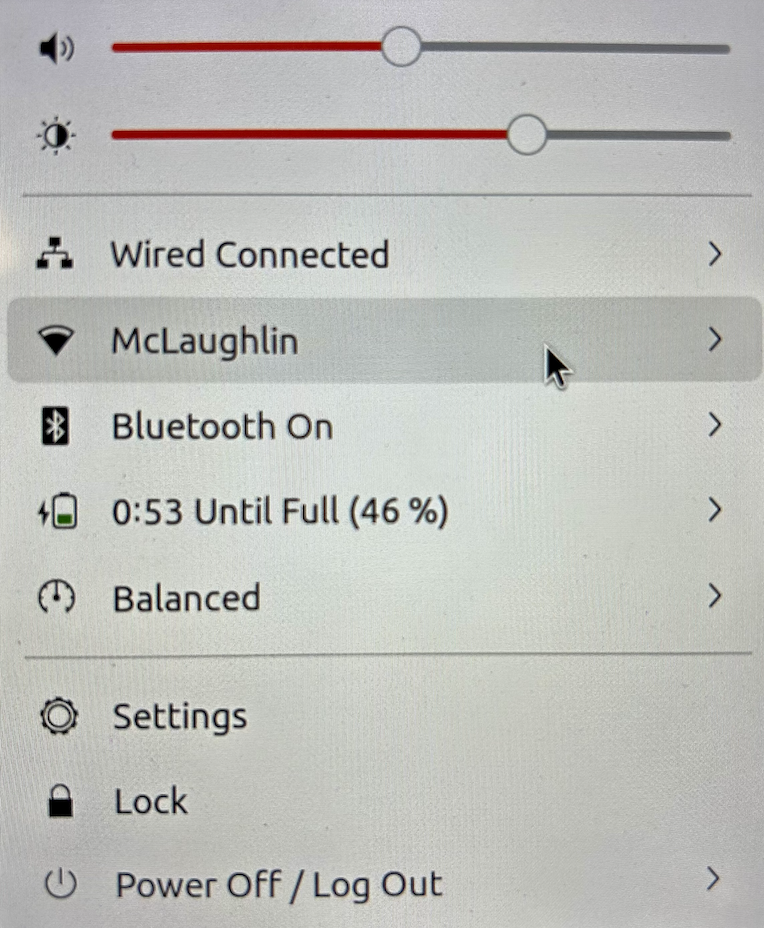
After you’ve installed the bcmwl-kernel-source libraries, navigate to the top right where you’ll find a small network icon. Click on the network icon and you’ll see the following dialog. Click on your designated Wifi, enter the password and you’ll have a Wifi connection.
As always, I hope this note helps those trying to solve a real world problem.
A tkprof Korn Shell
Reviewing old files, I thought posting my tkprof.ksh would be helpful. So, here’s the script that assumes you’re using Oracle e-Business Suite (Demo database, hence the APPS/APPS connection); and if I get a chance this summer I’ll convert it to Bash shell.
#!/bin/ksh
# -------------------------------------------------------------------------
# Author: Michael McLaughlin
# Name: tkprof.ksh
# Purpose: The program takes the following arguments:
# 1. A directory
# 2. A search string
# 3. A target directory
# It assumes raw trace files have an extension of ".trc".
# The output file name follows this pattern (because it is
# possible for multiple tracefiles to be written during the
# same minute).
# -------------------------------------------------------------------------
# Function to find minimum field delimiter.
function min
{
# Find the whitespace that preceeds the file date.
until [[ $(ls -al $i | cut -c$minv-$minv) == " " ]]; do
let minv=minv+1
done
}
# Function to find maximum field delimiter.
function max
{
# Find the whitespace that succeeds the file date.
until [[ $(ls -al $i | cut -c$maxv-$maxv) == " " ]]; do
let maxv=maxv+1
done
}
# Debugging enabled by unremarking the "set -x"
# set -x
# Print header information
print =================================================================
print Running [tkprof.ksh] script ...
# Evaluate whether an argument is provide and if no argument
# is provided, then substitute the present working directory.
if [[ $# == 0 ]]; then
dir=${PWD}
str="*"
des=${PWD}
elif [[ $# == 1 ]]; then
dir=${1}
str="*"
des=${1}
elif [[ $# == 2 ]]; then
dir=${1}
str=${2}
des=${1}
elif [[ $# == 3 ]]; then
dir=${1}
str=${2}
des=${3}
fi
# Evaluate whether the argument is a directory file.
if [[ -d ${dir} ]] && [[ -d ${des} ]]; then
# Print what directory and search string are targets.
print =================================================================
print Run in tkprof from [${dir}] directory ...
print The files contain a string of [${str}] ...
print =================================================================
# Evaluate whether the argument is the present working
# directory and if not change directory to that target
# directory so file type evaluation will work.
if [[ ${dir} != ${PWD} ]]; then
cd ${dir}
fi
# Set file counter.
let fcnt=0
# Submit compression to the background as a job.
for i in $(grep -li "${str}" *.trc); do
# Evaluate whether file is an ordinary file.
if [[ -f ${i} ]]; then
# Set default values each iteration.
let minv=40
let maxv=53
# Increment counter.
let fcnt=fcnt+1
# Call functions to reset min and max values where necessary.
min ${i}
max ${i}
# Parse date stamp from trace file without multiple IO calls.
# Assumption that the file is from the current year.
date=$(ls -al ${i} | cut -c${minv}-${maxv})
mon=$(echo ${date} | cut -c1-3)
yr=$(date | cut -c25-28)
# Validate month is 10 or greater to pad for reduced whitespace.
if (( $(echo ${date} | cut -c5-6) < 10 )); then
day=0$(echo ${date}| cut -c5-5)
hr=$(echo ${date} | cut -c7-8)
min=$(echo ${date} | cut -c10-11)
else
day=$(echo ${date} | cut -c5-6)
hr=$(echo ${date} | cut -c8-9)
min=$(echo ${date} | cut -c11-12)
fi
fn=file${fcnt}_${day}-${mon}-${yr}_${hr}:${min}:${day}
print Old [$i] and new [$des/$fn]
tkprof ${i} ${des}/${fn}.prf explain=APPS/APPS sort='(prsela,exeela,fchela)'
# Print what directory and search string are targets.
print =================================================================
fi
done
else
# Print message that a directory argument was not provided.
print You failed to provie a single valid directory argument.
fi |
I hope this helps those looking for a solution.
Listener for APEX
Unless dbca lets us build the listener.ora file, we often leave off some component. For example, running listener control program the following status indicates an incorrectly configured listener.ora file.
lsnrctl status |
It returns the following, which displays an endpoint for the XDB Server (I’m using Oracle Database 11g XE because it’s pre-containerized and has a small testing footprint):
LSNRCTL for Linux: Version 11.2.0.2.0 - Production on 24-MAR-2023 00:59:06 Copyright (c) 1991, 2011, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC_FOR_XE))) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 11.2.0.2.0 - Production Start Date 21-MAR-2023 21:17:37 Uptime 2 days 3 hr. 41 min. 29 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Default Service XE Listener Parameter File /u01/app/oracle/product/11.2.0/xe/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/localhost/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC_FOR_XE))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=8080))(Presentation=HTTP)(Session=RAW)) Services Summary... Service "PLSExtProc" has 1 instance(s). Instance "PLSExtProc", status UNKNOWN, has 1 handler(s) for this service... Service "XE" has 1 instance(s). Instance "XE", status READY, has 1 handler(s) for this service... Service "XEXDB" has 1 instance(s). Instance "XE", status READY, has 1 handler(s) for this service... The command completed successfully |
The listener is missing the second SID_LIST_LISTENER value of CLRExtProc value. A complete listener.ora file should be as follows for the Oracle Database XE:
# listener.ora Network Configuration FILE: SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME = PLSExtProc) (ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe) (PROGRAM = extproc) ) (SID_DESC = (SID_NAME = CLRExtProc) (ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe) (PROGRAM = extproc) ) ) LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) (ADDRESS = (PROTOCOL = TCP)(HOST = localhost.localdomain)(PORT = 1521)) ) ) DEFAULT_SERVICE_LISTENER = (XE) |
With this listener.ora file, the Oracle listener control utility will return the following correct status, which hides the XDB Server’s endpoint:
LSNRCTL for Linux: Version 11.2.0.2.0 - Production on 24-MAR-2023 02:38:57 Copyright (c) 1991, 2011, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC_FOR_XE))) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 11.2.0.2.0 - Production Start Date 24-MAR-2023 02:38:15 Uptime 0 days 0 hr. 0 min. 42 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Default Service XE Listener Parameter File /u01/app/oracle/product/11.2.0/xe/network/admin/listener.ora Listener Log File /u01/app/oracle/product/11.2.0/xe/log/diag/tnslsnr/localhost/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC_FOR_XE))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1521))) Services Summary... Service "CLRExtProc" has 1 instance(s). Instance "CLRExtProc", status UNKNOWN, has 1 handler(s) for this service... Service "PLSExtProc" has 1 instance(s). Instance "PLSExtProc", status UNKNOWN, has 1 handler(s) for this service... The command completed successfully |
It seems a number of examples on the web left the SID_LIST_LISTENER value of CLRExtProc value out of the listener.ora file. As always, I hope this helps those looking for a complete solution rather than generic instructions without a concrete example.
AWS EC2 TNS Listener
Having configured an AlmaLinux 8.6 with Oracle Database 11g XE, MySQL 8.0.30, and PostgreSQL 15, we migrated it to AWS EC2 and provisioned it. We used the older and de-supported Oracle Database 11g XE because it didn’t require any kernel modifications and had a much smaller footprint.
I had to address why attempting to connect with the sqlplus utility raised the following error after provisioning a copy with a new static IP address:
ERROR: ORA-12514: TNS:listener does NOT currently know OF service requested IN CONNECT descriptor |
A connection from SQL Developer raises a more addressable error, like:
ORA-17069 |
I immediately tried to check the connection with the tnsping utility and found that tnsping worked fine. However, when I tried to connect with the sqlplus utility it raised an ORA-12514 connection error.
There were no diagnostic steps beyond checking the tnsping utility. So, I had to experiment with what might block communication.
I changed the host name from ip-172-58-65-82.us-west-2.compute.internal to a localhost string in both the listener.ora and tnsnames.ora. The listener.ora file:
# listener.ora Network Configuration FILE: SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME = PLSExtProc) (ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe) (PROGRAM = extproc) ) ) LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) (ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)) ) ) DEFAULT_SERVICE_LISTENER = (XE) |
The tnsnames.ora file:
# tnsnames.ora Network Configuration FILE: XE = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = XE) ) ) EXTPROC_CONNECTION_DATA = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) ) (CONNECT_DATA = (SID = PLSExtProc) (PRESENTATION = RO) ) ) |
I suspected that it might be related to the localhost value. So, I checked the /etc/hostname and /etc/hosts files.
Then, I modified /etc/hostname file by removing the AWS EC2 damain address. I did it on a memory that Oracle’s TNS raises errors for dots or periods in some addresses.
The /etc/hostname file:
ip-172-58-65-82 |
The /etc/hosts file:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ip-172-58-65-82 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 ip-172-58-65-82 |
Now, we can connect to the Oracle Database 11g XE instance with the sqlplus utility. I believe this type of solution will work for other AWS EC2 provisioned Oracle databases.
MySQL @SQL_MODE
Installing MySQL Workbench 8 on Windows, we discovered that the default configuration no longer sets ONLY_FULL_GROUP_BY as part of the default SQL_MODE parameter value. While I’ve written a stored function to set the SQL_MODE parameter value for a session, some students didn’t understand that such a call is only valid in the scope of a connection to the database server. They felt the function didn’t work because they didn’t understand the difference between connecting to the MySQL CLI and clicking the lightening bolt in MySQL Workbench.
So, here are the instructions to reset the default SQL_MODE parameter value for Windows. You need to edit the setting in the my.ini file, which is in the C:\ProgramData\MySQL\MySQL Server 8.0 directory. The default installation will have the following:
# Set the SQL mode to strict sql-mode="STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION" |
You need to change it to the following in an editor with Administrative privileges:
# Set the SQL mode to strict sql-mode="STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION,ONLY_FULL_GROUP_BY" |
Then, you need to connect to the services by launching services.msc from the command prompt. In the list of services find MYSQL80 service and restart it. You can verify it by connecting to the MySQL 8.0.* server and running the following SQL query:
SELECT @@SQL_MODE: |
That’s how you convert Windows to use only traditional group by behaviors in SQL. As always, I hope this helps those looking for a solution.
AlmaLinux Libraries
I discovered a dependency for MySQL Workbench on AlmaLinux 8 installation. I neglected to fully cover it when I documented the installation in a VM of AlmaLinux 9. I go back later and update that entry but for now you need the following dependencies:
proj-6.3.2-4.el8.x86_64.rpm proj-datumgrid-1.8-6.3.2.4.el8.noarch.rpm proj-devel-6.3.2-4.el8.x86_64.rpm |
Install like this:
sudo dnf install -y *.rpm |
Log file:
Last metadata expiration check: 3:01:53 ago on Fri 10 Feb 2023 03:37:49 AM UTC. Dependencies resolved. ========================================================================================== Package Architecture Version Repository Size ========================================================================================== Installing: proj x86_64 6.3.2-4.el8 @commandline 2.0 M proj-datumgrid noarch 1.8-6.3.2.4.el8 @commandline 5.4 M proj-devel x86_64 6.3.2-4.el8 @commandline 89 k Transaction Summary ========================================================================================== Install 3 Packages Total size: 7.5 M Installed size: 17 M Downloading Packages: Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Installing : proj-datumgrid-1.8-6.3.2.4.el8.noarch 1/3 Installing : proj-6.3.2-4.el8.x86_64 2/3 Installing : proj-devel-6.3.2-4.el8.x86_64 3/3 Running scriptlet: proj-devel-6.3.2-4.el8.x86_64 3/3 Verifying : proj-6.3.2-4.el8.x86_64 1/3 Verifying : proj-datumgrid-1.8-6.3.2.4.el8.noarch 2/3 Verifying : proj-devel-6.3.2-4.el8.x86_64 3/3 Installed: proj-6.3.2-4.el8.x86_64 proj-datumgrid-1.8-6.3.2.4.el8.noarch proj-devel-6.3.2-4.el8.x86_64 Complete! |
A quick update while installing AlmaLinux for AWS.
Data Engineer?

Students often ask me about data engineering. I try to explain some of the aspects, and how the tasks can be organized but I never laid out all the titles. I really like this illustration (click on image for larger size) from the Gartner Group because it does that. You can download the full “What Are the Essential Roles for Data and Analytics” paper here).
An excerpt from Gartner’s paper:
Data Engineer
Data engineering is the practice of making the appropriate data available to various data consumers (including data scientists, data and business analysts, citizen integrators, and line-of-business users). It is a discipline that involves collaboration across business and IT units. This key discipline requires skilled data engineers to support both IT and business teams.
Data engineers are primarily responsible for building, managing and operationalizing data pipelines in support of key D&A use cases. They are also primarily responsible for leading the tedious (and often complex) task of:
- Curating datasets and data pipelines created by nontechnical users (e.g., through self-service data preparation tools), data scientists or even IT resources.
- Operationalizing data delivery for production-level deployments.
I hope the summary is helpful and Gartner’s paper interesting.
Updating SQL_MODE
This is an update for MySQL 8 Stored PSM to add the ONLY_FULL_GROUP_BY mode to the global SQL_MODE variable when it’s not set during a session. Here’s the code:
/* Drop procedure conditionally on whether it exists already. */ DROP PROCEDURE IF EXISTS set_full_group_by; /* Reset delimter to allow semicolons to terminate statements. */ DELIMITER $$ /* Create a procedure to verify and set connection parameter. */ CREATE PROCEDURE set_full_group_by() LANGUAGE SQL NOT DETERMINISTIC SQL SECURITY DEFINER COMMENT 'Set connection parameter when not set.' BEGIN /* Check whether full group by is set in the connection and if unset, set it in the scope of the connection. */ IF EXISTS (SELECT TRUE WHERE NOT REGEXP_LIKE(@@SESSION.SQL_MODE,'ONLY_FULL_GROUP_BY')) THEN SET @@GLOBAL.SQL_MODE := CONCAT(@@SESSION.sql_mode,',ONLY_FULL_GROUP_BY'); END IF; END; $$ /* Reset the default delimiter. */ DELIMITER ; |
You can call the set_full_group_by procedure with the CALL command:
CALL set_full_group_by(); |
You can see the SQL_MODE variable with the following query:
SELECT @@GLOBAL.SQL_MODE; |
It’ll return:
+---------------------------------------------------------------+ | @@GLOBAL.SQL_MODE | +---------------------------------------------------------------+ | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION | +---------------------------------------------------------------+ 1 row in set (0.00 sec) |
As always, I hope this helps those looking to solve this type of problem.
