Archive for the ‘PostgreSQL Developer’ tag
Go Config & PostgreSQL
Finally, I got around to building a GO environment with PostgreSQL on Ubuntu. Next, I’ll need to sort out how to extend it to Oracle and MySQL. The only tedious part was figuring out where the current PostgreSQL ODBC driver was on GitHub.
The installation of GO has two options. You can install the version from the Linux Distro’s repo, or you can install the most current version from the GO website. The generic install on Ubuntu uses the following two commands:
sudo apt update sudo apt install -y golang-go |
This will install GO in the /usr/bin directory, which means you don’t need to add it manually to your $PATH environment variable in your .bashrc file.
Download from the GO website into your /home/username/Downloads directory and then run this command:
sudo tar -C /usr/local -xzf /home/student/Downloads/go1.24.0.linux-amd64.tar.gz |
If you haven’t installed the distro’s repo of the GO programming environment, you should add this to your .bashrc file:
# Added to PATH for Go export set PATH=$PATH:/usr/local/go/bin |
However, add the following if you have installed the Linux distorts GO repo and prefer to use the most current release available (a which -a go command displays the go program files in your current $PATH variable and you can call the first one in the list without an absolute or fully qualified file name but the second requires a fully qualified file name):
# Added to PATH for Go export set PATH=/usr/local/go/bin:$PATH |
Now, you should decide where you want to put your GO programs. I chose to create a base .go directory and then project directories beneath that. Within each project directory you should create bin, pkg, and src subdirectories, as shown below:
mkdir .go .go/hello .go/hello/bin .go/hello/pkg .go/hello/src |
You can write a “Hello World” program like the following in you ~.go/hello/src directory, which I’ve named hello-world.go for illustrative purposes:
// Declare package. package main // Import library. import "fmt" // Define main function using fmt library to print. func main() { fmt.Println("Hello World!") } |
Next, you should create a makefile, like this in the same ~.go/hello/src directory. If you’re new to the rules for creating a makefile, there can be no leading or trailing white spaces, and you should use before commands:
.DEFAULT_GOAL := build .PHONY: fmt vet build fmt: go fmt ./... vet: fmt go vet ./... build: vet go build -o ../bin/hello hello-world.go |
Before you run the make utility, you need to initialize the module with this syntax:
go mod init |
It will create the go.mod file. You will see something like the following when you display the content of the go.mod file.
module hello-world.go go 1.24.0 |
You have completed your project preparation. You run the make command to create the hello executable in the ~/.go/hello/bin directory.
Run the make utility:
make |
You can run it from your current directory with this command:
~/.go/hello/bin/hello |
It will return to console:
Hello World! |
Having built the GO development environment and a rudimentary starting program, it’s time to learn how to write a GO program that queries the PostgreSQL database. The first step is finding the correct PostgreSQL library in GitHub.com. A number of web sites post examples using the pq library but that’s no longer correct.
You need to download the pgx ODBC driver with the following GO command:
go get github.com/jackc/pgx@latest |
It will display the following to the console:
go: downloading github.com/jackc/pgx v3.6.2+incompatible go: downloading github.com/pkg/errors v0.9.1 go: downloading golang.org/x/crypto v0.35.0 go: downloading golang.org/x/text v0.22.0 go: added github.com/jackc/pgx v3.6.2+incompatible go: added github.com/pkg/errors v0.9.1 go: added golang.org/x/crypto v0.35.0 go: added golang.org/x/text v0.22.0 |
To use the standard database/sql approach you’ll also need to run this command:
go get github.com/jackc/pgx/v5/stdlib |
It will display the following to the console:
go: downloading github.com/jackc/pgx/v5 v5.7.2 go: downloading github.com/jackc/pgpassfile v1.0.0 go: downloading github.com/jackc/pgservicefile v0.0.0-20240606120523-5a60cdf6a761 go: downloading github.com/jackc/puddle/v2 v2.2.2 go: downloading golang.org/x/sync v0.11.0 go: added github.com/jackc/pgpassfile v1.0.0 go: added github.com/jackc/pgservicefile v0.0.0-20240606120523-5a60cdf6a761 go: added github.com/jackc/pgx/v5 v5.7.2 go: added github.com/jackc/puddle/v2 v2.2.2 |
Change back to your home directory and run this command to build a new connect project:
mkdir .go/postgres .go/postgres/connect .go/postgres/connect/bin .go/postgres/connect/pkg .go/postgres/connect/src |
Create postgres-connect.go program in the .go/postgres/connect/src directory:
package main import ( "database/sql" "fmt" "os" _ "github.com/jackc/pgx/v5/stdlib" ) func main() { // Open connection and defer connection close. db, err := sql.Open("pgx", "host=localhost user=student password=student dbname=videodb sslmode=disable") if err != nil { fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err) os.Exit(1) } defer db.Close() // Declare an output variable for the query. var version string err = db.QueryRow("SELECT version()").Scan(&version) if err != nil { fmt.Fprintf(os.Stderr, "QueryRow failed: %v\n", err) os.Exit(1) } // Print database version. fmt.Println(version) } |
Next, you should create another makefile in the same ~.go/postgres/connect/src directory.
.DEFAULT_GOAL := build .PHONY: fmt vet build fmt: go fmt ./... vet: fmt go vet ./... build: vet go build -o ../bin/connect postgres-connect.go |
Before you run the make utility, you need to initialize the go.mod module file and check for dependencies in it. That requires the following two commands:
go mod init |
Which returns the following list of dependencies:
go: finding module for package github.com/jackc/pgx/v5/stdlib go: found github.com/jackc/pgx/v5/stdlib in github.com/jackc/pgx/v5 v5.7.2 |
There are two ways to fix this but the easiest is to run this command:
go mod tidy |
It adds the dependencies to the go.mod file. You will see something like the following when you display the content of the go.mod file.
module postgres-connect.go go 1.24.0 require github.com/jackc/pgx/v5 v5.7.2 require ( github.com/jackc/pgpassfile v1.0.0 // indirect github.com/jackc/pgservicefile v0.0.0-20240606120523-5a60cdf6a761 // indirect github.com/jackc/puddle/v2 v2.2.2 // indirect golang.org/x/crypto v0.31.0 // indirect golang.org/x/sync v0.10.0 // indirect golang.org/x/text v0.21.0 // indirect ) |
You should also note that the go mod tidy command created new go.sum file for the dependencies, which should look like the following:
github.com/davecgh/go-spew v1.1.0/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38= github.com/davecgh/go-spew v1.1.1 h1:vj9j/u1bqnvCEfJOwUhtlOARqs3+rkHYY13jYWTU97c= github.com/davecgh/go-spew v1.1.1/go.mod h1:J7Y8YcW2NihsgmVo/mv3lAwl/skON4iLHjSsI+c5H38= github.com/jackc/pgpassfile v1.0.0 h1:/6Hmqy13Ss2zCq62VdNG8tM1wchn8zjSGOBJ6icpsIM= github.com/jackc/pgpassfile v1.0.0/go.mod h1:CEx0iS5ambNFdcRtxPj5JhEz+xB6uRky5eyVu/W2HEg= github.com/jackc/pgservicefile v0.0.0-20240606120523-5a60cdf6a761 h1:iCEnooe7UlwOQYpKFhBabPMi4aNAfoODPEFNiAnClxo= github.com/jackc/pgservicefile v0.0.0-20240606120523-5a60cdf6a761/go.mod h1:5TJZWKEWniPve33vlWYSoGYefn3gLQRzjfDlhSJ9ZKM= github.com/jackc/pgx/v5 v5.7.2 h1:mLoDLV6sonKlvjIEsV56SkWNCnuNv531l94GaIzO+XI= github.com/jackc/pgx/v5 v5.7.2/go.mod h1:ncY89UGWxg82EykZUwSpUKEfccBGGYq1xjrOpsbsfGQ= github.com/jackc/puddle/v2 v2.2.2 h1:PR8nw+E/1w0GLuRFSmiioY6UooMp6KJv0/61nB7icHo= github.com/jackc/puddle/v2 v2.2.2/go.mod h1:vriiEXHvEE654aYKXXjOvZM39qJ0q+azkZFrfEOc3H4= github.com/pmezard/go-difflib v1.0.0 h1:4DBwDE0NGyQoBHbLQYPwSUPoCMWR5BEzIk/f1lZbAQM= github.com/pmezard/go-difflib v1.0.0/go.mod h1:iKH77koFhYxTK1pcRnkKkqfTogsbg7gZNVY4sRDYZ/4= github.com/stretchr/objx v0.1.0/go.mod h1:HFkY916IF+rwdDfMAkV7OtwuqBVzrE8GR6GFx+wExME= github.com/stretchr/testify v1.3.0/go.mod h1:M5WIy9Dh21IEIfnGCwXGc5bZfKNJtfHm1UVUgZn+9EI= github.com/stretchr/testify v1.7.0/go.mod h1:6Fq8oRcR53rry900zMqJjRRixrwX3KX962/h/Wwjteg= github.com/stretchr/testify v1.8.1 h1:w7B6lhMri9wdJUVmEZPGGhZzrYTPvgJArz7wNPgYKsk= github.com/stretchr/testify v1.8.1/go.mod h1:w2LPCIKwWwSfY2zedu0+kehJoqGctiVI29o6fzry7u4= golang.org/x/crypto v0.31.0 h1:ihbySMvVjLAeSH1IbfcRTkD/iNscyz8rGzjF/E5hV6U= golang.org/x/crypto v0.31.0/go.mod h1:kDsLvtWBEx7MV9tJOj9bnXsPbxwJQ6csT/x4KIN4Ssk= golang.org/x/sync v0.10.0 h1:3NQrjDixjgGwUOCaF8w2+VYHv0Ve/vGYSbdkTa98gmQ= golang.org/x/sync v0.10.0/go.mod h1:Czt+wKu1gCyEFDUtn0jG5QVvpJ6rzVqr5aXyt9drQfk= golang.org/x/text v0.21.0 h1:zyQAAkrwaneQ066sspRyJaG9VNi/YJ1NfzcGB3hZ/qo= golang.org/x/text v0.21.0/go.mod h1:4IBbMaMmOPCJ8SecivzSH54+73PCFmPWxNTLm+vZkEQ= gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0= gopkg.in/yaml.v3 v3.0.0-20200313102051-9f266ea9e77c/go.mod h1:K4uyk7z7BCEPqu6E+C64Yfv1cQ7kz7rIZviUmN+EgEM= gopkg.in/yaml.v3 v3.0.1 h1:fxVm/GzAzEWqLHuvctI91KS9hhNmmWOoWu0XTYJS7CA= gopkg.in/yaml.v3 v3.0.1/go.mod h1:K4uyk7z7BCEPqu6E+C64Yfv1cQ7kz7rIZviUmN+EgEM= |
Run the make utility:
make |
You can now run make to create the connect executable, which you can call with the following command:
~/.go/postgres/connect/bin/connect |
It will return to console:
PostgreSQL 14.17 (Ubuntu 14.17-0ubuntu0.22.04.1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0, 64-bit |
Ubuntu DaaS VM
Completed the build of my new Ubuntu Virtual Machine (VM) with Oracle 23c installed in a Docker instance, and MySQL and PostgreSQL installed locally. The VM image also provides a LAMP stack with Apache2, PHP 8.1 with MySQLi and PDO modules. Since the original post, I’ve added a number of items to support our program courses and the Data Science degrees.
There are lots of tricks and techniques in the blog associated with creating the build. I took the background photograph of Chapel Bridge early on Sunday morning August 30, 1987 in Lucerne Switzerland (with a Canon A1 and ASA 64 slide film that subsequently digitized well).
Next step: roll it out into an AWS image for the students to use for their courses.
Related blog posts:
- Installing and configuring Apache2 and PHP 8.1 on Ubuntu 22.04
- Installing and configuring Docker on Ubuntu 22.04
- Installing and configuring MySQL 8 on Ubuntu 22.04
- Installing Oracle Database 23c Free in a Docker container with space allocation techniques
- Installing and configuring PostgreSQL on Ubuntu 22.04
- Installing and configuring pgAdmin4
- Installing and configuring Python for MySQL 8
- Installing and configuring Python for PostgreSQL driver on Ubuntu 22.04
- Installing and configuring SQL Developer on Ubuntu 22.04
- Installing the rlwrap utility to access command history in SQL*Plus (sqlplus) inside Docker container.
- How to add PostGIS to an existing PostgreSQL 14 Install on Ubuntu 22.0.4
- How to create a sandboxed user and wrap sqlplus inside the Docker version of Oracle 23c Free
- How to install, configure, and create a persistent SQLite 3 database and access it with Python.
As always, I hope the post and information helps others.
Python3 on PostgreSQL
The necessary Python 3 driver for connections to the PostgreSQL database is python3-psycopg2, as qualified by this earlier post with full test examples for Red Hat distributions. You can install it on Ubuntu with the following command:
sudo apt-get install -y python3-psycopg2 |
Display detailed console log →
python3-psycopg2 Reading package lists... Done Building dependency tree... Done Reading state information... Done Suggested packages: python-psycopg2-doc The following NEW packages will be installed: python3-psycopg2 0 upgraded, 1 newly installed, 0 to remove and 4 not upgraded. Need to get 136 kB of archives. After this operation, 483 kB of additional disk space will be used. Get:1 http://us.archive.ubuntu.com/ubuntu jammy/main amd64 python3-psycopg2 amd64 2.9.2-1build2 [136 kB] Fetched 136 kB in 1s (146 kB/s) Selecting previously unselected package python3-psycopg2. (Reading database ... 204321 files and directories currently installed.) Preparing to unpack .../python3-psycopg2_2.9.2-1build2_amd64.deb ... Unpacking python3-psycopg2 (2.9.2-1build2) ... Setting up python3-psycopg2 (2.9.2-1build2) ... |
As always, I hope this helps those looking for a solution. Also, remember the referenced post above provides Linux distribution neutral full solutions.
PL/pgSQL Test Q?
Intriguing little PostgreSQL PL/pgSQL test question posed by an interviewer of one of my students. Basically, how many times will this loop and what will it return or will it generate an error. (BTW, they wrapped it into a named function.)
DO $$ BEGIN FOR i IN 0.2..1.5 LOOP RAISE NOTICE '%', i; END LOOP; END; $$; |
It’ll loop three times and return 0, 1, and 2 because the double numbers entered as boundaries to the for-loop are implicitly case as integers.
SQL Developer & PostgreSQL
I had a request from one of the adjunct professors to connect SQL Developer to the PostgreSQL database. This is in support of our database programming class that teaches students how to write PL/SQL against the Oracle database and pgPL/SQL against the PostgreSQL database. We also demonstrate transactional management through Node.js, Python and Java.
Naturally, this is also a frequent step taken by those required to migrate PostgreSQL data models to an Oracle database. While my final solution requires mimicking Oracle’s database user to schema, it does work for migration purposes. I’ll update this post when I determine how to populate the database drop-down list.
The first step was figuring out where to put the PostgreSQL JDBC Java ARchive (.jar) file on a Linux distribution. You navigate to the end-user student account in a Terminal and change to the .sqldeveloper directory. Then, create a jdbc subdirectory as the student user with the following command:
mkdir /home/student/.sqldeveloper/jdbc |
Then, download the most current PostgreSQL JDBC Java ARchive (.jar) file and copy it into the /home/student/.sqldeveloper/jdbc, which you can see afterward with the following command:
ll /home/student/.sqldeveloper/jdbc |
It should display:
-rw-r--r--. 1 student student 1041081 Aug 9 13:46 postgresql-42.3.7.jar |
The next series of steps are done within SQL Developer. Launch SQL Developer and navigate to Tools and Preferences, like this:
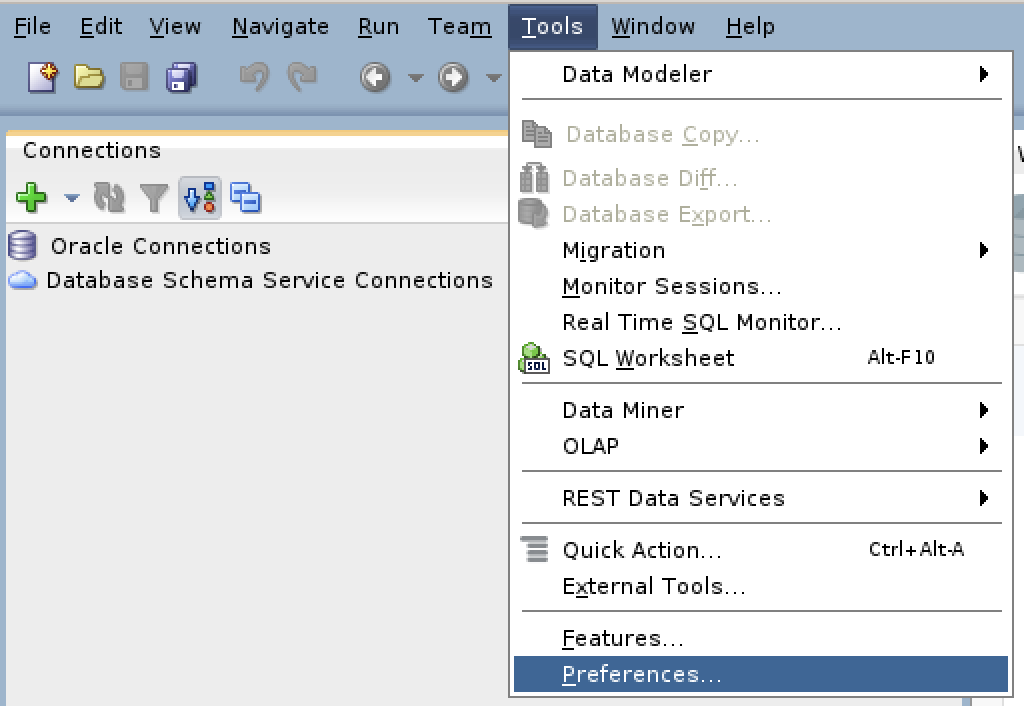
Inside the Preferences dialog, navigate to Database and Third Party JDBC Drivers like shown and click the Add Entry button to proceed:
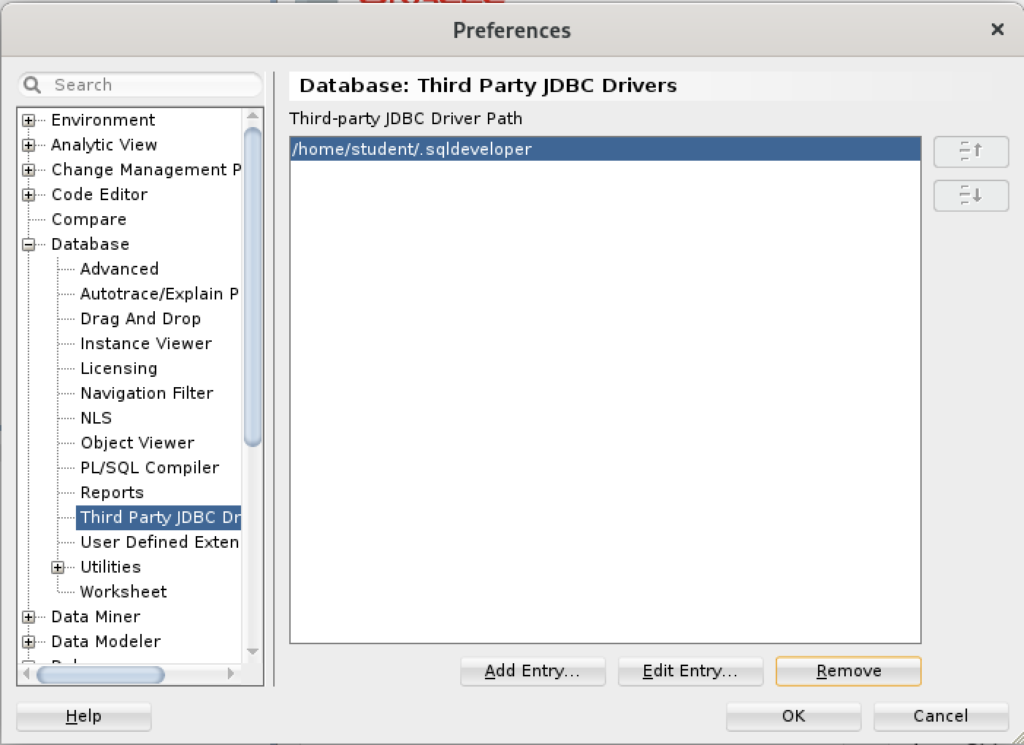
Inside the Select Path Entry dialog, select the current PostgreSQL JDBC Java ARchive (.jar) file, which is postgresql-42-3.7.jar in this example. Then, click the Select button.
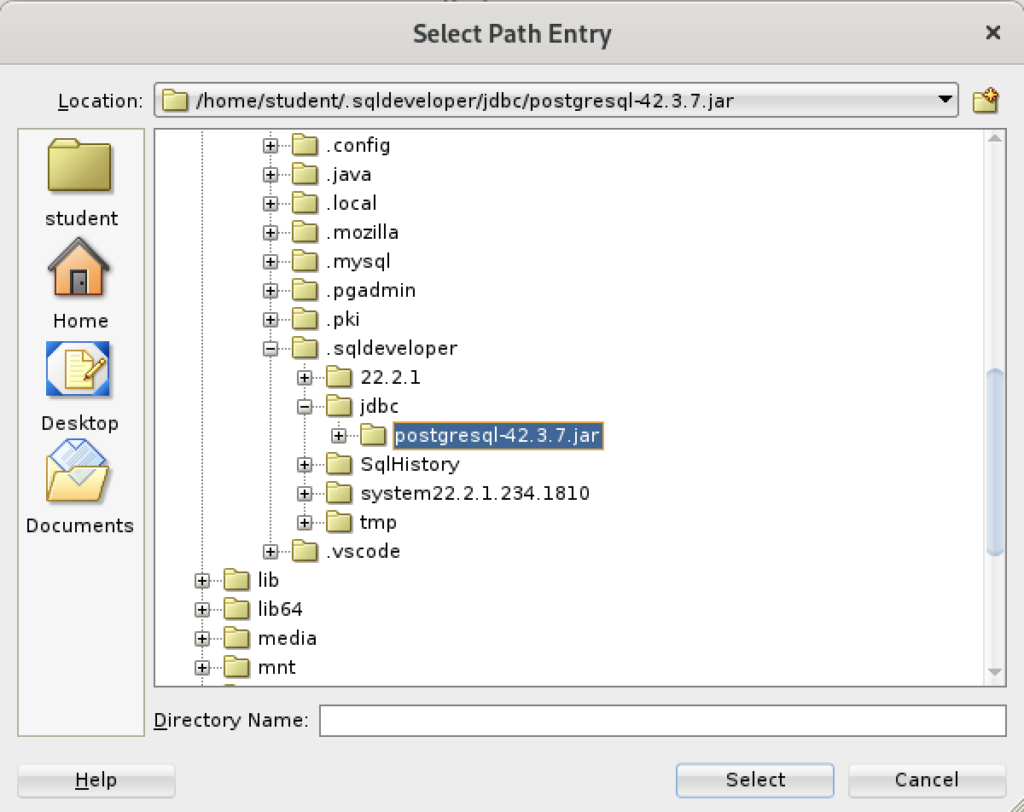
You are returned to the Preferences dialog as shown below. Click the OK button to continue.
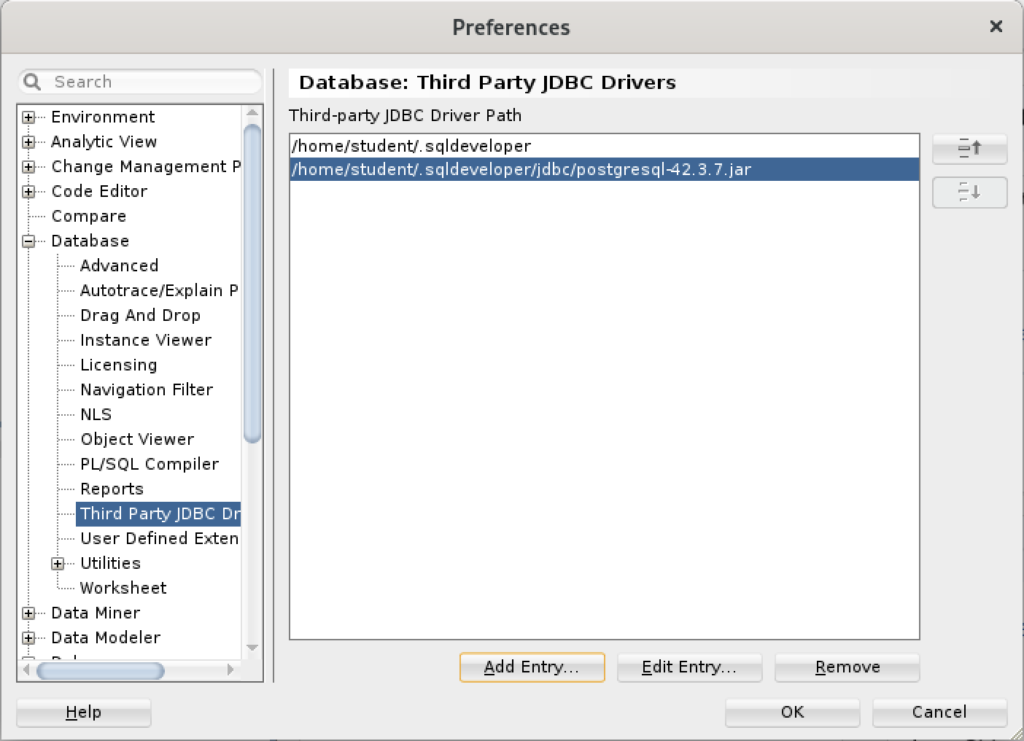
After completing the 3rd Party Java Driver setup, you attempt to create a new connection to the PostgreSQL database. You should see that you now have two available Database Type values: Oracle and PostgreSQL, as shown below:
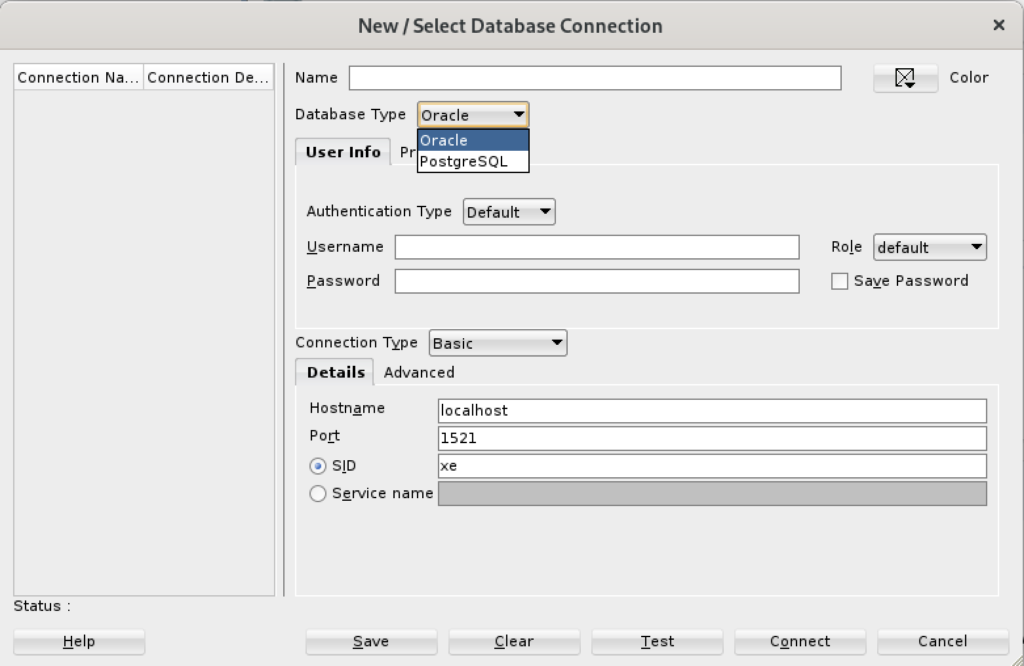
When you click on the PostgreSQL Database Type, the dialog updates to the following view. Unfortunately, I couldn’t discover how to set the values in the list for the Choose Database drop down. Naturally, a sandboxed user can’t connect to the PostgreSQL database without qualifying the database name.
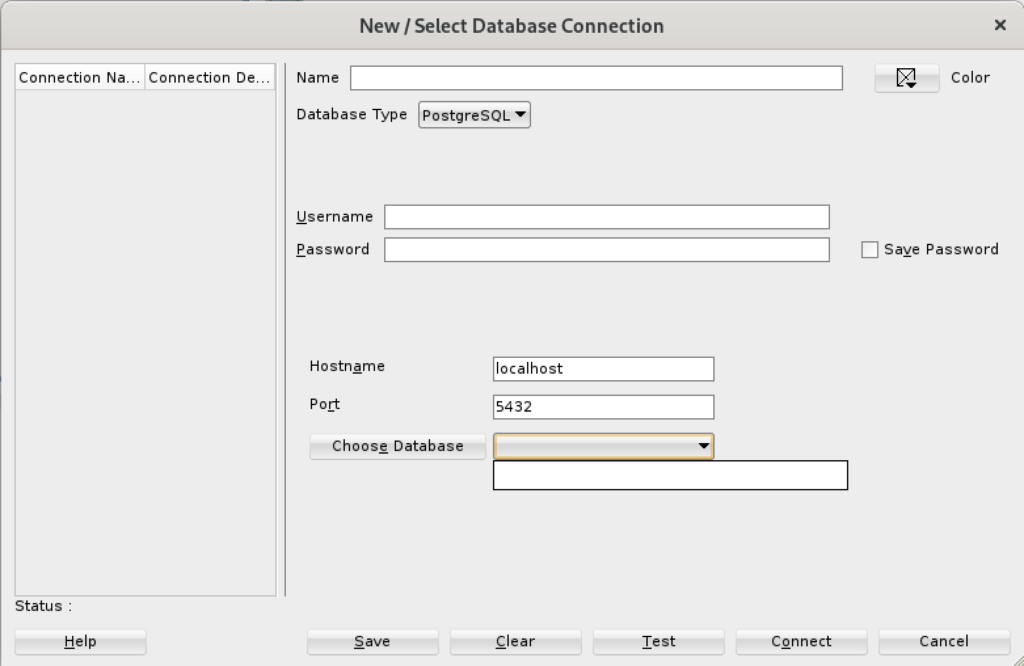
Unless you qualify the PostgreSQL database or connect as the postgres user with a privileged password, SQL Developer translates the absence of a database selection to a database name equivalent to the user’s name. That’s the default behavior for the Oracle database but differs from the behavior for MySQL, PostgreSQL, and Microsoft SQL Server. It returns the following
Status: Failure - Test failed: FATAL: database "student" does not exist |
As seen in the diaglog’s result when testing the connection:
Based on my hunch and not knowing how to populate the database field for the connection, I did the following:
- Created a Linux OS videodb user.
- Copied the .bashrc file with all the standard Oracle environment variables.
- Created the /home/videodb/.sqldeveloper/jdbc directory.
- Copied the postgresql-42.3.7.jar into the new jdbc directory.
- Connected as the postgres super user and created the PostgreSQL videodb user with this syntax:
CREATE USER videodb WITH ROLE dba ENCRYPTED PASSWORD 'cangetin';
- As the postgres super user, granted the following privileges:
-- Grant privileges on videodb database videodb user. GRANT ALL ON DATABASE "videodb" TO "videodb"; -- Connect to the videodb database. \c -- Grant privileges. GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO videodb; GRANT ALL PRIVILEGES ON ALL SEQUENCES IN SCHEMA public TO videodb;
- Added the following line to the pg_hba.conf file in the /var/lib/pgsql/15/data directory as the postgres user:
local all videodb peer - Connected as the switched from the student to videodb Linux user, and launched SQL Developer. Then, I used the Tools menu to create the 3rd party PostgreSQL JDBC Java ARchive (.jar) file in context of the SQL Developer program. Everything completed correctly.
- Created a new PostgreSQL connection in SQL Developer and tested it with success as shown:
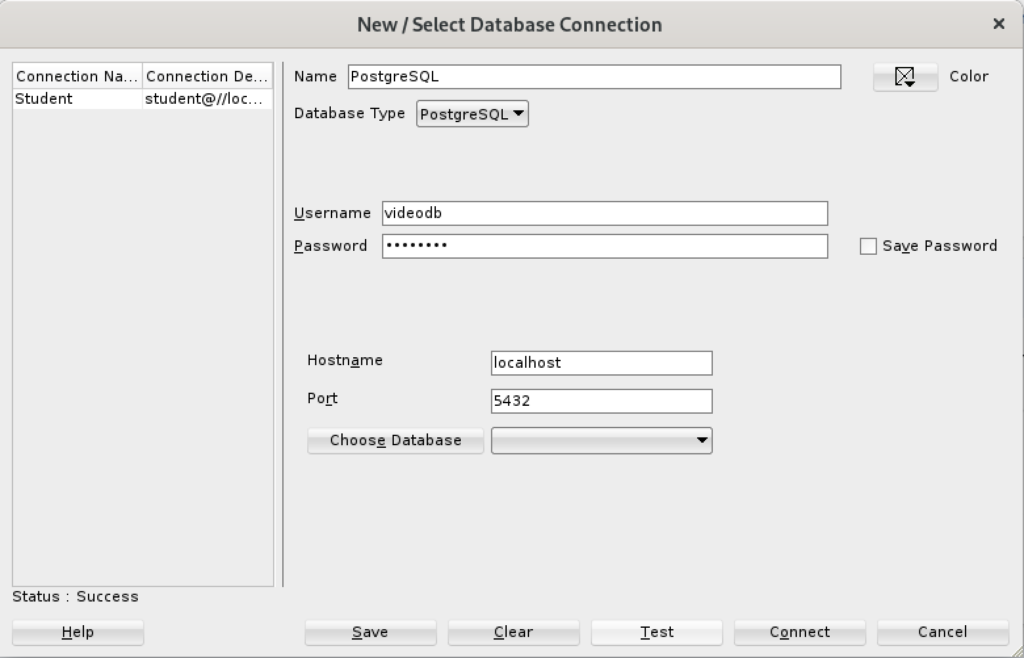
- Saving the new PostgreSQL connection, I opened the connection and could run SQL statements and display the catalog information, as shown:
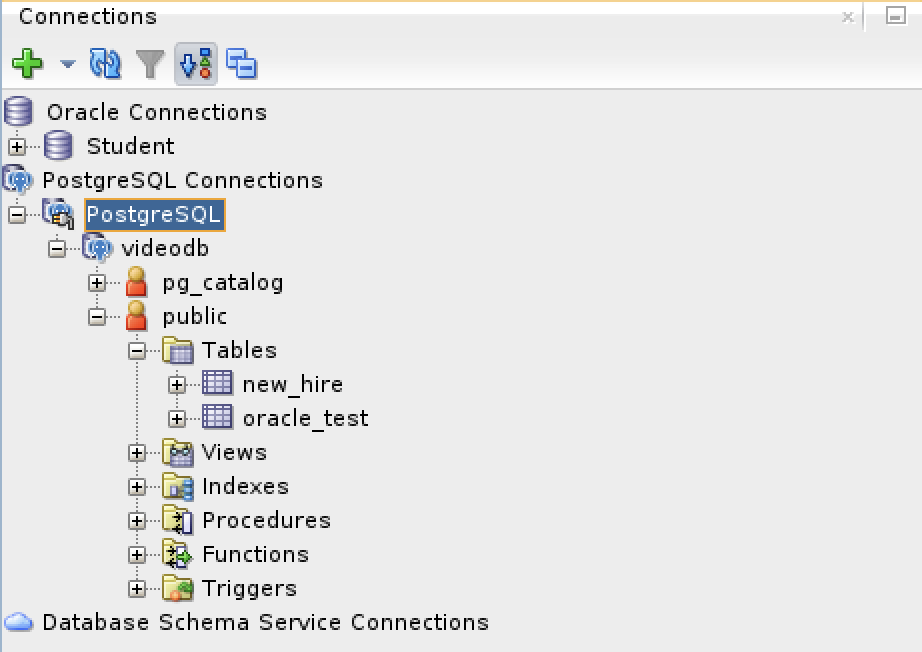
Connected as the videodb user to the videodb database I can display tables owned by student and videodb users:
-- List tables. \d List of relations Schema | Name | Type | Owner --------+--------------------------+----------+--------- public | new_hire | table | student public | new_hire_new_hire_id_seq | sequence | student public | oracle_test | table | videodb (3 rows)
In SQL Developer, you can also inspect the tables, as shown:

At this point, I’m working on trying to figure out how to populate the database drop-down table. However, I’ve either missed a key document or it’s unfortunate that SQL Developer isn’t as friendly as MySQL Workbench in working with 3rd Party drivers.
PostgreSQL Java
The majority of information to write this post comes form knowing how Java works and where to find the PostgreSQL JDBC Java archive (.jar) file and the standard documentation. Here are the URLs:
The rest of the example is simply demonstrating how to create a fully working program to return one or more rows from a static query. After you download the latest PostgreSQL JDBC archive, with a command like:
wget https://jdbc.postgresql.org/download/postgresql-42.3.7.jar |
Assuming you put it in test directory, like /home/student/java, you would add it to your Java $CLASSPATH environment variable, like this:
export set CLASSPATH="/home/student/Code/java/postgresql-42.3.7.jar:." |
If you’re new to Java and Linux, the . (dot) represents the present working directory and is required in the Java $CLASSPATH to avoid raising a java.lang.ClassNotFoundException when you test your code. For example, the sample program name is PostgreSQLDriver.java and if you failed to include the present working directory in the $CLASSPATH it would raise the following error message when you try to run the compiled class file:
Error: Could not find or load main class PSQL Caused by: java.lang.ClassNotFoundException: PSQL |
Now that you’ve set your Java $CLASSPATH correctly, you can copy or type this PostgreSQLDriver.java Java program into a file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 | // Import classes. import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import java.util.Properties; /* You can't include the following on Linux without raising an exception. */ // import com.mysql.jdbc.Driver; public class PostgreSQLDriver { public PostgreSQLDriver() { /* Declare variables that require explicit assignments because they're addressed in the finally block. */ Connection conn = null; Statement stmt = null; ResultSet rset = null; /* Declare other variables. */ String url; String username = "student"; String password = "student"; String database = "videodb"; String hostname = "[::1]"; String port = "5432"; String sql; /* Attempt a connection. */ try { // Set URL. url = "jdbc:postgresql://" + hostname + ":" + port + "/" + database; // Create instance of MySQLDriver. conn = DriverManager.getConnection (url, username, password); // Query the version of the database. sql = "SELECT version()"; stmt = conn.createStatement(); rset = stmt.executeQuery(sql); System.out.println ("Database connection established"); // Read row returns for one column. while (rset.next()) { System.out.println("PostgreSQL Connected to the [" + rset.getString(1) + "] database."); } } catch (SQLException e) { System.err.println ("Cannot connect to database server:"); System.out.println(e.getMessage()); } finally { if (conn != null) { try { rset.close(); stmt.close(); conn.close(); System.out.println ("Database connection terminated"); } catch (Exception e) { /* ignore close errors */ } } } } /* Unit test. */ public static void main(String args[]) { new PostgreSQLDriver(); } } |
Now, you compile the program from the present working directory with this syntax:
javac PostgreSQLDriver.java |
It creates a PostgreSQLDriver.class file, which you can run with this syntax:
java PostgreSQLDriver |
It will return the following, which verifies you’ve connected to a valid database in the PostgreSQL instance. You should note that the IPV6 syntax is used in the example on line #25 but you could substitute localhost, an assigned host name, or an IP address.
TDE on PostgreSQL

The scope of Transparent Data Encryption (TDE) in PostgreSQL only applies to columns. It does not encrypt other aspects of the database, like table-level and database-level encryption; and those who deploy PostgreSQL may need to implement additional security measures to protect these database components.
You need to know two key elements before exploring TDE in PostgreSQL: Scheme inside a database and extensions. Unlike many databases, PostgreSQL schemas are not synonymous with a database. You may have multiple scheme (or, alternatively schemas) inside any PostgreSQL database.
Creating an extension is a one time event. Therefore, it’s easier to show you that first. You create a pgcrypto extension with the following command:
CREATE EXTENSION pgcrypto; |
The public schema is the one most users deploy but for the purpose of hiding our AES encryption key this example creates a hidden schema. Unless you change the default find setting the hidden schema is not visible when connecting to the database.
You create the hidden schema with the following idimpotent (re-runnable) set of commands:
/* Drop dependent objects before dropping the schema. */ DROP TABLE IF EXISTS hidden.aes_key; DROP FUNCTION IF EXISTS hidden.get_aes_key; /* * Drop function with cascade to remove the * film_character_t trigger at same time. */ DROP FUNCTION IF EXISTS hidden.film_character_dml_f CASCADE; /* Drop the schema conditionally. */ DROP SCHEMA IF EXISTS hidden; /* Create the schema. */ CREATE SCHEMA hidden; |
Next, we need to create a aes_key table and get_aes_key function in the hidden schema. The table will store the AES encryption key and the function lets us create an AES encryption key.
/* Create an aes encryption key table. */ CREATE TABLE hidden.aes_key ( aes_key text ); /* Create a hidden function to build an AES encryption key. */ CREATE OR REPLACE FUNCTION hidden.get_aes_key() RETURNS text AS $$ BEGIN RETURN gen_random_bytes(16)::text; END; $$ LANGUAGE plpgsql; |
After creating the public get_key() function, you insert a single row to the aes_key table by prefacing it with the hidden schema name, like this:
/* Insert the AES encryption key into a table. */ INSERT INTO hidden.aes_key ( aes_key ) VALUES ( hidden.get_aes_key()); |
Having built the plumbing for our AES encryption key, let’s show you how to encrypt and decrypt string values. This example lets you create an idimpotent film_character table in the public schema, like:
/* Drop the table conditionally. */ DROP TABLE IF EXISTS film_character; /* Create the demonstration table for encrypting and decrypting strings. */ CREATE TABLE film_character ( character_id serial PRIMARY KEY , plain_text text , encrypted_text bytea ); |
After creating the AES encryption key table, function, and inserting a row of data, you need to create a public get_key() function, like:
/* Create a public function to retrieve the AES encryption key. */ CREATE OR REPLACE FUNCTION get_key() RETURNS text AS $$ DECLARE retval text; BEGIN SELECT aes_key INTO retval FROM hidden.aes_key; RETURN retval; END; $$ LANGUAGE plpgsql; |
The following INSERT statement write a plain text column and encrypted text column into the film_character table. The get_key() function hides how the pgp_sym_encrypt function encrypts the string.
/* Insert plain and encrypted text into a table. */ INSERT INTO film_character ( plain_text , encrypted_text ) VALUES ('Severus Snape' , pgp_sym_encrypt('Slytherin',get_key())); |
The following query displays the plain and encrypted text stored in a row of the film_character table.
/* Query plain and encrypted text from a table. */ SELECT character_id , plain_text , encrypted_text FROM film_character; |
It displays:
character_id | plain_text | encrypted_text
--------------+---------------+--------------------------------------------------------------------------------------------------------------------------------------------------------
1 | Severus Snape | \xc30d04070302fa1c4eebd90204cc7bd23901f1d4fa91b2455c3ef2987a305aebe01a4d94f9ebb467d6cb7a3846342ccd09cb55ac5e82a71cbaef93728fbeb4aaa9bf71b6fb93457758d1
(1 row) |
Last, the following query displays the plain and decrypted text with the pgp_sym_decrypt function in a query:
/* Query the plain and decrypted text from a table. */ SELECT character_id , plain_text , pgp_sym_decrypt(encrypted_text,get_key()) AS encrypted_text FROM film_character; |
The query returns the plain and decrypted values:
character_id | plain_text | encrypted_text
--------------+---------------+-----------------
1 | Severus Snape | Slytherin
(1 row) |
However, this approach exposes the method for encrypting the encrypted_text column’s string value. You can hide this by creating a film_character_dml_f function in the hidden schema and a film_character_t trigger in the public schema, like:
/* Create trigger function for insert or update. */ CREATE FUNCTION hidden.film_character_dml_f() RETURNS trigger AS $$ DECLARE /* Declare local variable. */ unencrypted_input VARCHAR(30); BEGIN unencrypted_input := new.encrypted_text::text; /* Encrypt the column. */ new.encrypted_text := pgp_sym_encrypt(unencrypted_input,get_key()); /* Return new record type. */ RETURN NEW; END; $$ LANGUAGE plpgsql; CREATE TRIGGER film_character_t BEFORE INSERT OR UPDATE ON film_character FOR EACH ROW EXECUTE FUNCTION hidden.film_character_dml_f(); |
Now, you can insert the plain text data in an INSERT statement and the encryption occurs without disclosing how it happens. Here’s a sample statement:
INSERT INTO film_character ( plain_text , encrypted_text ) VALUES ('Harry Potter' ,'Gryffindor'); |
A query of the table shows you that both rows have an encrypted value in the encrypted_text column.
/* Query plain and encrypted text from a table. */ SELECT character_id , plain_text , encrypted_text FROM film_character; |
Displayed like:
character_id | plain_text | encrypted_text
--------------+---------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | Severus Snape | \xc30d040703026716034f140d83e76cd23a01f99168afebe50d760b85c69373e3947c74473115a939843887db8e102cd0b2524378f4d684e0ba91c20afc436a056cd983fc47794eef7d4904
2 | Harry Potter | \xc30d040703020d8cc71d1f84e1ef6fd24701fd308f669e28a6135beac130fc51a6ccb5cef3c5005f4f557207fe5c84c4aedbb5b098dc9a882a9b7d801c61e34cd90517b4628b5a18b96b3fc61663b48391146b8c0fa2a858
(2 rows) |
As always, I hope this code complete solution helps those trying to work with this technical stack.
AlmaLinux Install & Configuration

This is a collection of blog posts for installing and configuring AlmaLinux with the Oracle, PostgreSQL, MySQL databases and several programming languages. Sample programs show how to connect PHP and Python to the MySQL database.
- Installing AlmaLinux operating system
- Installing and configuring MySQL
- Installing Python-MySQL connector and provide sample programs
- Configuring Flask for Python on AlmaLinux with a complete software router instruction set.
- Installing Rust programming language and writing a sample program
- Installing and configuring LAMP stack with PHP and MySQL and a self-signed security key
- MySQL PNG Images in LAMP with PHP Programming
- Demonstration of how to write Perl that connects to MySQL
- Installing and configuring MySQL Workbench
- Installing and configuring PostgreSQL and pgAdmin4
- Identifying the required libnsl2-devel packages for SQL*Plus
- Writing and deploying a sqlplus function to use a read line wrapper
- Installing and configuring Visual Studio Code Editor
- Installing and configuring Java with connectivity to MySQL
- Installing and configuring Oracle SQL Developer
I used Oracle Database 11g XE in this instance to keep the footprint as small as possible. It required a few tricks and discovering the missing library that caused folks grief eleven years ago. I build another with a current Oracle Database XE after the new year.
If you see something that I missed or you’d like me to add, let me know. As time allows, I’ll try to do that. Naturally, the post will get updates as things are added later.
AlmaLinux+PostgreSQL
This installs PostgreSQL 15 on AlmaLinux 9 (don’t forget the PostgreSQL 15 Documentation site). The executable is available in the script that the postgresql.org provides; however, it seems appropriate to show how to find that script for any platform.
When you launch the postgres.org web site, you will see the following dialog. Click the Download-> button to choose an operating system.
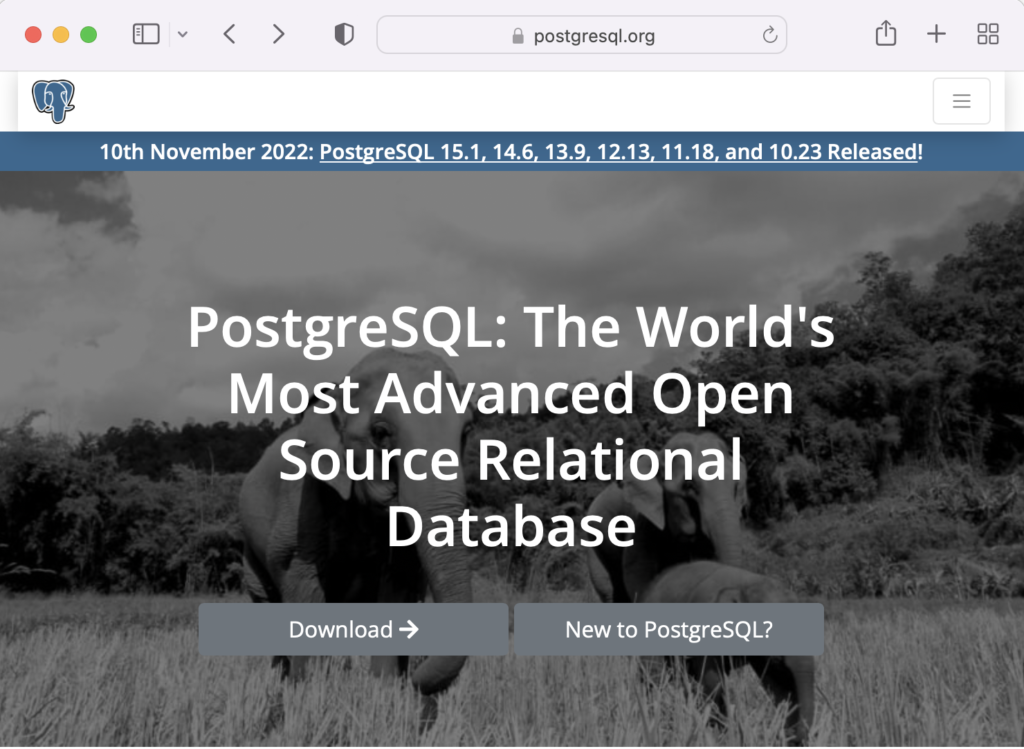
On the next webpage, click on the Linux icon button to proceed.
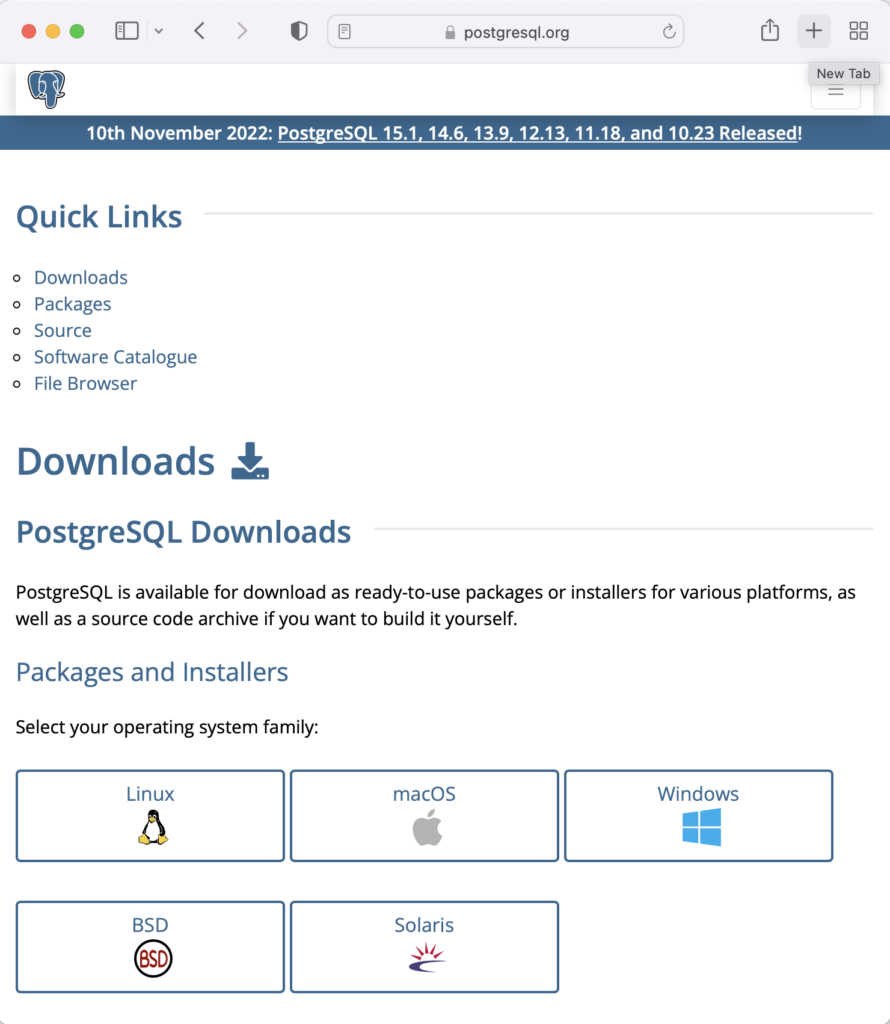
This page expands for you to choose a Linux distribution. Click on the Red Hat/Rocky/CentOS button to proceed.
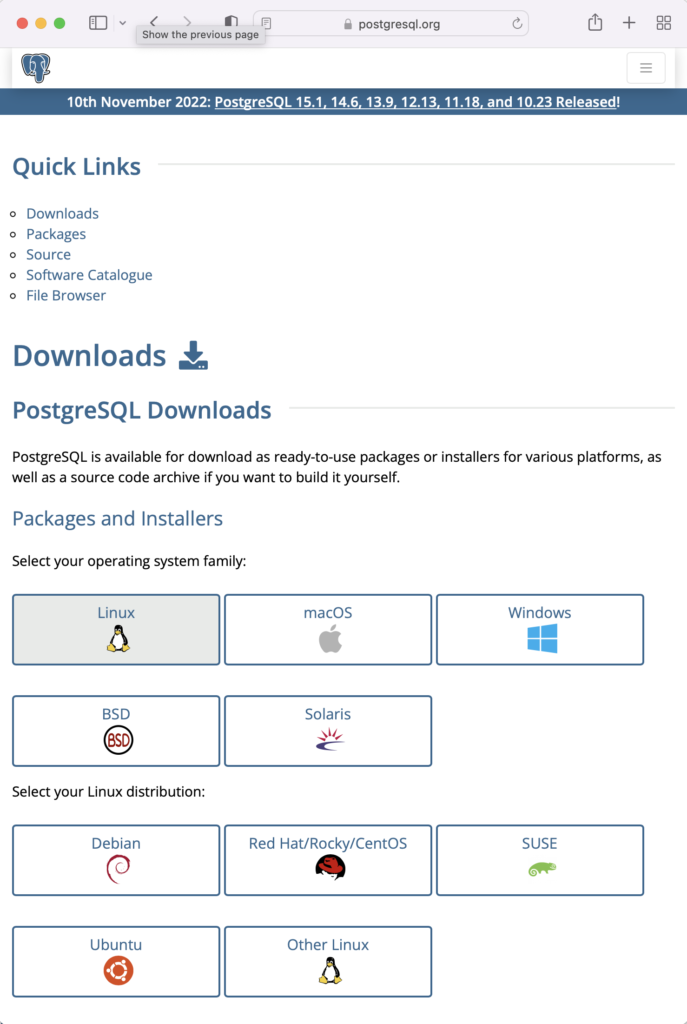
This web page lets you choose a platform, which should be Red Hat Enterprise, Rocky, or Oracle version 9.
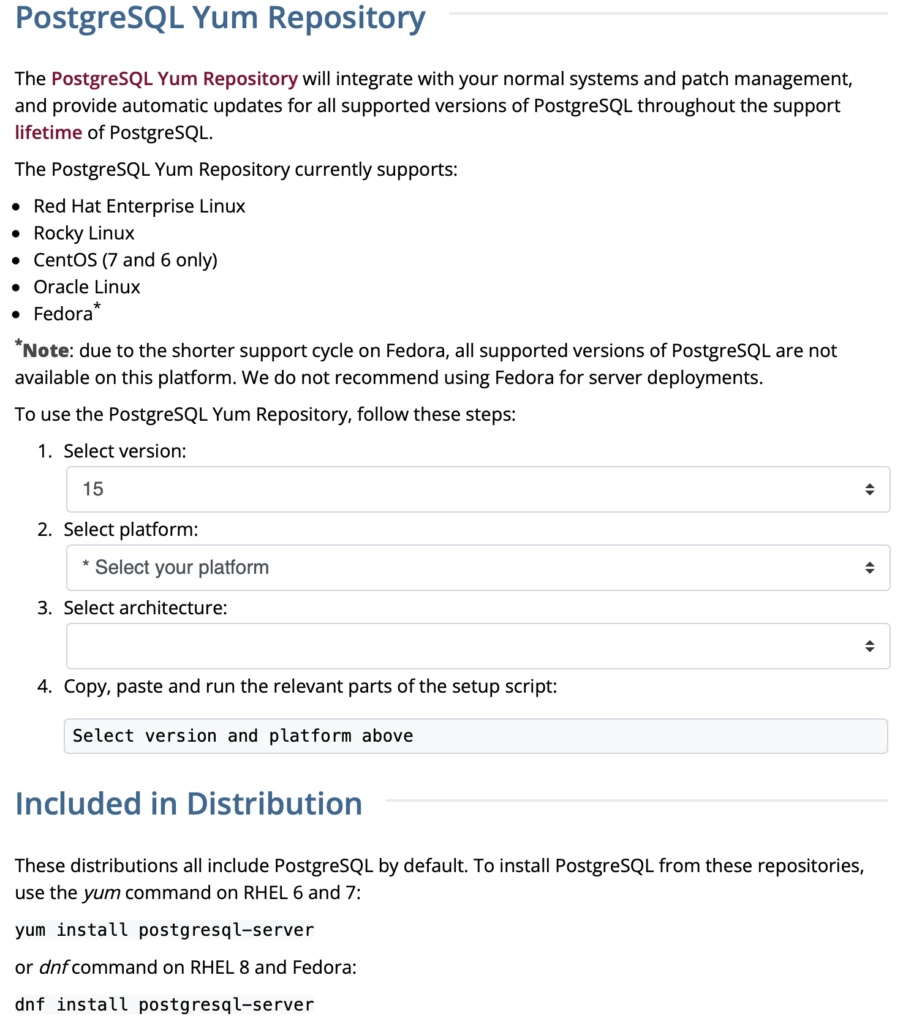
The selection fills out the web page and provides a setup script. The script installs the PostgreSQL packages, disables the built-in PostgreSQL module, installs PostgreSQL 15 Server, initialize, enable, and start PostgreSQL Server.
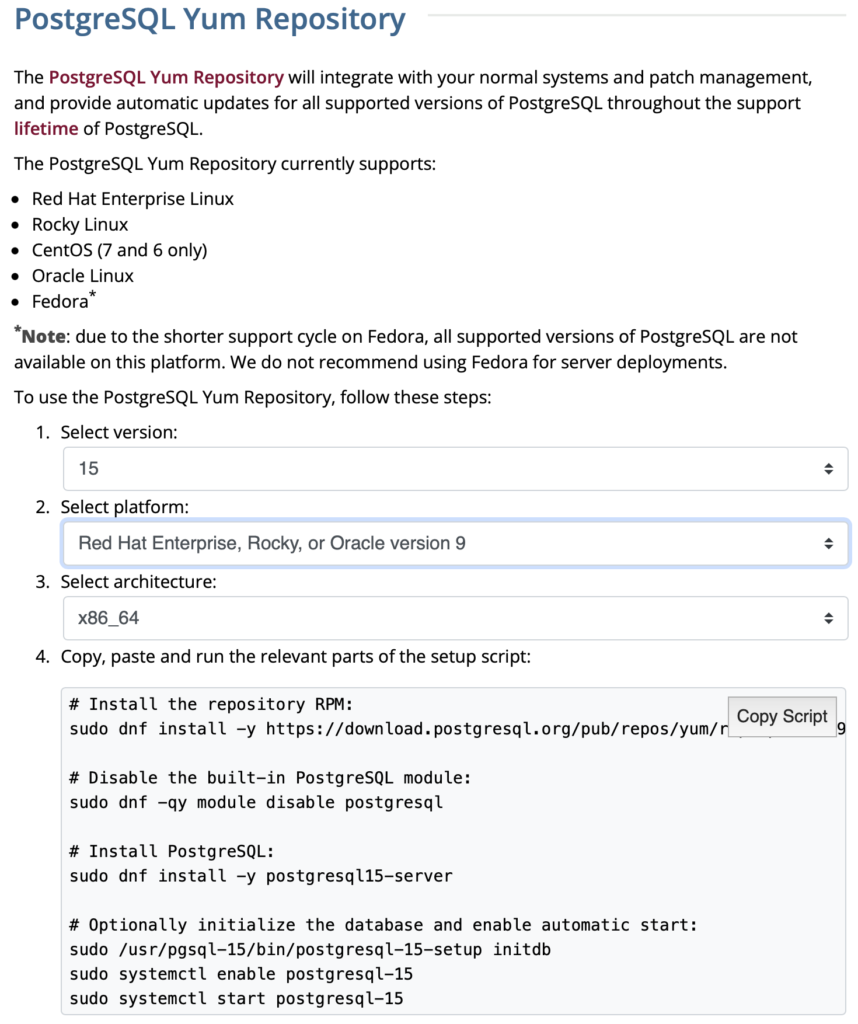
Here are the detailed steps:
- Install the PostgreSQL by updating dependent packages before installing it with the script provided by the PostgreSQL download web site:
# Install the repository RPM: sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm # Disable the built-in PostgreSQL module: sudo dnf -qy module disable postgresql # Install PostgreSQL: sudo dnf install -y postgresql15-server # Optionally initialize the database and enable automatic start: sudo /usr/pgsql-15/bin/postgresql-15-setup initdb sudo systemctl enable postgresql-15 sudo systemctl start postgresql-15
Display detailed console log →
Last metadata expiration check: 20:38:10 ago on Mon 21 Nov 2022 02:07:25 AM EST. pgdg-redhat-repo-latest.noarch.rpm 3.6 kB/s | 12 kB 00:03 Dependencies resolved. ================================================================================ Package Architecture Version Repository Size ================================================================================ Installing: pgdg-redhat-repo noarch 42.0-28 @commandline 12 k Transaction Summary ================================================================================ Install 1 Package Total size: 12 k Installed size: 14 k Downloading Packages: Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : pgdg-redhat-repo-42.0-28.noarch 1/1 Verifying : pgdg-redhat-repo-42.0-28.noarch 1/1 Installed: pgdg-redhat-repo-42.0-28.noarch Complete! Last metadata expiration check: 20:38:10 ago on Mon 21 Nov 2022 02:07:25 AM EST. pgdg-redhat-repo-latest.noarch.rpm 3.6 kB/s | 12 kB 00:03 Dependencies resolved. ================================================================================ Package Architecture Version Repository Size ================================================================================ Installing: pgdg-redhat-repo noarch 42.0-28 @commandline 12 k Transaction Summary ================================================================================ Install 1 Package Total size: 12 k Installed size: 14 k Downloading Packages: Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : pgdg-redhat-repo-42.0-28.noarch 1/1 Verifying : pgdg-redhat-repo-42.0-28.noarch 1/1 Installed: pgdg-redhat-repo-42.0-28.noarch Complete! Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Unable to resolve argument postgresql Error: Problems in request: missing groups or modules: postgresql Last metadata expiration check: 0:00:02 ago on Mon 21 Nov 2022 10:46:16 PM EST. Dependencies resolved. ================================================================================ Package Arch Version Repository Size ================================================================================ Installing: postgresql15-server x86_64 15.1-1PGDG.rhel9 pgdg15 6.0 M Installing dependencies: lz4 x86_64 1.9.3-5.el9 baseos 58 k postgresql15 x86_64 15.1-1PGDG.rhel9 pgdg15 1.5 M postgresql15-libs x86_64 15.1-1PGDG.rhel9 pgdg15 296 k Transaction Summary ================================================================================ Install 4 Packages Total download size: 7.8 M Installed size: 33 M Downloading Packages: (1/4): lz4-1.9.3-5.el9.x86_64.rpm 91 kB/s | 58 kB 00:00 (2/4): postgresql15-libs-15.1-1PGDG.rhel9.x86_6 97 kB/s | 296 kB 00:03 (3/4): postgresql15-15.1-1PGDG.rhel9.x86_64.rpm 214 kB/s | 1.5 MB 00:07 (4/4): postgresql15-server-15.1-1PGDG.rhel9.x86 371 kB/s | 6.0 MB 00:16 -------------------------------------------------------------------------------- Total 446 kB/s | 7.8 MB 00:17 PostgreSQL 15 for RHEL / Rocky 9 - x86_64 1.4 MB/s | 1.7 kB 00:00 Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsql-pkg-yum@postgresql.org>" Fingerprint: 68C9 E2B9 1A37 D136 FE74 D176 1F16 D2E1 442D F0F8 From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Key imported successfully Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : postgresql15-libs-15.1-1PGDG.rhel9.x86_64 1/4 Running scriptlet: postgresql15-libs-15.1-1PGDG.rhel9.x86_64 1/4 Installing : lz4-1.9.3-5.el9.x86_64 2/4 Installing : postgresql15-15.1-1PGDG.rhel9.x86_64 3/4 Running scriptlet: postgresql15-15.1-1PGDG.rhel9.x86_64 3/4 Running scriptlet: postgresql15-server-15.1-1PGDG.rhel9.x86_64 4/4 Installing : postgresql15-server-15.1-1PGDG.rhel9.x86_64 4/4 Running scriptlet: postgresql15-server-15.1-1PGDG.rhel9.x86_64 4/4 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Verifying : lz4-1.9.3-5.el9.x86_64 1/4 Verifying : postgresql15-15.1-1PGDG.rhel9.x86_64 2/4 Verifying : postgresql15-libs-15.1-1PGDG.rhel9.x86_64 3/4 Verifying : postgresql15-server-15.1-1PGDG.rhel9.x86_64 4/4 Installed: lz4-1.9.3-5.el9.x86_64 postgresql15-15.1-1PGDG.rhel9.x86_64 postgresql15-libs-15.1-1PGDG.rhel9.x86_64 postgresql15-server-15.1-1PGDG.rhel9.x86_64 Complete! Initializing database ... /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 /sbin/restorecon: Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 OK Created symlink /etc/systemd/system/multi-user.target.wants/postgresql-15.service → /usr/lib/systemd/system/postgresql-15.service.
- The simpmlest way to verify the installation is to check for the psql executable. You can do that with this command:
which psqlIt should return:
/usr/bin/psql
- Attempt to login with the following command-line interface (CLI) syntax:
psql -U postgres -W
It should fail and return the following:
psql: error: connection to server on socket "/var/run/postgresql/.s.PGSQL.5432" failed: FATAL: Peer authentication failed for user "postgres"
This error occurs because you’re not the postgres user, and all other users must designate that they’re connecting to an account with a password. The following steps let you configure the Operating System (OS).
-
You must shell out to the root superuser’s account, and then shell out to the postgres user’s account to test your connection because postgres user’s account disallows direct connection.
su - root su - postgres
You can verify the current postgres user with this command:
whoamiIt should return the following:
postgres
As the postgres user, you connect to the database without a password. You use the following syntax:
psql -U postgresIt should display the following:
psql (15.1) Type "help" for help.
-
At this point, you have some operating system (OS) stuff to setup before configuring a PostgreSQL sandboxed videodb database and student user. Exit psql with the following command:
postgres=# \q
Navigate to the PostgreSQL home database directory as the postgres user with this command:
cd /var/lib/pgsql/15/data
Edit the pg_hba.conf file to add lines for the postgres and student users:
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all peer local all postgres peer local all student peer # IPv4 local connections: host all all 127.0.0.1/32 scram-sha-256 # IPv6 local connections: host all all ::1/128 scram-sha-256 # Allow replication connections from localhost, by a user with the # replication privilege. local replication all scram-sha-256 host replication all 127.0.0.1/32 scram-sha-256 host replication all ::1/128 scram-sha-256
Navigate up the directory tree from the /var/lib/pgsql/15/data directory, which is also the data dictionary, to the following /var/lib/pgsql/15 base directory:
cd /var/lib/pgsql/15
Create a new video_db directory. This is where you will deploy the video_db tablespace. You create this directory with the following command:
mkdir video_dbChange the video_db permissions to read, write, and execute for only the owner with this syntax as the postgres user:
chmod 700 video_db
-
Exit the postgres user with the exit command and open PostgreSQL’s 5432 listener port as the root user. You can use the following command, as the root user:
firewall-cmd --zone=public --add-port 5432/tcp --permanent
-
You must shell out from the root user to the postgres user with the following command:
su - postgres
-
You must shell out to the root superuser’s account, and then shell out to the postgres user’s account to test your connection because postgres user’s account disallows direct connection.
- Connect to the postgres account and perform the following commands:
- After connecting as the postgres superuser, you can create a video_db tablespace with the following syntax:
CREATE TABLESPACE video_db OWNER postgres LOCATION 'C:\Users\username\video_db';
This will return the following:
CREATE TABLESPACE
You can query whether you successfully create the video_db tablespace with the following:
SELECT * FROM pg_tablespace;
It should return the following:
oid | spcname | spcowner | spcacl | spcoptions -------+------------+----------+--------+------------ 1663 | pg_default | 10 | | 1664 | pg_global | 10 | | 16389 | video_db | 10 | | (3 rows)
-
You need to know the PostgreSQL default collation before you create a new database. You can write the following query to determine the default correlation:
postgres=# SELECT datname, datcollate FROM pg_database WHERE datname = 'postgres';
It should return something like this:
datname | datcollate ----------+------------- postgres | en_US.UTF-8 (1 row)
The datcollate value of the postgres database needs to the same value for the LC_COLLATE and LC_CTYPE parameters when you create a database. You can create a videodb database with the following syntax provided you’ve made appropriate substitutions for the LC_COLLATE and LC_CTYPE values below:
CREATE DATABASE videodb WITH OWNER = postgres ENCODING = 'UTF8' TABLESPACE = video_db LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8' CONNECTION LIMIT = -1;
You can verify the creation of the videodb with the following command:
postgres# \l
It should show you a display like the following:
List of databases Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges -----------+----------+----------+-------------+-------------+------------+-----------------+----------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres videodb | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | (4 rows)Then, you can assign comment to the database with the following syntax:
COMMENT ON DATABASE videodb IS 'Video Store Database';
- After connecting as the postgres superuser, you can create a video_db tablespace with the following syntax:
- Create a Role, Grant, and User:
In this section you create a dba role, grant privileges on a videodb database to a role, and create a user with the role that you created previously with the following three statements. There are three steps in this sections.
- The first step creates a dba role:
CREATE ROLE dba WITH SUPERUSER;
- The second step grants all privileges on the videodb database to both the postgres superuser and the dba role:
GRANT TEMPORARY, CONNECT ON DATABASE videodb TO PUBLIC; GRANT ALL PRIVILEGES ON DATABASE videodb TO postgres; GRANT ALL PRIVILEGES ON DATABASE videodb TO dba;
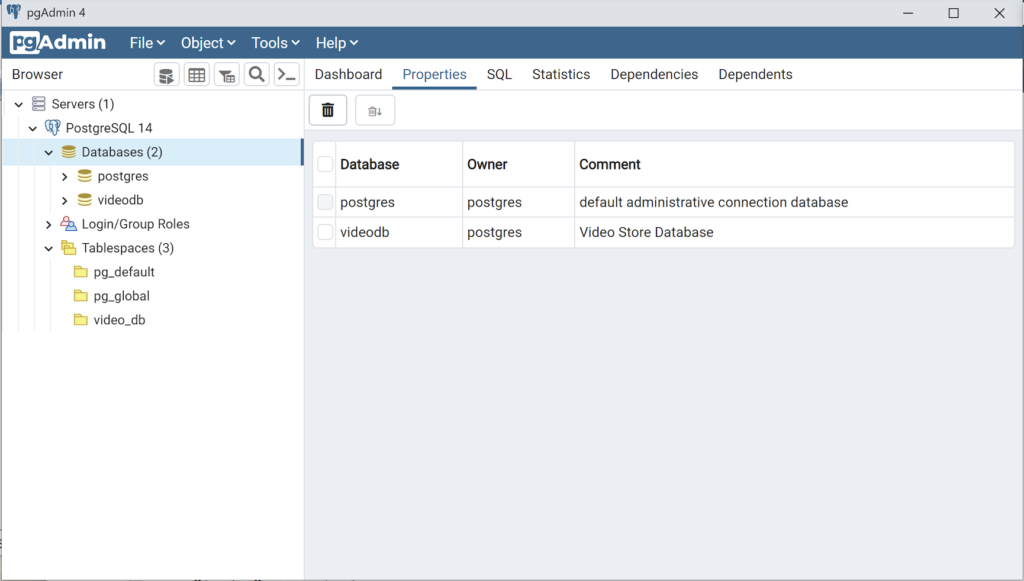
Any work in pgAdmin4 requires a grant on the videodb database to the postgres superuser. The grant enables visibility of the videodb database in the pgAdmin4 console as shown in the following image.
- The third step changes the ownership of the videodb database to the student user:
ALTER DATABASE videodb OWNER TO student;
You can verify the change of ownership for the videodb from the postgres user to student user with the following command:
postgres# \l
It should show you a display like the following:
List of databases Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges -----------+----------+----------+-------------+-------------+------------+-----------------+----------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres videodb | student | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =Tc/student + | | | | | | | student=CTc/student + | | | | | | | dba=CTc/student (4 rows) - The fourth step creates a student user with the dba role:
CREATE USER student WITH ROLE dba ENCRYPTED PASSWORD 'student';
After this step, you need to disconnect as the postgres superuser with the following command:
\q
- The first step creates a dba role:
- Connect to the videodb database as the student user with the PostgreSQL CLI, create a new_hire table and quit the database.
The following syntax lets you connect to a videodb database as the student user. You should note that the Linux OS student user name should match the database user name.
psql -Ustudent -W -dvideodb
You create the new_hire table in the public schema of the videodb database with the following syntax:
CREATE TABLE new_hire ( new_hire_id SERIAL CONSTRAINT new_hire_pk PRIMARY KEY , first_name VARCHAR(20) NOT NULL , middle_name VARCHAR(20) , last_name VARCHAR(20) NOT NULL , hire_date DATE NOT NULL , UNIQUE(first_name, middle_name, hire_date));
You can describe the new_hire table with the following command:
\d new_hire
You quit the psql connection with a quit; or \q, like so
quit;
- Installing, configuring, and launching pgadmin4 (don’t forget the pgAdmin 4 Documentation site):
- You need to install three sets of packages. They’re the pgadmin-server, policycoreutils-python-utils, and pgadmin4-desktop.
- Apply the pgadmin-server package:
sudo yum install https://ftp.postgresql.org/pub/pgadmin/pgadmin4/yum/redhat/rhel-9Server-x86_64/pgadmin4-server-6.16-1.el9.x86_64.rpm
Display detailed console log →
Last metadata expiration check: 0:36:13 ago on Mon 28 Nov 2022 12:59:07 AM EST. pgadmin4-server-6.16-1.el9.x86_64.rpm 1.9 MB/s | 73 MB 00:38 Dependencies resolved. ================================================================================================================================ Package Architecture Version Repository Size ================================================================================================================================ Installing: pgadmin4-server x86_64 6.16-1.el9 @commandline 73 M Transaction Summary ================================================================================================================================ Install 1 Package Total size: 73 M Installed size: 265 M Is this ok [y/N]: y Downloading Packages: Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : pgadmin4-server-6.16-1.el9.x86_64 1/1 Verifying : pgadmin4-server-6.16-1.el9.x86_64 1/1 Installed: pgadmin4-server-6.16-1.el9.x86_64 Complete!
- Apply or upgrade (which is the default at this point) the policycoreutils-python-utils package:
sudo dnf install policycoreutils-python-utils
Display detailed console log →
Last metadata expiration check: 0:50:44 ago on Mon 28 Nov 2022 12:59:07 AM EST. Package policycoreutils-python-utils-3.3-6.el9_0.noarch is already installed. Dependencies resolved. ================================================================================================================================ Package Architecture Version Repository Size ================================================================================================================================ Upgrading: libsemanage x86_64 3.4-2.el9 baseos 118 k policycoreutils x86_64 3.4-4.el9 baseos 202 k policycoreutils-devel x86_64 3.4-4.el9 appstream 139 k policycoreutils-python-utils noarch 3.4-4.el9 appstream 69 k python3-libsemanage x86_64 3.4-2.el9 appstream 80 k python3-policycoreutils noarch 3.4-4.el9 appstream 2.0 M Transaction Summary ================================================================================================================================ Upgrade 6 Packages Total download size: 2.6 M Is this ok [y/N]: y Downloading Packages: (1/6): policycoreutils-python-utils-3.4-4.el9.noarch.rpm 28 kB/s | 69 kB 00:02 (2/6): python3-libsemanage-3.4-2.el9.x86_64.rpm 32 kB/s | 80 kB 00:02 (3/6): policycoreutils-devel-3.4-4.el9.x86_64.rpm 55 kB/s | 139 kB 00:02 (4/6): libsemanage-3.4-2.el9.x86_64.rpm 189 kB/s | 118 kB 00:00 (5/6): python3-policycoreutils-3.4-4.el9.noarch.rpm 2.8 MB/s | 2.0 MB 00:00 (6/6): policycoreutils-3.4-4.el9.x86_64.rpm 302 kB/s | 202 kB 00:00 -------------------------------------------------------------------------------------------------------------------------------- Total 521 kB/s | 2.6 MB 00:05 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Upgrading : libsemanage-3.4-2.el9.x86_64 1/12 Upgrading : python3-libsemanage-3.4-2.el9.x86_64 2/12 Upgrading : policycoreutils-3.4-4.el9.x86_64 3/12 Running scriptlet: policycoreutils-3.4-4.el9.x86_64 3/12 Upgrading : python3-policycoreutils-3.4-4.el9.noarch 4/12 Upgrading : policycoreutils-python-utils-3.4-4.el9.noarch 5/12 Upgrading : policycoreutils-devel-3.4-4.el9.x86_64 6/12 Cleanup : policycoreutils-devel-3.3-6.el9_0.x86_64 7/12 Cleanup : policycoreutils-python-utils-3.3-6.el9_0.noarch 8/12 Cleanup : python3-policycoreutils-3.3-6.el9_0.noarch 9/12 Cleanup : python3-libsemanage-3.3-2.el9.x86_64 10/12 Running scriptlet: policycoreutils-3.3-6.el9_0.x86_64 11/12 Cleanup : policycoreutils-3.3-6.el9_0.x86_64 11/12 Cleanup : libsemanage-3.3-2.el9.x86_64 12/12 Running scriptlet: libsemanage-3.3-2.el9.x86_64 12/12 Verifying : policycoreutils-devel-3.4-4.el9.x86_64 1/12 Verifying : policycoreutils-devel-3.3-6.el9_0.x86_64 2/12 Verifying : policycoreutils-python-utils-3.4-4.el9.noarch 3/12 Verifying : policycoreutils-python-utils-3.3-6.el9_0.noarch 4/12 Verifying : python3-libsemanage-3.4-2.el9.x86_64 5/12 Verifying : python3-libsemanage-3.3-2.el9.x86_64 6/12 Verifying : python3-policycoreutils-3.4-4.el9.noarch 7/12 Verifying : python3-policycoreutils-3.3-6.el9_0.noarch 8/12 Verifying : libsemanage-3.4-2.el9.x86_64 9/12 Verifying : libsemanage-3.3-2.el9.x86_64 10/12 Verifying : policycoreutils-3.4-4.el9.x86_64 11/12 Verifying : policycoreutils-3.3-6.el9_0.x86_64 12/12 Upgraded: libsemanage-3.4-2.el9.x86_64 policycoreutils-3.4-4.el9.x86_64 policycoreutils-devel-3.4-4.el9.x86_64 policycoreutils-python-utils-3.4-4.el9.noarch python3-libsemanage-3.4-2.el9.x86_64 python3-policycoreutils-3.4-4.el9.noarch Complete!
- Apply the pgadmin4-desktop package:
sudo dnf install -y https://ftp.postgresql.org/pub/pgadmin/pgadmin4/yum/redhat/rhel-9Server-x86_64/pgadmin4-desktop-6.16-1.el9.x86_64.rpm
Display detailed console log →
Last metadata expiration check: 1:14:02 ago on Mon 28 Nov 2022 12:59:07 AM EST. pgadmin4-desktop-6.16-1.el9.x86_64.rpm 3.1 MB/s | 88 MB 00:28 Dependencies resolved. ================================================================================================================================ Package Architecture Version Repository Size ================================================================================================================================ Installing: pgadmin4-desktop x86_64 6.16-1.el9 @commandline 88 M Installing dependencies: libatomic x86_64 11.3.1-2.1.el9.alma baseos 56 k Transaction Summary ================================================================================================================================ Install 2 Packages Total size: 88 M Total download size: 56 k Installed size: 341 M Downloading Packages: libatomic-11.3.1-2.1.el9.alma.x86_64.rpm 83 kB/s | 56 kB 00:00 -------------------------------------------------------------------------------------------------------------------------------- Total 39 kB/s | 56 kB 00:01 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Regex version mismatch, expected: 10.40 2022-04-14 actual: 10.37 2021-05-26 Preparing : 1/1 Installing : libatomic-11.3.1-2.1.el9.alma.x86_64 1/2 Installing : pgadmin4-desktop-6.16-1.el9.x86_64 2/2 Running scriptlet: pgadmin4-desktop-6.16-1.el9.x86_64 2/2 Verifying : libatomic-11.3.1-2.1.el9.alma.x86_64 1/2 Verifying : pgadmin4-desktop-6.16-1.el9.x86_64 2/2 Installed: libatomic-11.3.1-2.1.el9.alma.x86_64 pgadmin4-desktop-6.16-1.el9.x86_64 Complete!
- Apply the pgadmin-server package:
- You configure your .bashrc file to add the pgadmin4 directory to your $PATH environment variable.
# Add the pgadmin4 executable to the $PATH. export set PATH=$PATH:/usr/pgadmin4/bin
You also configure your .bashrc file to add a pgadmin4 function, which simplifies how you call the pgadmin4 executable.
# Function to ensure pgadmin4 call is simplified and without warnings. pgadmin4 () { # Call the pgadmin4 executable. if [[ `type -t pgadmin4` = 'function' ]]; then if [ -f "/usr/pgadmin4/bin/pgadmin4" ]; then /usr/pgadmin4/bin/pgadmin4 2>/dev/null & else echo "[/usr/pgadmin4/bin/pgadmin4] is not found." fi else echo "[pgadmin4] is not a function" fi }
You can launch your pgadmin4 program file now with the following syntax as the student user:
pgadmin4
It takes a couple moments to launch the pgadmin4 desktop. The initial screen will look like:

After pgadmin4 launches, you’re prompted for a master password. Enter the password and click the OK button to proceed.
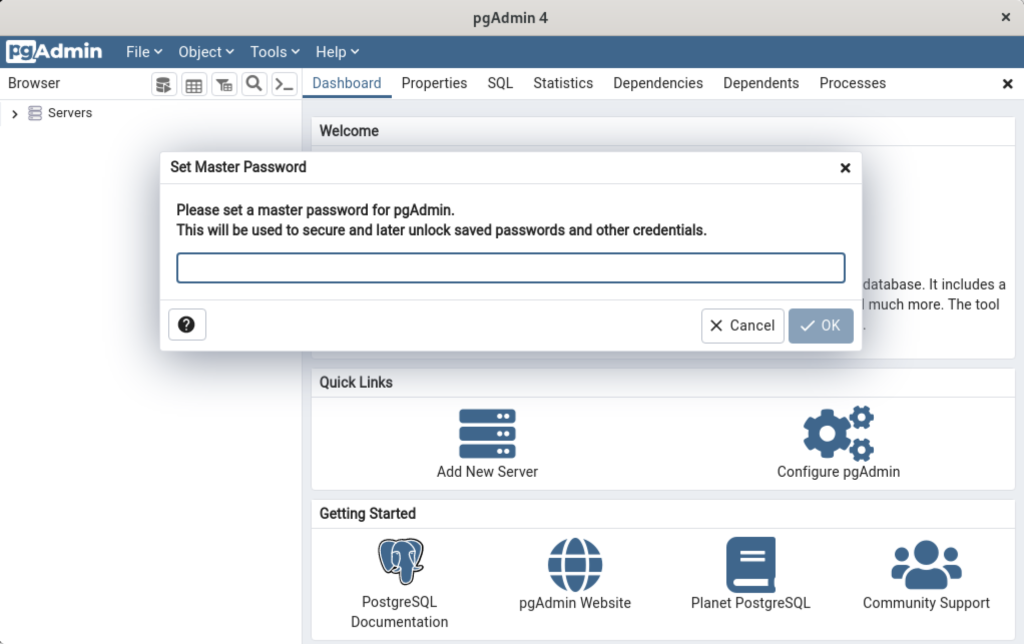
After entering the password, you arrive at the base dialog, as shown.
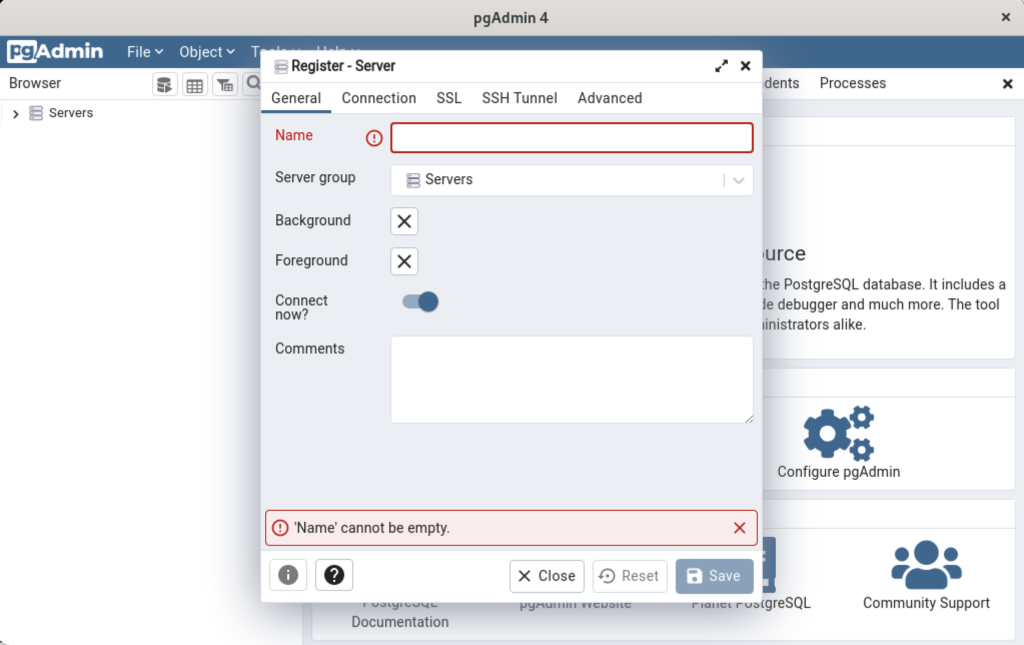
Click the Add New Server link, which prompts you to register your database. Enter videodb in the Name field and click the Connection tab to the right of the General tab.
In the Connection dialog, enter the following values:
- Host name/address: localhost
- Port: 5432
- Maintenance database: postgres
- Username: student
- Password: student

Enter a name for your database. In this example, videodb is the Server Name. Click the Save button to proceed.

- You need to install three sets of packages. They’re the pgadmin-server, policycoreutils-python-utils, and pgadmin4-desktop.
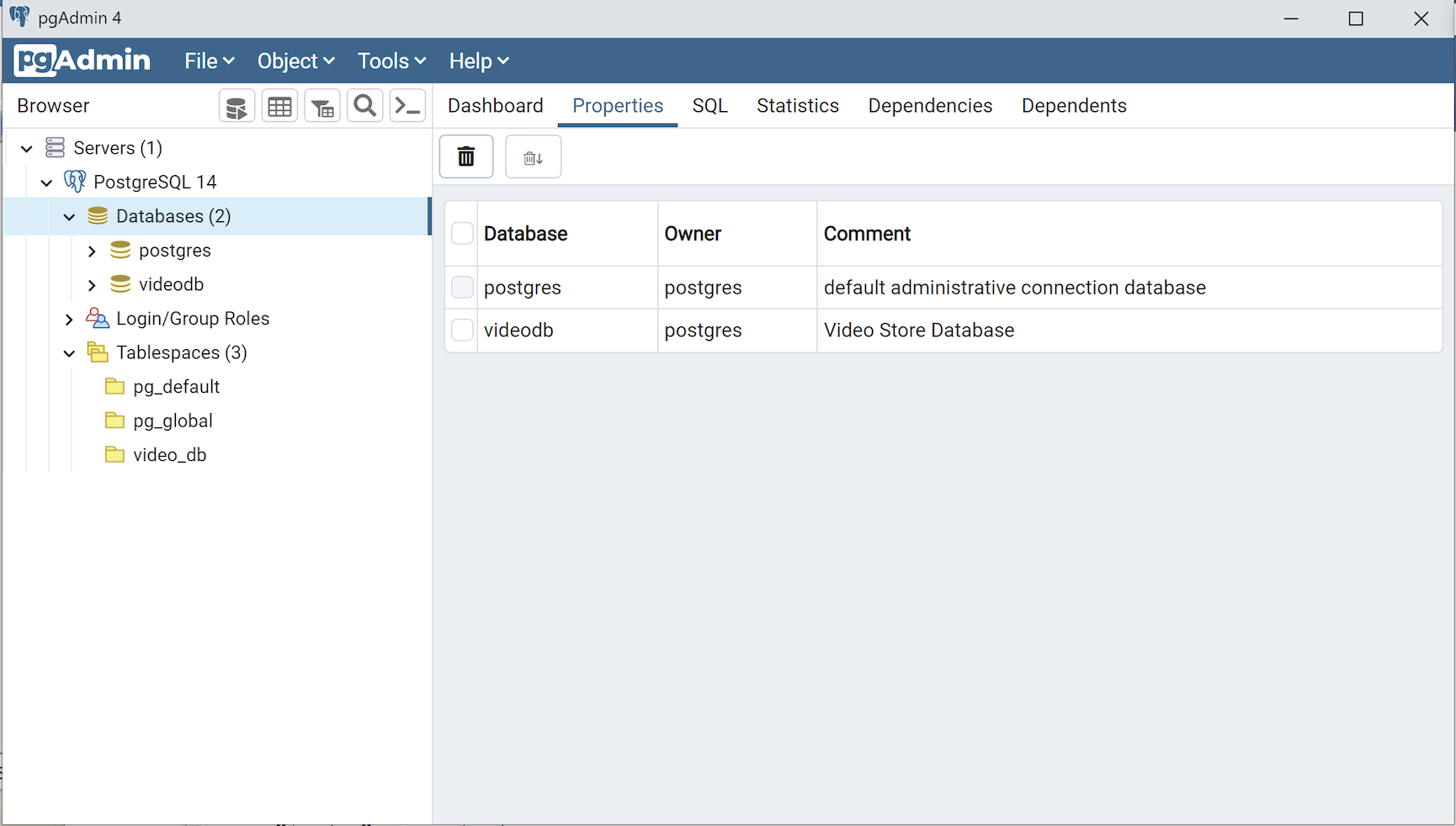
This completes the instructions for installing, configuring, and using PostgreSQL on AlmaLinux. As always, I hope it helps those looking for instructions.
PostgreSQL Trigger 1
This entry covers how to write a statement logging trigger for PostgreSQL. It creates two tables: avenger and avenger_log; one avenger_t1 trigger, and a testing INSERT statement.
It was written to help newbies know how and what to return from a function written for a statement-level trigger. They often get stuck on the following when they try to return true. The term non-composite is another way to describe the tuple inserted.
psql:basics_postgres.sql: 59: ERROR: cannot return non-composite value from function returning composite type CONTEXT: PL/pgSQL function write_avenger_t1() line 15 at RETURN |
The avenger table:
/* Conditionally drop table. */ DROP TABLE IF EXISTS avenger; /* Create table. */ CREATE TABLE avenger ( avenger_id SERIAL , avenger_name VARCHAR(30) , first_name VARCHAR(20) , last_name VARCHAR(20)); |
Seed the avenger table:
/* Seed the avenger table with data. */ INSERT INTO avenger ( first_name, last_name, avenger_name ) VALUES ('Anthony', 'Stark', 'Iron Man') ,('Thor', 'Odinson', 'God of Thunder') ,('Steven', 'Rogers', 'Captain America') ,('Bruce', 'Banner', 'Hulk') ,('Clinton', 'Barton', 'Hawkeye') ,('Natasha', 'Romanoff', 'Black Widow') ,('Peter', 'Parker', 'Spiderman') ,('Steven', 'Strange', 'Dr. Strange') ,('Scott', 'Lange', 'Ant-man'); |
The avenger_log table:
/* Conditionally drop table. */ DROP TABLE IF EXISTS avenger_log; /* Create table. */ CREATE TABLE avenger_log ( avenger_log_id SERIAL , trigger_name VARCHAR(30) , trigger_timing VARCHAR(6) , trigger_event VARCHAR(6) , trigger_type VARCHAR(12)); |
The INSERT statement that tests the trigger:
DROP FUNCTION IF EXISTS avenger_t1_function; CREATE FUNCTION avenger_t1_function() RETURNS TRIGGER AS $$ BEGIN /* Insert a row into the avenger_log table. * Also, see PostrgreSQL 39.9 Trigger Procedures. */ INSERT INTO avenger_log ( trigger_name , trigger_timing , trigger_event , trigger_type ) VALUES ( UPPER(TG_NAME) , TG_WHEN , TG_OP , TG_LEVEL ); /* A statement trigger doesn't use a composite type or tuple, * it should simply return an empty composite type or void. */ RETURN NULL; END; $$ LANGUAGE plpgsql; |
The avenger_t1 statement trigger:
CREATE TRIGGER avenger_t1 BEFORE INSERT ON avenger EXECUTE FUNCTION avenger_t1_function(); |
The INSERT statement:
INSERT INTO avenger ( first_name, last_name, avenger_name ) VALUES ('Hope', 'van Dyne', 'Wasp'); |
The results logged to the avenger_log table from a query:
avenger_log_id | trigger_name | trigger_timing | trigger_event | trigger_type
----------------+--------------+----------------+---------------+--------------
1 | AVENGER_T1 | BEFORE | INSERT | STATEMENT
(1 row) |
As always, I hope this helps those looking for a solution.
