Archive for the ‘DevOps’ Category
Bash Debug Function
My students working in Linux would have a series of labs to negotiate and I’d have them log the activities of their Oracle SQL scripts. Many of them would suffer quite a bit because they didn’t know how to find the errors in the log files.
I wrote this SQL function for them to put in their .bashrc files. It searches all the .txt files for errors and organizes them by log file, line number, and descriptive error message.
errors () { label="File Name:Line Number:Error Code"; list=`ls ./*.$1 | wc -l`; if [[ ${list} -eq 1 ]]; then echo ${label}; echo "----------------------------------------"; filename=`ls *.txt`; echo ${filename}:`find . -type f | grep -in *.txt -e ora\- -e pls\- -e sp2\-`; else if [[ ${list} -gt 1 ]]; then echo ${label}; echo "----------------------------------------"; find . -type f | grep --color=auto -in *.txt -e ora\- -e pls\- -e sp2\-; fi; fi } |
I hope it helps others now too.
What’s up on M1 Chip?
I’ve been trying to sort out what’s up on Oracle’s support of Apple’s M1 (arm64) chip. It really is a niche area. It only applies to those of us who work on a macOS machines with Oracle Database technology; and then only when we want to install a version of Oracle Database 21c or newer in Windows OS for testing. Since bootcamp is now gone, these are only virtualized solutions through a full virtualization product or containerized with Docker of Kubernetes.
The Best Virtual Machine Software for Mac 2022 (4/11/2022) article lets us know that only Parallels fully supports Windows virtualization on the ARM64 chip. Then, there’s the restriction that you must use Monterey or Big Sur (macOS) and Windows 11 arm64.
Instructions were published on On how to run Windows 11 on an Apple M1 a couple weeks ago. They use the free UTM App from the Apple Store and provide the download site for the Windows Insider Program. You can’t get a copy of Windows 11 arm64 without becoming part of the Windows Insider Program.
The next step would be to try and install Oracle Database 21c on Windows 11 arm64, which may or may not work. At least, I haven’t tested it yet and can’t make the promise that it works. After all, I doubt it will work because the Oracle Database 21c documentation says it only supports x64 (or Intel) architecture.
If anybody knows what Oracle has decided, will decide or even their current thinking on the issue, please make a comment.
Oracle ODBC DSN
As I move forward with trying to build an easy to use framework for data analysts who use multiple database backends and work on Windows OS, here’s a complete script that lets you run any query stored in a file to return a CSV file. It makes the assumption that you opted to put the user ID and password in the Windows ODBC DSN, and only provides the ODBC DSN name to make the connection to the ODBC library and database.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 | # A local function for verbose reporting. function Get-Message ($param, $value = $null) { if (!($value)) { Write-Host "Evaluate swtich [" $param "]" } else { Write-Host "Evaluate parameter [" $param "] and [" $value "]" } } # Read SQLStatement file and minimally parse it. function Get-SQLStatement ($sqlStatement) { # Set localvariable for return string value. $statement = "" # Read a file line-by-line. foreach ($line in Get-Content $sqlStatement) { # Use regular expression to replace multiple whitespace. $line = $line -replace '\s+', ' ' # Add a whitespace to avoid joining keywords from different lines; # and remove trailing semicolons which are unneeded. if (!($line.endswith(";"))) { $statement += $line + " " } else { $statement += $line.trimend(";") } } # Returned minimally parsed statement. return $statement } # Set default type of SQL statement value to a query. $stmt = "select" # Set a variable to hold a SQL statement from a file. $query = "" # Set default values for SQL input and output files. $outFile = "output.csv" $sqlFile = "query.sql" # Set default path to: %USERPROFILE%\AppData\Local\Temp folder, but ir # the tilde (~) in lieu of the %USERPROFILE% environment variable value. $path = "~\AppData\Local\Temp" # Set a verbose switch. $verbose = $false # Wrap the Parameter call to avoid a type casting warning. try { param ( [Parameter(Mandatory)][hashtable]$args ) } catch {} # Check for switches and parameters with arguments. for ($i = 0; $i -lt $args.count; $i += 1) { if (($args[$i].startswith("-")) -and ($args[$i + 1].startswith("-"))) { if ($args[$i] = "-v") { $verbose = $true } # Print to verbose console. if ($verbose) { Get-Message $args[$i] }} elseif ($args[$i].startswith("-")) { # Print to verbose console. if ($verbose) { Get-Message $args[$i] $args[$i + 1] } # Evaluate and take action on parameters and values. if ($args[$i] -eq "-o") { $outfile = $args[$i + 1] } elseif ($args[$i] -eq "-q") { $sqlFile = $args[$i + 1] } elseif ($args[$i] -eq "-p") { $path = $args[$i + 1] } } } # Set a PowerShell Virtual Drive. New-PSDrive -Name folder -PSProvider FileSystem -Description 'Forder Location' ` -Root $path | Out-Null # Remove the file only when it exists. if (Test-Path folder:$outFile) { Remove-Item -Path folder:$outFile } # Read SQL file into minimally parsed string. if (Test-Path folder:$sqlFile) { $query = Get-SQLStatement $sqlFile } # Set a ODBC DSN connection string. $ConnectionString = 'DSN=OracleGeneric' # Set an Oracle Command Object for a query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = $query; # Attempt to read SQL command. try { $row = $Command.ExecuteReader(); # Read while records are found. while ($row.Read()) { # Initialize output for each row. $output = "" # Navigate across all columns (only two in this example). for ($column = 0; $column -lt $row.FieldCount; $column += 1) { # Mechanic for comma-delimit between last and first name. if ($output.length -eq 0) { $output += $row[$column] } else { $output += ", " + $row[$column] } } # Write the output from the database to a file. Add-Content -Value $output -Path folder:$outFile } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $row.Close() } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
You can use a command-line call like this:
powershell ./OracleContact.ps1 -v -o output.csv -q script.sql -p . |
It produces the following verbose output to the console:
Evaluate swtich [ -v ] Evaluate parameter [ -o ] and [ output.csv ] Evaluate parameter [ -q ] and [ script.sql ] Evaluate parameter [ -p ] and [ . ] |
You can suppress printing to the console by eliminating the -v switch from the parameter list.
As always, I hope this helps those looking for a solution to less tedious interactions with the Oracle database.
Transaction Management
Transaction Management
Learning Outcomes
- Learn how to use Multiversion Concurrency Control (MVCC).
- Learn how to manage ACID-compliant transactions.
- Learn how to use:
- SAVEPOINT Statement
- COMMIT Statement
- ROLLBACK Statement
Lesson Material
Transaction Management involves two key components. One is Multiversion Concurrency Control (MVCC) so one user doesn’t interfere with another user. The other is data transactions. Data transactions packag SQL statements in the scope of an imperative language that uses Transaction Control Language (TCL) to extend ACID-compliance from single SQL statements to groups of SQL statements.
Multiversion Concurrency Control (MVCC)
Multiversion Concurrency Control (MVCC) uses database snapshots to provide transactions with memory-persistent copies of the database. This means that users, via their SQL statements, interact with the in-memory copies of data rather than directly with physical data. MVCC systems isolate user transactions from each other and guarantee transaction integrity by preventing dirty transactions, writes to the data that shouldn’t happen and that make the data inconsistent. Oracle Database 12c prevents dirty writes by its MVCC and transaction model.
Transaction models depend on transactions, which are ACID-compliant blocks of code. Oracle Database 12c provides an MVCC architecture that guarantees that all changes to data are ACID-compliant, which ensures the integrity of concurrent operations on data—transactions.
ACID-compliant transactions meet four conditions:
- Atomic
- They complete or fail while undoing any partial changes.
- Consistent
- They change from one state to another the same way regardless of whether
the change is made through parallel actions or serial actions. - Isolated
- Partial changes are never seen by other users or processes in the concurrent system.
- Durable
- They are written to disk and made permanent when completed.
Oracle Database 12c manages ACID-compliant transactions by writing them to disk first, as redo log files only or as both redo log files and archive log files. Then it writes them to the database. This multiple-step process with logs ensures that Oracle database’s buffer cache (part of the instance memory) isn’t lost from any completed transaction. Log writes occur before the acknowledgement-of-transactions process occurs.
The smallest transaction in a database is a single SQL statement that inserts, updates, or deletes rows. SQL statements can also change values in one or more columns of a row in a table. Each SQL statement is by itself an ACID-compliant and MVCC-enabled transaction when managed by a transaction-capable database engine. The Oracle database is always a transaction-capable system. Transactions are typically a collection of SQL statements that work in close cooperation to accomplish a business objective. They’re often grouped into stored programs, which are functions, procedures, or triggers. Triggers are specialized programs that audit or protect data. They enforce business rules that prevent unauthorized changes to the data.
SQL statements and stored programs are foundational elements for development of business applications. They contain the interaction points between customers and the data and are collectively called the application programming interface (API) to the database. User forms (typically web forms today) access the API to interact with the data. In well-architected business application software, the API is the only interface that the form developer interacts with.
Database developers, such as you and I, create these code components to enforce business rules while providing options to form developers. In doing so, database developers must guard a few things at all cost. For example, some critical business logic and controls must prevent changes to the data in specific tables, even changes in API programs. That type of critical control is often written in database triggers. SQL statements are events that add, modify, or delete data. Triggers guarantee that API code cannot make certain additions, modifications, or deletions to critical resources, such as tables. Triggers can run before or after SQL statements. Their actions, like the SQL statements themselves, are temporary until the calling scope sends an instruction to commit the work performed.
A database trigger can intercept values before they’re placed in a column, and it can ensure that only certain values can be inserted into or updated in a column. A trigger overrides an INSERT or UPDATE statement value that violates a business rule and then it either raises an error and aborts the transaction or changes the value before it can be inserted or updated into the table. Chapter 12 offers examples of both types of triggers in Oracle Database 12c.
MVCC determines how to manage transactions. MVCC guarantees how multiple users’ SQL statements interact in an ACID compliant manner. The next two sections qualify how data transactions work and how MVCC locks and isolates partial results from data transactions.
Data Transaction
Data Manipulation Language (DML) commands are the SQL statements that transact against the data. They are principally the INSERT, UPDATE, and DELETE statements. The INSERT statement adds new rows in a table, the UPDATE statement modifies columns in existing rows, and the DELETE statement removes a row from a table.
The Oracle MERGE statement transacts against data by providing a conditional insert or update feature. The MERGE statement lets you add new rows when they don’t exist or change column values in rows that do exist.
Inserting data seldom encounters a conflict with other SQL statements because the values become a new row or rows in a table. Updates and deletes, on the other hand, can and do encounter conflicts with other UPDATE and DELETE statements. INSERT statements that encounter conflicts occur when columns in a new row match a preexisting row’s uniquely constrained columns. The insertion is disallowed because only one row can contain the unique column set.
These individual transactions have two phases in transactional databases such as Oracle. The first phase involves making a change that is visible only to the user in the current session. The user then has the option of committing the change, which makes it permanent, or rolling back the change, which undoes the transaction. Developers use Transaction Control Language (TCL) commands to confirm or cancel transactions. The COMMIT statement confirms or makes permanent any change, and the ROLLBACK statement cancels or undoes any change.
![]()
A generic transaction lifecycle for a two-table insert process implements a business rule that specifies that neither INSERT statement works unless they both work. Moreover, if the first INSERT statement fails, the second INSERT statement never runs; and if the second INSERT statement fails, the first INSERT statement is undone by a ROLLBACK statement to a SAVEPOINT.
After a failed transaction is unwritten, good development practice requires that you write the failed event(s) to an error log table. The write succeeds because it occurs after the ROLLBACK statement but before the COMMIT statement.
A SQL statement followed by a COMMIT statement is called a transaction process, or a two-phase commit (2PC) protocol. ACID-compliant transactions use a 2PC protocol to manage one SQL statement or collections of SQL statements. In a 2PC protocol model, the INSERT, UPDATE, MERGE, or DELETE DML statement starts the process and submits changes. These DML statements can also act as events that fire database triggers assigned to the table being changed.
Transactions become more complex when they include database triggers because triggers can inject an entire layer of logic within the transaction scope of a DML statement. For example, database triggers can do the following:
- Run code that verifies, changes, or repudiates submitted changes
- Record additional information after validation in other tables (they can’t write to the table being changed—or, in database lexicon, “mutated”
- Throw exceptions to terminate a transaction when the values don’t meet business rules
As a general rule, triggers can’t contain a COMMIT or ROLLBACK statement because they run inside the transaction scope of a DML statement. Oracle databases give developers an alternative to this general rule because they support autonomous transactions. Autonomous transactions run outside the transaction scope of the triggering DML statement. They can contain a COMMIT statement and act independently of the calling scope statement. This means an autonomous trigger can commit a transaction when the calling transaction fails.
As independent statements or collections of statements add, modify, and remove rows, one statement transacts against data only by locking rows: the SELECT statement. A SELECT statement typically doesn’t lock rows when it acts as a cursor in the scope of a stored program. A cursor is a data structure that contains rows of one-to-many columns in a stored program. This is also known as a list of record structures.
Cursors act like ordinary SQL queries, except they’re managed by procedure programs row by row. There are many examples of procedural programming languages. PL/SQL and SQL/PSM programming languages are procedural languages designed to run inside the database. C, C++, C#, Java, Perl, and PHP are procedural languages that interface with the database through well-defined interfaces, such as Java Database Connectivity (JDBC) and Open Database Connectivity (ODBC).
Cursors can query data two ways. One way locks the rows so that they can’t be changed until the cursor is closed; closing the cursor releases the lock. The other way doesn’t lock the rows, which allows them to be changed while the program is working with the data set from the cursor. The safest practice is to lock the rows when you open the cursor, and that should always be the case when you’re inserting, updating, or deleting rows that depend on the values in the cursor not changing until the transaction lifecycle of the program unit completes.
Loops use cursors to process data sets. That means the cursors are generally opened at or near the beginning of program units. Inside the loop the values from the cursor support one to many SQL statements for one to many tables.
Stored and external programs create their operational scope inside a database connection when they’re called by another program. External programs connect to a database and enjoy their own operational scope, known as a session scope. The session defines the programs’ operational scope. The operational scope of a stored program or external program defines the transaction scope. Inside the transaction scope, the programs interact with data in tables by inserting, updating, or deleting data until the operations complete successfully or encounter a critical failure. These stored program units commit changes when everything completes successfully, or they roll back changes when any critical instruction fails. Sometimes, the programs are written to roll back changes when any instruction fails.
In the Oracle Database, the most common clause to lock rows is the FOR UPDATE clause, which is appended to a SELECT statement. An Oracle database also supports a WAIT n seconds or NOWAIT option. The WAIT option is a blessing when you want to reply to an end user form’s request and can’t make the change quickly. Without this option, a change could hang around for a long time, which means virtually indefinitely to a user trying to run your application. The default value in an Oracle database is NOWAIT, WAIT without a timeout, or wait indefinitely.
You should avoid this default behavior when developing program units that interact with customers. The Oracle Database also supports a full table lock with the SQL LOCK TABLE command, but you would need to embed the command inside a stored or external program’s instruction set.
Oracle Unit Test
A unit test script may contain SQL or PL/SQL statements or it may call another script file that contains SQL or PL/SQL statements. Moreover, a script file is a way to bundle several activities into a single file because most unit test programs typically run two or more instructions as unit tests.
Unconditional Script File
You can write a simple unit test like the example program provided in the Lab 1 Help Section, which includes conditional logic. However, you can write a simpler script that is unconditional and raises exceptions when preconditions do not exist.
The following script file creates a one table and one_s sequence. The DROP TABLE and DROP SEQUENCE statements have the same precondition, which is that the table or sequence must previously exist.
-- Drop table one. DROP TABLE one; -- Crete table one. CREATE TABLE one ( one_id NUMBER , one_text VARCHAR2(10)); -- Drop sequence one_s. DROP SEQUENCE one_s; -- Create sequence one_s. CREATE SEQUENCE one_s; |
After writing the script file, you can save it in the lab2 subdirectory as the unconditional.sql file. After you login to the SQL*Plus environment from the lab2 subdirectory. You call the unconditional.sql script file from inside the SQL*Plus environment with the following syntax:
@unconditional.sql |
It will display the following output, which raises an exception when the one table or one_s sequence does not already exist in the schema or database:
DROP TABLE one
*
ERROR at line 1:
ORA-00942: table or view does not exist
Table created.
DROP SEQUENCE one_s
*
ERROR at line 1:
ORA-02289: sequence does not exist
Sequence created. |
An unconditional script raises exceptions when a precondition of the statement does not exist. The precondition is not limited to objects, like the table or sequence; and the precondition may be specific data in one or several rows of one or several tables. You can avoid raising conditional errors by writing conditional scripts.
Conditional Script File
A conditional script file contains statements that check for a precondition before running a statement, which effectively promotes their embedded statements to a lambda function. The following logic recreates the logic of the unconditional.sql script file as a conditional script file:
-- Conditionally drop a table and sequence. BEGIN FOR i IN (SELECT object_name , object_type FROM user_objects WHERE object_name IN ('ONE','ONE_S') ORDER BY object_type ) LOOP IF i.object_type = 'TABLE' THEN EXECUTE IMMEDIATE 'DROP TABLE '||i.object_name||' CASCADE CONSTRAINTS'; ELSE EXECUTE IMMEDIATE 'DROP SEQUENCE '||i.object_name; END IF; END LOOP; END; / -- Crete table one. CREATE TABLE one ( one_id NUMBER , one_text VARCHAR2(10)); -- Create sequence one_s. CREATE SEQUENCE one_s; |
You can save this script in the lab2 subdirectory as conditional.sql and then unit test it in SQL*Plus. You must manually drop the one table and one_s sequence before running the conditional.sql script to test the preconditions.
You will see that the conditional.sql script does not raise an exception because the one table or one_s sequence is missing. It should generate output to the console, like this:
PL/SQL procedure successfully completed. Table created. Sequence created. |
As a rule, you should always write conditional script files. Unconditional script files throw meaningless errors, which may cause your good code to fail a deployment test that requires error free code.
MySQL CSV Output
Saturday, I posted how to use Microsoft ODBC DSN to connect to MySQL. Somebody didn’t like the fact that the PowerShell program failed to write a *.csv file to disk because the program used the Write-Host command to write to the content of the query to the console.
I thought that approach was a better as an example. However, it appears that it wasn’t because not everybody knows simple redirection. The original program can transfer the console output to a file, like:
powershell .\MySQLODBC.ps1 > output.csv |
So, the first thing you need to do is add a parameter list, like:
2 3 4 | param ( [Parameter(Mandatory)][string]$fileName ) |
Anyway, it’s trivial to demonstrate how to modify the PowerShell program to write to a disk. You should also create a virtual PowerShell drive before writing the file. That’s because you can change the physical directory anytime you want with minimal changes to rest of your code’s file references.
You can create a PowerShell virtual drive with the following command:
7 8 | New-PSDrive -Name test -PSProvider FileSystem -Description 'Test area' ` -Root C:\Data\cit225\mysql\test |
but, it will write the following to console:
Name Used (GB) Free (GB) Provider Root CurrentLocation ---- --------- --------- -------- ---- --------------- test 0.00 28.74 FileSystem C:\Data\cit225\mysql\test |
You can suppress the console output with Microsoft’s version of redirection to the void (> /dev/null), which pipes (|) the standard out (stdout) to Out-Null, like:
7 8 | New-PSDrive -Name test -PSProvider FileSystem -Description 'Test area' ` -Root C:\Data\cit225\mysql\test | Out-Null |
Since the program may run before an output file has been created, or after its been created and removed, you need to check whether the file exists before attempting to remove it. PowerShell provides the Test-Path command to check for the existence of a file and the Remove-Item command to remove a file, like:
11 12 | if (Test-Path test:$fileName) { Remove-Item -Path test:$fileName } |
Then, you simply replace the Write-Host call in the other program with the Add-Content command:
Add-Content -Value $output -Path test:$fileName |
Now, the PowerShell script file writes the MySQL query’s output to an output.csv file. You can call the MySQLContact.ps1 script file with the following syntax:
powershell MySQLContact.ps1 output.csv |
In case these changes don’t make sense outside the scope of the full script, here is the rewritten script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | # Define parameter list for mandatory file name. param ( [Parameter(Mandatory)][string]$fileName ) # Define a PowerShell Virtual Drive. New-PSDrive -Name test -PSProvider FileSystem -Description 'Test area' ` -Root C:\Data\cit225\mysql\test | Out-Null # Remove the file only when it exists. if (Test-Path test:$fileName) { Remove-Item -Path test:$fileName } # Define a ODBC DSN connection string. $ConnectionString = 'DSN=MySQLODBC2' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT last_name " + ", first_name " + "FROM contact " + "ORDER BY 1, 2"; # Attempt to read SQL command. try { $row = $Command.ExecuteReader(); # Read while records are found. while ($row.Read()) { # Initialize output for each row. $output = "" # Navigate across all columns (only two in this example). for ($column = 0; $column -lt $row.FieldCount; $column += 1) { # Mechanic for comma-delimit between last and first name. if ($output.length -eq 0) { $output += $row[$column] } else { $output += ", " + $row[$column] } } # Write the output from the database to a file. Add-Content -Value $output -Path test:$fileName } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $row.Close() } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
While I understand you might want to go to this level of effort if you where building a formal cmdlet, I’m not convinced its worth the effort in an ordinary PowerShell script. However, I don’t like to leave a question unanswered.
MySQL ODBC DSN
This post explains and demonstrates how to install, configure, and use the MySQL’s ODBC libraries and a DSN (Data Source Name) to connect your Microsoft PowerShell programs to a locally or remotely installed MySQL database. After you’ve installed the MySQL ODBC library, use Windows search field to find the ODBC Data Sources dialog and run it as administrator.
There are four steps to setup, test, and save your ODBC Data Source Name (DSN) for MySQL. You can click on the images on the right to launch them in a more readable format or simply read the instructions.
MySQL ODBC Setup Steps
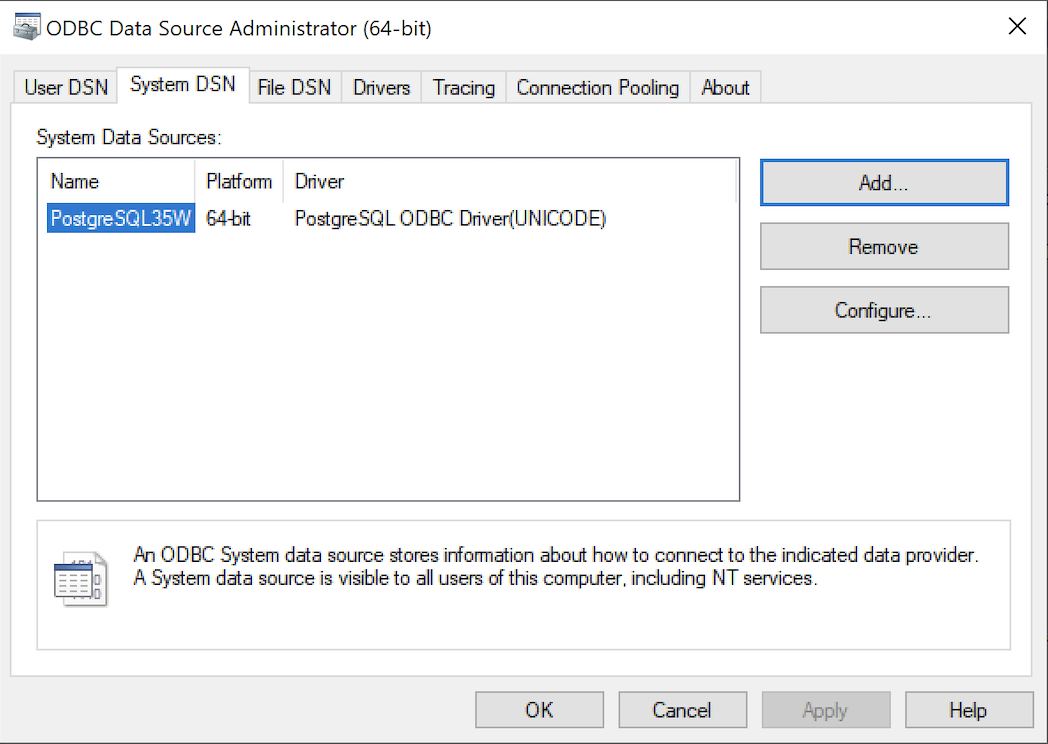
- Click the SystemDSN tab to see he view which is exactly like the User DSN tab. Click the Add button to start the workflow.
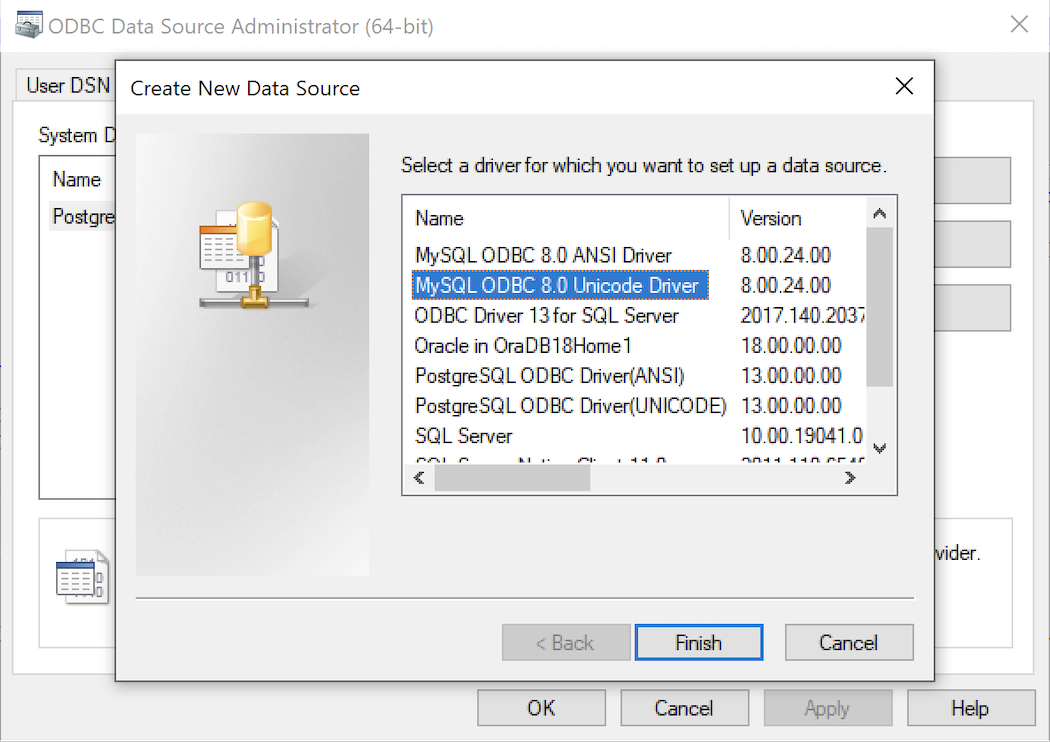
- The Create New Data Source dialog requires you select the MySQL ODBC Driver(UNICODE) option from the list and click the Finish button to proceed.
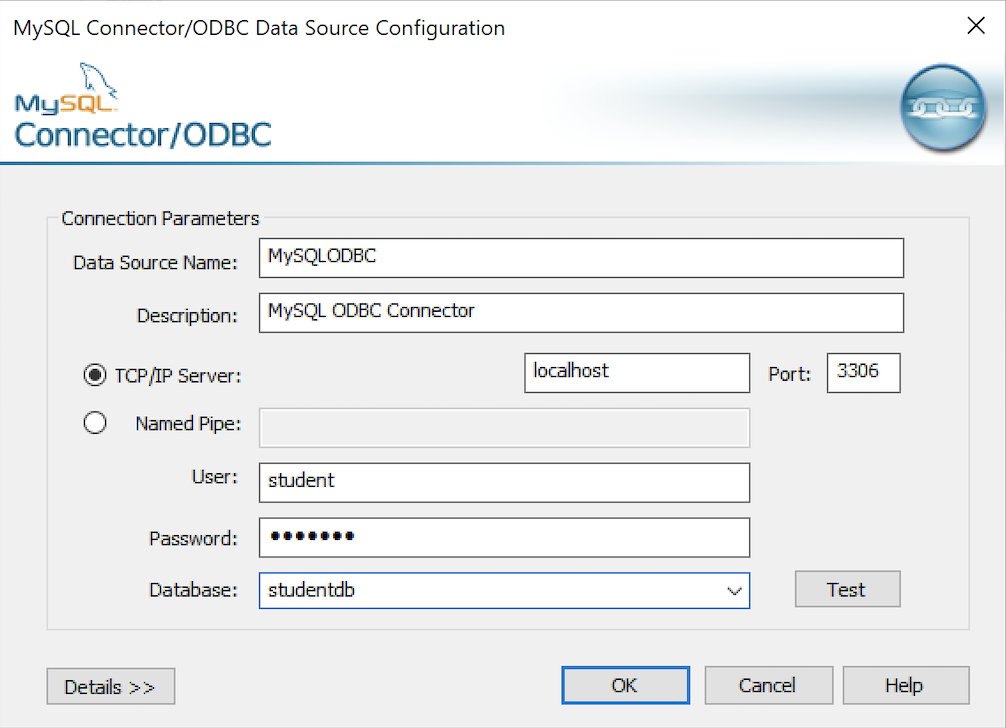
- The MySQL Unicode ODBC Driver Setup dialog should complete the prompts as follows below. If you opt for localhost as the server value and you have a DCHP IP address, make sure you’ve configured your hosts file in the C:\Windows\System32\drivers\etc directory. You should enter the following two lines in the hosts file:
127.0.0.1 localhost ::1 localhost
These are the string values you should enter in the MySQL Unicode ODBC Driver Setup dialog:
Data Source: MySQLODBC Database: studentdb Server: localhost User Name: student Description: MySQL ODBC Connector Port: 3306 Password: student
After you complete the entry, click the Test button.
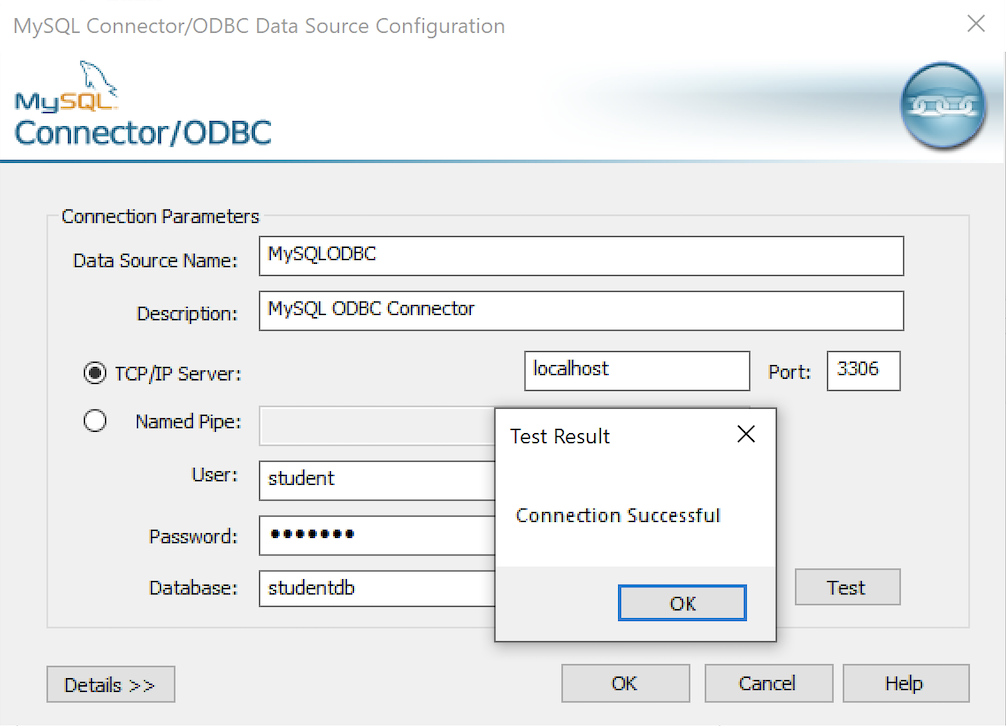
- The Connection Test dialog should return a “Connection successful” message. Click the OK button to continue, and then click the OK button in the next two screens.
After you have created the System MySQL ODBC Setup, it’s time to build a PowerShell Cmdlet (or, Commandlet). Some documentation and blog notes incorrectly suggest you need to write a connection string with a UID and password, like:
$ConnectionString = 'DSN=MySQLODBC;Uid=student;Pwd=student' |
You can do that if you leave the UID and password fields empty in the MySQL ODBC Setup but it’s recommended to enter them there to avoid putting them in your PowerShell script file.
The UID and password are unnecessary in the connection string when they’re in MySQL ODBC DSN. You can use a connection string like the following when the UID and password are in the DSN:
$ConnectionString = 'DSN=MySQLODBC' |
You can create a MySQLCursor.ps1 Cmdlet like the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | # Define a ODBC DSN connection string. $ConnectionString = 'DSN=MySQLODBC' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT database();"; # Attempt to read SQL command. try { $Reader = $Command.ExecuteReader(); # Read while records are found. while ($Reader.Read()) { Write-Host "Current Database [" $Reader[0] "]"} } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $Reader.Close() } } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
Line 14 assigns a SQL query that returns a single row with one column as the CommandText of a Command object. Line 22 reads the zero position of a row or record set with only one column.
You call the MySQLCursor.ps1 Cmdlet with the following syntax:
powershell .\MySQLCursor.ps1 |
It returns:
Current Database [ studentdb ] |
A more realistic way to write a query would return multiple rows with a set of two or more columns. The following program queries a table with multiple rows of two columns, but the program logic can manage any number of columns.
# Define a ODBC DSN connection string. $ConnectionString = 'DSN=MySQLODBC' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT last_name, first_name FROM contact ORDER BY 1, 2"; # Attempt to read SQL command. try { $row = $Command.ExecuteReader(); # Read while records are found. while ($row.Read()) { # Initialize output for each row. $output = "" # Navigate across all columns (only two in this example). for ($column = 0; $column -lt $row.FieldCount; $column += 1) { # Mechanic for comma-delimit between last and first name. if ($output.length -eq 0) { $output += $row[$column] } else { $output += ", " + $row[$column] } } # Write the output from the database. Write-Host $output } } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $row.Close() } } catch { Write-Host "Message: $($_.Exception.Message)" Write-Host "StackTrace: $($_.Exception.StackTrace)" Write-Host "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
You call the MySQLContact.ps1 Cmdlet with the following syntax:
powershell .\MySQLContact.ps1 |
It returns an ordered set of comma-separated values, like
Clinton, Goeffrey Gretelz, Simon Moss, Wendy Potter, Ginny Potter, Harry Potter, Lily Royal, Elizabeth Smith, Brian Sweeney, Ian Sweeney, Matthew Sweeney, Meaghan Vizquel, Doreen Vizquel, Oscar Winn, Brian Winn, Randi |
As always, I hope this helps those looking for a complete concrete example of how to make Microsoft Powershell connect and query results from a MySQL database.
PostgreSQL+PowerShell
This post explains and demonstrates how to install, configure, and use the psqlODBC (32-bit) and psqlODBC (64-bit) libraries to connect your Microsoft PowerShell programs to a locally installed PostgreSQL 14 database. It relies on you previously installing and configuring a PostgreSQL 14 database. This post is a step-by-step guide to installing PostgreSQL 14 on Windows 10, and this post shows you how to configure the PostgreSQL 14 database.
If you didn’t follow the instructions to get the psqlODBC libraries in the installation blog post, you will need to get those libraries, as qualified by Microsoft with the PostgreSQL Stack Builder.
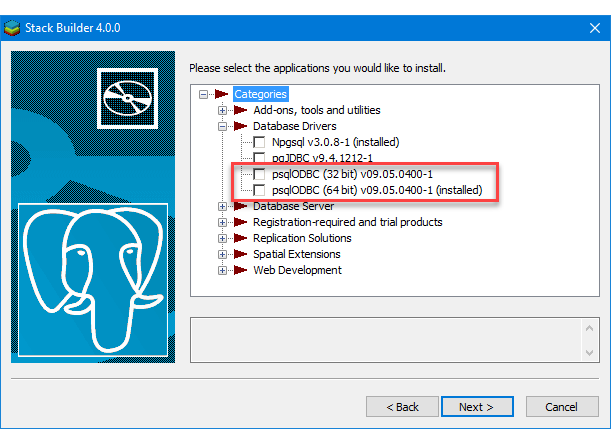
You can launch PostgreSQL Stack Builder after the install by clicking on Start -> PostgreSQL -> Stack Builder. Choose to enable Stack Builder to change your system and install the psqlODBC libraries. After you’ve installed the psqlODBC library, use Windows search field to find the ODBC Data Sources dialog and run it as administrator.
There are six steps to setup, test, and save your ODBC Data Source Name (DSN). You can click on the images on the right to launch them in a more readable format or simply read the instructions.
PostgreSQL ODBC Setup Steps

- The Microsoft DSN (Data Source Name) dialog automatically elects the User DSN tab. Click on the System DSN tab.
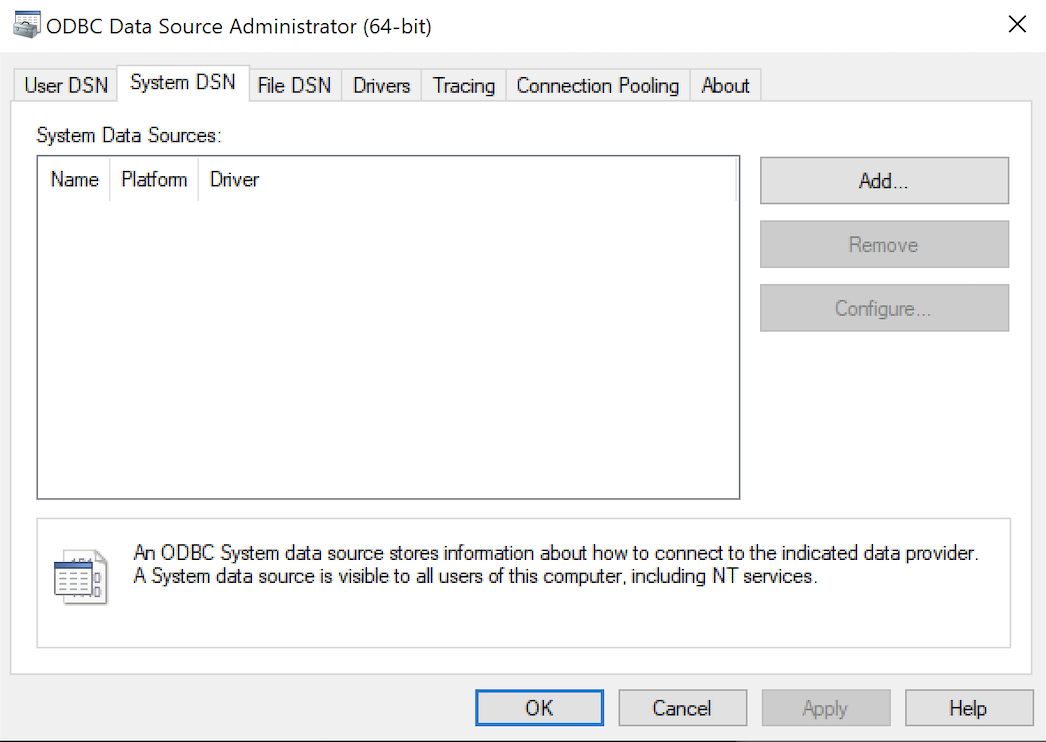
- The view under the System DSN is exactly like the User DSN tab. Click the Add button to start the workflow.

- The Create New Data Source dialog requires you select the PostgreSQL ODBC Driver(UNICODE) option from the list and click the Finish button to proceed.
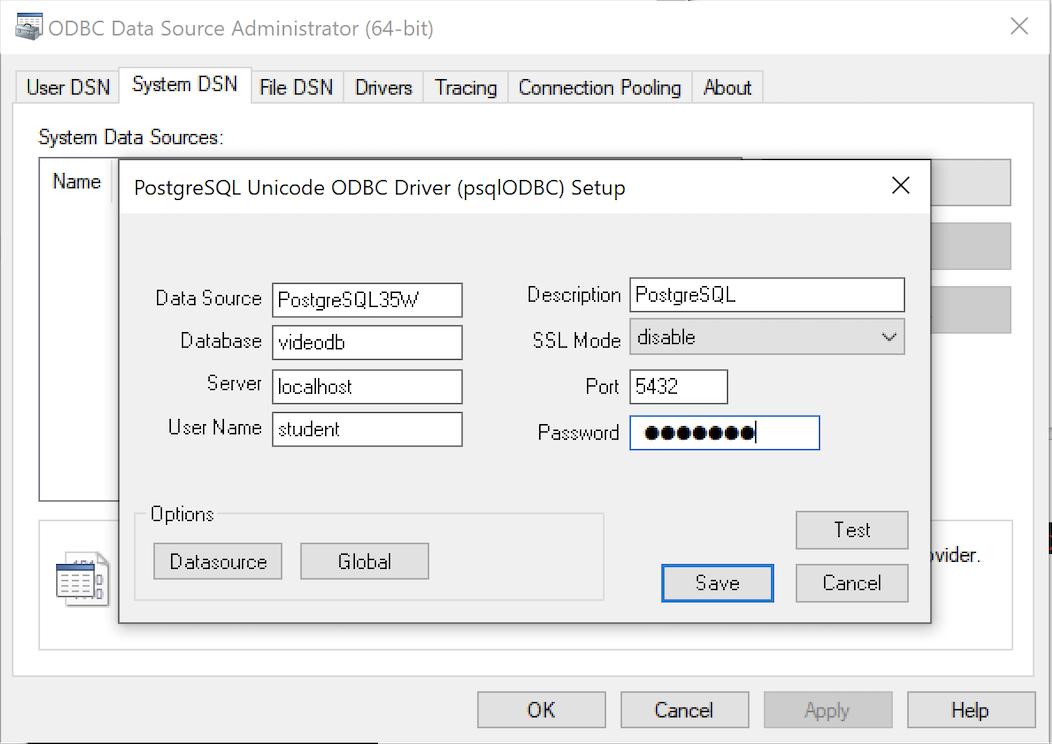
- The PostgreSQL Unicode ODBC Driver Setup dialog should complete the prompts as follows below and consistent with the PostgreSQL 14 Configuration blog. If you opt for localhost as the server value because you have a DCHP IP address, make sure you’ve configured your hosts file in the C:\Windows\System32\drivers\etc directory. You should enter the following two lines in the hosts file:
127.0.0.1 localhost ::1 localhost
These are the string values you should enter in the PostgreSQL Unicode ODBC Driver Setup dialog:
Data Source: PostgreSQL35W Database: videodb Server: localhost User Name: student Description: PostgreSQL SSL Mode: disable Port: 5432 Password: student
After you complete the entry, click the Test button.
- The Connection Test dialog should return a “Connection successful” message. Click the OK button to continue.
- The ODBC Data Source Administrator dialog should show the PostgreSQL35W System Data Source. Click the OK button to continue.
After you have created the System PostgreSQL ODBC Setup, it’s time to build a PowerShell Cmdlet (or, Commandlet). Some documentation and blog notes incorrectly suggest you need to write a connection string with a UID and password, like:
$ConnectionString = 'DSN=PostgreSQL35W;Uid=student;Pwd=student' |
The UID and password is unnecessary in the connection string. As a rule, the UID and password are only necessary in the ODBC DSN, like:
$ConnectionString = 'DSN=PostgreSQL35W' |
You can create a readcursor.ps1 Cmdlet like the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | # Define a ODBC DSN connection string. $ConnectionString = 'DSN=PostgreSQL35W' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT current_database();"; # Attempt to read SQL command. try { $Reader = $Command.ExecuteReader(); # Read while records are found. while ($Reader.Read()) { Write-Host "Current Database [" $Reader[0] "]"} } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $Reader.Close() } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
Line 14 assigns a SQL query that returns a single row with one column as the CommandText of a Command object. Line 22 reads the zero position of a row or record set with only one column.
You call the readcursor.ps1 Cmdlet with the following syntax:
powershell .\readcursor.ps1 |
It returns:
Current Database [ videodb ] |
A more realistic way to write a query would return multiple rows with a set of two or more columns. The following program queries a table with multiple rows of two columns, but the program logic can manage any number of columns.
# Define a ODBC DSN connection string. $ConnectionString = 'DSN=PostgreSQL35W' # Define a MySQL Command Object for a non-query. $Connection = New-Object System.Data.Odbc.OdbcConnection; $Connection.ConnectionString = $ConnectionString # Attempt connection. try { $Connection.Open() # Create a SQL command. $Command = $Connection.CreateCommand(); $Command.CommandText = "SELECT last_name, first_name FROM contact ORDER BY 1, 2"; # Attempt to read SQL command. try { $row = $Command.ExecuteReader(); # Read while records are found. while ($row.Read()) { # Initialize output for each row. $output = "" # Navigate across all columns (only two in this example). for ($column = 0; $column -lt $row.FieldCount; $column += 1) { # Mechanic for comma-delimit between last and first name. if ($output.length -eq 0) { $output += $row[$column] } else { $output += ", " + $row[$column] } } # Write the output from the database. Write-Host $output } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { # Close the reader. $row.Close() } } catch { Write-Error "Message: $($_.Exception.Message)" Write-Error "StackTrace: $($_.Exception.StackTrace)" Write-Error "LoaderExceptions: $($_.Exception.LoaderExceptions)" } finally { $Connection.Close() } |
You call the readcontact.ps1 Cmdlet with the following syntax:
powershell .\readcontact.ps1 |
It returns an ordered set of comma-separated values, like
Clinton, Goeffrey Gretelz, Simon Moss, Wendy Royal, Elizabeth Smith, Brian Sweeney, Ian Sweeney, Matthew Sweeney, Meaghan Vizquel, Doreen Vizquel, Oscar Winn, Brian Winn, Randi |
As always, I hope this helps those looking for a complete concrete example of how to make Microsoft Powershell connect and query results from a PostgreSQL database.
Python on PostgreSQL
The ODBC library you use when connecting Python to PostgreSQL is the psycopg2 Python library. This blog post will show use how to use it in Python and install it on your Fedora Linux installation. It leverages a videodb database that I show you how to build in this earlier post on configuring PostgreSQL 14.
You would import psycopg2 as follows in your Python code:
import psycopg2 |
Unfortunately, that only works on Linux servers when you’ve installed the library. That library isn’t installed with generic Python libraries. You get the following error when the psycopg2 library isn’t installed on your server.
Traceback (most recent call last):
File "python_new_hire.sql", line 1, in <module>
import psycopg2
ModuleNotFoundError: No module named 'psycopg2' |
You can install it on Fedora Linux with the following command:
yum install python3-psycopg2 |
It will install:
==================================================================================== Package Architecture Version Repository Size ==================================================================================== Installing: python3-psycopg2 x86_64 2.7.7-1.fc30 fedora 160 k Transaction Summary ==================================================================================== Install 1 Package Total download size: 160 k Installed size: 593 k Is this ok [y/N]: y Downloading Packages: python3-psycopg2-2.7.7-1.fc30.x86_64.rpm 364 kB/s | 160 kB 00:00 ------------------------------------------------------------------------------------ Total 167 kB/s | 160 kB 00:00 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Preparing : 1/1 Installing : python3-psycopg2-2.7.7-1.fc30.x86_64 1/1 Running scriptlet: python3-psycopg2-2.7.7-1.fc30.x86_64 1/1 Verifying : python3-psycopg2-2.7.7-1.fc30.x86_64 1/1 Installed: python3-psycopg2-2.7.7-1.fc30.x86_64 Complete! |
Here’s a quick test case that you can run in PostgreSQL and Python to test all the pieces. The first SQL script creates a new_hire table and inserts two rows, and the Python program queries data from the new_hire table.
The new_hire.sql file creates the new_hire table and inserts two rows:
-- Environment settings for the script. SET SESSION "videodb.table_name" = 'new_hire'; SET CLIENT_MIN_MESSAGES TO ERROR; -- Verify table name. SELECT current_setting('videodb.table_name'); -- ------------------------------------------------------------------ -- Conditionally drop table. -- ------------------------------------------------------------------ DROP TABLE IF EXISTS new_hire CASCADE; -- ------------------------------------------------------------------ -- Create table. -- ------------------------------------------------------------------- CREATE TABLE new_hire ( new_hire_id SERIAL , first_name VARCHAR(20) NOT NULL , middle_name VARCHAR(20) , last_name VARCHAR(20) NOT NULL , hire_date TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT CURRENT_TIMESTAMP , PRIMARY KEY (new_hire_id)); -- Alter the sequence by restarting it at 1001. ALTER SEQUENCE new_hire_new_hire_id_seq RESTART WITH 1001; -- Display the table organization. SELECT tc.table_catalog || '.' || tc.constraint_name AS constraint_name , tc.table_catalog || '.' || tc.table_name AS table_name , kcu.column_name , ccu.table_catalog || '.' || ccu.table_name AS foreign_table_name , ccu.column_name AS foreign_column_name FROM information_schema.table_constraints AS tc JOIN information_schema.key_column_usage AS kcu ON tc.constraint_name = kcu.constraint_name AND tc.table_schema = kcu.table_schema JOIN information_schema.constraint_column_usage AS ccu ON ccu.constraint_name = tc.constraint_name AND ccu.table_schema = tc.table_schema WHERE tc.constraint_type = 'FOREIGN KEY' AND tc.table_name = current_setting('videodb.table_name') ORDER BY 1; SELECT c1.table_name , c1.ordinal_position , c1.column_name , CASE WHEN c1.is_nullable = 'NO' AND c2.column_name IS NOT NULL THEN 'PRIMARY KEY' WHEN c1.is_nullable = 'NO' AND c2.column_name IS NULL THEN 'NOT NULL' END AS is_nullable , CASE WHEN data_type = 'character varying' THEN data_type||'('||character_maximum_length||')' WHEN data_type = 'numeric' THEN CASE WHEN numeric_scale != 0 AND numeric_scale IS NOT NULL THEN data_type||'('||numeric_precision||','||numeric_scale||')' ELSE data_type||'('||numeric_precision||')' END ELSE data_type END AS data_type FROM information_schema.columns c1 LEFT JOIN (SELECT trim(regexp_matches(column_default,current_setting('videodb.table_name'))::text,'{}')||'_id' column_name FROM information_schema.columns) c2 ON c1.column_name = c2.column_name WHERE c1.table_name = current_setting('videodb.table_name') ORDER BY c1.ordinal_position; -- Display primary key and unique constraints. SELECT constraint_name , lower(constraint_type) AS constraint_type FROM information_schema.table_constraints WHERE table_name = current_setting('videodb.table_name') AND constraint_type IN ('PRIMARY KEY','UNIQUE'); -- Insert two test records. INSERT INTO new_hire ( first_name, middle_name, last_name, hire_date ) VALUES ('Malcolm','Jacob','Lewis','2018-2-14') ,('Henry',null,'Chabot','1990-07-31'); |
You can put it into a local directory, connect as the student user to a videodb database, and run the following command (or any database you’ve created).
\i new_hire.sql |
The new_hire.py file creates the new_hire table and inserts two rows:
# Import the PostgreSQL connector library. import psycopg2 try: # Open a connection to the database. connection = psycopg2.connect( user="student" , password="student" , port="5432" , dbname="videodb") # Open a cursor. cursor = connection.cursor() # Assign a static query. query = "SELECT new_hire_id, first_name, last_name " \ "FROM new_hire" # Parse and execute the query. cursor.execute(query) # Fetch all rows from a table. records = cursor.fetchall() # Read through and print the rows as tuples. for row in range(0, len(records)): print(records[row]) except (Exception, psycopg2.Error) as error : print("Error while fetching data from PostgreSQL", error) finally: # Close the database connection. if (connection): cursor.close() connection.close() |
You run it from the command line, like:
python3 ./new_hire.py |
It should print:
(1001, 'Malcolm', 'Lewis') (1002, 'Henry', 'Chabot') |
As always, I hope this helps those trying to sort out how to connect Python to PostgreSQL.
MySQL Self-Join
I’m switching to MySQL and leveraging Alan Beaulieu’s Learning SQL as a supporting reference for my Database Design and Development course. While reviewing Alan’s Chapter 5: Querying Multiple Tables, I found his coverage of using self-joins minimal.
In fact, he adds a prequel_film_id column to the film table in the sakila database and then a single row to demonstrate a minimal self-join query. I wanted to show them how to view a series of rows interconnected by a self-join, like the following:
SELECT f.title AS film , fp.title AS prequel FROM film f LEFT JOIN film fp ON f.prequel_id = fp.film_id WHERE f.series_name = 'Harry Potter' ORDER BY f.series_number; |
It returns the following result set:
+----------------------------------------------+----------------------------------------------+ | film | prequel | +----------------------------------------------+----------------------------------------------+ | Harry Potter and the Chamber of Secrets | Harry Potter and the Sorcerer's Stone | | Harry Potter and the Prisoner of Azkaban | Harry Potter and the Chamber of Secrets | | Harry Potter and the Goblet of Fire | Harry Potter and the Prisoner of Azkaban | | Harry Potter and the Order of the Phoenix | Harry Potter and the Goblet of Fire | | Harry Potter and the Half Blood Prince | Harry Potter and the Order of the Phoenix | | Harry Potter and the Deathly Hallows: Part 1 | Harry Potter and the Half Blood Prince | | Harry Potter and the Deathly Hallows: Part 2 | Harry Potter and the Deathly Hallows: Part 1 | +----------------------------------------------+----------------------------------------------+ 7 rows in set (0.00 sec) |
Then, I thought about what questions the students might ask. For example, why doesn’t the query return the first film that doesn’t have a prequel. So, I took the self-join to the next level to display the first film having no prequel, like this:
SELECT f.title AS film , IFNULL( CASE WHEN NOT f.film_id = fp.film_id AND f.prequel_id = fp.film_id THEN fp.title END,'None') AS prequel FROM film f LEFT JOIN film fp ON f.prequel_id = fp.film_id WHERE f.series_name = 'Harry Potter' ORDER BY f.series_number; |
The CASE operator in the SELECT-list filters the result set by eliminating rows erroneously returned. Without the CASE filter, the query would return the original Harry Potter and the Sorcerer’s Stone film matched agains a NULL and all of the other sequels. The CASE operator effectively limits the result set for the LEFT JOIN to only the following data:
+----------------------------------------------+----------------------------------------------+ | film | prequel | +----------------------------------------------+----------------------------------------------+ | Harry Potter and the Sorcerer's Stone | NULL | +----------------------------------------------+----------------------------------------------+ |
The IFNULL() built-in function lets you replace the NULL value returned as the prequel’s title value. The IFNULL() function substitutes a 'None' string literal for a NULL value. The query returns the following result set:
+----------------------------------------------+----------------------------------------------+ | film | prequel | +----------------------------------------------+----------------------------------------------+ | Harry Potter and the Sorcerer's Stone | None | | Harry Potter and the Chamber of Secrets | Harry Potter and the Sorcerer's Stone | | Harry Potter and the Prisoner of Azkaban | Harry Potter and the Chamber of Secrets | | Harry Potter and the Goblet of Fire | Harry Potter and the Prisoner of Azkaban | | Harry Potter and the Order of the Phoenix | Harry Potter and the Goblet of Fire | | Harry Potter and the Half Blood Prince | Harry Potter and the Order of the Phoenix | | Harry Potter and the Deathly Hallows: Part 1 | Harry Potter and the Half Blood Prince | | Harry Potter and the Deathly Hallows: Part 2 | Harry Potter and the Deathly Hallows: Part 1 | +----------------------------------------------+----------------------------------------------+ 8 rows in set (0.01 sec) |
Alan’s modification of the sakila.film table had the following two related design flaws:
- It didn’t provide a way to guarantee the ordering of films with prequels because relational databases don’t guarantee ordered result sets unless you use an
ORDER BYclause, which typically requires a column to order. - It didn’t provide a way to isolate a series of films.
I modified the film table differently by adding the series_name, series_number, and prequel_id columns. The series_name column lets you group results and the series_number column lets you order by a preserved sequence that you store as part of the data The prequel_id column lets you connect to the prequel film, much like the backward portion of a doubly linked list.
The new sakila.film table is:
+----------------------+---------------------------------------------------------------------+------+-----+-------------------+-----------------------------------------------+ | Field | Type | Null | Key | Default | Extra | +----------------------+---------------------------------------------------------------------+------+-----+-------------------+-----------------------------------------------+ | film_id | smallint unsigned | NO | PRI | NULL | auto_increment | | title | varchar(255) | NO | MUL | NULL | | | description | text | YES | | NULL | | | release_year | year | YES | | NULL | | | language_id | tinyint unsigned | NO | MUL | NULL | | | original_language_id | tinyint unsigned | YES | MUL | NULL | | | rental_duration | tinyint unsigned | NO | | 3 | | | rental_rate | decimal(4,2) | NO | | 4.99 | | | length | smallint unsigned | YES | | NULL | | | replacement_cost | decimal(5,2) | NO | | 19.99 | | | rating | enum('G','PG','PG-13','R','NC-17') | YES | | G | | | special_features | set('Trailers','Commentaries','Deleted Scenes','Behind the Scenes') | YES | | NULL | | | last_update | timestamp | NO | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP | | series_name | varchar(20) | YES | | NULL | | | series_number | int unsigned | YES | | NULL | | | prequel | int unsigned | YES | | NULL | | +----------------------+---------------------------------------------------------------------+------+-----+-------------------+-----------------------------------------------+ 16 rows in set (0.21 sec) |
After adding the three new columns, I inserted eight rows for the original Harry Potter films. You can use the following script in the MySQL client (mysql) to add the columns and insert the data to test the preceding queries:
-- Use sakila database. USE sakila; -- Add a prequel_id column to the sakila.film table. ALTER TABLE film ADD (series_name varchar(20)), ADD (series_number int unsigned), ADD (prequel_id int unsigned); -- Set primary to foreign key local variable. SET @sv_film_id = 0; -- Insert Harry Potter films in sakila.film table with classic values clause. INSERT INTO film ( title , description , release_year , language_id , original_language_id , rental_duration , rental_rate , length , replacement_cost , rating , special_features , last_update , series_name , series_number , prequel_id ) VALUES ('Harry Potter and the Sorcerer''s Stone' ,'A film about a young boy who on his eleventh birthday discovers, he is the orphaned boy of two powerful wizards and has unique magical powers.' , 2001 , 1 , NULL , 3 , 0.99 , 152 , 19.99 ,'PG' ,'Trailers' ,'2001-11-04' ,'Harry Potter' , 1 , NULL ); -- Assign the last generated primary key value to the local variable. SET @sv_film_id := last_insert_id(); -- Insert 2nd film in sakila.film table with classic values clause. INSERT INTO film ( title , description , release_year , language_id , original_language_id , rental_duration , rental_rate , length , replacement_cost , rating , special_features , last_update , series_name , series_number , prequel_id ) VALUES ('Harry Potter and the Chamber of Secrets' ,'A film where Harry returning to Hogwarts, still famous and a hero, when strange things start to happen ... people are turning to stone and no-one knows what, or who, is doing it.' , 2002 , 1 , NULL , 3 , 0.99 , 160 , 19.99 ,'PG' ,'Trailers' ,'2002-11-15' ,'Harry Potter' , 2 , @sv_film_id ); -- Assign the last generated primary key value to the local variable. SET @sv_film_id := last_insert_id(); -- Insert 3rd film in sakila.film table with classic values clause. INSERT INTO film ( title , description , release_year , language_id , original_language_id , rental_duration , rental_rate , length , replacement_cost , rating , special_features , last_update , series_name , series_number , prequel_id ) VALUES ('Harry Potter and the Prisoner of Azkaban' ,'A film where Harry, Ron, and Hermione return for their third year at Hogwarts and are forced to face escaped prisoner, Sirius Black.' , 2004 , 1 , NULL , 3 , 0.99 , 141 , 19.99 ,'PG' ,'Trailers' ,'2004-06-04' ,'Harry Potter' , 3 , @sv_film_id ); -- Assign the last generated primary key value to the local variable. SET @sv_film_id := last_insert_id(); -- Insert 4th film in sakila.film table with classic values clause. INSERT INTO film ( title , description , release_year , language_id , original_language_id , rental_duration , rental_rate , length , replacement_cost , rating , special_features , last_update , series_name , series_number , prequel_id ) VALUES ('Harry Potter and the Goblet of Fire' ,'A film where where Harry Potter''s name emerges from the Goblet of Fire, and he becomes a competitor in a grueling battle for glory among three wizarding schools - the Triwizard Tournament.' , 2005 , 1 , NULL , 3 , 0.99 , 157 , 19.99 ,'PG' ,'Trailers' ,'2005-11-18' ,'Harry Potter' , 4 , @sv_film_id ); -- Assign the last generated primary key value to the local variable. SET @sv_film_id := last_insert_id(); -- Insert 5th film in sakila.film table with classic values clause. INSERT INTO film ( title , description , release_year , language_id , original_language_id , rental_duration , rental_rate , length , replacement_cost , rating , special_features , last_update , series_name , series_number , prequel_id ) VALUES ('Harry Potter and the Order of the Phoenix' ,'A film where Lord Voldemort has returned, but the Ministry of Magic is doing everything it can to keep the wizarding world from knowing the truth.' , 2007 , 1 , NULL , 3 , 0.99 , 138 , 19.99 ,'PG-13' ,'Trailers' ,'2007-07-12' ,'Harry Potter' , 5 , @sv_film_id ); -- Assign the last generated primary key value to the local variable. SET @sv_film_id := last_insert_id(); -- Insert 6th film in sakila.film table with classic values clause. INSERT INTO film ( title , description , release_year , language_id , original_language_id , rental_duration , rental_rate , length , replacement_cost , rating , special_features , last_update , series_name , series_number , prequel_id ) VALUES ('Harry Potter and the Half Blood Prince' ,'A film where Voldemort is tightening his grip on Hogwarts and it is no longer the safe haven it once was. Harry and Dumbledore work to find the key to unlock the Dark Lord''s defenses.' , 2009 , 1 , NULL , 3 , 0.99 , 153 , 19.99 ,'PG' ,'Trailers' ,'2009-07-15' ,'Harry Potter' , 6 , @sv_film_id ); -- Assign the last generated primary key value to the local variable. SET @sv_film_id := last_insert_id(); -- Insert 7th film in sakila.film table with classic values clause. INSERT INTO film ( title , description , release_year , language_id , original_language_id , rental_duration , rental_rate , length , replacement_cost , rating , special_features , last_update , series_name , series_number , prequel_id ) VALUES ('Harry Potter and the Deathly Hallows: Part 1' ,'A film where Harry, Ron and Hermione set out on their perilous mission to track down and destroy the Horcruxes - the keys to Voldemort''s immortality.' , 2010 , 1 , NULL , 3 , 0.99 , 146 , 19.99 ,'PG-13' ,'Trailers' ,'2010-11-19' ,'Harry Potter' , 7 , @sv_film_id ); -- Assign the last generated primary key value to the local variable. SET @sv_film_id := last_insert_id(); -- Insert 8th film in sakila.film table with classic values clause. INSERT INTO film ( title , description , release_year , language_id , original_language_id , rental_duration , rental_rate , length , replacement_cost , rating , special_features , last_update , series_name , series_number , prequel_id ) VALUES ('Harry Potter and the Deathly Hallows: Part 2' ,'A film where Harry, Ron and Hermione set out on their perilous mission to track down and destroy the Horcruxes - the keys to Voldemort''s immortality.' , 2011 , 1 , NULL , 3 , 0.99 , 130 , 19.99 ,'PG-13' ,'Trailers' ,'2011-07-15' ,'Harry Potter' , 8 , @sv_film_id ); |
You can put the following commands into a SQL script file to revert the sakila.film table to its base configuration:
DELETE FROM film WHERE film_id > 1000; ALTER TABLE film DROP COLUMN series_name; ALTER TABLE film DROP COLUMN series_number; ALTER TABLE film DROP COLUMN prequel_id; ALTER TABLE film AUTO_INCREMENT = 1000; |
As always, I hope this helps those looking for how to solve a new problem.
