Archive for the ‘Oracle’ Category
SQL Developer & PostgreSQL
I had a request from one of the adjunct professors to connect SQL Developer to the PostgreSQL database. This is in support of our database programming class that teaches students how to write PL/SQL against the Oracle database and pgPL/SQL against the PostgreSQL database. We also demonstrate transactional management through Node.js, Python and Java.
Naturally, this is also a frequent step taken by those required to migrate PostgreSQL data models to an Oracle database. While my final solution requires mimicking Oracle’s database user to schema, it does work for migration purposes. I’ll update this post when I determine how to populate the database drop-down list.
The first step was figuring out where to put the PostgreSQL JDBC Java ARchive (.jar) file on a Linux distribution. You navigate to the end-user student account in a Terminal and change to the .sqldeveloper directory. Then, create a jdbc subdirectory as the student user with the following command:
mkdir /home/student/.sqldeveloper/jdbc |
Then, download the most current PostgreSQL JDBC Java ARchive (.jar) file and copy it into the /home/student/.sqldeveloper/jdbc, which you can see afterward with the following command:
ll /home/student/.sqldeveloper/jdbc |
It should display:
-rw-r--r--. 1 student student 1041081 Aug 9 13:46 postgresql-42.3.7.jar |
The next series of steps are done within SQL Developer. Launch SQL Developer and navigate to Tools and Preferences, like this:
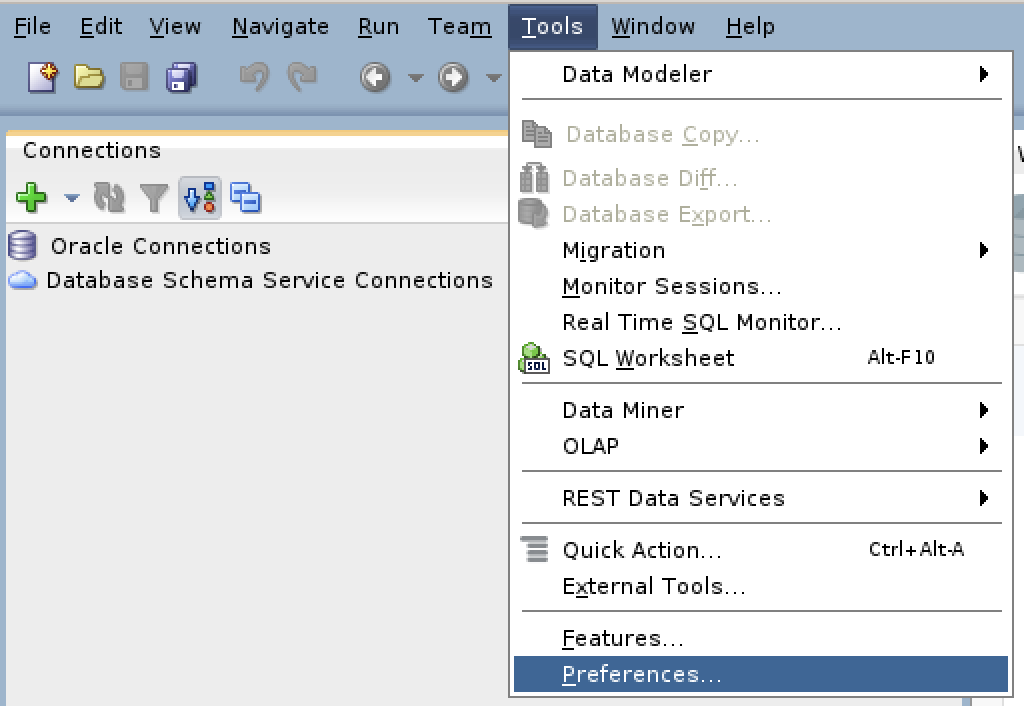
Inside the Preferences dialog, navigate to Database and Third Party JDBC Drivers like shown and click the Add Entry button to proceed:
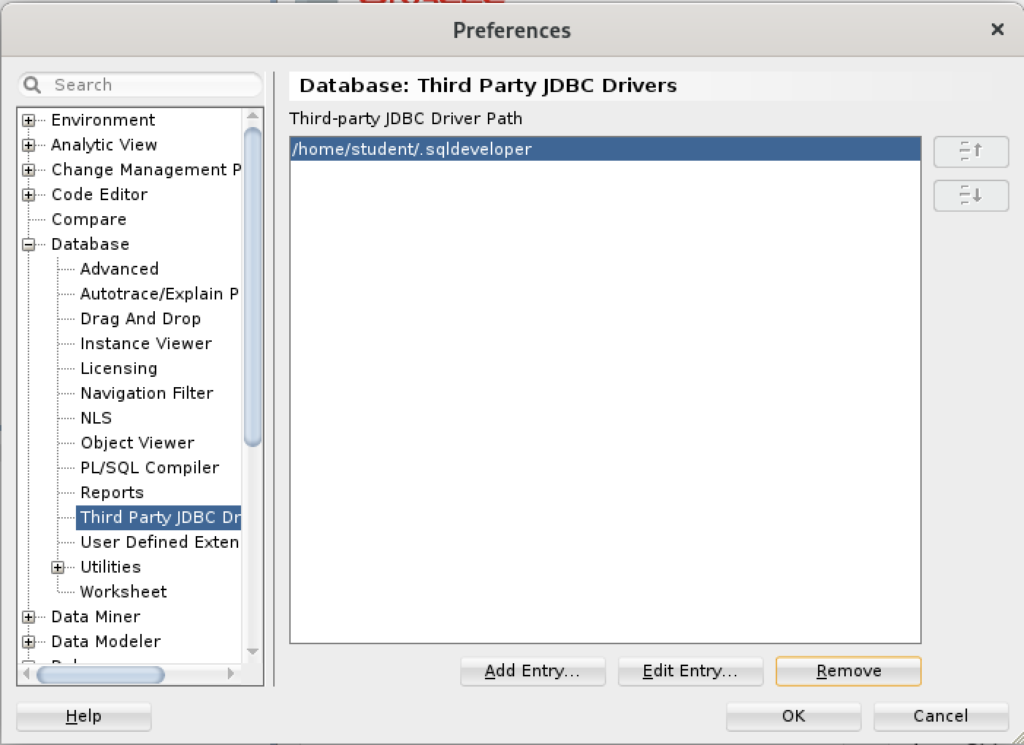
Inside the Select Path Entry dialog, select the current PostgreSQL JDBC Java ARchive (.jar) file, which is postgresql-42-3.7.jar in this example. Then, click the Select button.
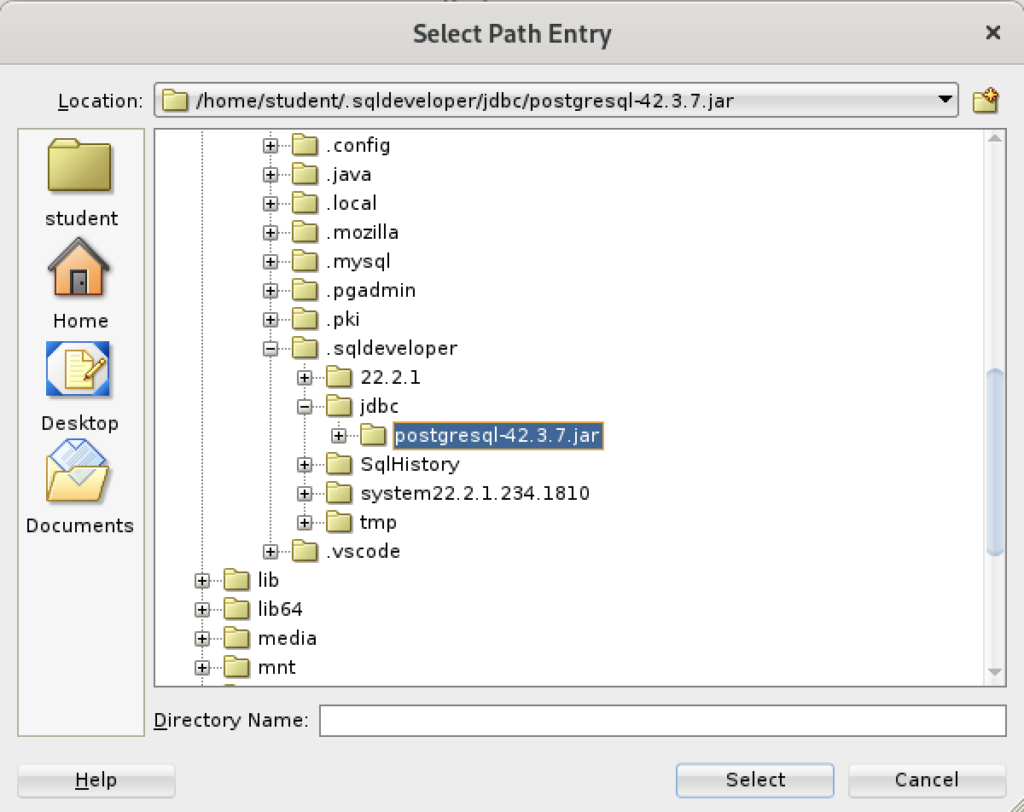
You are returned to the Preferences dialog as shown below. Click the OK button to continue.
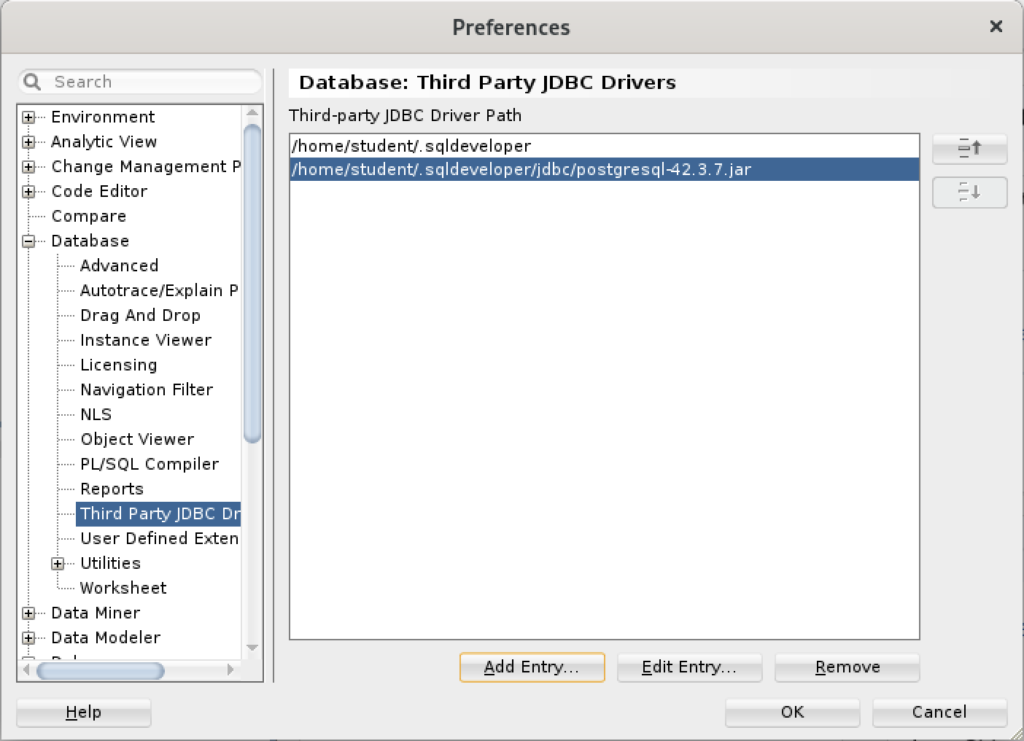
After completing the 3rd Party Java Driver setup, you attempt to create a new connection to the PostgreSQL database. You should see that you now have two available Database Type values: Oracle and PostgreSQL, as shown below:
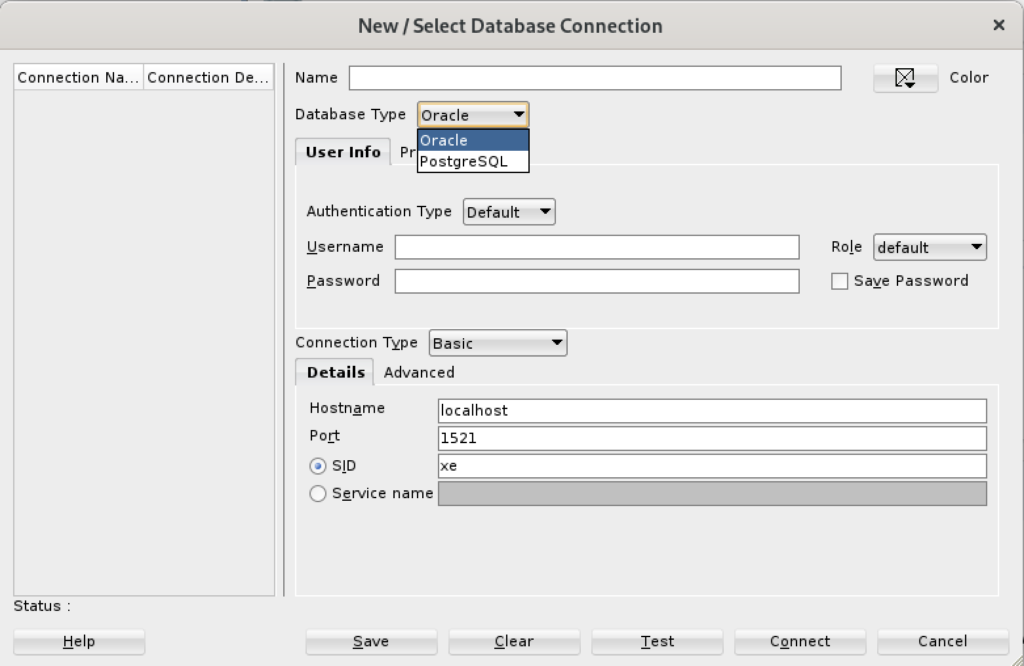
When you click on the PostgreSQL Database Type, the dialog updates to the following view. Unfortunately, I couldn’t discover how to set the values in the list for the Choose Database drop down. Naturally, a sandboxed user can’t connect to the PostgreSQL database without qualifying the database name.
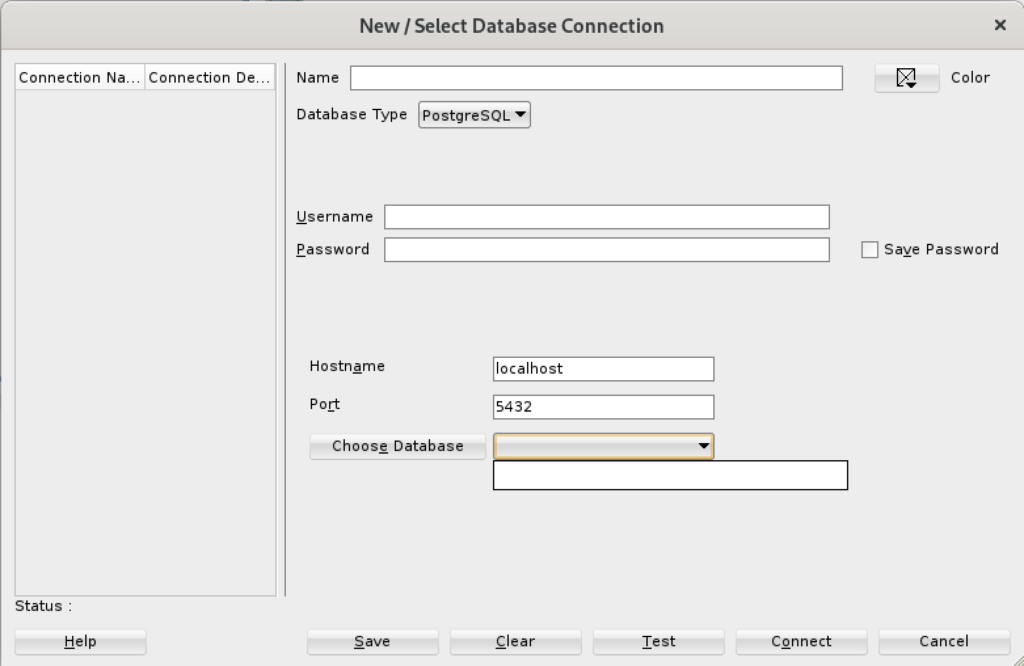
Unless you qualify the PostgreSQL database or connect as the postgres user with a privileged password, SQL Developer translates the absence of a database selection to a database name equivalent to the user’s name. That’s the default behavior for the Oracle database but differs from the behavior for MySQL, PostgreSQL, and Microsoft SQL Server. It returns the following
Status: Failure - Test failed: FATAL: database "student" does not exist |
As seen in the diaglog’s result when testing the connection:
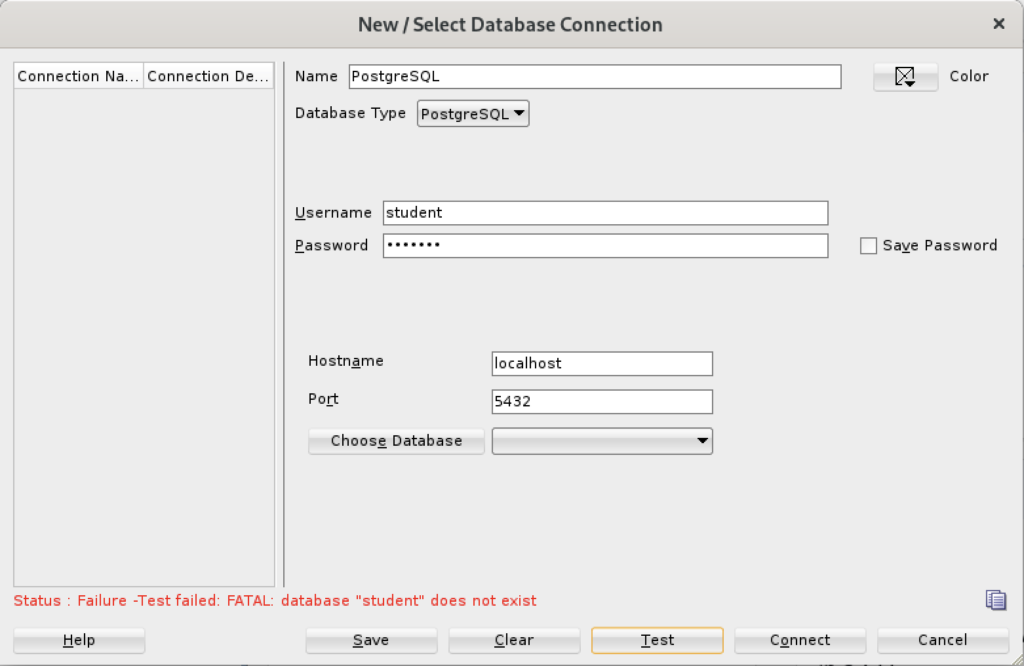
Based on my hunch and not knowing how to populate the database field for the connection, I did the following:
- Created a Linux OS videodb user.
- Copied the .bashrc file with all the standard Oracle environment variables.
- Created the /home/videodb/.sqldeveloper/jdbc directory.
- Copied the postgresql-42.3.7.jar into the new jdbc directory.
- Connected as the postgres super user and created the PostgreSQL videodb user with this syntax:
CREATE USER videodb WITH ROLE dba ENCRYPTED PASSWORD 'cangetin';
- As the postgres super user, granted the following privileges:
-- Grant privileges on videodb database videodb user. GRANT ALL ON DATABASE "videodb" TO "videodb"; -- Connect to the videodb database. \c -- Grant privileges. GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO videodb; GRANT ALL PRIVILEGES ON ALL SEQUENCES IN SCHEMA public TO videodb;
- Added the following line to the pg_hba.conf file in the /var/lib/pgsql/15/data directory as the postgres user:
local all videodb peer - Connected as the switched from the student to videodb Linux user, and launched SQL Developer. Then, I used the Tools menu to create the 3rd party PostgreSQL JDBC Java ARchive (.jar) file in context of the SQL Developer program. Everything completed correctly.
- Created a new PostgreSQL connection in SQL Developer and tested it with success as shown:
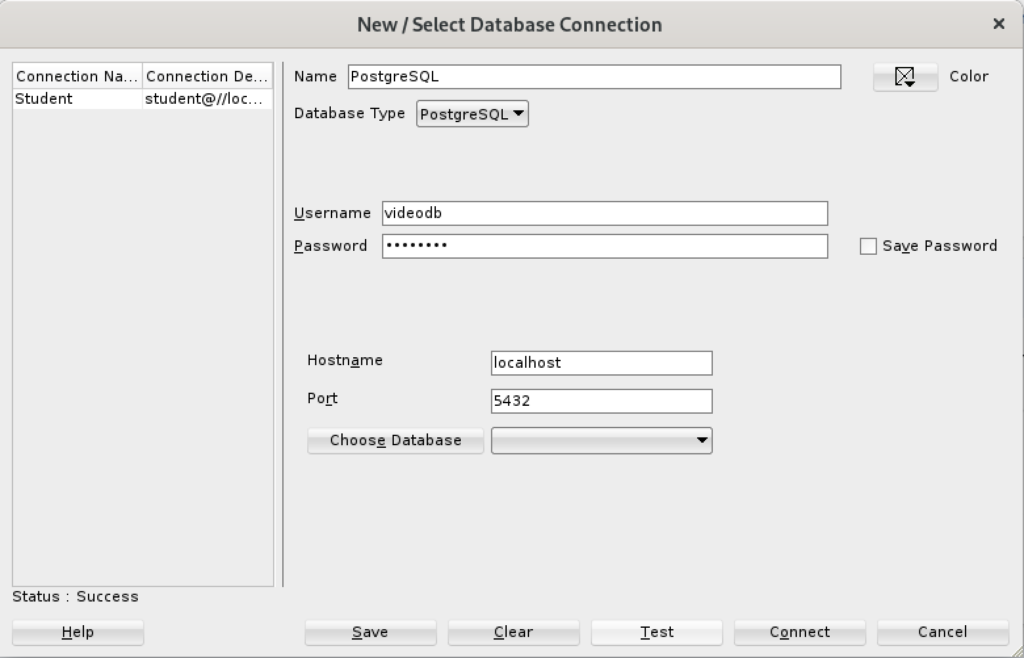
- Saving the new PostgreSQL connection, I opened the connection and could run SQL statements and display the catalog information, as shown:
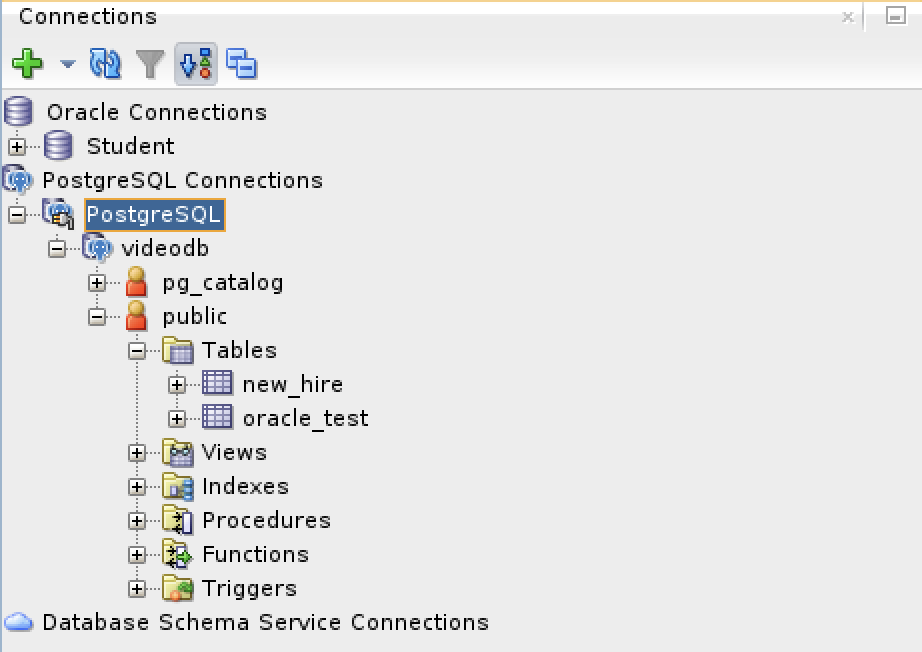
Connected as the videodb user to the videodb database I can display tables owned by student and videodb users:
-- List tables. \d List of relations Schema | Name | Type | Owner --------+--------------------------+----------+--------- public | new_hire | table | student public | new_hire_new_hire_id_seq | sequence | student public | oracle_test | table | videodb (3 rows)
In SQL Developer, you can also inspect the tables, as shown:

At this point, I’m working on trying to figure out how to populate the database drop-down table. However, I’ve either missed a key document or it’s unfortunate that SQL Developer isn’t as friendly as MySQL Workbench in working with 3rd Party drivers.
A tkprof Korn Shell
Reviewing old files, I thought posting my tkprof.ksh would be helpful. So, here’s the script that assumes you’re using Oracle e-Business Suite (Demo database, hence the APPS/APPS connection); and if I get a chance this summer I’ll convert it to Bash shell.
#!/bin/ksh
# -------------------------------------------------------------------------
# Author: Michael McLaughlin
# Name: tkprof.ksh
# Purpose: The program takes the following arguments:
# 1. A directory
# 2. A search string
# 3. A target directory
# It assumes raw trace files have an extension of ".trc".
# The output file name follows this pattern (because it is
# possible for multiple tracefiles to be written during the
# same minute).
# -------------------------------------------------------------------------
# Function to find minimum field delimiter.
function min
{
# Find the whitespace that preceeds the file date.
until [[ $(ls -al $i | cut -c$minv-$minv) == " " ]]; do
let minv=minv+1
done
}
# Function to find maximum field delimiter.
function max
{
# Find the whitespace that succeeds the file date.
until [[ $(ls -al $i | cut -c$maxv-$maxv) == " " ]]; do
let maxv=maxv+1
done
}
# Debugging enabled by unremarking the "set -x"
# set -x
# Print header information
print =================================================================
print Running [tkprof.ksh] script ...
# Evaluate whether an argument is provide and if no argument
# is provided, then substitute the present working directory.
if [[ $# == 0 ]]; then
dir=${PWD}
str="*"
des=${PWD}
elif [[ $# == 1 ]]; then
dir=${1}
str="*"
des=${1}
elif [[ $# == 2 ]]; then
dir=${1}
str=${2}
des=${1}
elif [[ $# == 3 ]]; then
dir=${1}
str=${2}
des=${3}
fi
# Evaluate whether the argument is a directory file.
if [[ -d ${dir} ]] && [[ -d ${des} ]]; then
# Print what directory and search string are targets.
print =================================================================
print Run in tkprof from [${dir}] directory ...
print The files contain a string of [${str}] ...
print =================================================================
# Evaluate whether the argument is the present working
# directory and if not change directory to that target
# directory so file type evaluation will work.
if [[ ${dir} != ${PWD} ]]; then
cd ${dir}
fi
# Set file counter.
let fcnt=0
# Submit compression to the background as a job.
for i in $(grep -li "${str}" *.trc); do
# Evaluate whether file is an ordinary file.
if [[ -f ${i} ]]; then
# Set default values each iteration.
let minv=40
let maxv=53
# Increment counter.
let fcnt=fcnt+1
# Call functions to reset min and max values where necessary.
min ${i}
max ${i}
# Parse date stamp from trace file without multiple IO calls.
# Assumption that the file is from the current year.
date=$(ls -al ${i} | cut -c${minv}-${maxv})
mon=$(echo ${date} | cut -c1-3)
yr=$(date | cut -c25-28)
# Validate month is 10 or greater to pad for reduced whitespace.
if (( $(echo ${date} | cut -c5-6) < 10 )); then
day=0$(echo ${date}| cut -c5-5)
hr=$(echo ${date} | cut -c7-8)
min=$(echo ${date} | cut -c10-11)
else
day=$(echo ${date} | cut -c5-6)
hr=$(echo ${date} | cut -c8-9)
min=$(echo ${date} | cut -c11-12)
fi
fn=file${fcnt}_${day}-${mon}-${yr}_${hr}:${min}:${day}
print Old [$i] and new [$des/$fn]
tkprof ${i} ${des}/${fn}.prf explain=APPS/APPS sort='(prsela,exeela,fchela)'
# Print what directory and search string are targets.
print =================================================================
fi
done
else
# Print message that a directory argument was not provided.
print You failed to provie a single valid directory argument.
fi |
I hope this helps those looking for a solution.
Listener for APEX
Unless dbca lets us build the listener.ora file, we often leave off some component. For example, running listener control program the following status indicates an incorrectly configured listener.ora file.
lsnrctl status |
It returns the following, which displays an endpoint for the XDB Server (I’m using Oracle Database 11g XE because it’s pre-containerized and has a small testing footprint):
LSNRCTL for Linux: Version 11.2.0.2.0 - Production on 24-MAR-2023 00:59:06 Copyright (c) 1991, 2011, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC_FOR_XE))) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 11.2.0.2.0 - Production Start Date 21-MAR-2023 21:17:37 Uptime 2 days 3 hr. 41 min. 29 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Default Service XE Listener Parameter File /u01/app/oracle/product/11.2.0/xe/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/localhost/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC_FOR_XE))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=8080))(Presentation=HTTP)(Session=RAW)) Services Summary... Service "PLSExtProc" has 1 instance(s). Instance "PLSExtProc", status UNKNOWN, has 1 handler(s) for this service... Service "XE" has 1 instance(s). Instance "XE", status READY, has 1 handler(s) for this service... Service "XEXDB" has 1 instance(s). Instance "XE", status READY, has 1 handler(s) for this service... The command completed successfully |
The listener is missing the second SID_LIST_LISTENER value of CLRExtProc value. A complete listener.ora file should be as follows for the Oracle Database XE:
# listener.ora Network Configuration FILE: SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME = PLSExtProc) (ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe) (PROGRAM = extproc) ) (SID_DESC = (SID_NAME = CLRExtProc) (ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe) (PROGRAM = extproc) ) ) LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) (ADDRESS = (PROTOCOL = TCP)(HOST = localhost.localdomain)(PORT = 1521)) ) ) DEFAULT_SERVICE_LISTENER = (XE) |
With this listener.ora file, the Oracle listener control utility will return the following correct status, which hides the XDB Server’s endpoint:
LSNRCTL for Linux: Version 11.2.0.2.0 - Production on 24-MAR-2023 02:38:57 Copyright (c) 1991, 2011, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC_FOR_XE))) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 11.2.0.2.0 - Production Start Date 24-MAR-2023 02:38:15 Uptime 0 days 0 hr. 0 min. 42 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Default Service XE Listener Parameter File /u01/app/oracle/product/11.2.0/xe/network/admin/listener.ora Listener Log File /u01/app/oracle/product/11.2.0/xe/log/diag/tnslsnr/localhost/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC_FOR_XE))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1521))) Services Summary... Service "CLRExtProc" has 1 instance(s). Instance "CLRExtProc", status UNKNOWN, has 1 handler(s) for this service... Service "PLSExtProc" has 1 instance(s). Instance "PLSExtProc", status UNKNOWN, has 1 handler(s) for this service... The command completed successfully |
It seems a number of examples on the web left the SID_LIST_LISTENER value of CLRExtProc value out of the listener.ora file. As always, I hope this helps those looking for a complete solution rather than generic instructions without a concrete example.
AWS EC2 TNS Listener
Having configured an AlmaLinux 8.6 with Oracle Database 11g XE, MySQL 8.0.30, and PostgreSQL 15, we migrated it to AWS EC2 and provisioned it. We used the older and de-supported Oracle Database 11g XE because it didn’t require any kernel modifications and had a much smaller footprint.
I had to address why attempting to connect with the sqlplus utility raised the following error after provisioning a copy with a new static IP address:
ERROR: ORA-12514: TNS:listener does NOT currently know OF service requested IN CONNECT descriptor |
A connection from SQL Developer raises a more addressable error, like:
ORA-17069 |
I immediately tried to check the connection with the tnsping utility and found that tnsping worked fine. However, when I tried to connect with the sqlplus utility it raised an ORA-12514 connection error.
There were no diagnostic steps beyond checking the tnsping utility. So, I had to experiment with what might block communication.
I changed the host name from ip-172-58-65-82.us-west-2.compute.internal to a localhost string in both the listener.ora and tnsnames.ora. The listener.ora file:
# listener.ora Network Configuration FILE: SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME = PLSExtProc) (ORACLE_HOME = /u01/app/oracle/product/11.2.0/xe) (PROGRAM = extproc) ) ) LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) (ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)) ) ) DEFAULT_SERVICE_LISTENER = (XE) |
The tnsnames.ora file:
# tnsnames.ora Network Configuration FILE: XE = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = XE) ) ) EXTPROC_CONNECTION_DATA = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE)) ) (CONNECT_DATA = (SID = PLSExtProc) (PRESENTATION = RO) ) ) |
I suspected that it might be related to the localhost value. So, I checked the /etc/hostname and /etc/hosts files.
Then, I modified /etc/hostname file by removing the AWS EC2 damain address. I did it on a memory that Oracle’s TNS raises errors for dots or periods in some addresses.
The /etc/hostname file:
ip-172-58-65-82 |
The /etc/hosts file:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ip-172-58-65-82 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 ip-172-58-65-82 |
Now, we can connect to the Oracle Database 11g XE instance with the sqlplus utility. I believe this type of solution will work for other AWS EC2 provisioned Oracle databases.
GROUP BY Quirk
It’s always interesting to see how others teach SQL courses. It can be revealing as to whether they understand SQL or only understand a dialect of SQL. In this case, one of my old students was taking a graduate course in SQL and the teacher was using MySQL. The teacher made an issue of using ANSI SQL:1999 or SQL3 and asked the following question, which I suspect is a quiz bank question from a textbook:
“How would you get all students’ names and for each student the number of courses that the
student has registered for?”
They referenced the MySQL 5.7 documentation for the GROUP BY and SQL:1999 as if MySQL implemented the ANSI SQL:1999 specification defined the standard. I didn’t know whether to laugh or cry because they were referring to MySQL 5.7 when we’re all using MySQL 8 and anybody who’s worked in more than MySQL knows that the behavior for a GROUP BY in MySQL can work without listing the necessary non-aggregated columns in the SELECT-list.
For example, their working solution, which is from the instructor and the author of their MySQL textbook the correct perspective of ANSI:1999 behavior. It doesn’t matter that their solution is actually based on ANSI:1992 not ANSI:1999 because it will only succeed because of a quirk of MySQL:
SELECT a.studentname , COUNT(b.courseid) FROM students a INNER JOIN registeredcourses b ON a.studentid = b.studentid GROUP BY a.studentid; |
While it works in MySQL, it doesn’t work because it conforms to an ANSI standard. It works in MySQL, notwithstanding that standard because it violates the standard.
In Oracle, PostgreSQL, and SQL Server, it raises an exception. For example, Oracle raises the following exception:
SELECT a.studentname
*
ERROR at line 1:
ORA-00979: not a GROUP BY expression |
The correct way to write the GROUP BY is:
SELECT a.studentname , COUNT(b.courseid) FROM students a INNER JOIN registeredcourses b ON a.studentid = b.studentid INNER JOIN courses c ON b.courseid = c.courseid GROUP BY a.studentname; |
Then, it would return:
Student Name Course IDs ------------------------------ ---------- Montgomery Scott 1 Leonard McCoy 2 James Tiberus Kirk 3 |
For reference, here’s a complete test case for MySQL:
/* Drop table conditionally. */ DROP TABLE IF EXISTS students; /* Create table. */ CREATE TABLE students ( studentID int unsigned primary key auto_increment , studentName varchar(30)); /* Drop table conditionally. */ DROP TABLE IF EXISTS courses; /* Create table. */ CREATE TABLE courses ( courseid int unsigned primary key auto_increment , coursename varchar(40)); /* Drop table conditionally. */ DROP TABLE IF EXISTS registeredcourses; /* Create table. */ CREATE TABLE registeredcourses ( courseid int unsigned , studentid int unsigned ); /* Insert into students. */ INSERT INTO students ( studentName ) VALUES ('James Tiberus Kirk') ,('Leonard McCoy') ,('Montgomery Scott'); /* Insert into courses. */ INSERT INTO courses ( coursename ) VALUES ('English Literature') ,('Physics') ,('English Composition') ,('Botany') ,('Mechanical Engineering'); /* Insert into registeredcourses. */ INSERT INTO registeredcourses ( studentid , courseid ) VALUES (1,1) ,(1,3) ,(1,4) ,(2,2) ,(2,5) ,(3,4); /* Check global sql_mode to ensure only_full_group_by is set. */ SELECT @@GLOBAL.SQL_MODE; /* Query with a column not found in the SELECT-list. */ SELECT a.studentname , COUNT(b.courseid) FROM students a INNER JOIN registeredcourses b ON a.studentid = b.studentid GROUP BY a.studentid; /* Query consistent with ANSI SQL:1992 */ SELECT a.studentname , COUNT(b.courseid) FROM students a INNER JOIN registeredcourses b ON a.studentid = b.studentid INNER JOIN courses c ON b.courseid = c.courseid GROUP BY a.studentname; |
and, another complete test case for Oracle:
/* Drop tabhe unconditionallly. */ DROP TABLE students; /* Create table. */ CREATE TABLE students ( studentID NUMBER PRIMARY KEY , studentName VARCHAR(30)); /* Drop table unconditionally. */ DROP TABLE courses; /* Create table. */ CREATE TABLE courses ( courseid NUMBER PRIMARY KEY , coursename VARCHAR(40)); /* Drop table unconditionally. */ DROP TABLE registeredcourses; /* Create table. */ CREATE TABLE registeredcourses ( courseid NUMBER , studentid NUMBER ); /* Insert values in student. */ INSERT INTO students ( studentid, studentName ) VALUES (1,'James Tiberus Kirk'); INSERT INTO students ( studentid, studentName ) VALUES (2,'Leonard McCoy'); INSERT INTO students ( studentid, studentName ) VALUES (3,'Montgomery Scott'); /* Insert values in courses. */ INSERT INTO courses ( courseid, coursename ) VALUES (1,'English Literature'); INSERT INTO courses ( courseid, coursename ) VALUES (2,'Physics'); INSERT INTO courses ( courseid, coursename ) VALUES (3,'English Composition'); INSERT INTO courses ( courseid, coursename ) VALUES (4,'Botany'); INSERT INTO courses ( courseid, coursename ) VALUES (5,'Mechanical Engineering'); /* Insert values into registeredcourses. */ INSERT INTO registeredcourses ( studentid, courseid ) VALUES (1,1); INSERT INTO registeredcourses ( studentid, courseid ) VALUES (1,3); INSERT INTO registeredcourses ( studentid, courseid ) VALUES (1,4); INSERT INTO registeredcourses ( studentid, courseid ) VALUES (2,2); INSERT INTO registeredcourses ( studentid, courseid ) VALUES (2,5); INSERT INTO registeredcourses ( studentid, courseid ) VALUES (3,4); /* Non-ANSI SQL GROUP BY statement. */ SELECT a.studentname , COUNT(b.courseid) FROM students a INNER JOIN registeredcourses b ON a.studentid = b.studentid GROUP BY a.studentid; /* ANSI SQL GROUP BY statement. */ SELECT a.studentname AS "Student Name" , COUNT(b.courseid) AS "Course IDs" FROM students a INNER JOIN registeredcourses b ON a.studentid = b.studentid INNER JOIN courses c ON b.courseid = c.courseid GROUP BY a.studentname; |
I hope this helps those learning the correct way to write SQL.
DML Event Management
Data Manipulation Language (DML)
DML statements add data to, change data in, and remove data from tables. This section examines four DML statements—the INSERT, UPDATE, DELETE, and MERGE statements—and builds on concepts of data transactions. The INSERT statement adds new data, the UPDATE statement changes data, the DELETE statement removes data from the database, and the MERGE statement either adds new data or changes existing data.
Any INSERT, UPDATE, MERGE, or DELETE SQL statement that adds, updates, or deletes rows in a table locks rows in a table and hides the information until the change is committed or undone (that is, rolled back). This is the nature of ACID-compliant SQL statements. Locks prevent other sessions from making a change while a current session is working with the data. Locks also restrict other sessions from seeing any changes until they’re made permanent. The database keeps two copies of rows that are undergoing change. One copy of the rows with pending changes is visible to the current session, while the other displays committed changes only.
ACID Compliant Transactions
ACID compliance relies on a two-phase commit (2PC) protocol and ensures that the current session is the only one that can see new inserts, updated column values, and the absence of deleted rows. Other sessions run by the same or different users can’t see the changes until you commit them.
ACID Compliant INSERT Statements
The INSERT statement adds rows to existing tables and uses a 2PC protocol to implement ACID- compliant guarantees. The SQL INSERT statement is a DML statement that adds one or more rows to a table. Oracle supports a VALUES clause when adding a single-row, and support a subquery when adding one to many rows.
The figure below shows a flow chart depicting an INSERT statement. The process of adding one or more rows to a table occurs during the first phase of an INSERT statement. Adding the rows exhibits both atomic and consistent properties. Atomic means all or nothing: it adds one or more rows and succeeds, or it doesn’t add any rows and fails. Consistent means that the addition of rows is guaranteed whether the database engine adds them sequentially or concurrently in threads.
Concurrent behaviors happen when the database parallelizes DML statements. This is similar to the concept of threads as lightweight processes that work under the direction of a single process. The parallel actions of a single SQL statement delegate and manage work sent to separate threads. Oracle supports all ACID properties and implements threaded execution as parallel operations. All tables support parallelization.

After adding the rows to a table, the isolation property prevents any other session from seeing the new rows—that means another session started by the same user or by another user with access to the same table. The atomic, consistent, and isolation properties occur in the first phase of any INSERT statement. The durable property is exclusively part of the second phase of an INSERT statement, and rows become durable when the COMMIT statement ratifies the insertion of the new data.
ACID Compliant UPDATE Statements
An UPDATE statement changes column values in one-to-many rows. With a WHERE clause, you update only rows of interest, but if you forget the WHERE clause, an UPDATE statement would run against all rows in a table. Although you can update any column in a row, it’s generally bad practice to update a primary or foreign key column because you can break referential integrity. You should only update non-key data in tables—that is, the data that doesn’t make a row unique within a table.
Changes to column values are atomic when they work. For scalability reasons, the database implementation of updates to many rows is often concurrent, in threads through parallelization. This process can span multiple process threads and uses a transaction paradigm that coordinates changes across the threads. The entire UPDATE statement fails when any one thread fails.
Similar to the INSERT statement, UPDATE statement changes to column values are also hidden until they are made permanent with the application of the isolation property. The changes are hidden from other sessions, including sessions begun by the same database user.
It’s possible that another session might attempt to lock or change data in a modified but uncommitted row. When this happens, the second DML statement encounters a lock and goes into a wait state until the row becomes available for changes. If you neglected to set a timeout value for the wait state, such as this clause, the FOR UPDATE clause waits until the target rows are unlocked:
WAIT n |
As the figure below shows, actual updates are first-phase commit elements. While an UPDATE statement changes data, it changes only the current session values until it is made permanent by a COMMIT statement. Like the INSERT statement, the atomic, consistent, and isolation properties of an UPDATE statement occur during the first phase of a 2PC process. Changes to column values are atomic when they work. Any column changes are hidden from other sessions until the UPDATE statement is made permanent by a COMMIT or ROLLBACK statement, which is an example of the isolation property.
Any changes to column values can be modified by an ON UPDATE trigger before a COMMIT statement. ON UPDATE triggers run inside the first phase of the 2PC process. A COMMIT or ROLLBACK statement ends the transaction scope of the UPDATE statement.
The Oracle database engine can dispatch changes to many threads when an UPDATE statement works against many rows. UPDATE statements are consistent when these changes work in a single thread-of-control or across multiple threads with the same results.

As with the INSERT statement, the atomic, consistent, and isolation properties occur during the first phase of any UPDATE statement, and the COMMIT statement is the sole activity of the second phase. Column value changes become durable only with the execution of a COMMIT statement.
ACID Compliant DELETE Statements
A DELETE statement removes rows from a table. Like an UPDATE statement, the absence of a WHERE clause in a DELETE statement deletes all rows in a table. Deleted rows remain visible outside of the transaction scope where it has been removed. However, any attempts to UPDATE those deleted rows are held in a pending status until they are committed or rolled back.
You delete rows when they’re no longer useful. Deleting rows can be problematic when rows in another table have a dependency on the deleted rows. Consider, for example, a customer table that contains a list of cell phone contacts and an address table that contains the addresses for some but not all of the contacts. If you delete a row from the customer table that still has related rows in the address table, those address table rows are now orphaned and useless.
As a rule, you delete data from the most dependent table to the least dependent table, which is the opposite of the insertion process. Basically, you delete the child record before you delete the parent record. The parent record holds the primary key value, and the child record holds the foreign key value. You drop the foreign key value, which is a copy of the primary key, before you drop the primary key record. For example, you would insert a row in the customer table before you insert a row in the address table, and you delete rows from the address table before you delete rows in the customer table.
The figure below shows the logic behind a DELETE statement. Like the INSERT and UPDATE statements, acid, consistency, and isolation properties of the ACID-compliant transaction are managed during the first phase of a 2PC. The durability property is managed by the COMMIT or ROLLBACK statement.

There’s no discussion or diagrams for the MERGE statement because it does either an INSERT or UPDATE statement based on it’s internal logic. That means a MERGE statement is ACID compliant like an INSERT or UPDATE statement.
AlmaLinux Install & Configuration

This is a collection of blog posts for installing and configuring AlmaLinux with the Oracle, PostgreSQL, MySQL databases and several programming languages. Sample programs show how to connect PHP and Python to the MySQL database.
- Installing AlmaLinux operating system
- Installing and configuring MySQL
- Installing Python-MySQL connector and provide sample programs
- Configuring Flask for Python on AlmaLinux with a complete software router instruction set.
- Installing Rust programming language and writing a sample program
- Installing and configuring LAMP stack with PHP and MySQL and a self-signed security key
- MySQL PNG Images in LAMP with PHP Programming
- Demonstration of how to write Perl that connects to MySQL
- Installing and configuring MySQL Workbench
- Installing and configuring PostgreSQL and pgAdmin4
- Identifying the required libnsl2-devel packages for SQL*Plus
- Writing and deploying a sqlplus function to use a read line wrapper
- Installing and configuring Visual Studio Code Editor
- Installing and configuring Java with connectivity to MySQL
- Installing and configuring Oracle SQL Developer
I used Oracle Database 11g XE in this instance to keep the footprint as small as possible. It required a few tricks and discovering the missing library that caused folks grief eleven years ago. I build another with a current Oracle Database XE after the new year.
If you see something that I missed or you’d like me to add, let me know. As time allows, I’ll try to do that. Naturally, the post will get updates as things are added later.
AlmaLinux+SQLDeveloper
This post makes the assumption that you’ve installed the current version of Java and the Java SDK. If you haven’t, you can find instructions on my blog. You will also need to have an installation of the Oracle database running on your server or a remote service, or cloud micro service.
The remainder of this post deals with downloading, installing, and configuring Oracle’s SQL Developer for AlmaLinux 9, which is the GNU version of Red Hat Enterprise 9.
- Go to Oracle’s download site and download the sqldeveloper RPM file. You will need to provide your Oracle credentials to download SQL Developer. It will download to your sudoer account’s Download directory. In this example the sudoer user is the student user.
You should see the following web page and click on the Download link, provided you’re installing on Linux it’ll look like the next image.

Then, you need to accept the license and click the Download button. Oracle will prompt you for your credentials if you’re not logged in on the web page already.

- Next, you need to navigate to the Downloads directory and install the sqldeveloper RPM. Assuming your sudoer user is student, you can get to the Downloads directory with the following command.
cd ~student/Downloads
Assuming, you downloaded the SQL Developer package, you can use the following command to install any downloaded version of sqldeveloper package.
sudo rpm -Uvh `ls sqldeveloper*.rpm`
The log file for this is:
Display detailed console log →
warning: RPM v3 packages are deprecated: sqldeveloper-22.2.1-234.1810.noarch Verifying... ################################# [100%] Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing... ################################# [100%] warning: RPM v3 packages are deprecated: sqldeveloper-22.2.1-234.1810.noarch Updating / installing... 1:sqldeveloper-22.2.1-234.1810 ################################# [100%]
- Click on Activities link in the upper left corner and then the clustered nine dots to view applications. Choose the SQL Developer icon and double click and you should see the following dialog if you’re a first time user. Unless you’re upgrading, click the No button to proceed.

- The first official screen after checking whether you need to transfer existing settings wants to know whether or allow or disallow user tracking. Click the OK button if you don’t mind Oracle tracking your use, or click the Allow automated usage reporting to Oracle checkbox to disallow Oracle tracking your use before you click the OK button.

- The next screen lets you set up a TNS names file or use an existing file. I clicked on the XE existing database to continue.

This is a password prompt for the TNS name resolution of XE, which should point to the Oracle Database 11g Express Edition. (I’d use a more current version but I couldn’t resist using the smaller footprint of the pre-containerized Oracle databases.)

Replace XE with the name of a sandboxed user, like student, and the password for the student user before you click the OK button. (If you don’t know what a sandboxed user is, you should. It’s a user with limited access to a database of the same name in the context of an Oracle database. A non-sandboxed user has global privileges like the system user.)
- The next screen lets you enter SQL statements agains the student database. You can click the X button in the top right corner to close the application.

You’ve now installed SQL Developer. However, sometimes I want to start SQL Developer from the command-line interface (CLI) but you’ll get a bunch of warnings and unnecessary Java non-critical errors. So, I create an alias to avoid the extraneous noise. I create the sqldeveloper alias in the .bashrc file for it. You can create a sqldeveloper alias by adding the following line to your .bashrc file:
The unnecessary noise when you don’t create a sqldeveloper alias.
Display detailed console log →
Oracle SQL Developer Copyright (c) 2005, 2021, Oracle and/or its affiliates. All rights reserved. OpenJDK 64-Bit Server VM warning: Options -Xverify:none and -noverify were deprecated in JDK 13 and will likely be removed in a future release. WARNING: A terminally deprecated method in java.lang.System has been called WARNING: System::setSecurityManager has been called by org.netbeans.TopSecurityManager (file:/opt/sqldeveloper/netbeans/platform/lib/boot.jar) WARNING: Please consider reporting this to the maintainers of org.netbeans.TopSecurityManager WARNING: System::setSecurityManager will be removed in a future release WARNING: A terminally deprecated method in java.lang.System has been called WARNING: System::setSecurityManager has been called by oracle.ide.IdeCore (file:/opt/sqldeveloper/ide/extensions/oracle.ide.jar) WARNING: Please consider reporting this to the maintainers of oracle.ide.IdeCore WARNING: System::setSecurityManager will be removed in a future release java.lang.IllegalAccessException: class oracle.ideimpl.config.EnvironOptionsPanel cannot access class com.sun.java.swing.plaf.gtk.GTKLookAndFeel (in module java.desktop) because module java.desktop does not export com.sun.java.swing.plaf.gtk to unnamed module @49c746f at java.base/jdk.internal.reflect.Reflection.newIllegalAccessException(Reflection.java:392) at java.base/java.lang.reflect.AccessibleObject.checkAccess(AccessibleObject.java:674) at java.base/java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:489) at java.base/java.lang.reflect.ReflectAccess.newInstance(ReflectAccess.java:128) at java.base/jdk.internal.reflect.ReflectionFactory.newInstance(ReflectionFactory.java:347) at java.base/java.lang.Class.newInstance(Class.java:645) at oracle.ideimpl.config.EnvironOptionsPanel._initLafCombo(EnvironOptionsPanel.java:540) at oracle.ideimpl.config.EnvironOptionsPanel.initComponents(EnvironOptionsPanel.java:238) at oracle.ideimpl.config.EnvironOptionsPanel.<init>(EnvironOptionsPanel.java:99) at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:77) at java.base/jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.base/java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:499) at java.base/java.lang.reflect.Constructor.newInstance(Constructor.java:480) at javax.ide.util.MetaClass.newInstance(MetaClass.java:145) at oracle.dbtools.raptor.standalone.IndexedPreferencesCommand$IndexPreferencesTask.doWork(IndexedPreferencesCommand.java:122) at oracle.dbtools.raptor.standalone.IndexedPreferencesCommand$IndexPreferencesTask.doWork(IndexedPreferencesCommand.java:65) at oracle.dbtools.raptor.backgroundTask.RaptorTask.call(RaptorTask.java:199) at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) at oracle.dbtools.raptor.backgroundTask.RaptorTaskManager$RaptorFutureTask.run(RaptorTaskManager.java:702) at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:539) at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) at java.base/java.lang.Thread.run(Thread.java:833) java.lang.IllegalAccessException: class oracle.ideimpl.config.EnvironOptionsPanel cannot access class com.sun.java.swing.plaf.gtk.GTKLookAndFeel (in module java.desktop) because module java.desktop does not export com.sun.java.swing.plaf.gtk to unnamed module @49c746f at java.base/jdk.internal.reflect.Reflection.newIllegalAccessException(Reflection.java:392) at java.base/java.lang.reflect.AccessibleObject.checkAccess(AccessibleObject.java:674) at java.base/java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:489) at java.base/java.lang.reflect.ReflectAccess.newInstance(ReflectAccess.java:128) at java.base/jdk.internal.reflect.ReflectionFactory.newInstance(ReflectionFactory.java:347) at java.base/java.lang.Class.newInstance(Class.java:645) at oracle.ideimpl.config.EnvironOptionsPanel._initLafCombo(EnvironOptionsPanel.java:540) at oracle.ideimpl.config.EnvironOptionsPanel.initComponents(EnvironOptionsPanel.java:238) at oracle.ideimpl.config.EnvironOptionsPanel.<init>(EnvironOptionsPanel.java:99) at oracle.dbtools.raptor.config.EnvironOptionsPanelWrapper.<init>(EnvironOptionsPanelWrapper.java:30) at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:77) at java.base/jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.base/java.lang.reflect.Constructor.newInstanceWithCaller(Constructor.java:499) at java.base/java.lang.reflect.Constructor.newInstance(Constructor.java:480) at javax.ide.util.MetaClass.newInstance(MetaClass.java:145) at oracle.dbtools.raptor.standalone.IndexedPreferencesCommand$IndexPreferencesTask.doWork(IndexedPreferencesCommand.java:122) at oracle.dbtools.raptor.standalone.IndexedPreferencesCommand$IndexPreferencesTask.doWork(IndexedPreferencesCommand.java:65) at oracle.dbtools.raptor.backgroundTask.RaptorTask.call(RaptorTask.java:199) at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) at oracle.dbtools.raptor.backgroundTask.RaptorTaskManager$RaptorFutureTask.run(RaptorTaskManager.java:702) at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:539) at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264) at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136) at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635) at java.base/java.lang.Thread.run(Thread.java:833) |
You create the alias like this:
alias sqldeveloper="sqldeveloper 2>/dev/null &" |
That completes the instructions. Good luck with SQL Developer. It’s a great tool.
Wrapping sqlplus
After sorting out the failures of Oracle Database 11g (11.2.0) on AlmaLinux, I grabbed the Enterprise Linux 9 rlwrap library. The rlwrap is a ‘readline wrapper’ that uses the GNU readline library to
allow the editing of keyboard input for any other command. Input history is remembered across invocations, separately for each command; history completion and search work as in bash and completion word
lists can be specified on the command line.
Installed it with the dnf utility:
dnf install -y rlwrap |
It gave me this log file:
Last metadata expiration check: 0:53:30 ago on Fri 02 Dec 2022 01:07:54 AM EST. Dependencies resolved. ================================================================================================================================ Package Architecture Version Repository Size ================================================================================================================================ Installing: rlwrap x86_64 0.45.2-3.el9 epel 132 k Transaction Summary ================================================================================================================================ Install 1 Package Total download size: 132 k Installed size: 323 k Downloading Packages: rlwrap-0.45.2-3.el9.x86_64.rpm 162 kB/s | 132 kB 00:00 -------------------------------------------------------------------------------------------------------------------------------- Total 117 kB/s | 132 kB 00:01 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : rlwrap-0.45.2-3.el9.x86_64 1/1 Running scriptlet: rlwrap-0.45.2-3.el9.x86_64 1/1 Verifying : rlwrap-0.45.2-3.el9.x86_64 1/1 Installed: rlwrap-0.45.2-3.el9.x86_64 Complete! |
Then, I added this sqlplus function to the student account’s .bashrc file:
sqlplus () { # Discover the fully qualified program name. path=`which rlwrap 2>/dev/null` file='' # Parse the program name from the path. if [ -n ${path} ]; then file=${path##/*/} fi; # Wrap when there is a file and it is rewrap. if [ -n ${file} ] && [[ ${file} = "rlwrap" ]]; then rlwrap sqlplus "${@}" else echo "Command-line history unavailable: Install the rlwrap package." $ORACLE_HOME/bin/sqlplus "${@}" fi } |
Then, I connected to the old, but tiny, footprint of Oracle Database 11g XE for testing, which worked:

Yes, I couldn’t resist. After all Version 11 was the last non-pluggable release and it’s been 11 years since its release. A double lucky 11.
Naturally, you can always use vi (or vim) to edit the command history provided you include the following command in your .bashrc file:
set -o vi |
Next, I’ll build a new VM instance with the current version of Oracle Database XE for student testing.
As always, I hope this helps those working with Oracle’s database products.
Oracle Library Missing
It was always aware of a problem with Oracle 11g XE on various Linux platforms from 10 years ago. I knew it was misleading but never found the time to explain the error that occurred during the cloning of the instance.
While it would occur when you were on an unsupported version of Linux, it was easy to fix. For example, after downloading the old compressed oracle-xe-11.2.0-1.0.x86_64.rpm.zip file, you uncompress it. Then, you run the file with the following command:
rpm -ivh oracle-xe-11.2.0-1.0.x86_64.rpm |
This command will install the packages in verbose syntax and display the following messages:
[sudo] password for mclaughlinm: Preparing packages for installation... oracle-xe-11.2.0-1.0 Executing post-install steps... You must run '/etc/init.d/oracle-xe configure' as the root user to configure the database. |
Connect as the root user to another instance of the terminal and run the following command:
/etc/init.d/oracle-xe configure |
You will see the following control output:
Oracle Database 11g Express Edition Configuration ------------------------------------------------- This will configure on-boot properties of Oracle Database 11g Express Edition. The following questions will determine whether the database should be starting upon system boot, the ports it will use, and the passwords that will be used for database accounts. Press <Enter> to accept the defaults. Ctrl-C will abort. Specify the HTTP port that will be used for Oracle Application Express [8080]: Specify a port that will be used for the database listener [1521]: Specify a password to be used for database accounts. Note that the same password will be used for SYS and SYSTEM. Oracle recommends the use of different passwords for each database account. This can be done after initial configuration: Confirm the password: Do you want Oracle Database 11g Express Edition to be started on boot (y/n) [y]:y Starting Oracle Net Listener...Done Configuring database...grep: /u01/app/oracle/product/11.2.0/xe/config/log/*.log: No such file or directory grep: /u01/app/oracle/product/11.2.0/xe/config/log/*.log: No such file or directory Done /bin/chmod: cannot access '/u01/app/oracle/diag': No such file or directory Starting Oracle Database 11g Express Edition instance...Done Installation completed successfully. |
This looks like an unsolvable problem, and for many it was too hard to solve. Most never knew the next step to take to discover the missing library. The failure actually occurs when the configuration tries to launch SQL*Plus. You can test that by creating the following oracle_env.sh parameter script:
# Oracle Settings TMP=/tmp; export TMP TMPDIR=$TMP; export TMPDIR ORACLE_HOSTNAME=localhost.localdomain; export ORACLE_HOSTNAME ORACLE_UNQNAME=DB11G; export ORACLE_UNQNAME ORACLE_BASE=/u01/app/oracle; export ORACLE_BASE ORACLE_HOME=$ORACLE_BASE/product/11.2.0/xe; export ORACLE_HOME ORACLE_SID=XE; export ORACLE_SID NLS_LANG=`$ORACLE_HOME/bin/nls_lang.sh`; export NLS_LANG ORACLE_TERM=xterm; export ORACLE_TERM PATH=/usr/sbin:$PATH; export PATH PATH=$ORACLE_HOME/bin:$PATH; export PATH LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib; export LD_LIBRARY_PATH CLASSPATH=$ORACLE_HOME/JRE:$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib; export CLASSPATH if [ $USER = "oracle" ]; then if [ $SHELL = "/bin/ksh" ]; then ulimit -p 16384 ulimit -n 65536 else ulimit -u 16384 -n 65536 fi fi |
Then, source the oracle_env.sh file like this:
. ./oracle_env.sh |
As the oracle user, try to connect to the sqlplus executable with this command:
sqlplus / as sysdba |
It’ll raise the following error:
sqlplus: error while loading shared libraries: libnsl.so.1: cannot open shared object file: No such file or directory |
You won’t find the /usr/lib64/libnsl.so.1 because it’s a symbolic link to the /usr/lib64/libnsl-2.29.so shared library file, which you can find on older Fedora installations. AlmaLinux has libnsl2, which you can download from the pgks.org.
After finding the library and installing it in the /usr/lib64 directory, the balance of the fix is to run the cloning manually. This type of error can occur for newer version of the database but it’s easiest to highlight with the Oracle 11g XE installation.
You also can find it in the libnsl2-devel development libraries on the pkgs.org web site:

You may need to build the libnsl.so.1 symbolic link as the root user with the following command:
ln -s libnsl-2.29.so libnsl.so.1 |
Ensure the file permissions for these files are:
-rwxr-xr-x. 1 root root 218488 Dec 2 01:33 libnsl-2.29.so lrwxrwxrwx. 1 root root 14 Dec 2 01:39 libnsl.so.1 -> libnsl-2.29.so |
After you create the database, you can provision a student user and database, like so:
Oracle Database 11g (Pre-containerization)
After you create and provision the Oracle Database 11g XE, you create an instance with the following two step process.
- Create a
studentOracle user account with the following command:CREATE USER student IDENTIFIED BY student DEFAULT TABLESPACE users QUOTA 200M ON users TEMPORARY TABLESPACE temp;
- Grant necessary privileges to the newly created
studentuser:GRANT CREATE CLUSTER, CREATE INDEXTYPE, CREATE OPERATOR , CREATE PROCEDURE, CREATE SEQUENCE, CREATE SESSION , CREATE TABLE, CREATE TRIGGER, CREATE TYPE , CREATE VIEW TO student;
Oracle Database 21c (Post-containerization)
After you create and provision the Oracle Database 21c Express Edition (XE), you can create a c##student container user with the following two step process.
- Create a c##student Oracle user account with the following command:
CREATE USER c##student IDENTIFIED BY student DEFAULT TABLESPACE users QUOTA 200M ON users TEMPORARY TABLESPACE temp;
- Grant necessary privileges to the newly created c##student user:
GRANT CREATE CLUSTER, CREATE INDEXTYPE, CREATE OPERATOR , CREATE PROCEDURE, CREATE SEQUENCE, CREATE SESSION , CREATE TABLE, CREATE TRIGGER, CREATE TYPE , CREATE VIEW TO c##student;
As always, it should help you solve new problems.
